







1)预编译(生成*.i文件)
1>将所有的“#define”删除,并且展开所有宏;
2>处理掉所有条件预编译指令,如:“#if”、“#ifdef”、“#elif”、“#else”、“#endif”;
3>处理“#include”指令,这是一个递归过程;
4>删除所有的注释“//”和“/* */”;
5>添加行号和文件名标识;
6>保留所有的#pragma编译器指令,待编译器使用;
2)编译(生成*.s文件)
把预处理完的文件进行一系列的词法分析,语法分析,语义分析及优化后生成相对应的汇编代码文件。
3)汇编(生成*.o文件,也叫目标文件)
汇编器是将汇编代码转变成机器可以执行的指令,每一个汇编语句几乎都对应一条机器指令。.o文件也叫可重定位的二进制文件
4)链接(生成*.exe文件,也叫可执行文件)
1>地址和空间分配;
2>符号解析;
3>符号重定位;
Windows .obj/.exe PE格式
Linux .o ELF格式
#include<stdio.h>//test.c
int gdata1=10;
int gdata2=0;
int gdata3;
static int gdata4=10;
static int gdata5=0;
static int gdata6;
int main()
{
int a=10;
int b=0;
int c;
static int e=10;
static int f=0;
static int g;
return 0;
}
ELF格式的文件
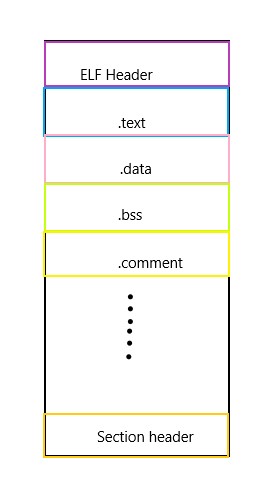
预编译指令:gcc -E *.c -o *.i 生成.i文件
编译指令:gcc -S *.i 生成*.s文件
汇编指令:gcc -c *.s 生成*.o文件 .o文件为可重定位的二进制文件
objdump -h *.o 段(section)信息 objdump -s *.o-----》详细信息
readlf -h *.o ELF头部信息 readlf -s *.o--------》详细信息
objdump -t *.o 符号表

Section header:段表就是保存各个段信息的结构以数组形式存放,段表的起始位置、长度、项数分别由ELF文件头中的start of section headers 、size of section headers、number of section headers指出 。使用 readelf -S *.o查看
这个段保存了目标文件中,每个段的详细信息,包括段的大小、起始偏移等信息。编译器只要访问这个段的详细信息。.bss段虽然不占空间,但是.bss段的详细信息都被保存在Section headers中了

Windows .obj/.exe PE格式
Linux .o ELF格式
ELE header:文件头的信息包括程序的入口位置(由于.o是没有链接的目标文件所以值是0X00)段表开始位置的首字节、段表的长度、段表中的项数,也就是存多少段。。。执行 readelf -h *.o查看

符号表以数组结构保存符号信息 。存放在.data和.bss段的变量都要有一个名称来标识这个变量,这个名称称为符号,存放在符号表中。
强符号:全局的已初始化的符号。
弱符号:全局的 未初始化的符号。
强弱符号的选取规则: 1、两个强符号,编译出错
2、一个强符号、一个弱符号,选择强符号
3、两个弱符号,根据不同编译器处理方式不同
由于一个项目可能有多个源文件,编译段都是每个文件单独编译的,可能在其他文件中存在强符号,所以没办法在编译期间确定具体的符号,因此将本文件的弱符号存放在*COM*
对于引用的外部符号,符号表中是*UND*标志,也就是说这个符号没有具体定义的地方
链接阶段链接器只关注符号表中的全局符号。链接后,对每个符号给出了具体的虚拟地址,并把外部符号放到对应的段中。符号解析和符号重定位就发生在这个过程中
符号解析:在每个文件符号引用(引用外部符号)的地方找到符号的定义,这就是符号解析。
符号重定位:就是对.o文件中,.test段中的无效地址给出具体的虚拟地址或者相对位移偏移量

代码段:
.test保存代码编译后的指令可以用 objdump -s -d *.o查看

数据段:
.data段保存的是已初始化且初始化不为零的数据。使用objdump -x -s -d *.o查看


5)运行:
1>创建内核映射结构体 PCB
2>建立虚拟地址空间到物理内存的映射
3>加载指令和数据
4>把程序的入口地址写入下一行指令寄存器















 1015
1015











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









