






02.商户查询缓存
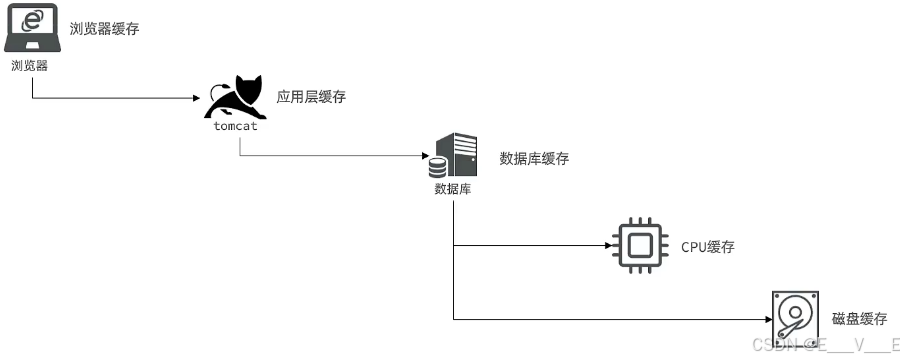
比如说那么这是因为这种数据读写的能力远远的低于预算能力,所以说计算机性能受到了一个限制。所以为了解决这个问题,人们就在CPU的内部添加了一个缓存,什么意思?就是CPU会把经常需要读写的一些数据放到CPU的缓存里面去,当我们去做高速运算的时候,就不必要每次等半天从内存或磁盘里把数据读过来再运算了,而是直接从缓存里拿到数据进行一个运算,那么这样一来是不是可以充分的让CPU的运算能力得到释放 衡量一个CPU它是否强大的一项标准,就是CPU的缓存的大小缓存越大,能缓存的数据自然也越多,那么处理起来的性能是不是也越好?对吧?所以这时候缓存使用的一个典型场景。那么在我们的web应用开发的过程中,也是离不开缓存,比如说作为一个外部应用用户,肯定要通过浏览器向我们发起请求,那么在这个时候浏览器首先就可以建立缓存,浏览器缓存,比较常见的,比如说我们页面的一些静态的资源,我们访问一个页面里面有很多的一些css,js和图片,这些东西一般都是不变的,浏览器就可以把它缓存在本地,那这样一来就无需每次访问都要去加载这些数据了,是不是可以大大的降低网络的这种延迟,提高页面响应的速度?
这是浏览器缓存好浏览器缓存中未命中的一些数据,那么它就会去到我们的tomcat,那也就是我们所编写的那些加应用,而在tomcat里边也就是我们的java应用里,我们还可以添加应用层的缓存,什么叫应用层缓存?简单来说我们去创建一个map,然后把我们从数据库查的数据放到 MAC里以后,再来的时候我直接从外部里读给你,那这样一来是不是减少了数据库的查询效率,是不是也就会提升,所以这也是一种应用层的缓存,当然一般情况下我们不用map来做缓存,我们可以利用我们所学的redis,为什么?因为redis它本身的读写能力是不是非常的强?速度非常的快,而它的延迟读写的延迟往往在微秒的级别,所以说用它来作为应用层的缓存,再合适不过了。那当然了,当缓存未命中的情况下,请求依然还会落到我们的数据库,那么数据库层面它也可以去添加缓存,数据库缓存什么?举个例子,我们的索引,我们的Mysql数据库它是一个技术索引,它会给it创建索引对吧这些索引数据我们就可以把它存起来,这样当我们去根据这些索引进行查询的时候,就可以在内存里快速进化得到结果,而不用每次都要去读写磁盘,那么效率也会大大提升,所以这是数据库层面的一些缓存。当然了最终数据去查找还是要落到磁盘,还有做一些复杂的排序,或者是一些表观点还会用到CPU去做运算,所以最终的数据库还会去访问我们的CPU和磁盘,这个时候自然就会用到我们之前提到过了是不是CPU的多级缓存以及磁盘,甚至于它也可以去建立读写缓存,所以在整个外部开发的每一个阶段都可以去添加缓存
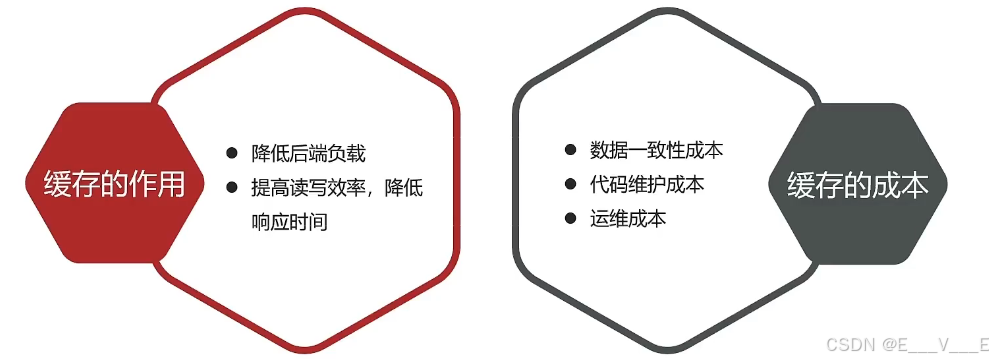
缓存的应用非常丰富的,但是缓存也不能乱用,那么任何的东西都是一个双刃剑,有得必有失。引入缓存以后,它再给你带来好处的同时也会有一些成本,这一点我们就基于外部应用开发来分析一下在外部应用当中缓存带来的一些作用和它的一个成本。 首先我们做外部应用开发一般就是在我们调查代码里去添加缓存,那么它比较常见的一个好处就是降低后端的负载,请求进入了我们的航母开采以后,以前我们是要先去查数据库,而数据库本身因为要去做数据的磁盘读写,所以相对来讲效率是比较低的,导致我们整个业务的延迟也会比较高,特别是一些复杂的业务随口那么查询起来就更慢了,所以给我们的数据库往往会带来比较大的一个压力。