







2025.1.6
1、insert语句获取自增键,获取值为空
**问题:Insert语句在xml映射文件中,Option在方法上,导致将自增的值赋值到实体类。**原因:@Insert注解和@Option注解必须搭配使用
解决方案:
方案一:全使用xml配置
<mapper namespace="com.itheima.mapper.EmpMapper">
<insert id="insert" useGeneratedKeys = "true" keyProperty = "id">
insert into emp(username, name, gender, phone, job, salary, image, entry_date, dept_id, create_time, update_time)
values (#{username},#{name},#{gender},#{phone},#{job},#{salary},#{image},#{entryDate},#{deptId},#{createTime},#{updateTime});
</insert>
方案二:在方法头上加上@Insert和@Option
@Insert("INSERT INTO sys_user (login_name, password, salt, del_flag) VALUES(#{loginName}, #{password}, #{salt}, #{delFlag}")
//useGeneratedKeys:当设置为true时,MyBatis将会调用此方法,并可以捕获由数据库生成的主键值。
//keyProperty:需要赋值的实体类的键值此参数指定了将生成的主键值设置到实体类的哪个属性上
//keyColumn:该参数定义了数据库表中哪一列是主键列,默认为id
@Options(useGeneratedKeys = true, keyProperty = "id", keyColumn = "id")
void insertUser(User user);
