







专有名词
| Cluster | 集群 |
|---|---|
| Node | 单个ES实例 |
| Document | 文档,索引或搜索的最小数据单元 |
| Type | 类型,类型是文档的逻辑容器, 类似于表是行的容器 |
| Index | 索引,在 Elasticsearch 中, 索引是文档的集合 |
| Shard | 分片 |
| Replica | 副本 |
| Mapping | 类似于数据库中的表结构定义 schema |
| 倒排索引 | 建立的是分词(Term)和文档(Document)之间的映射关系 |
| Analysis | 分词,是一个概念,将全文本转化为单词的一个文本分析过程 |
| Analyzer | 分词器,es有很多内置的分词器,中文比较常用的就是IK |
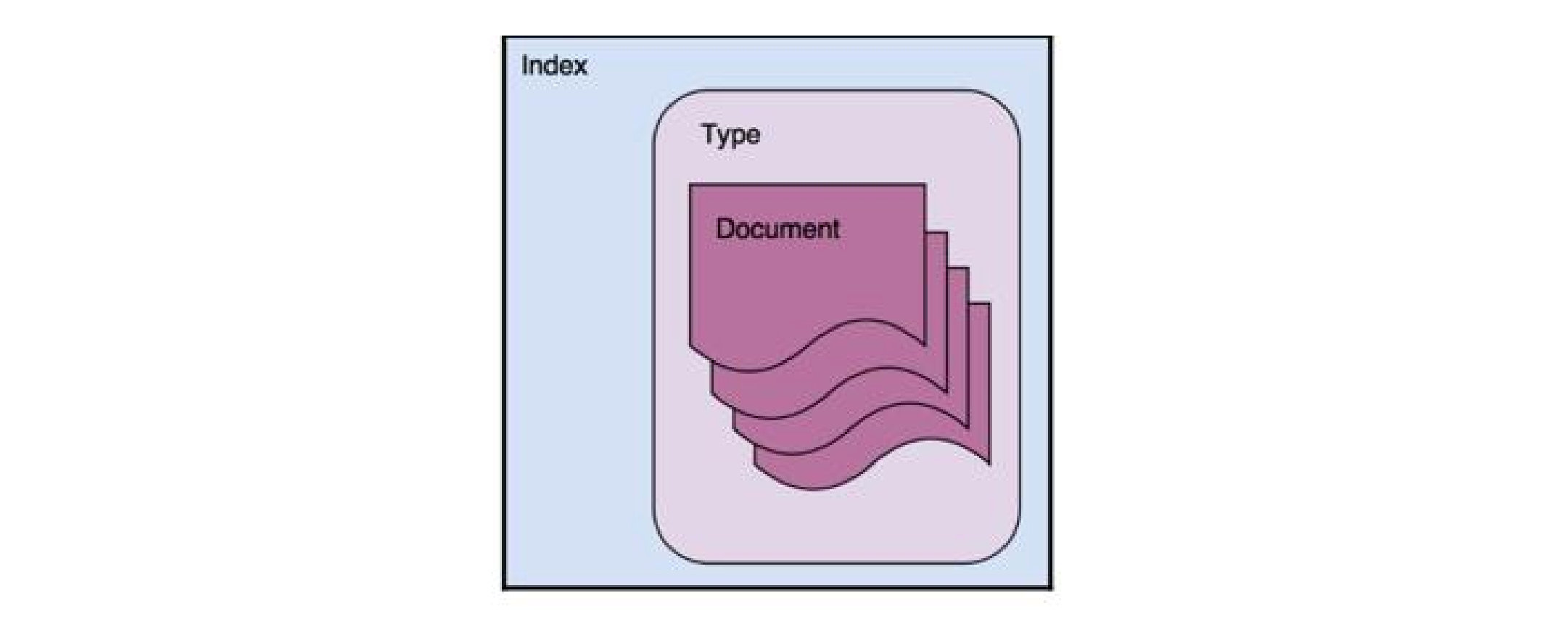
Document - 文档
文档在es中有一些重要的属性:
1、文档是独立的,文档包含字段(名称)及其值
2、文档是可以分层的。可以将其视为文档中的文档,还可以包含其他字段和值,例如, 位置字段可能包含
城市和街道地址
3、机构灵活,Json的数据格式
4、对比传统关系型数据库,es中的文档就相当于数据库的一行数据
Type - 类型
类型是文档的逻辑容器, 类似于表是行的容器
在未来 8.0 的版本中, type 将被彻底删除
Index - 索引
在 Elasticsearch 中, 索引是文档的集合。
index 类似于关系数据库中的 database,我觉得更像是一张表
Shard - 分片
分片有两个非常重要的属性:
1、允许你水平分割/扩展你的内容容量
2、允许你在分片(潜在地, 位于多个节点上) 之上进行分布式的、 并行的操作, 进而提高性能/吞吐量
有两种类型的分片: Primary shard 和 Replica shard
Replica - 副本
默认情况下, Elasticsearch 为每个索引创建一个主分片和一个副本。 这意味着每个
索引将包含一个主分片, 每个分片将具有一个副本
Mapping - 映射
模式定义,有以下几个作用:
- 定义索引中的字段的名称
- 定义字段的数据类型,比如字符串、数字、布尔
- 字段,倒排索引的相关配置,比如设置某个字段为不被索引、记录 position 等
在 ES 早期版本,一个索引下是可以有多个 Type ,从 7.0 开始,一个索引只有一个 Type,也可以说一个 Type 有一个 Mapping 定义。
一文搞懂 ElasticSearch 之 Mapping:https://baijiahao.baidu.com/s?id=1661467987954314526&wfr=spider&for=pc
ElasticSearch 映射(mapping):https://www.jianshu.com/p/7b2dd5382a5f
创建索引妙招:
卸磨杀驴法创建索引的语句相对比较复杂,而且容易出错,所以一般建议创建索引使用
卸磨杀驴法,简单的说就是利用es的特性,我们在不设置mapping的情况下,创建一个文档,由es来推断生成mapping映射关系,然后按照我们的需求再做出一些微调,具体操作步骤如下:# 创建一个临时文档 POST /user_temp/_create/1 { "name": "zhangsan", "age": 18, "isCoder": "true" } # 查看mapping GET /user_temp/_mapping # 拿到mapping后对字段约束做调整,再创建正式的索引,设置mapping PUT /users { "mappings" : { "properties" : { "age" : { "type" : "long" }, "isCoder" : { "type" : "boolean" }, "name" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } } } } } # 插入数据 POST /users/_create/1 { "name": "zhangsan", "age": 18, "isCoder": "true" } # 查看mapping GET /users/_mapping