这个时候如果有了缓存请求进入他们开采以后,直接在缓存里查到数据返回给前端,不用去查数据库,是不是对于后端来讲压力就会大大的降低了,所以这是它的第一个作用,降低后端负担。 那么第二还可以提高读写效率,降低响应时间。刚才说了像这种数据库的读写往往是磁盘的读写,它显示时间往往是比较长的,那么这时候如果我们使用了缓存,像我们的redis,它读写的延时往往是在微秒级别的,这个显然时间是不是大大缩短,读写效率也大大提高,所以这个时候我们是不是就能够应对更高的并发请求了? 所以在一些用户量比较大变化比较高的业务里使用缓存就能够去解决这样的高并发问题了。但是使用缓存,它也会带来一些成本。
第一个就是数据的一致性成本,你想我们的数据本来是保存在数据库的,现在你把它缓存了一份放到了内存里,比如redis,用户查询的时候优先去查redis,这样来减轻了数据库压力,但是如果数据库的数据发生了变化,而这个时候redis里边或者说缓存里面的数据还是旧的数据,现在又会去读拿到的或者读到的是不是就是旧的数据,这个时候两者就产生了不一致,如果是一些比较重要的数据产生不一致,甚至可能会带来比较严重的一些问题。 所以这就是数据的一致性的一个成本。为了解决这个一致性问题,他就给我们的代码维护带来了极大的一个成本。为什么?因为你要去解决一致性的过程中,需要有非常复杂的一些业务编码,而且在缓存一致性处理过程中还会出现我们缓存穿透击穿等等这些问题,为了解决这些问题,那么代码的复杂度就会提高很多,以后开发和维护起来成本也就越来越高,那么最后还会带来运维上的一些成本。 为了避免缓存雪崩这样的问题,还有保证缓存的高可用,缓存往往会要搭需要搭建成集群模式,而缓存集群的这样一种部署维护就会有额外的一些人力上的一个成本。还有这些集群部署的过程中是吧?还有一些硬件的成本,你看任何东西都是双刃剑,有得必有失。那么因此一个企业在开发过程中你要去选择你们使用缓存以后带来的这些个好处,能不能去弥补它所带来的一些成本?如果不能我觉得不用也罢,特别是一些中小型的企业,然后刚刚起步,用户量也不大,这时候你不用缓存,其实也能够应对日常的用户请求,那就没有必要去做这件事情了
接下来我们为查询商户来添加redis缓存
第一个接口就是shop跟上id啊,他其实直接shop service的getbyid,而这个是由iservice接口提供的那么i service呢是mybatisplus 直接走数据库查询
@GetMapping("/{id}")
public Result queryShopById(@PathVariable("id") Long id) {
return Result.ok(shopService.getById(id));
}
你首先得明白缓存工作的一个模型:这里没有添加缓存的时候,客户端向我们服务器发起的请求,那么都会直接打到我们的数据库,而数据库产生数据以后再返回给我们的客户端,添加缓存就等于是在客户端与数据库之间添加了一个中间层,比如说我们添加一个redis缓存,这样一来客户端请求就会优先到达我们的缓存it的redis。 如果说 redis里恰好有这一部分数据,那么它直接就返回了,这样请求就不会到达数据库,那数据库压力是不是大大减轻了?只有在瑞士里没有这部分数据的情况下,也就是说请求为民众,那么他才会到达我们的数据库,这个时候数据库就会去完成自己的查询动作了,查询完以后把结果返回给客户端。
