






 文章介绍了ArchSummit全球架构师峰会上关于系统精简、AI多媒体内容审核以及大模型在生产力工具中的应用。去哪儿旅行的冯阳阳分享了如何高效清理线上无用代码,趣丸科技的马金龙探讨了AI在内容审核的实践,美的集团的郭智勇分享了分布式应用运行时的落地经验,而商谈科技的詹明捷则讨论了大模型时代的生产力工具技术探索。
文章介绍了ArchSummit全球架构师峰会上关于系统精简、AI多媒体内容审核以及大模型在生产力工具中的应用。去哪儿旅行的冯阳阳分享了如何高效清理线上无用代码,趣丸科技的马金龙探讨了AI在内容审核的实践,美的集团的郭智勇分享了分布式应用运行时的落地经验,而商谈科技的詹明捷则讨论了大模型时代的生产力工具技术探索。
大家好,我是煎鱼。
最近 ArchSummit 全球架构师峰会在深圳也开展了,以下是我简单记录的一些笔记,有兴趣的同学可以一起看看学习进步。
上篇:《技术大会的学习笔记:AI 大模型落地、AIGC 技术探索等干货》;
本文是下篇。
欢迎大家关注!
系统精简之道-冯阳阳
演进主题:《系统精简之道:如何以极低风险,高效清理线上无用代码》,讲师:马阳阳,去哪儿旅行
这个演讲主题挺有意思,我提前有所关注。内容是:瘦身项目,去除无用代码,业内挺少见,主打极低风险。
业务背景:去哪儿是 2005 年开始做,业务历史悠久,短期业务多(例如:端),人员流动大(互联网特性),容易找不到人。
线上有流量覆盖的代码行只有 40%。
做这个精简项目,成立了虚拟团队来支撑:

整体的步骤,分为:找的到,删的好:


”找得到” 的依据,主要是这两点:没流量和没迭代。
例如: 网关、Trace、定时任务。Config 等。(可以理解为所有能证明你这个项目还在跑的依据,基本就是依赖的识别使用)
真正下线时做了个灰度流程,人工确认,不接流量。服务下线,再真正回收等。
对应的精简代码的核心特征分析:
未被引用的方法(静态)
没有流量的方法(运行时)
重构
“找得到” 方案的最终选型:

核心是基于 Java 语言的 SA 工具,JVM 内有记录了方法的执行次数,SA 工具有提供对应的 JAR 用来获取。
实际上 SA 计数,会跑三个月,每次服务迭代发布,都是在跑统计的。对老的 Pod (上个迭代的老版本服务)进行计数,不会影响到新的 Pod(新迭代新上的服务版本)。
注:超过三个月都没有跑的,确实很难避免。但是基本不会出现 P1、P2 的事故。SA 工具理论上跑的越久越好。
“删得好” 的多种手段:

全自动这个很好理解;半自动是提供了 IDE 插件来识别和提醒,便于人工介入。
真正删完上线,最佳实践是根据服务、包的重要程度等选择了不同的删除手段和建议。这个结合自己实际公司行情就可以了。
一张图总结概括:

粗略总结:
这个项目,感觉上级给了很大的支撑,否则这种事情,还是比较折腾的,也很容易出事故。
技术思路上,主要就是调用 SA 工具的方法技术群 MethodCount 来得到调用次数,接着就是对应的业务逻辑处理和灰度策略了。
目前仅适用于 Java 项目,如果有其他语言的,也可以参考思路来解决。
AI 多媒体内容审核
演进主题:《AI多媒体技术在内容审核场景实践探索》,讲师:马金龙,趣丸科技
这个演讲主题,和大家最近遇到的挺相关,因为 AIGC 出现了后,很多应用需要受到很多的要求,要做内容审核。否则很容易翻车。特意看看思路和行业情况如何。
当前内容审核要求很多、种类多样、挑战多多、AI 幻觉多多、较为不可控。
设计上是基于 ASR(Automatic Speech Recognition,语音识别)的架构,也就是基于语义,预训练。提前训练好。用 NLP 做。技术路径和以往的差不多。

