






pwn:二进制漏洞挖掘与利用(程序里面的漏洞)
CTF中的Pwn是仅保留漏洞代码和基本逻辑的二进制程序,选手通过自身对漏洞的熟悉程度来快速的在逆向分析中找到漏洞点,并且结合自身对漏洞利用的熟悉程度来编写EXP脚本,从而获得目标机器Shell拿到Flag。
作用
1.)破解,利用成功(程序的二进制漏洞)
2.)攻破(设备,服务器)
3.)控制(设备,服务器)
拿到 进制漏洞 用file命令查看文件
常用语句
exploit(用于攻击的脚本与方案)
payload(攻击载荷,给服务器发送恶意数据使其目标进程被劫持的数据,)
shellcode(调用攻击目标的shell代码)
shell(kali linux里面提供用户与操作系统交互的命令行接口,提供了一个文本接口)
pwn的几大主流漏洞
- 栈溢出
- 堆溢出
- ROP
- 格式化字符串漏洞
- 其余漏洞
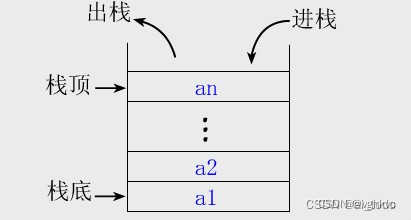
栈
首先是栈,它是一种后进先出(LIFO)的数据结构,在计算机中具有重要的作用。程序在运行时,会将栈用来存储函数的调用栈、内存的分配操作、表达式求值的临时变量以及与程序中的控制流相关的数据。
每当程序执行函数调用、变量声明或其他类型的操作时,都会在栈中添加一个栈帧(Stack Frame),也即是称为堆栈帧,用于存储函数的执行环境。
栈溢出
1. 定义
栈溢出是缓冲区溢出的一种,当缓冲区数据大于缓冲区大小时,缓冲区之外的有用数据就会被多出去的缓冲区数据覆盖改写,从而可能导致程序崩溃。
缓冲区:程序在运行过程中,为了临时存取数据的需要,一般都要分配一些内存空间,通常称这些空间为缓冲区。
2. 原理
栈溢出漏洞在ctf题中常被用来覆盖程序的返回地址,以达到某函数返回(return)时,不再是返回原先的返回函数地址,而是返回到我们为其指定地址的地方。
举个简单的例子就是我们向桌面上的水杯中倒入大量的水,水杯中的水一定会溢出来,并且覆盖到桌面上。水杯就是我们所说的栈缓冲区,水就是我们输入的数据,桌面就是整个栈空间。所以栈溢出漏洞的本质在于对栈缓冲区写入数据的长度没有做校验,可以使得写入长度是任意值,当写入超过缓冲区自身长度的数据后会覆盖其后面的栈空间数据。
堆
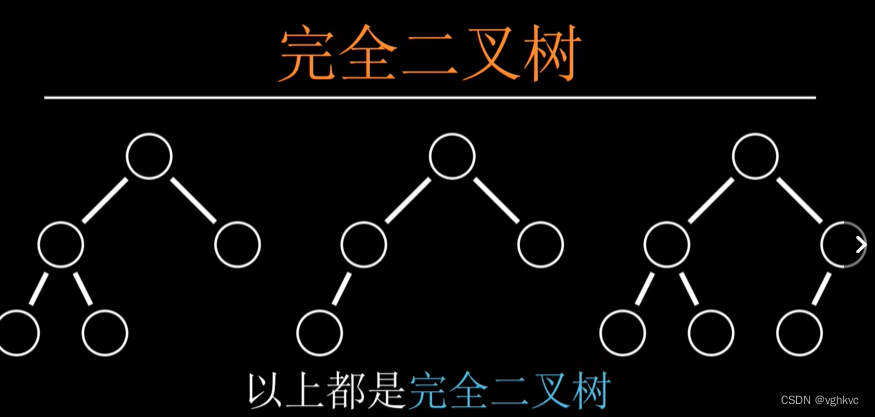
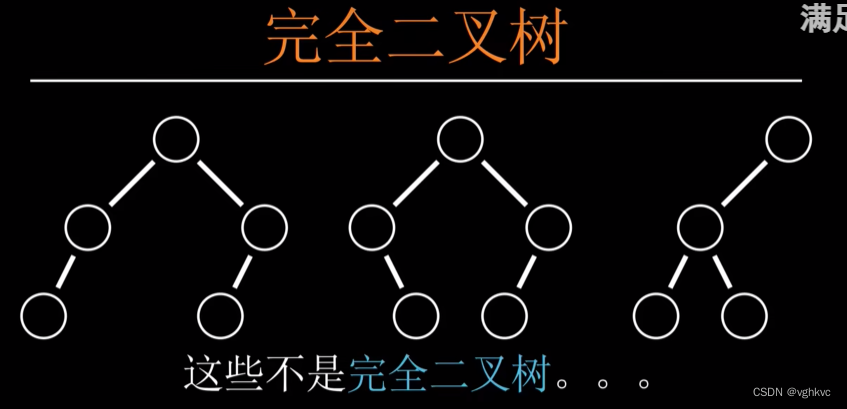
完全二叉树
1.)只允许最后一行不为满
2.)最后一行必须从左往右排序
3.)最后一行元素之间不可以有间隔
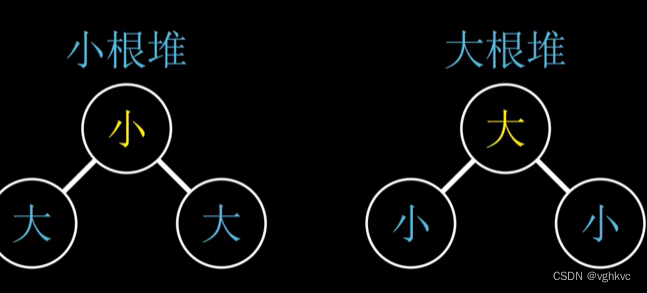
堆的第二性质:堆序性
据此分为大根堆(每个父节点都大于它的子节点) 小根堆(每个父节点都小于它的子节点)
堆的储存
先按照层序遍历的顺序来给结点编号(从上到下 从左到右)把编号对应到数组的下标,然后把数的元素存入相应的下标里,因为是完全二叉树,所以每个下标和树的位置都是一一对应的,一个堆可以用一个一维数组来表述
堆内存是一种允许程序在运行过程中动态分配内存和使用的区域。和栈的主要不同在于动态分配,堆的内存区域是程序运行时申请和释放的。
堆溢出