倒排索引
es把文档数据写入到倒排索引(Inverted Index)的数据结构中,倒排索引建立的是分词(Term)和文档(Document)之间的映射关系,在倒排索引中,数据是面向词(Term)而不是面向文档的
ES:倒排索引、分词详解:https://juejin.cn/post/6844904146710036488
Analysis - 分词
analysis由三部分组成:
- Character Filter:将文本中的html标签剔除掉
- Tokenizer:按照规则进行分词,英文的规则一般是按照空格分词
- Token Filter:去掉停顿词(a、an、the、in、等等),然后再转成小写
除了在数据写入的时候会对词条进行分词处理,同样,在查询的时候也会使用分词器对我们需要查询的关键字进行分析
Analyzer - 分词器
es内置的分词器:
| 分词器名称 | 处理过程 |
|---|---|
| Standard Analyzer | 默认的分词器,按词切分,小写处理 |
| Simple Analyzer | 按非字母切分(符号被过滤),小写处理 |
| Stop Analyzer | 停用词过滤(a、an、the、in等等),小写处理 |
| Whitespace Analyzer | 按照空格切分,不转换小写 |
| keyword Analyzer | 不分词,直接用输入当输出 |
| PatternAnalyzer | 正则表达式,默认是\W+(非字符串分隔) |
可以使用下面的命令查看分词器具体的分词计划
GET _analyze { "analyzer": "standard", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." }中文有关的分词器:ik_analyzer、like_pinyin_analyzer、prefix_pinyin_analyzer、full_pinyin_analyzer、CJKAnalyzer、SmartChinieseAnalyzer
es基础命令
添加索引
PUT /{index}/_doc/{id}
具有幂等性,如果原有的索引已经存在,再次put会报错(一个index+id的组合,组成了一个唯一资源);put方法在es中的两个作用:
1、添加索引
2、完全覆盖
添加索引
POST /{index}
不具有幂等性,对同一命令多次操作,会产生不一样的结果;es会自动生成一个id;post方法在es中的两个作用:
1、添加索引
2、局部更新
获取索引
GET /{index}/_doc/{id}
具有幂等性
删除索引
DELETE /{index}
查看所有索引:显示简化信息
GET _cat/indices

Elasticsearch-Cat命令详解:https://blog.csdn.net/qq_28988969/article/details/105079476
查看映射
GET /es_jd_goods/_mapping # 类似于查看数据库表结构
空索引
GET _search
-- 查询字段name,值包含java的文档,从第一个文档开始,查出2个
GET /_search
{
"query": {
"match": {
"name": "java"
}
},
"from": 0,
"size": 2
}
返回结构分析:
- took:耗时,以毫秒为单位
- timed_out:是否超时
- _shards:分片信息,
- hits:
返回结果中最重要的部分,包含所查结果的前10个文档,包含文档总数total,包含_index、_type、_id,加上_source字段
对文档的CRUD
以下索引 xxx 只为演示
查看 xxx 下的所有数据
GET /xxx/_search