2、路径中的\\和/问题
在Java中,路径分隔符的选择(`\\` 或 `/`)主要影响代码的可移植性和兼容性。以下是这两种分隔符的区别和使用场景:**\\ (反斜杠) 使用:**
Windows特定:反斜杠 \ 是Windows操作系统上文件路径的默认分隔符。由于在Java字符串中反斜杠是转义字符,所以需要使用双反斜杠 \\ 来表示一个实际的反斜杠。
-
非跨平台:如果你直接使用反斜杠来构建路径,你的代码将只适用于Windows系统,并且可能在其他操作系统(如Linux或macOS)上无法正常工作。
-
直观性:对于习惯于Windows环境的开发者来说,使用反斜杠可能看起来更直观。
java示例:
File file = new File(“C:\Users\user\file.txt”);
** / (正斜杠) 使用:**
-
跨平台:正斜杠
/是Unix-like系统(包括Linux和macOS)上的默认路径分隔符,但Java I/O库也接受它作为Windows路径的分隔符。因此,使用正斜杠可以编写出与操作系统无关的代码,提高代码的可移植性。 -
无需转义:正斜杠不需要在Java字符串中进行转义,这使得路径字符串更易读、更简洁。
-
URL兼容:当处理网络路径或URL时,正斜杠是标准的一部分,因此在这种情况下必须使用正斜杠。
java示例:
File file = new File(“/home/user/file.txt”); // 对于Linux/macOS
File file = new File(“C:/Users/user/file.txt”); // 对于Windows
推荐做法
为了确保代码的可移植性和兼容性,推荐的做法是使用以下方法之一:
-
使用
File.separator:这是Java提供的静态字段,返回适合当前操作系统的路径分隔符。String path = "folder" + File.separator + "file.txt"; -
使用
