






做项目时碰到一个不容易注意到的问题,幸亏及时看出来了,不然项目做完才发现,怕是会酿成大错。。特此记录一下改正的过程,希望能够引以为戒。
项目细节就不赘述了,就简单讲一下遇到的这个问题:
文件命名
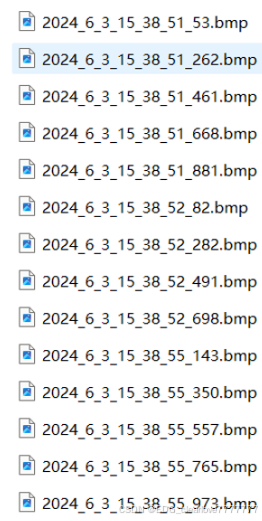
文件命名格式:年_月_日_时_分_秒_毫秒,是每隔200毫秒的文件命名,在Windows文件夹中按名称排序如下所示:
目的
按时间顺序读取这些文件,说白了就是要对这些文件按照时间顺序进行正确排序,用前三个文件为例,['2024_6_3_15_38_51_53.bmp','2024_6_3_15_38_51_262.bmp','2024_6_3_15_38_51_461.bmp'],先进行读取,然后输出排序后的列表。
root_dir=r'D:\6'
img_list = os.listdir(root_dir) #读取文件夹里的文件,生成列表
print(sorted(img_list))#输出排序后的结果
初看看不出什么不对,但仔细去看,前面时间都是相同的,看最后边的毫秒位,分别是262、461、53,正常理解应该是53、262、461,但用sorted()排序输出的结果却是262、461、53!!!
原因
Python的按文件名排序sorted()并没有考虑到整体,是一位数一位数进行排序的,5>4>2,所以排序的结果是262、461、53,但按人所认知的数字大小来应该是53、262、461。
解决方法
定义一个函数extract_numbers(),提取所有的数字部分,并将它们作为整数列表返回,这样就可以按整体的数字进行对比排序,而不是之前的sorted()按单一位数对比,所以在sorted()函数中以此为标准进行排序。
def extract_numbers(filename):
base_name = filename.rsplit('.', 1)[0]
numbers = [int(part) for part in base_name.split('_') if part.isdigit()]
return numbers
root_dir=r'D:\6'
img_list = os.listdir(root_dir)
print(sorted(img_list, key=extract_numbers))#输出排序结果
输出结果如上所示,可以看到这才是正常人所认知的排序结果,53、262、461。
总结
写代码时候还是得认真仔细,到处都是细节,任何一个地方的细节有问题,都会影响到后续的结果,幸好及时发现了问题,早发现问题还是比项目快做完了才发现好啊。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









