






我们都知道浏览器是要向服务器发出请求资源,而服务器向浏览器返回响应
服务器一般常用的有tomcat,那么我们就以tomcat为列子,首先我们需要知道tomcat服务器打开后下面几个文件夹是干什么
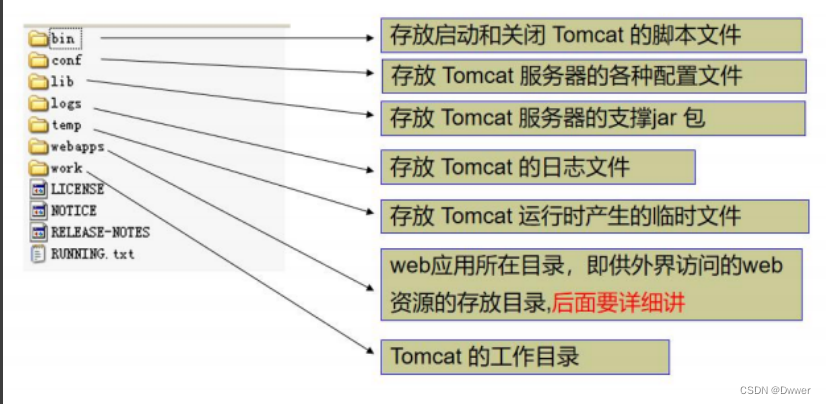
tomcat服务器中的文件介绍
JavaWeb程序/应用/工程目录结构
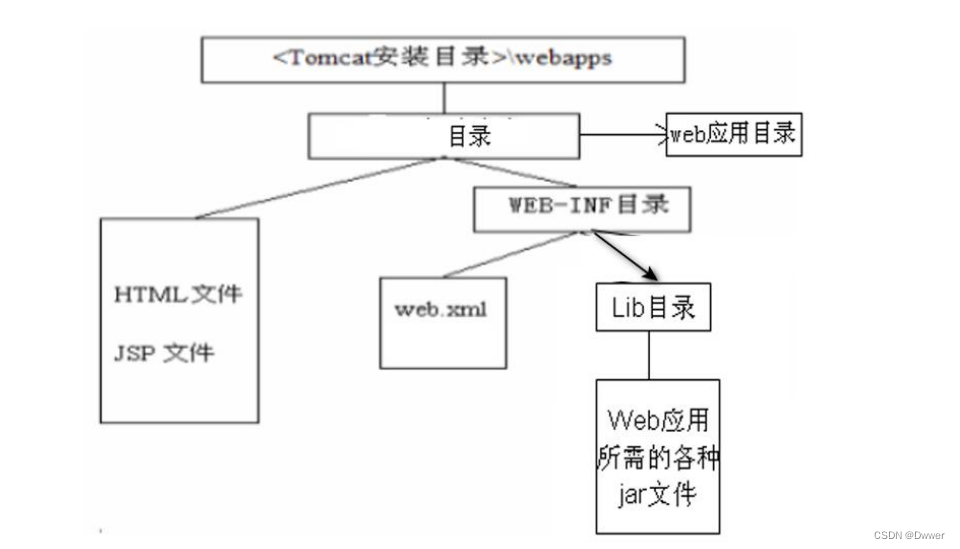
webapps 最为主要,是存放浏览器访问服务器时,服务器返回的静态页面(html,css等)以及要一些java代码。那么静态页面可以直接放入到webapps文件下,那么类似于java代码等该怎么存放呢?而java代码则引发出了一个新的问题,那么就是只要java代码就会有一些配置文件或者jar包,像这类信息该如何存放呢?