Path和Paths类(从Java 7开始提供):这些类提供了更好的抽象来处理文件路径,自动处理不同操作系统之间的差异。Path path = Paths.get("folder", "file.txt"); -
始终使用正斜杠
/:即使是在Windows环境中,Java I/O库也能正确解析用正斜杠分隔的路径,因此可以直接使用正斜杠以保持代码简单和跨平台。
通过遵循上述建议,你可以编写出更加便携和易于维护的代码。
3、CollectionUtils.isEmpty()和List接口中的isEmpty的区别是什么?
List接口:不能处理null值,在调用前确保对象不是null
CollectionUtils:提供了更为广泛的适用性,能够安全处理null值

2025.1.8
4、泛型问题:解释如下代码
```plain public static List asList(T... a) { return new ArrayList<>(a); } ```静态方法想要使用泛型,必须要申明自己的泛型,所以在static后面加,List表明返回类型是泛型List,T…表示名是T类型的可变参数,实际a是一个集合或者数组。
5、为什么字节流操作纯文本会乱码,字符流不会
字节流以字节为单位读取和写入数据,这意味着它直接处理原始的二进制数据而不考虑这些数据代表的具体含义。对于包含非ASCII字符(如中文、日文等)的文本文件,如果使用字节流进行读写操作,并且没有正确设置编码格式,就可能导致乱码。例如,在UTF-8编码下,一个汉字可能由三个字节组成;当字节流逐字节读取时,可能会将一个多字节字符分割开来读取,导致部分字节丢失或不完整,进而产生乱码。操作系统与Java程序之间可能存在不同的默认编码格式。比如,IDEA默认使用UTF-8编码来读取文件,而Windows系统文件默认存储格式可能是GBK。在这种情况下,如果不做特殊处理,Java程序读取文件时就会因为编码格式不匹配而出现乱码。
字符流是以字符为单位进行读写的,它内部包含了对特定字符集的支持。字符流在读取或写入文本时会自动根据指定的编码规则将字节序列转换成相应的字符,或者反过来将字符转换成字节序列。因此,只要确保读写两端使用的编码一致,就可以避免乱码问题的发生。