查看 xxx 的总条数
GET /xxx/_count
根据指定 id = 123 查询
GET /xxx/_doc/123
不指定id进行数据插入(不推荐)
POST /users/_doc
{
"firstName": "sun",
"lastName": "jiujiayi"
}
指定id进行数据插入(不推荐)
POST /users/_doc/1
{
"firstName": "sun",
"lastName": "dudu"
}
注意:上面两种数据插入方式不推荐使用,因为如果id重复,文档将被覆盖,这有一定的数据风险
指定id进行数据插入(推荐)
POST /users/_create/1
{
"firstName": "jack",
"lastName": "ma"
}
使用
_create这种方式创建文档,如果id重复,会进行错误提示,并不会直接覆盖现有的文档数据
修改指定id的文档
POST /users/_update/2
{
"doc": {
"age": 38
}
}
对于文档的 增加、修改,
post和put用法是一样的
批量插入数据
POST /users/_bulk
{"index":{"_id":1}}
{"user":"xxx","pwd":"xx-xx"}
{"index":{"_id":2}}
{"user":"aaa","pwd":"aa-aa"}
{"index":{}}
{"user":"ddd","pwd":"dd-dd"}
{"index":{"_id":3}}
{"user":"fff","pwd":"ff-ff"}
批量查询数据
GET _mget
{
"docs":[
{"_index":"users", "_id":1},
{"_index":"users", "_id":2},
{"_index":"users", "_id":3}
]
}
URI查询
查询索引 es_jd_goods中保包含 elasticsearch的所有文档
GET /es_jd_goods/_search?q=elasticsearch
查询指定索引,字段:name包含java的所有文档(以下两个语句的语义是相同的)
GET /es_jd_goods/_search?q=java&df=name
GET /es_jd_goods/_search?q=name:java
查询指定索引,字段:name包含java和elasticsearch两个关键字的所有文档(满足其中之一即可,类似sql中的 or )
GET /es_jd_goods/_search?q=name:java elasticsearch
查询指定索引,字段:name包含java并且不包含elasticsearch的所有文档(加号【+】表示包含,减号【-】表示不包含)
GET /es_jd_goods/_search?q=name:(+java -elasticsearch)
查询指定索引,字段:name既包含java又包含elasticsearch的所有文档(必须同时满足,类型sql中的and)
注意:语句中的 AND 关键字,这个关键字必须大写,大小写所得到的结果差异很大
GET /es_jd_goods/_search?q=name:(java AND elasticsearch)
查询指定索引,字段 name 包含 java、基础,并且java和基础不能分开
GET /es_jd_goods/_search?q=name:"java 基础"
分页查询:从第5页开始,每页3条
GET /es_jd_goods/_search?q=name:"网络"&from=15&size=3
查询指定索引,字段 price 小于等于 50的所有文档
GET /es_jd_goods/_search?q=price:<=50
范围区间查询,查询指定索引,字段price 大于等于50并且小于等于60的所有文档
GET /es_jd_goods/_search?q=price:[50 TO 60]
通配符查询
GET /es_jd_goods/_search?q=name:ja?