异常特别的场景,还是会找一些渠道找到数据,或者考虑 AIGC 来生成:

给出的数据来看,普遍多维度的检测成功率都在 91% 以上,准确度据描述已经比较高了。
未成年人的识别率达到 99%,从表述来看,针对用户行为、动作、语义等多个方面都做了综合判别。根据描述是公司核心能力之一,拿了许多奖,没有具体举例说明。主打一个描述。
声音识别上,主要可以识别声音的事件,例如唱歌、说唱等。识别声音事件、类型、语义。能做到比较好的识别结果。对于不同语种,主要是基于模型训练,也做微调,拿到不同的标签等。
歌曲识别,识别人声指纹。就能很好的捕获到不合规的艺人、语录等。
识别的关键词基本是:语义、行为、声纹、事件等。
提问有同学问到:AIGC 文生文,文生图的内容审核安全问题。也是我去听时较关注的问题之一。
主要是通过以下方面来解决:
丰富语义库,针对多个模型进行给出判定。只是尽可能提高准确率。
针对不同的模型,要做特定的数据组预训练,提高垂直领域的准确率。
针对文生图的,建议对输入进行限制,保证是可以的。其次也是上述的图书垂直训练的问题。
结论上来说只能提高识别率,没有完美的方案。
粗略总结:
给出的数据各方面都非常亮眼,行业发展的感觉有一定成熟度了。不过没有看到实际的演示例子,比较可惜。
针对 AIGC 侧,确实有许多新的不确定性(涉及多模态)。主要也是要靠增加数据做预训练,来提高准确率。没有一劳永逸的办法。当然,AIGC,从输入侧就开始限制是最好的。
这个话题比较敏感,安全第一。
分布式应用运行时的落地实践
演进主题:《分布式应用运行时的落地实践》,讲师:郭智勇,美的集团
业务场景主要是物联网,有不同的连接类型,海量的家电,存量很多很大,连接会越来越多。
很容易出现异常场景,例如:只要有一个批次出问题,设备终端就会批量重建。压力会很大。
另外为了合规要求,需要在各地快速部署。如果在系统上引入了云厂商,就会很麻烦。希望依赖越少越好。
解决思路:采取业务运行时和技术运行时分离:

主体就是 Dapr 的解决思路,基于此加了一层,隔离了所有的可能变更,要改也是直接改技术运行时,不需要动到终端的业务运行时。
多泳道是靠 Dapr 做的服务间的环境调用(二开扩展了能力,mdns),由于成本问题,多泳道只分了三个固定环境。
后面篇幅内容主要就是讲解基于 Dapr 的二次开发适配了,有兴趣的可以找网上对应的资料阅读。
粗略总结:比较经典的一个技术解决思路。
大模型时代——生产力工具转型的技术探索
演进主题:《大模型时代——生产力工具转型的技术探索》,讲师:詹明捷,商谈科技
这个主题和内容都比较接地气,讲师也非常的有技术激情,观感挺不错的。有兴趣的同学可以仔细查看。
AGI 的发展历史:
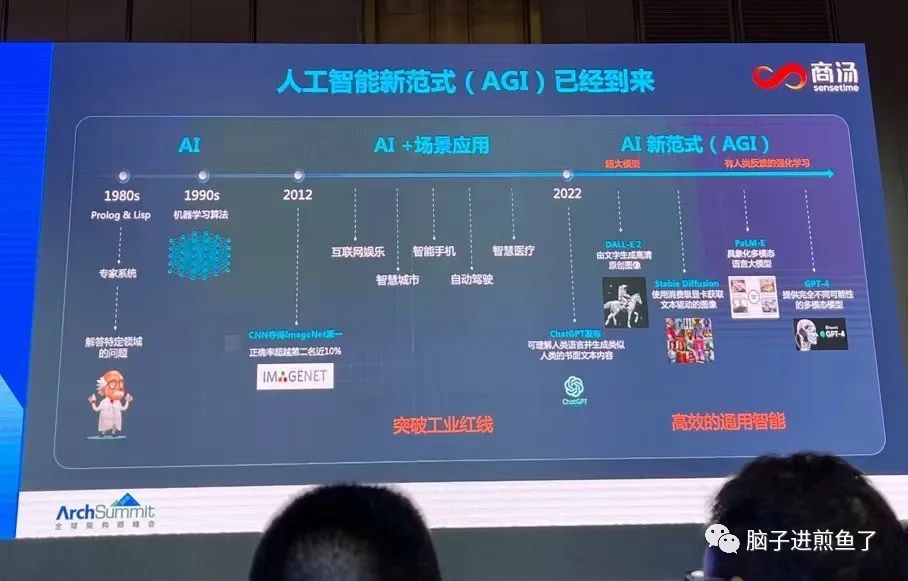
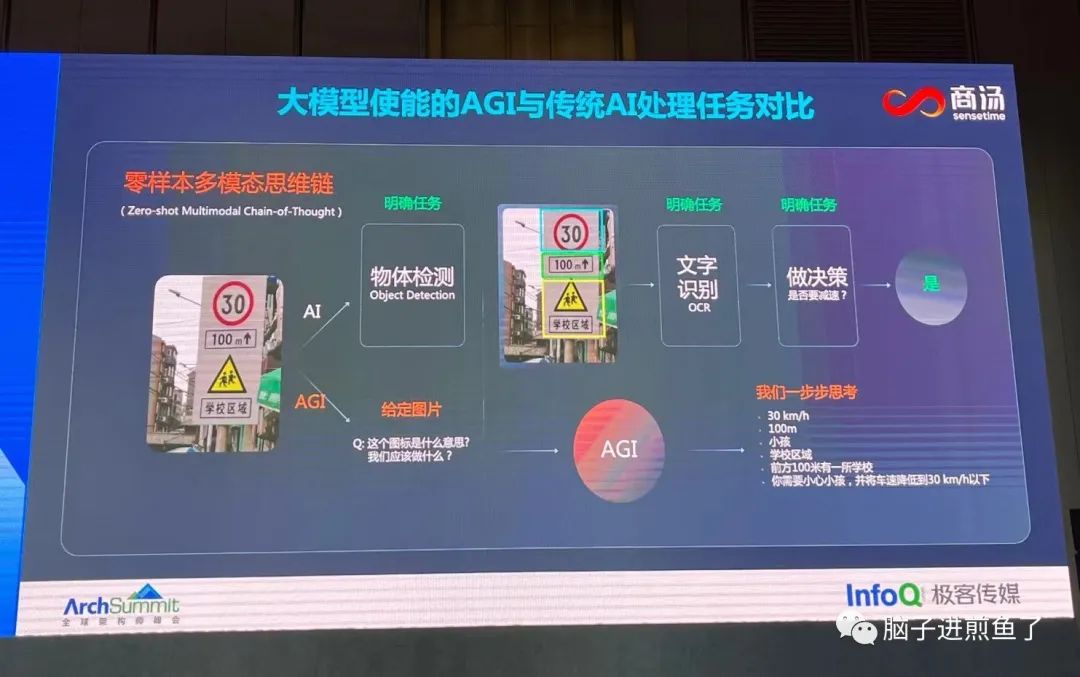
AGI 和传统 AI 的区别:
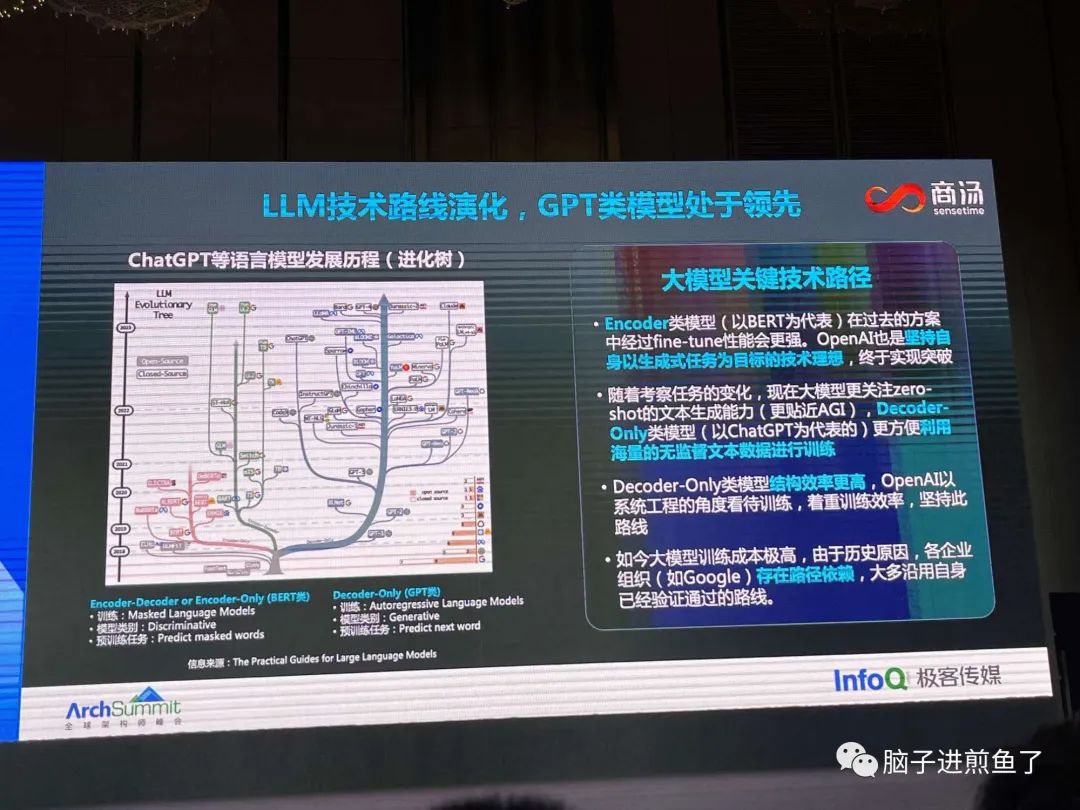
LLM 近几年的演进路线,GPT 这两年异军突起:
讲师提了一个很值得大家思考的问题:模型是越大更好?还是用好数据更好?