无论是字节流还是字符流,保持编码的一致性是关键。如果你用UTF-8编码保存了一个文件,那么读取这个文件时也必须使用UTF-8编码。
综上所述,字节流由于其底层机制的原因,在处理含有非ASCII字符的文本时容易产生乱码;而字符流则内置了对多种字符编码的支持,能够更好地适应不同语言和地区的需求,减少了乱码发生的可能性。为了提高代码的健壮性和兼容性,建议在处理文本文件时优先选择字符流,并始终注意编码的一致性。
2025.1.12
6.配置mouduls后,打成jar包过程的问题
> Unable to find main class >错误原因:检查父工程的 pom.xml,发现有全局配置 spring-boot-maven-plugin 插件。但是实际只在需要的子模块中配置该插件。
处理:删除父工程中的全局打包模块,就不会在每一个子模块中查找main class文件了。
7.vscode中不能执行vue脚本文件
原因:此系统禁止运行脚本。
解决方案:
1.在Windows搜索框中查找PowerShell
2.右键点击PowerShell图标
3.选择“以管理员身份运行”
4.执行以下命令来查看当前的执行策略:Get****-ExecutionPolicy
5.如果返回结果是:Restricted
6.执行以下命令:Set-ExecutionPolicy RemoteSigned
8.vue路径引入报错
造成的原因:修改过文件名字,但是仅仅改变了字母大小写,源文件名没更新。
解决方案:
1.修改为其他名字(仅改变字母大小写无效),若需要保留原名,重启vscode后再改回来
2.引入路径时不加vue(可能找不到文件)
2025.1.14
9.Aspect的切面表达式不能拦截Mapper层接口方法。