GET /es_jd_goods/_search?q=name:ja*
注意,通配符星号【*】和问好【?】有着很大的区别,问好只能代替一个字符,而星号可以代替任意个数的字符
RequestBody 查询 (重点)
全文匹配查询 - match
GET /es_jd_goods/_search
{
"_source": ["name", "price", "shopName"],
"query": {
"match": {
"name": "java 核心"
}
},
"sort": [
{
"price": {
"order": "desc"
}
}
]
}
区间查询 - range
GET /es_jd_goods/_search
{
"query": {
"range": {
"price": {
"lte": 100,
"gte": 50
}
}
}
}
区间查询适用于整数、浮点数类型的索引
- gt - 大于
- gte - 大于等于
- lt - 小于
- lte - 小于等于
精确查询 - term
GET /es_jd_goods/_search
{
"query": {
"term": {
"name": {
"value": "java基础"
}
}
},
"from": 0,
"size": 5
}
在es中,term和match是两个很常用的搜索,区别在于term在查询时,对于查询关键字不做分词处理,而match会对关键字进行分词
es中term和match的区别:https://www.jianshu.com/p/0f424f19d945
如果想精确匹配多个关键词,可以使用terms
组合查询 - bool
{
"bool": {
"must": { "match": { "title": "how to make millions" }},
"must_not": { "match": { "tag": "spam" }},
"should": [
{ "match": { "tag": "starred" }}
],
"filter": {
"range": { "date": { "gte": "2014-01-01" }}
}
}
}
- must - 文档 必须 同时匹配这些条件才能被包含进来,会算分
- must_not - 文档 必须同时不匹配这些条件才能被包含进来,不会算分
- should - 如果满足这些语句中的任意语句,多条件的或,会算分
- filter - 必须 匹配,但它以不评分、过滤模式来进行。这些语句对评分没有贡献,只是根据过滤标准来排除或包含文档
使用constant_score提高查询效率
GET /es_jd_goods/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"name": "java"
}
}
}
}
}
利用constant_score将查询转换成一个filter,可以避免算分,同时可以使用缓存,提高搜索效率
constant_score 只能使用term查询,不能使用match查询
模糊查询 - fuzzy
GET /es_jd_goods/_search
{
"query": {
"fuzzy": {
"name": {
"value": "elasticsearch",
"fuzziness": 1
}
}
}
}
fuzzy,准确的说可以理解为联想查询,如果value的
elasticsearch输入错误,变成了elasticsearhc,结果并不会有什么影响,这和fuzziness参数有直接关系,值:1 表示对查询的字符串做出一次调整,而这个调整是针对字符来说,也就是可以有一次字符换位的机会,注意:fuzziness 的值并不能无限的增大,比如设置为10,可以调整10次,因为每一次调整都会消耗资源,所以es规定 fuzziness的值范围只能是 0-2
es核心简单字段类型
Elasticsearch 支持如下简单字段类型:
- 字符串: text, keyword
- 整数: byte, short, integer, long
- 浮点数: float, double
- 布尔型: boolean
- 日期: date
Text
text 类型字段的最重要属性是分析器 analyzer, 默认 Elasticsearch 使用standard 分析器, 但你可以指定一个内置的分析器替代它, 例如 whitespace 、simple 、 english、 cjk
{
"message": {
"type": "text",
"analyzer": "cjk"
}
}
注意:如果es推断得到文档的字段属性是text,mapping中es会为这个字段创建一个子属性keyword并且值是keyword,而keyword不论是在数据写入,还是查询的时候都不会走分词,必须完全匹配而且是大小写敏感
GET /user_temp/_mapping { "user_temp" : { "mappings" : { "properties" : { "age" : { "type" : "long" }, "isCoder" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "name" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } } } } } }
Java API - High Level REST Client 基础操作
创建索引
public class Ex_doc_insert {
public static void main(String[] args) throws Exception {
// 创建客户端
RestHighLevelClient esClient = Es_demo.getEsClient();
// 创建文档
User user = new User("zhangsan", 18, "男"); // 准备数据
IndexRequest request = new IndexRequest();
request.index("es_test_user"); // 指定索引
request.id("1001"); // 指定id
request.source(JSON.toJSONString(user), XContentType.JSON); // 设置文档数据,必须是json格式
IndexResponse response = esClient.index(request, RequestOptions.DEFAULT);
System.out.println("响应结果:" + response.getResult());
// 关闭客户端连接
esClient.close();
}
}
删除索引
public class Es_index_delete {
public static void main(String[] args) throws Exception {
// 创建客户端