这样一来,其实真正能够到达数据库的请求是不是就非常少了,原来是一个又粗又大的箭头,现在是不是变细了?但是我们不能满足于这个就完了,你想如果你到这儿就结束了不管了,那么在redis中未命中的数据,下一次是不是依然是未命中? 所以如果redis未命中查了数据库,我们应该把查到的数据是不是在写回应词当中,这样下一次再来查询这个数据的时候,就可以命中。随着用户请求的数据越来越多,redis当中缓存的数据是不是也会越来越多,那么redis的命中率也越来越高,这样就形成了一个良性的工作模型了
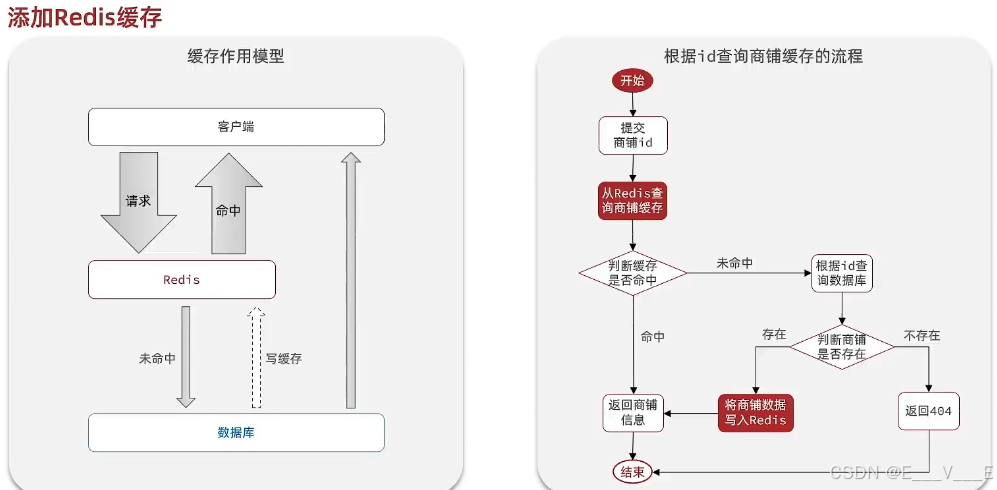
那么我们产品商户的业务功能参考这个模型需要做出怎样的一些修改呢?我们一起来看一下,首先我们现在会从前端提交一个商铺的ID,如果是以前直接是不是就查询数据库了?但现在不行,现在我们首先要去查询redis,去redis查shop,这个地方查完了以后不一定能查到.所以说我们需要对查询的结果做一个判断,缓存是否命中了,命中就代表查到了比较简单,直接把这个结果返回就行了,返回上部结束了。未命中的情况下就麻烦一点了,未命中我们还要先去查数据库,查数据库其实也有两种情况,一种是存在,一种是不存在,直接结果是不是存在? 如果查数据库不存在证明用户提交的 ID是错误的,根本的数据库里就没有。那么在这种情况下,我们经过判断,如果不存在,我们应该是不是返回一个404了,告诉他说这个商户不存在,但是如果说我们这个地方查的是存在的,证明数据库里确实有,我们要做两件事对吧?第一是把这个结果写到redis里,确保什么?下一次再来查的时候是不是能够命中,所以说我们先把数据写到redis,而后我们再把这个数据直接返回 返回商品信息,所以说我们更加低产业商铺的业务流程就会变成这个样子,于是三连修改control,Service和impl
@GetMapping("/{id}")
public Result queryShopById(@PathVariable("id") Long id) {
return shopService.queryById(id);
}package com.hmdp.service;
import com.hmdp.dto.Result;
import com.hmdp.entity.Shop;
import com.baomidou.mybatisplus.extension.service.IService;
/**
* <p>
* 服务类
* </p>
*
* @author 虎哥
* @since 2021-12-22
*/
public interface IShopService extends IService<Shop> {
Result queryById(Long id);
}
package com.hmdp.service.impl;
import cn.hutool.core.util.StrUtil;
import cn.hutool.json.JSONUtil;
import com.hmdp.dto.Result;
import com.hmdp.entity.Shop;
import com.hmdp.mapper.ShopMapper;
import com.hmdp.service.IShopService;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import static com.hmdp.utils.RedisConstants.CACHE_SHOP_KEY;