在Spring中使用[MyBatis](https://so.csdn.net/so/search?q=MyBatis&spm=1001.2101.3001.7020) 的 Mapper 接口自动生成时,用一个自定义的注解标记在Mapper接口的方法中,再利用@Aspect定义一个切面,拦截这个注解以记录日志或者执行时长。但是惊奇的发现这样做之后,在Spring Boot 1.X(Spring Framework 4.x)中,并不能生效,而在Spring Boot 2.X(Spring Framework 5.X)中却能生效。2025.1.17
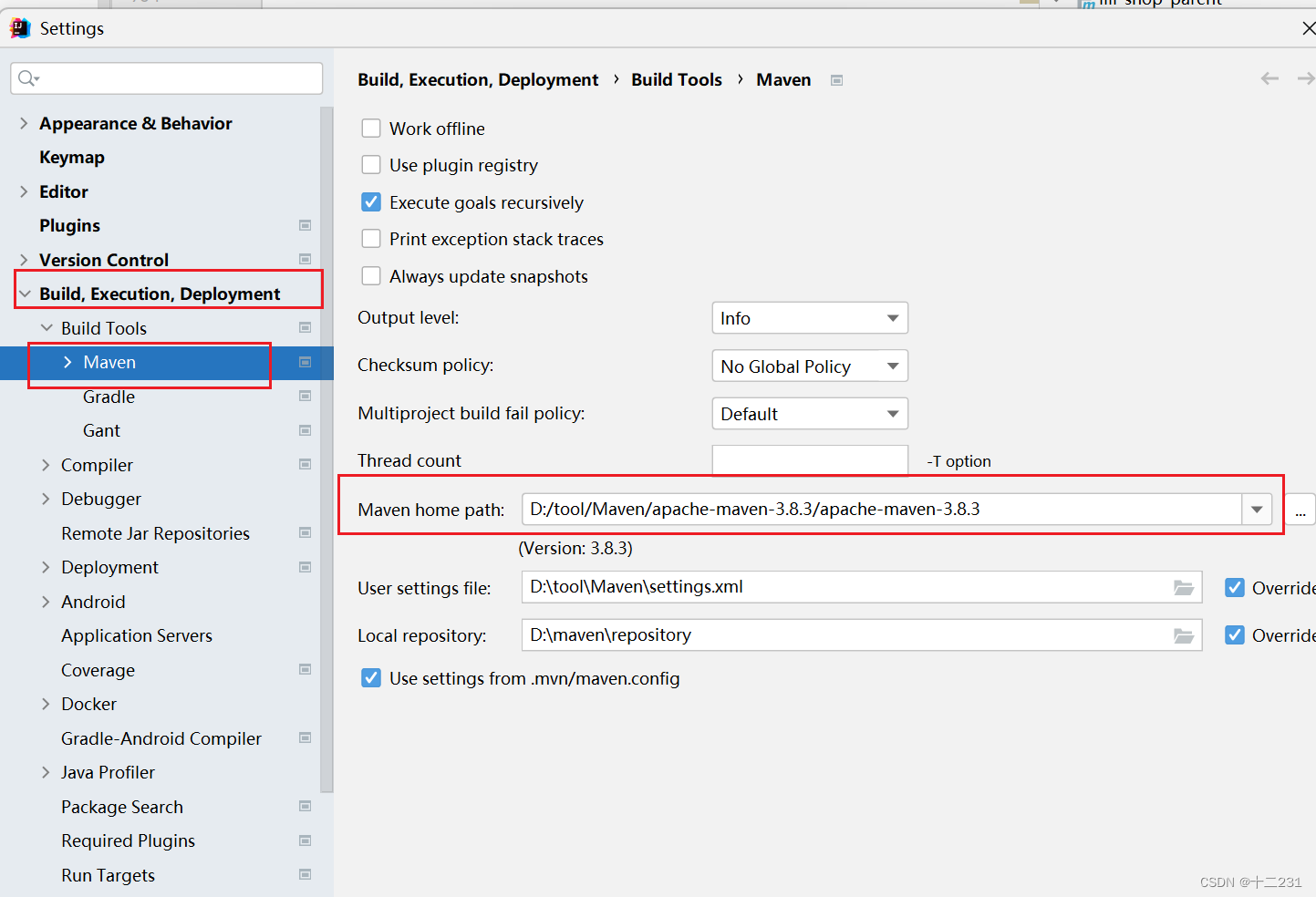
10.No valid Maven installation found. Either set the home directory in the configuration dialog or set
无法使用maven的构建工具。
这个错误是由于找不到maven的路径。
2025.1.18
10.关于nginx无法启动问题
1.测试能否访问成功:在nginx目录下,输入nginx进行启动,未报错说明启动成功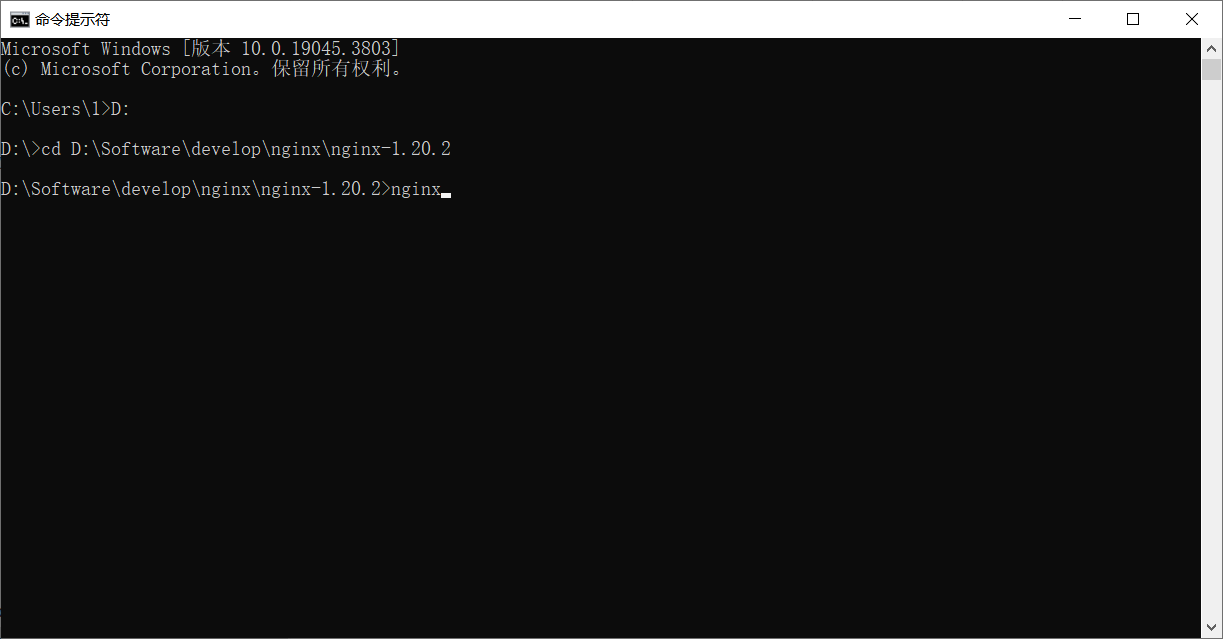
如果报错:(按照下面流程进行处理)
nginx: [alert] could not open error log file: CreateFile() “logs/error.log” failed (5: Access is denied)
2025/01/19 13:06:09 [emerg] 8580#12408: CreateDirectory() “D:\Software\develop\nginx\nginx-1.20.2/temp/client_body_temp” failed (3: The system cannot find the path specified)
2.开启访问权限
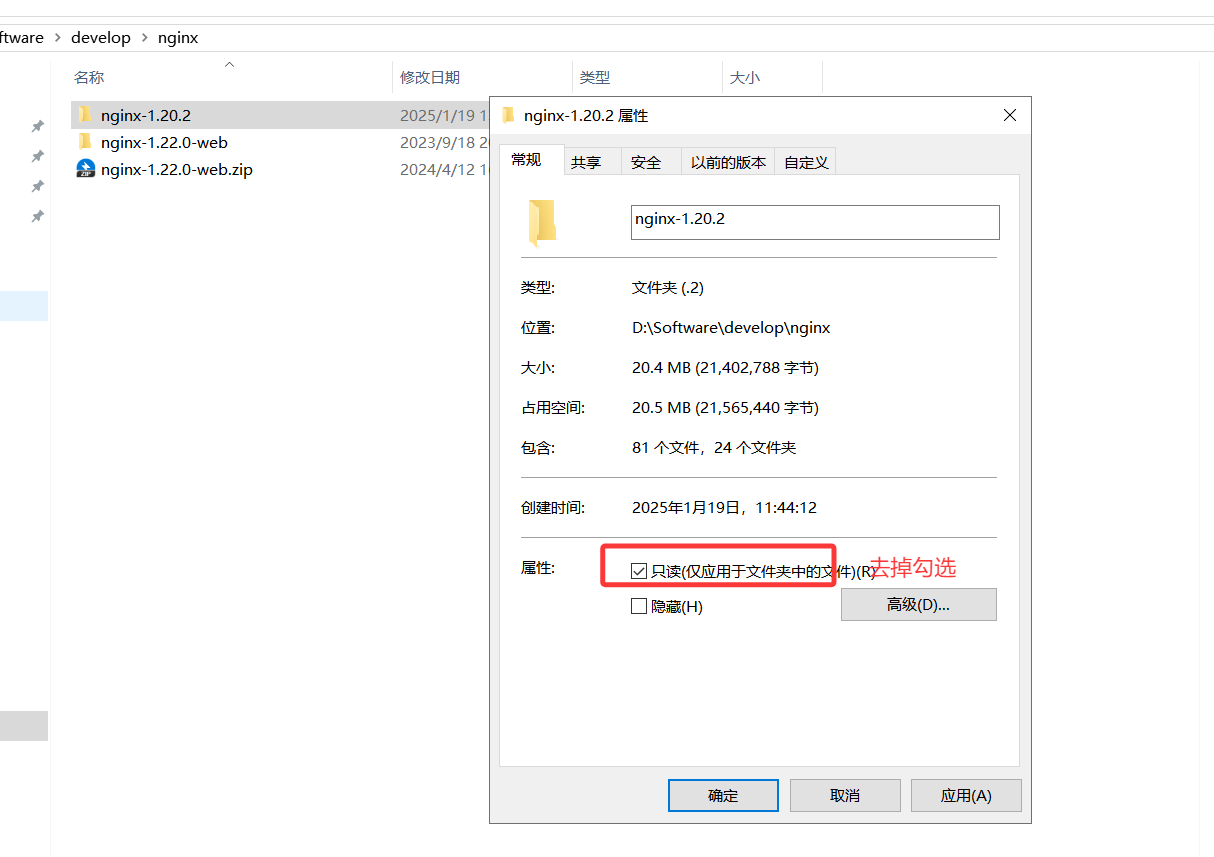
3.如果访问不成功,根据bug提示手动创建子文件夹temp/client_body_tem(一般上一步就可以解决了)
4.双击nginx.exe进行后台运行
2025.1.21