所以就有了要在webapps下创建一个WEB-INF目录,用来存放这些jar包或其xml等配置文件,而Lib目录就用来存放java代码或其jar包等之类的
浏览器请求资源的流程分析步骤如下:
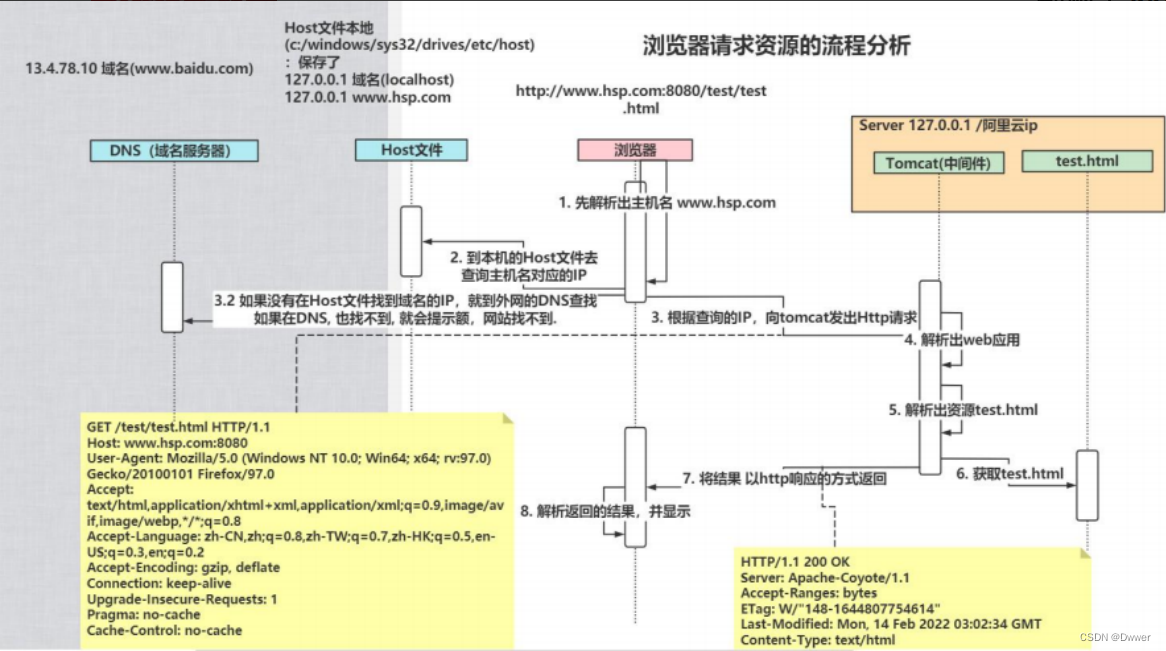
在具备上述一些必备的知识点后,此刻我们才能引出浏览器请求资源的流程分析,以案例我们向浏览器发出一个请求 http://www.htp.com:8080/test/tests.xml
(1)域名解析:浏览器会先将localHost进行一个解析,要先知道localHost的IP地址是什么?
(2) 所以浏览器会先通过本地的host的文件来查找localHost的IP地址是多少?(host的文件地址所在windows/System32/dirves/etc/host)
(3)Host文件如果查找到后,那么此刻浏览器就会将其查找到的IP地址以及端口号,文件目录等向其服务器发出http请求
(4)服务器解析:服务器接收后,也会先进行一个解析,解析web应用(每个web应用其就是一个文件夹)
(5)接着服务器会再次解析,解析其想要访问的是某个资源(也就是文件夹里具体的某个文件)
(6)服务器查找文件目录,并获取到该资源
(7)将其资源以http响应发出给浏览器
(8)浏览器解析:浏览器得到后文件后,会将其解析并渲染显示到其页面
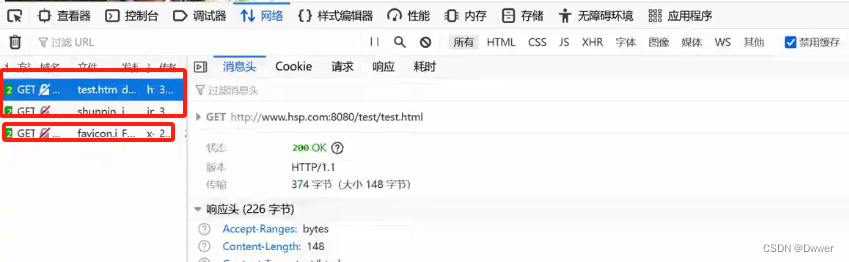
注意:因一个请求只能有一个响应,那么在服务器返回给浏览器的html资源后,是一个文本资源。
浏览器发现其文本内有一个图片,那么就需要再次发出请求,所要图片资源,而服务器此时会将图片资源发出
所以看图片就得出,浏览器其实发出了三次请求,但最后一个请求是url地址旁边的一个图标,没是那么作用,所以就是两次请求,符合一个请求一个响应
浏览器解析返回的响应文本,根据其响应文本中的信息来判断是否要再次发出新的请求















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









