







学习链接:https://httplib2.github.io/httplib2/
使用编写工具:notepad++
自我学习目的:使用httplib2获取获取想要的网页数据,再整理形成表格,提高效率
httplib2.content:获取访问网页的HTML内容
import httplib2
h = httplib2.Http(".cache")
(httplib2.resp_headers, httplib2.content) = h.request("http://example.org/","GET")
print("响应内容", httplib2.content)
访问 http://example.org/
将获取到的相应内容存储到example.html文件(在哪里打开的命令行,文件就在那个目录下)
import httplib2
h = httplib2.Http(".cache")
(httplib2.resp_headers, httplib2.content) = h.request("http://example.org/","GET")
filename = "example.html"
with open(filename, "w") as file:
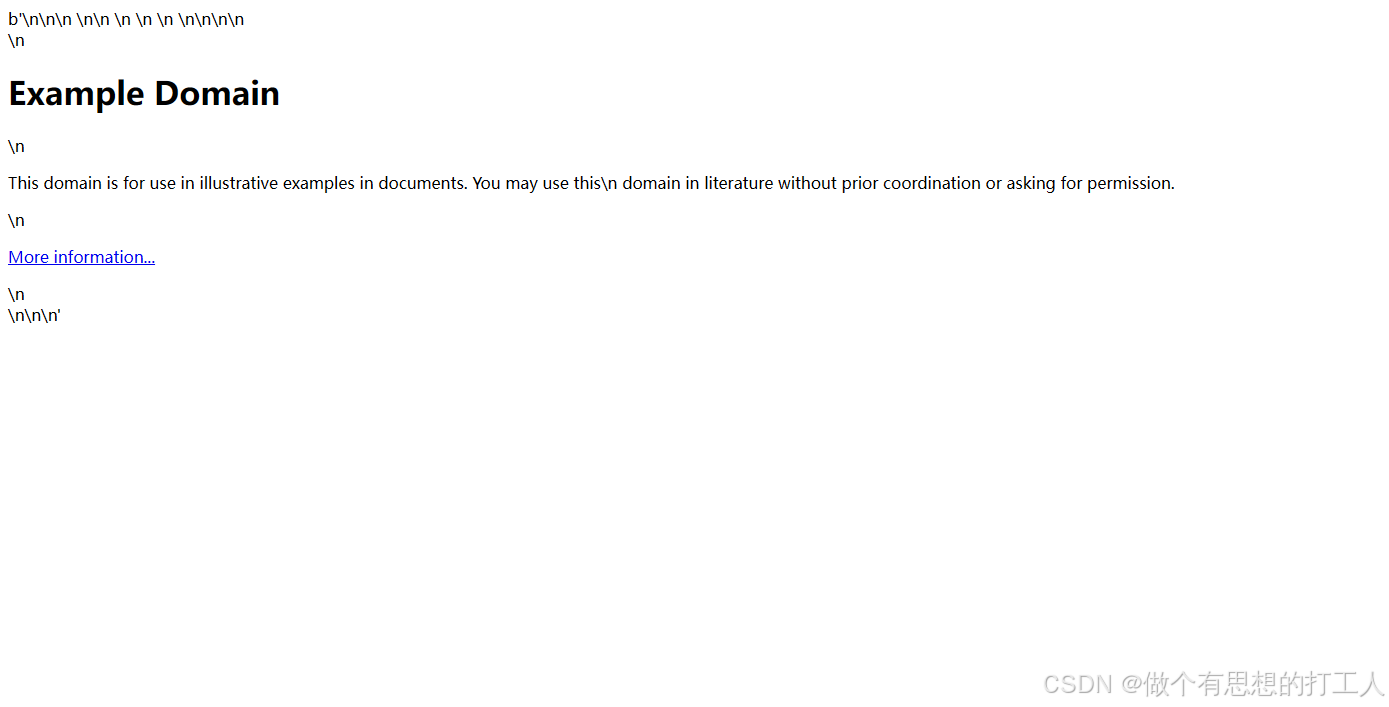
file.write(str(httplib2.content))b'<!doctype html>\n<html>\n<head>\n <title>Example Domain</title>\n\n <meta charset="utf-8" />\n <meta http-equiv="Content-type" content="text/html; charset=utf-8" />\n <meta name="viewport" content="width=device-width, initial-scale=1" />\n <style type="text/css">\n body {\n background-color: #f0f0f2;\n margin: 0;\n padding: 0;\n font-family: -apple-system, system-ui, BlinkMacSystemFont, "Segoe UI", "Open Sans", "Helvetica Neue", Helvetica, Arial, sans-serif;\n \n }\n div {\n width: 600px;\n margin: 5em auto;\n padding: 2em;\n background-color: #fdfdff;\n border-radius: 0.5em;\n box-shadow: 2px 3px 7px 2px rgba(0,0,0,0.02);\n }\n a:link, a:visited {\n color: #38488f;\n text-decoration: none;\n }\n @media (max-width: 700px) {\n div {\n margin: 0 auto;\n width: auto;\n }\n }\n </style> \n</head>\n\n<body>\n<div>\n <h1>Example Domain</h1>\n <p>This domain is for use in illustrative examples in documents. You may use this\n domain in literature without prior coordination or asking for permission.</p>\n <p><a href="https://www.iana.org/domains/example">More information...</a></p>\n</div>\n</body>\n</html>