11.导入项目运行后,报错java: Cannot find JDK ‘XX‘ for module ‘XX‘
1.删除.idea和.iml文件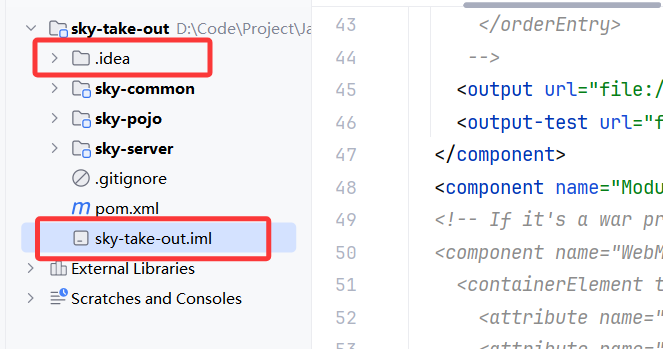
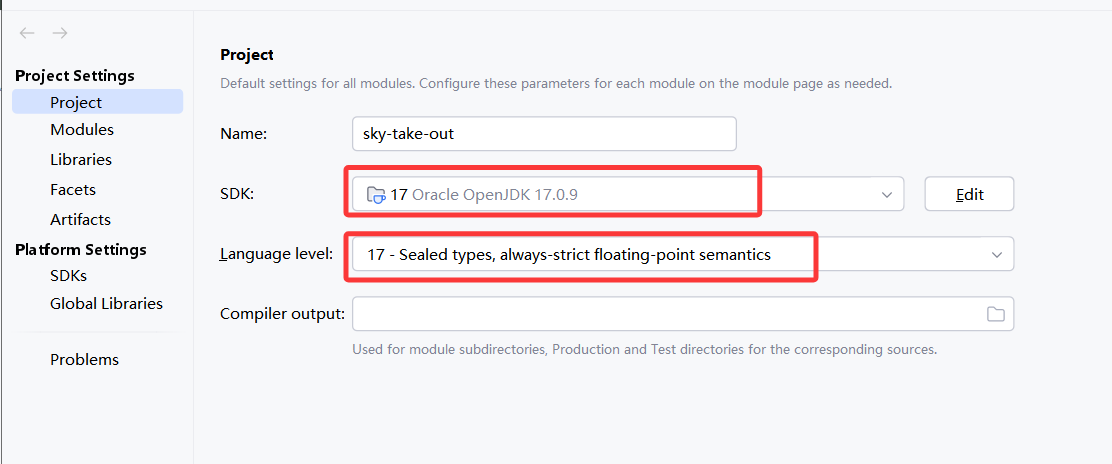
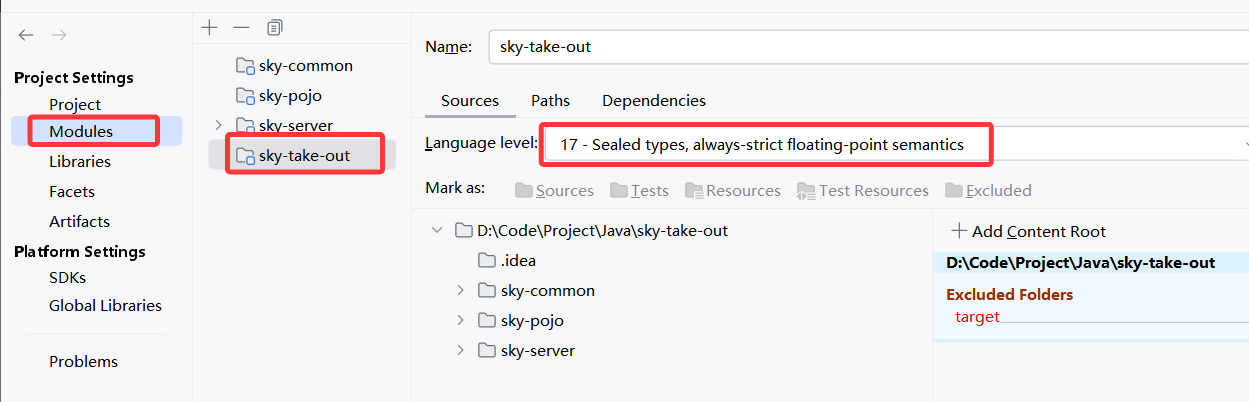
2.打开项目结构,将项目和各个模块的jdk保持一致,只要修改后点应用或者ok就可以自动生成.idea文件
3.生成iml文件:按两下ctrl,在弹出的窗口右上角点击project,在下拉列表中选择需要生成.iml文件的模块,左边运行写 : mvn idea:module ,然后回车运行,即可生成.iml文件。
运行成功:
12.lambda(同匿名内部类)不能修改外部局部变量的值
**条件:**- 局部变量并且在lambda外部
- 你想要在lambda中修改它
报错:Local variable result defined in an enclosing scope must be final or effectively final
报错原因:本质上就是因为lambda表达式在方法内部,那么lambda表达式的内存分配就是在栈上。局部变量也被存放在栈上,而每个线程都有自己独立的栈,局部变量本身不会在线程间共享。然而,lambda表达式或匿名内部类可以被不同的线程执行栈内存不会被共享,也就意味着你没有权利和其他栈帧通信。
解决方案:
1、使用一个数组来包装局部变量,数组是对象,因此所有的数组实例(无论是局部数组还是成员变量)都是在堆(heap)上分配内存的。
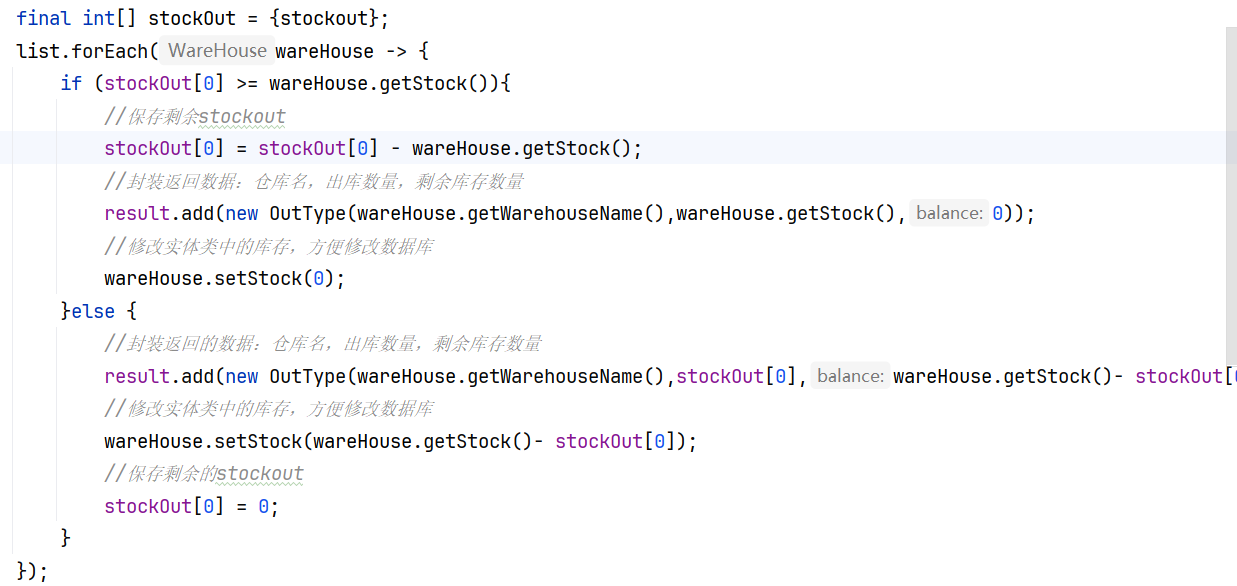
2、使用 AtomicInteger对象进行包装,使这个变量在堆中就可以访问和修改了。
13.固定idea的主菜单栏和工具栏
找了半小时。。。我真的服了。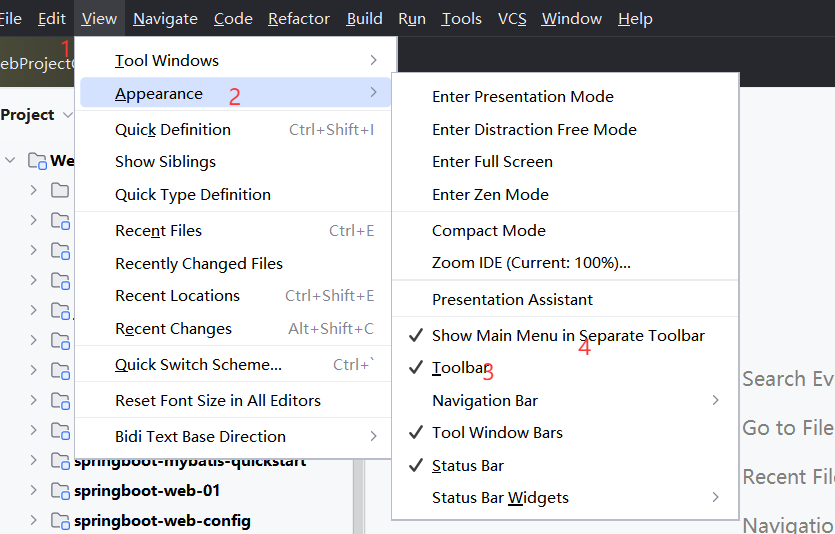