RestHighLevelClient esClient = Es_demo.getEsClient();
// 删除索引
DeleteIndexRequest request = new DeleteIndexRequest("es_demo_index1");
AcknowledgedResponse response = esClient.indices().delete(request, RequestOptions.DEFAULT);
System.out.println("响应结果:" + response.isAcknowledged());
// 关闭客户端连接
esClient.close();
}
}
获取索引
public class Es_index_search {
public static void main(String[] args) throws Exception {
// 创建客户端
RestHighLevelClient esClient = Es_demo.getEsClient();
// 获取索引
GetIndexRequest request = new GetIndexRequest("es_demo_index1");
GetIndexResponse response = esClient.indices().get(request, RequestOptions.DEFAULT);
System.out.println("别名:" + response.getAliases());
System.out.println("索引结构:" + JSON.toJSONString(response.getMappings()));
System.out.println("配置:" + response.getSettings());
// 关闭客户端连接
esClient.close();
}
}
创建文档
public class Ex_doc_insert {
public static void main(String[] args) throws Exception {
// 创建客户端
RestHighLevelClient esClient = Es_demo.getEsClient();
// 创建文档
User user = new User("zhangsan", 18, "男"); // 准备数据
IndexRequest request = new IndexRequest();
request.index("es_test_user"); // 指定索引
request.id("1001"); // 指定id
request.source(JSON.toJSONString(user), XContentType.JSON); // 设置文档数据,必须是json格式
IndexResponse response = esClient.index(request, RequestOptions.DEFAULT);
System.out.println("响应结果:" + response.getResult());
// 关闭客户端连接
esClient.close();
}
}
查询文档
public class Ex_doc_get {
public static void main(String[] args) throws Exception {
// 创建客户端
RestHighLevelClient esClient = Es_demo.getEsClient();
// 查询文档
GetRequest request = new GetRequest();
request.index("es_test_user");
request.id("1001");
GetResponse response = esClient.get(request, RequestOptions.DEFAULT);
System.out.println(response.getSourceAsString());
// 关闭客户端连接
esClient.close();
}
}
更新文档
public class Ex_doc_update {
public static void main(String[] args) throws Exception {
// 创建客户端
RestHighLevelClient esClient = Es_demo.getEsClient();
// 修改文档(局部修改)
UpdateRequest request = new UpdateRequest();
request.index("es_test_user"); // 指定索引
request.id("1001"); // 指定id
request.doc(XContentType.JSON, "username", "sisi"); // 设置文档数据,必须是json格式
UpdateResponse response = esClient.update(request, RequestOptions.DEFAULT);
System.out.println("响应结果:" + response.getResult());
// 关闭客户端连接
esClient.close();
}
}
删除文档
public class Ex_doc_delete {
public static void main(String[] args) throws Exception {
// 创建客户端
RestHighLevelClient esClient = Es_demo.getEsClient();
DeleteRequest request = new DeleteRequest();
request.index("es_test_user");
request.id("1001");
DeleteResponse response = esClient.delete(request, RequestOptions.DEFAULT);
System.out.println(response.toString());
// 关闭客户端连接
esClient.close();
}
}
搜索文档
public class Ex_doc_search {
/**
* @Description: 查询全量数据
* @author: lb.sun
* @DateTime: 2022-02-15 - 09:03
*/
private static SearchSourceBuilder all(RestHighLevelClient esClient) throws Exception {
// QueryBuilders 有很多已经提供的方法,matchAllQuery 是匹配所有
return new SearchSourceBuilder().query(QueryBuilders.matchAllQuery());
}
/**
* @Description: 条件查询
* @author: lb.sun