/**
* <p>
* 服务实现类
* </p>
*
* @author 虎哥
* @since 2021-12-22
*/
@Service
public class ShopServiceImpl extends ServiceImpl<ShopMapper, Shop> implements IShopService {
@Resource
private StringRedisTemplate stringRedisTemplate;
@Override
public Result queryById(Long id) {
String key = CACHE_SHOP_KEY+ id;
// 1.从redis查询商铺缓存
String shopJson = stringRedisTemplate.opsForValue().get(key);
// 2.判断是否存在
if (StrUtil.isNotBlank(shopJson)) {
// 3.存在,直接返回
Shop shop = JSONUtil.toBean(shopJson, Shop.class);
return Result.ok(shop);
}
// 4.不存在,根据id查询数据库
Shop shop = getById(id);
// 5.不存在,返回错误
if (shop == null) {
return Result.fail("店铺不存在!");
}
// 6.存在,写入redis
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop));
// 7.返回
return Result.ok(shop);
}
}
你可以在RESP中查找到缓存的文件
给店铺类型查询业务添加缓存
店铺类型在首页和其它多个页面都会用到,如图:需求:修改ShopTypeController中的queryTypeList方法,添加查询缓存,(本人没有修改)
@Override
public Result queryShopList() {
// 1. 从redis中查询商铺类型列表
String jsonArray = stringRedisTemplate.opsForValue().get("shop-type");
// json转list
List<ShopType> jsonList = JSONUtil.toList(jsonArray,ShopType.class);
System.out.println("json"+jsonList);
// 2. 命中,返回redis中商铺类型信息
if (!CollectionUtils.isEmpty(jsonList)) {
return Result.ok(jsonList);
}
// 3. 未命中,从数据库中查询商铺类型,并根据sort排序
List<ShopType> shopTypesByMysql = query().orderByAsc("sort").list();
System.out.println("mysql"+shopTypesByMysql);
// 4. 将商铺类型存入到redis中
stringRedisTemplate.opsForValue().set("shop-type",JSONUtil.toJsonStr(shopTypesByMysql));
// 5. 返回数据库中商铺类型信息