14.项目能正常启动,但是报了一堆红
方案一:清理缓存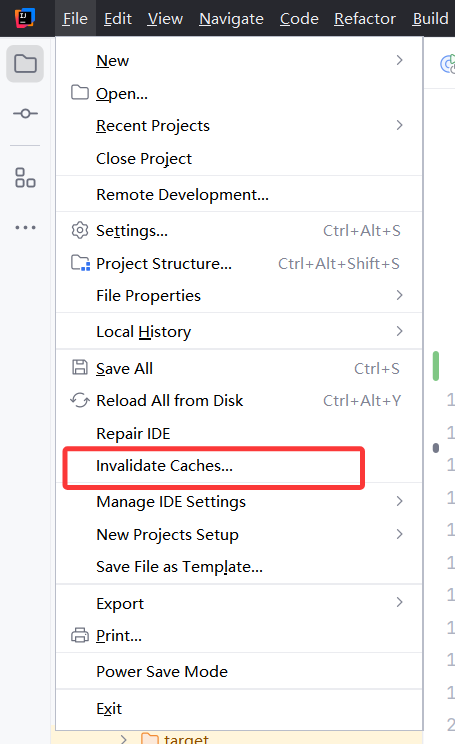
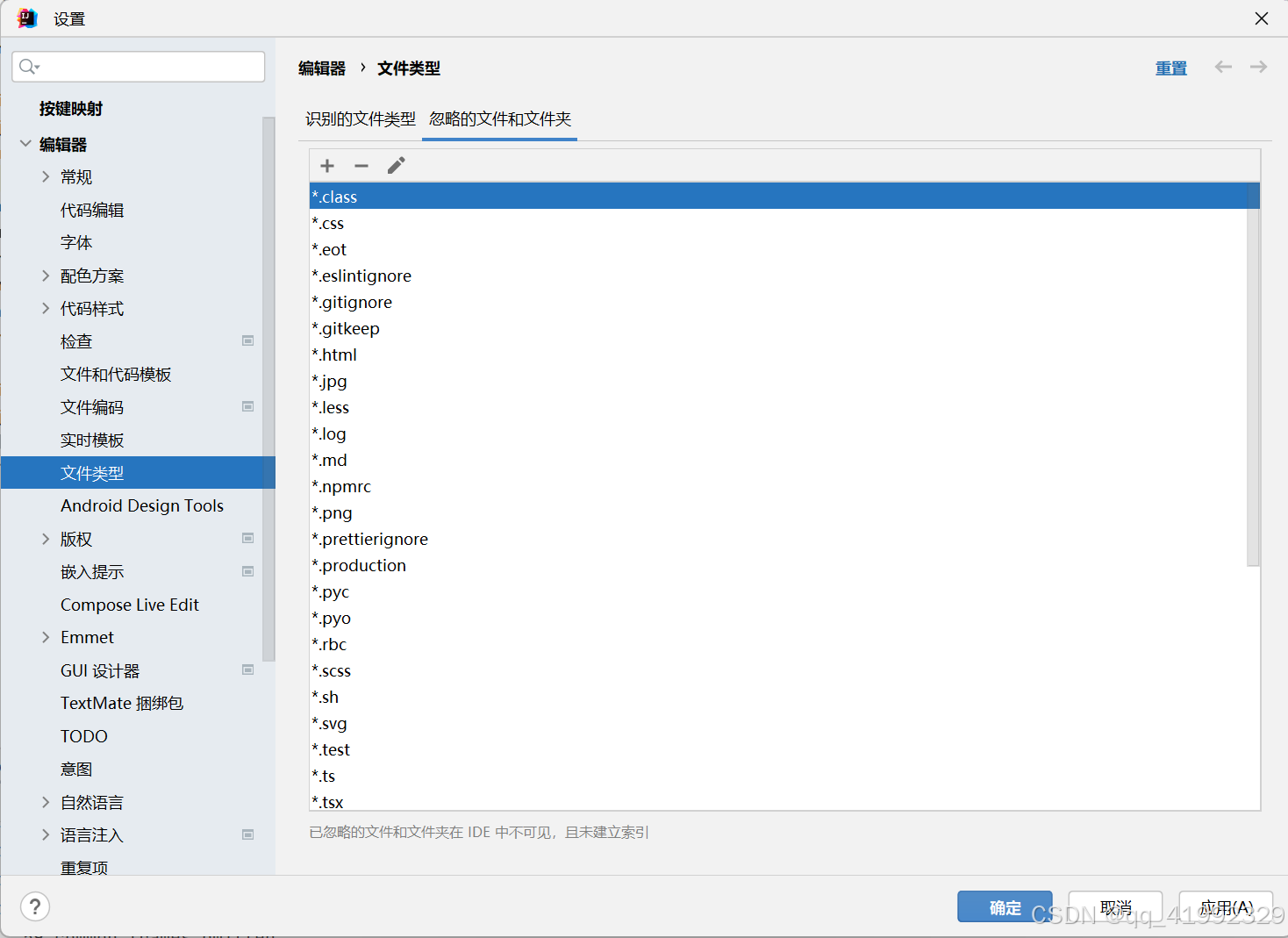
方案2:想一想,在出现这个问题之前,是不是在提交代码的时候看到大量无关文件,所以你选择忽略了.class后缀的文件?打开设置->编辑器->文件类型->忽略的文件和文件夹,选中*.class类型文件,点击上方减号,点击应用,项目恢复正常。
15.AOP编程,切面表达式无法匹配到mapper层的方法
错误原因:@Mapper层没有接口方法,插件无法找到实现类Bean,所以无法跳转,报空错误。
解决方案:正常写即可,spring底层会正常管理和切入匹配相关Bean,不要纠结插件报错。
2025.2.10
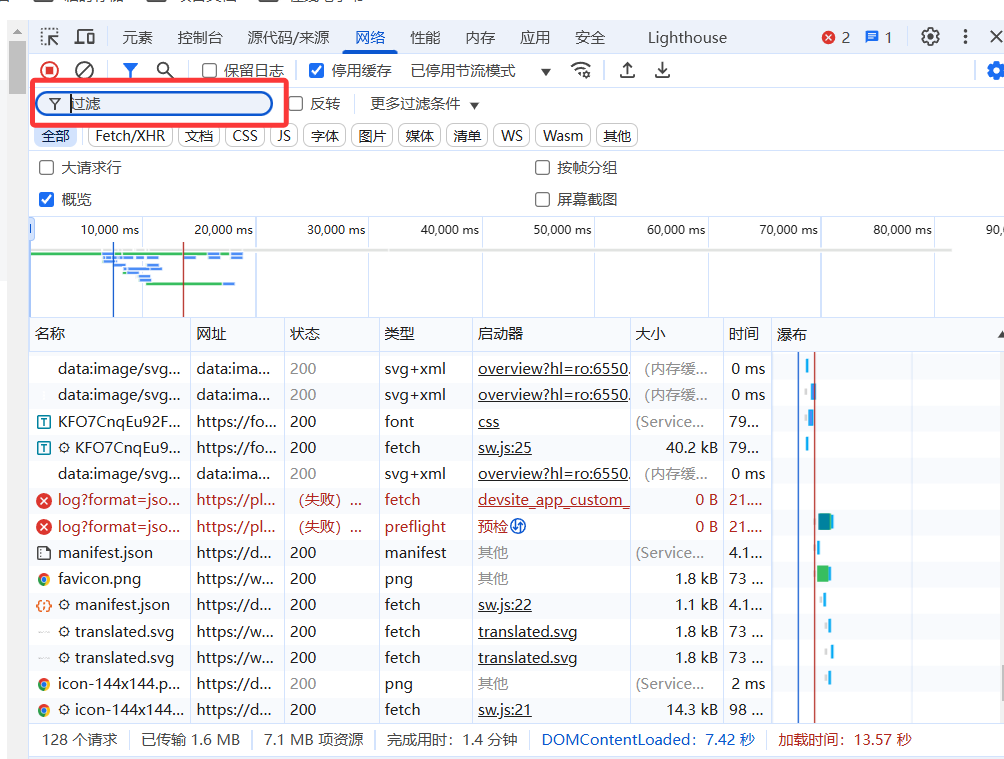
16.谷歌浏览器开发者工具中网络只能抓包内网请求,外网请求不显示
错误原因:启用了过滤选项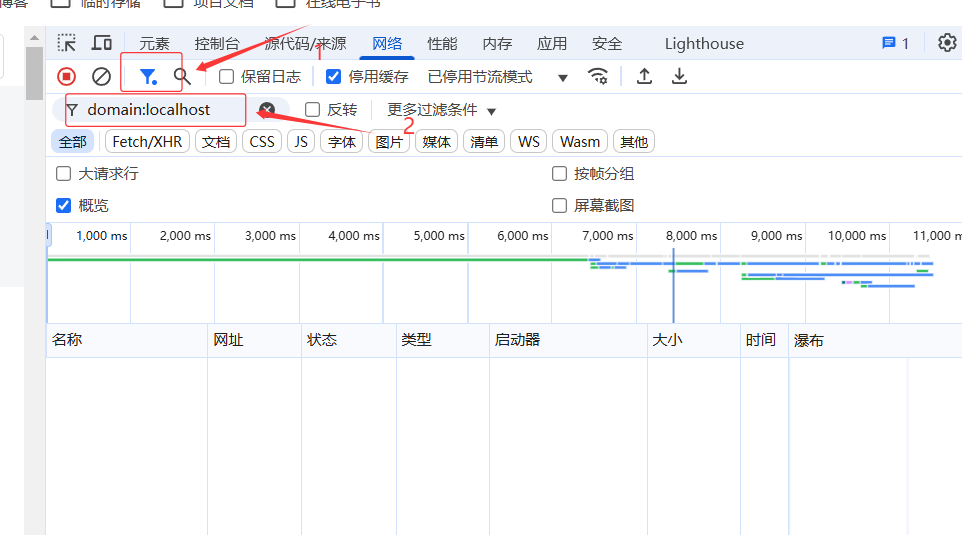
解决方案:删除过滤条件
知识点:
17.java.lang.OutOfMemoryError: Java heap space
**出现原因:**在用户统计的业务中加入以下代码报错
public UserReportVO userStatistics(LocalDate begin, LocalDate end) {
//获取开始日期和结束日期之间的日期列表
List<LocalDate> dateList = new ArrayList<>();
dateList.add(begin);
while (begin.plusDays(1) != end){
begin = begin.plusDays(1);
dateList.add(begin);
}
分析:begin和end都是一个对象,!=运算符只能对基本数据类型进行比较,引用数据类型默认比较其地址,导致无限循环,集合无限扩大,导致堆空间不足!!!