* @DateTime: 2022-02-15 - 09:12
*/
private static SearchSourceBuilder paramQuery(RestHighLevelClient esClient) throws Exception {
return new SearchSourceBuilder().query(QueryBuilders.termQuery("age", 20));
}
/**
* @Description: 分页查询
* @author: lb.sun
* @DateTime: 2022-02-15 - 09:16
*/
private static SearchSourceBuilder pageQuery(RestHighLevelClient esClient) throws Exception {
SearchSourceBuilder builder = new SearchSourceBuilder().query(QueryBuilders.matchAllQuery());
builder.from((3-1)*2); // 从第几条数据开始,起始位置0,一般用于页码,页码计算公式:(页码-1)* 每页条数
builder.size(2); // 每页条数
return builder;
}
/**
* @Description: 查询排序
* @author: lb.sun
* @DateTime: 2022-02-15 - 09:58
*/
private static SearchSourceBuilder sortQuery(RestHighLevelClient esClient) throws Exception {
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.query(QueryBuilders.matchAllQuery()).sort("age", SortOrder.DESC); // 根据年龄降序
return builder;
}
/**
* @Description: 包含、排除字段
* @author: lb.sun
* @DateTime: 2022-02-15 - 10:28
*/
private static SearchSourceBuilder extOrInQuery(RestHighLevelClient esClient) throws Exception {
SearchSourceBuilder builder = new SearchSourceBuilder().query(QueryBuilders.matchAllQuery());
String[] includes = {};
String[] excludes = {"age"};
builder.fetchSource(includes, excludes);
return builder;
}
/**
* @Description: 组合查询
* @author: lb.sun
* @DateTime: 2022-02-15 - 11:20
*/
private static SearchSourceBuilder composeQuery(RestHighLevelClient esClient) throws Exception {
SearchSourceBuilder builder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
boolQueryBuilder.must(QueryBuilders.matchQuery("sex", "nv"));
boolQueryBuilder.must(QueryBuilders.matchQuery("age", 19));
return builder.query(boolQueryBuilder);
}
public static void main(String[] args) throws Exception {
// 创建客户端
RestHighLevelClient esClient = Es_demo.getEsClient();
// 查询全量数据 - QueryBuilders.matchAllQuery()
System.out.println("全量查询---------------------");
printResp(esClient, all(esClient));
// 条件查询
System.out.println("条件查询---------------------");
printResp(esClient, paramQuery(esClient));
// 分页查询
System.out.println("分页查询---------------------");
printResp(esClient, pageQuery(esClient));
// 查询排序
System.out.println("查询排序---------------------");
printResp(esClient, sortQuery(esClient));
// 过滤字段
System.out.println("过滤字段---------------------");
printResp(esClient, extOrInQuery(esClient));
// 组合查询
System.out.println("组合查询---------------------");
printResp(esClient, composeQuery(esClient));
// 关闭客户端连接
esClient.close();
}
private static void printResp(RestHighLevelClient esClient, SearchSourceBuilder builder) throws IOException {
SearchResponse response = esClient.search(
new SearchRequest().indices("es_test_user").source(builder),RequestOptions.DEFAULT);
SearchHits hits = response.getHits();
System.out.println("数据总数:" + hits.getTotalHits());
System.out.println("用时:" + response.getTook());
System.out.println("数据:--------------------");
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsString());
}
}
}















 178
178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