httplib2.resp_header:请求头响应头
import httplib2
h = httplib2.Http(".cache")
(httplib2.resp_headers, httplib2.content) = h.request("http://example.org/","GET")
print("", httplib2.resp_headers)执行结果:
{'status': '200', 'age': '319629', 'cache-control': 'max-age=604800', 'content-type': 'text/html; charset=UTF-8', 'date': 'Mon, 21 Oct 2024 11:31:05 GMT', 'etag': '"3147526947+gzip"', 'expires': 'Mon, 28 Oct 2024 11:31:05 GMT', 'last-mo
dified': 'Thu, 17 Oct 2019 07:18:26 GMT', 'server': 'ECAcc (sac/2505)', 'vary': 'Accept-Encoding', 'x-cache': 'HIT', 'content-length': '1256', '-content-encoding': 'gzip', 'content-location': 'http://example.org/', '-varied-accept-encodi
ng': 'gzip, deflate'}
?httplib2.resp:
import httplib2
h = httplib2.Http(".cache")
h.add_credentials("name", "password")
(httplib2.resp, httplib2.content) = h.request("http://example.org/chapter/2",
"PUT", body="This is text",
headers={'content-type':'text/plain'} )
print("?响应次数", httplib2.resp)
print("响应内容", httplib2.content)执行结果:
?响应次数 {'content-type': 'text/html; charset=UTF-8', 'date': 'Mon, 21 Oct 2024 12:13:11 GMT', 'server': 'ECAcc (sac/252D)', 'content-length': '0', 'status': '405'}
响应内容 b''
headers={'CACHE-control':'no-cache'}
第一个请求将被缓存,此后对该URI 的任何 GET 请求都将返回来自磁盘缓存的值,并且不会向服务器发出请求。
第二个请求添加了 Cache-Control:标头和“no-cache”值,告诉库在处理此请求时不得使用缓存的副本。
import httplib2
h = httplib2.Http(".cache")
(httplib2.resp, httplib2.content) = h.request("http://bitworking.org", "GET")
print("没有hearders参数信息. {}", httplib2.resp)
print("没有hearders参数信息:content:{}".format(httplib2.content))
(httplib2.resp, httplib2.content) = h.request("http://bitworking.org", "GET",
headers={'CACHE-control':'no-cache'})
print("有hearders参数信息. {}", httplib2.resp)
print("有hearders参数信息:content:{}".format(httplib2.content))执行结果:

import httplib2
h = httplib2.Http(".cache")
(httplib2.resp, httplib2.content) = h.request("http://bitworking.org", "GET")
print("没有hearders参数信息. {}", httplib2.resp)
print("没有hearders参数信息:content:{}".format(httplib2.content))
(httplib2.resp, httplib2.content) = h.request("http://bitworking.org", "GET")
print("没有hearders参数信息. {}", httplib2.resp)
print("没有hearders参数信息:content:{}".format(httplib2.content))
(httplib2.resp, httplib2.content) = h.request("http://bitworking.org", "GET",
headers={'CACHE-control':'no-cache'})
print("有hearders参数信息. {}", httplib2.resp)
print("有hearders参数信息:content:{}".format(httplib2.content))执行结果

实战1:访问荣耀X50i+ - 11.11全程1.2倍价保,退换货免运费 | 荣耀商城获取手机信息
import httplib2
h = httplib2.Http()
httplib2.content = h.request("https://www.honor.com/cn/shop/product/10086041939069.html", "GET")
print(httplib2.content)
? 执行结果:报错
XXXXXXXXXXXXXXXXX
ssl.SSLCertVerificationError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1000)
import httplib2
h = httplib2.Http()
h.ca_certs = False # 去除SSL验证
h.disable_ssl_certificate_validation=True #禁用SSL验证证书为真,不执行SSL证书验证
(httplib2.response, httplib2.content)= h.request("https://www.honor.com/cn/shop/product/10086041939069.html", "POST")
print(httplib2.content)?执行结果:
b''
访问地址:荣耀Magic6 Pro参数配置-规格性能 | 荣耀官方网站
import httplib2
h = httplib2.Http()
h.ca_certs = False # 去除SSL验证
h.disable_ssl_certificate_validation=True #禁用SSL验证证书为真,不执行SSL证书验证
(httplib2.response, httplib2.content)= h.request("https://www.honor.com/cn/phones/honor-magic6-pro/spec/", "POST")
print(httplib2.content)执行结果:
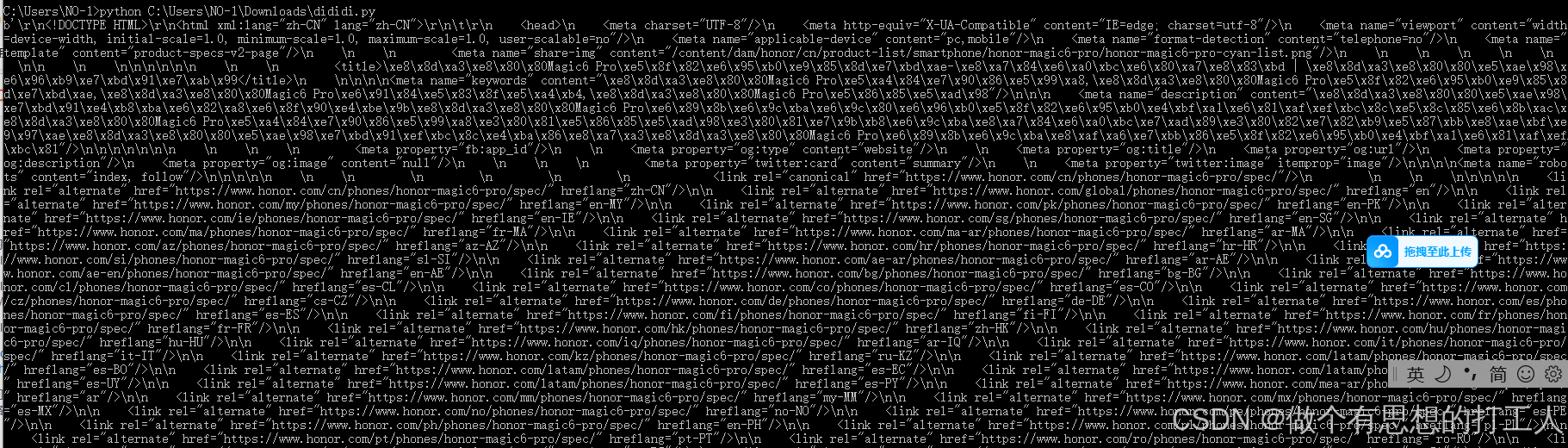

















 826
826

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