堆溢出是指程序向某堆块(chunk)中写入的字节数超过了堆块本身可使用的字节数,因而导致了数据溢出,并覆盖到物理地址相邻的高地址的下一个堆块。这里之所以是可使用而不是用户申请的字节数,是因为堆管理器会对用户所申请的字节数进行调整,这也导致可利用的字节数大于等于用户申请的字节数。
ptmalloc 分配出来的大小是对齐的。这个长度一般是字长的 2 倍,比如 32 位系统是 8 个字节,64 位系统是 16 个字节。但是对于不大于 2 倍字长的请求,malloc 会直接返回 2 倍字长的块也就是最小 chunk,比如 64 位系统执行malloc(0)会返回用户区域为 16 字节的块。
因此,要利用堆溢出要满足两个前提
1)程序向堆上写数据;
2)写入的数据大小没有被控制;
对于堆和栈的理解
堆和栈是在程序运行中用于存储数据和指令的两种不同的内存空间,它们都是程序中重要的组成部分。
本质上讲没什么差别 都是内存的一块区域 区别在于用法
栈区
连续内存
变量的使用仅仅局限于函数的内部即这个函数运行完成之后,此变量占用的内存就可以销毁了,这种变量即为局限变量 其占据的内存十分好管理,内存的分配和释放仅仅需要移动一个指针(寄存器)而已。 栈区的内存管理无需程序员担心,因为栈区的内存申请和释放很有规律,遵循先来的后释放(栈的顺序)。
堆区
一个变量的生命周期超越了函数 函数运行完之后 变量占据的内存是不可以被回收的 其内存的生命周期受程序员控制。 堆区中的内存需要精心标记 ,由于进程中的所有线程共享一个堆区 ,堆区内存分配器必须处理好线程安全问题 所以性能比栈区差
成员变量和局部变量
局部变量,如果是基本数据类型,那么就直接存在栈中,如果是引用数据类型(类、接口、数组),比如String str = new String(“12”);,会把对象存在堆中,对象的引用(指针)存在栈中,
成员变量,类的成员在不同对象中各不相同(属性和方法),基本数据类型和引用数据类型都存储在这个对象中,作为一个整体存储在堆中。而类的方法是所有的对象共享的,方法是存在方法区的,只用当调用的时候才会被压栈,不用的时候是占内存的。
区别
(1)在类中的位置不同
成员变量:类中方法外
局部变量:方法定义中或者方法声明上
(2)在内存中的位置不同
成员变量:在堆中
局部变量:在栈中
(3)生命周期不同
成员变量:随着对象的创建而存在,随着对象的消失而消失
局部变量:随着方法的调用而存在,随着方法的调用完毕而消失
(4)初始化值不同
成员变量:有默认值
局部变量:没有默认值,必须定义,赋值,然后才能使用
局部变量基本上是方法的参数。
参考资料:
https://blog.csdn.net/Morphy_Amo/article/details/122323280
https://www.zhihu.com/question/464671097/answer/2816873492
https://blog.csdn.net/m0_49768044/article/details/131391832
https://blog.csdn.net/weixin_45197447/article/details/107390320















 6131
6131

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