解决方案:修改比较方式,使用方法equals()
2025.2.11
18.插入数据库时,id设置的自增,但是id突然变成一个很大的数字
问题:
分析原因:

这条插入语句是mybatis-Plus生成的,发现id是通过程序传入的,所以我们需要查看mybatis-Plus使用手册
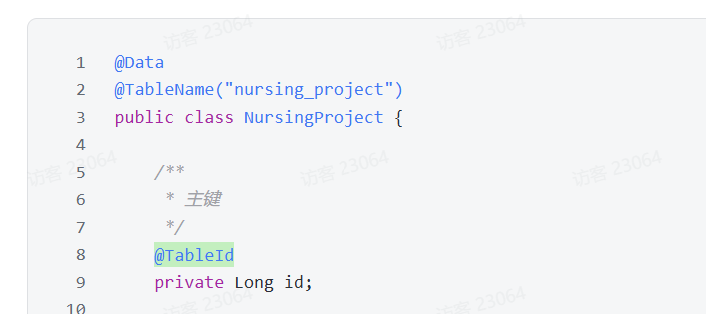
@TableId
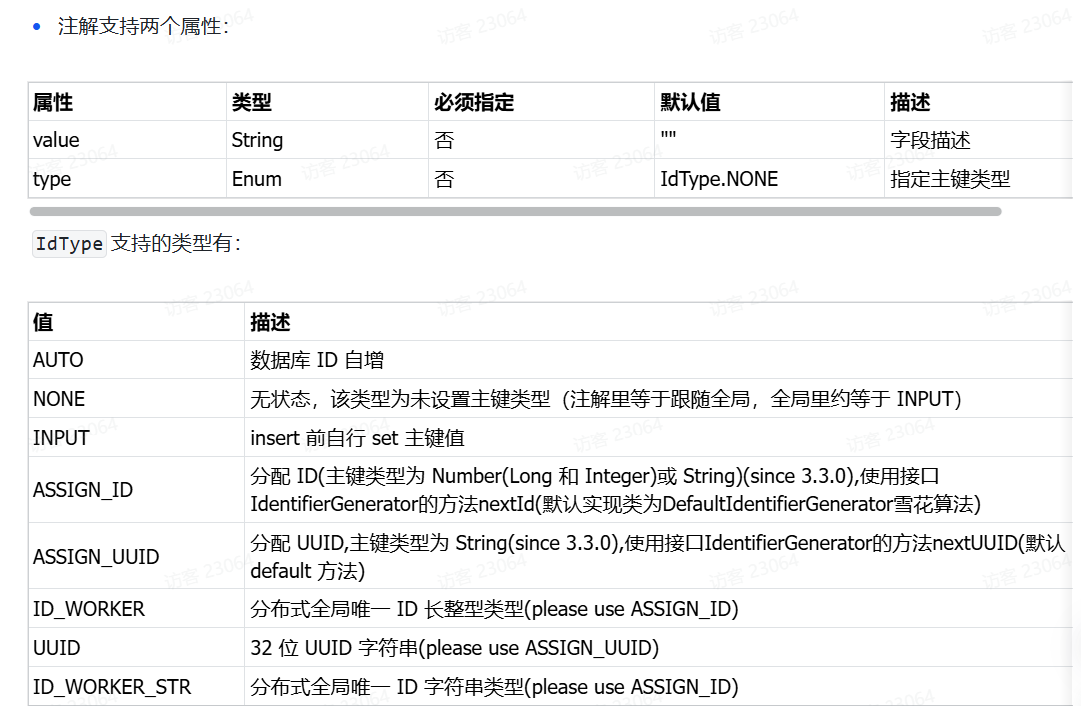

总结:通过设置对实体类属性加上注解**@TableId,**其默认主键类型为type=IdType.ASSIGN_ID,所以在插入的时候会通过雪花算法生成主键id进行插入
这条插入语句是mybatis-Plus生成的,发现id是通过程序传入的,所以我们需要查看mybatis-Plus使用手册。
19.输入文本的时候,英文字符键产生了不必要的空隙
**问题:**输入文本的时候,英文字符键产生了不必要的空隙思路:
先测试在不同的地方进行输入,如果每个地方都有空隙,那就是输入程序的问题。
如果单纯在一个地方输入的时候有问题,我这里是语雀。要么是格式问题,要么是程序自身的bug,所以先尝试使用格式刷进行格式化,不行的话,再采取重启程序基本上就能解决了
20.启动报错
**问题:**启动的时候报了一堆错思路:
三部曲:统一jdk,修改maven路径,刷新maven
如果还有问题:从下往上查找**cause by,**再分析原因去解决
21.后端传Long类型的id,前端js接受后精度丢失,查询回显找不到
解决方案:前端无法处理,后端在传Long类型数据的时候,**将数据转换为字符串**,再进行响应。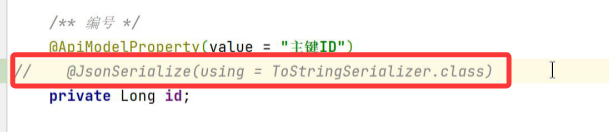
2025.2.12
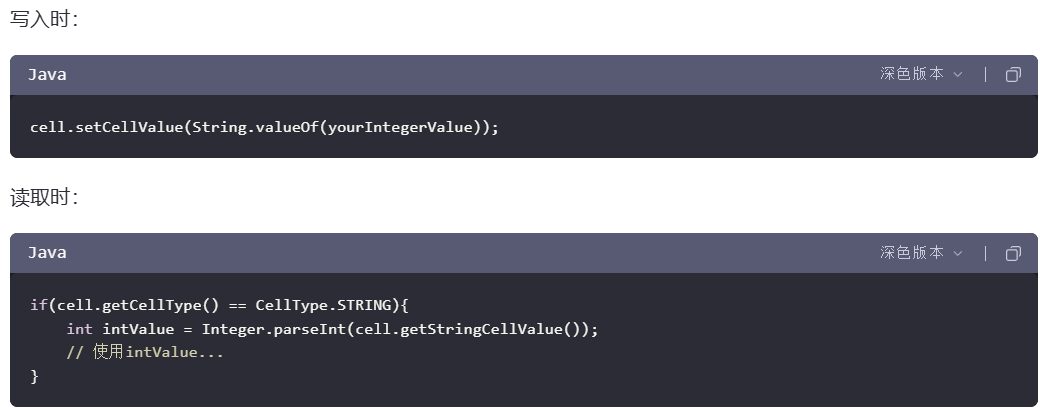
22.java程序使用POI向excel中写入Integer类型数据,再读取变成了Double类型数据,为什么,怎么处理。
当你使用Apache POI向Excel写入数据时,如果写入的是` Integer` 类型的值,默认情况下POI会将其作为数值类型(即Excel中的Number格式)存储在单元格中。当读取这些单元格的数据时,Apache POI可能会将这些数值以` Double` 类型返回,这是因为Excel内部是以浮点数的形式来存储所有数字值的,这导致了即使你写入的是整数,在读取时也可能被解释为` Double` 类型。解决方案:
方案一:可以手动检查单元格的类型,并根据需要进行类型转换

方案二:使用字符串方式写入(推荐)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