讲师认为应当是:做好一个模型,用好数据才是关键。(不是指的单纯的去扩大数据集)
也提到 NLP 这几年都是围绕在怎么用好数据,而不是数据用多大。
NLP 最近三年最大的进展:思维链,多任务学习,指令微调(很眼熟,这就是我们使用大模型时经常用到的)
后续讲师主要分享了 AI 代码助手相关的,因为他是负责这一块的。提出了一个问题:如何让语言模型做好一个代码生成?
关键之一是要做到软件开发上的流程和交互让模型知道和主动询问,而不是一轮就解决。这样精准度可能不会太高。
就跟和产品经理的沟通一样。要有分析师,分步实现,才形成完整的代码,最后要有测试员(让自我 debug)

可以让大模型做三个角色,每个 “人” 做不同的分工。
可以让模型自己做 debug,再调整,再输出。精准度会更高。集成到了 IDE 插件中,使用起来会更方便。
认为 Function Calling 是后续机器人的未来,深入到各行各业。例如机器人需要和很多 API 打通,这是大模型没法直接做到的。
有提问提到会不会像终结者一样。讲师认为大模型已经有一点意识了,不过现在是受限的。
粗略总结:
模型不一定是越大越好,用好数据才是关键之一。(提问时有同学提到,似乎有所争议)
可以对大模型做流程设计时一样,分饰多角,多轮询问,互相 debug。提高最终生成的准确率。
NPL 近年的核心进展:思维链,多任务学习,指令微调。在本次 GPT 发展中也起到了非常关键的作用。
讲师的公司感觉给到了足够大的底气支撑,全场没有提到关于任何业务 ROI 的营收压力。非常的有技术热情了。
关注和加煎鱼微信,
一手消息和知识,拉你进技术交流群👇


你好,我是煎鱼,出版过 Go 畅销书《Go 语言编程之旅》,再到获得 GOP(Go 领域最有观点专家)荣誉,点击蓝字查看我的出书之路。
日常分享高质量文章,输出 Go 面试、工作经验、架构设计,加微信拉读者交流群,和大家交流!

















 5256
5256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









