







内容较多分开来写,这样吸收起来也好些,附有练习可学习,下面Shuffle补充
文章目录
1、Shuffle机制
1)Combiner合并 <b,1> <b,1>==<b,2>
(1)combiner是MR程序中Mapper和Reducer之外的一种组件。
(2)combiner组件的父类就是Reducer。
(3)combiner和reducer的区别在于运行的位置:
Combiner是在每一个maptask所在的节点运行;
Reducer是接收全局所有Mapper的输出结果;
(4)combiner的意义就是对每一个maptask的输出进行局部汇总,以减小网络传输量。
(5)combiner能够应用的前提是不能影响最终的业务逻辑,而且,combiner的输出kv应该跟reducer的输入kv类型要对应起来。
Mapper
Maptask1:
3 5 7 ->(3+5+7)/3=5
Maptask2:
2 6 ->(2+6)/2=4
Reducer
(3+5+7+2+6)/5=23/5 不等于 (5+4)/2=9/2
(6)自定义Combiner实现步骤:
a)自定义一个combiner继承Reducer,重写reduce方法。
public class WordcountCombiner extends Reducer<Text, IntWritable, Text,
IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
// 1 汇总操作
int count = 0;
for(IntWritable v :values){
count += v.get();
}
// 2 写出
context.write(key, new IntWritable(count));
}
}
b)在job驱动类中设置:
job.setCombinerClass(WordcountCombiner.class);
2)Combiner合并案例实操
(1)需求
统计过程中对每一个maptask的输出进行局部汇总,以减小网络传输量即采用Combiner功能,如图所示:

(2)数据准备
hello.txt
hello world
bigdata bigdata
hadoop
spark
hello world
bigdata bigdata
hadoop
spark
hello world
bigdata bigdata
hadoop
spark
方案一
a)增加一个WordcountCombiner类继承Reducer。
package com.bigdata.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordcountCombiner extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override//重写父类的reduce方法,在这里实现自己的业务逻辑,在这里统计每个单词出现的总次数
//分组调用,按照key进行分组,如果key一样,则key相同的所有kv,就会在一次reduce方法里面得到调用
protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {
//<hello,1>,<hello,1>,<hello,1>
//将所有的value遍历,进行累加,value全是1,累加后的结果,就是单词出现的总次数
int sum = 0;
for (IntWritable num : values) {
int i = num.get();
sum = sum + i;
}
//将单词总次数封装为keyvalue对写出,即<单词,总次数> <hello,3>
context.write(key, new IntWritable(sum));
}
}
b)在WordcountDriver驱动类中指定combiner。
// 指定需要使用combiner,以及用哪个类作为combiner的逻辑
job.setCombinerClass(WordcountCombiner.class);
方案二
将WordcountReducer作为combiner在WordcountDriver驱动类中指定。
// 指定需要使用combiner,以及用哪个类作为combiner的逻辑
job.setCombinerClass(WordcountReducer.class);
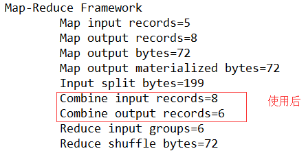
运行程序,如图所示:
未使用前

使用后
3)GroupingComparator分组(辅助排序)
对reduce阶段的数据根据某一个或几个字段进行分组。
partioner是在MapTask阶段将数据写入环形缓冲区中进行的分区操作,其目的是为了划分出几个结果文件(ReduceTask,但是partioner必须小于ReduceTask个数),而是什么决定将一组数据发送给一次Reduce类中的reduce方法中呢?换句话说,Reduce类中的reduce方法中key一样,values有多个,是什么情况下的key是一样的,能不能自定义。其实这就是 GroupingComparator分组(辅助排序)的作用。
4)GroupingComparator分组案例实操
(1)需求
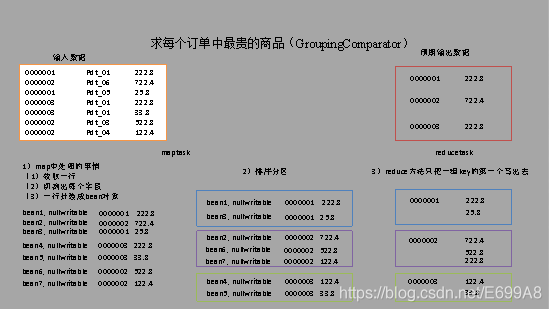
有如下订单数据:

现在需要求出每一个订单中最贵的商品。
(2)输入数据
GroupingComparator.txt
0000001 Pdt_01 222.8
0000002 Pdt_06 722.4
0000001 Pdt_05 25.8
0000003 Pdt_01 222.8
0000003 Pdt_01 33.8
0000002 Pdt_03 522.8
0000002 Pdt_04 122.4
输出数据预期:

(3)分析
a)利用“订单id和成交金额”作为key,可以将map阶段读取到的所有订单数据按照id分区,按照金额排序,发送到reduce。
b)在reduce端利用groupingcomparator将订单id相同的kv聚合成组,然后取第一个即是最大值,如图所示:
(4)代码实现
第一种方法:
package com.bigdata.maxmoney;
import java.io.IOException;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2204
2204











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