return Result.ok(shopTypesByMysql);
}
缓存更新策略
| 内存淘汰 | 超时剔除 | 主动更新 | |
| 说明 | 不用自己维护,利用Redis的内存淘汰机制,当内存不足时自动淘汰部分数据。下次查询时更新缓存。 | 给缓存数据添加TTL时间,到期后自动删除缓存。 下次查询时更新缓存。 | 编写业务逻辑,在修改数据库的同时,更新缓存。 |
| 一致性 | 差 | 一般 | 好 |
| 维护成本 | 无 | 低 | 高 |
业务场景:
● 低一致性需求:使用内存淘汰机制。例如店铺类型的查询缓存
● 高一致性需求:主动更新,并以超时剔除作为兜底方案。例如店铺详情查询的缓存
企业里常见有三种模式:
第一种,简单来讲人工编码的模式也就说我们自己写代码,那么更新数据库的同时把缓存也给它更新了,这种方式我们需要去自己写一些代码,对于调用者来讲可能会稍微有些复杂,但是你是可以人为去控制它的。
第二种方案叫read through,实录是将我们的缓存与数据库整合成一个服务,那么这个服务你不要管它底层到底用的是什么,对外来讲它就是一个透明的服务。那么这个服务因为内部同时处理老板的数据库,所以它是可以保证两者的处理同时成功和失败的,所以由它来维护两者的一个一致性。 也就是说我们作为一个调用者,我们只需要干什么?说我今天要新增一个数据了,它可以保证你缓存里有,数据库里也有,就是你不用管了,你直接掉就行了,用者无需关心一致性问题,那么这样一来我们作为调用者是不是就非常简单了,这是它相对于翻译的一个好处,当然它最大的一个问题是 你想维护这样一个服务是比较复杂的,市面上你想找到一个现成的这样的服务可能也不太好,你去开发起来了成本还是挺高的。
那么第三种方案叫write behind caching ,要写回它这种模式与方案二有类似之处,它们的作用都是为了简化调用者的开发,调用者无需关心一致性,区别在于我们的一致性方案二是由我们服务来控制的。 我们调用者不知道自己到底是操作的缓存数据库,对外是透明的,而作为方案三来讲写回这种模式来讲,我们的程序员明确的知道我只操作缓存。我只操作缓存,我不关心数据库,我也不需要去处理数据库,我也不需要处理数据,我的资产调查全部在缓存里做,那么谁来保证一致性? 有一个独立的线程,独立的线程异步的将缓存数据持久化到数据库保证一致。这个又是什么意思呢?也就是说,你单独的你去操作增删改,它全部在缓存里做,这样来缓存的数据是不是最新的数据,而数据库的是不是旧的数据?好,现在有一个线程它及时的去看一看缓存有没有变化,如果有,他再帮我们把缓存数据写到数据库里去,然后有现场运作你不用管,而且显示异步的,那么它会隔一段时间去执行一次,这样做有什么好处?比方说我们在缓存里做了10次写操作,而在这10次结束以后,刚好轮到了我们一波更新的动作了,那么他会把这10个操作合并成一次性操作,往数据库里去写做1个批处理,你看这样是不是就可以把多次对数据库的写合并成一次写了,你觉得它效率是肯定得到提升 而且还有一种特殊情况,举个例子,那么在他的两次异步更新之间,如果说我们对缓存中的某一个key做了N次更新,事实上只有最后一次更新有效对不对?那么我们在做一步更新的时候,我们只需要把最后一次的结果写入数据库是不是就ok?所以这就是什么?我们这种异步机制它的一个好处效率比较高,它最大的问题是什么?
第一你要维护这样的一个异步的任务是比较复杂的,你需要去实时的监控缓存中的,数据的一个变更对吧?那么其次我们这个地方的一致性是难以保证的。你想我们先做的缓存,然后一步去更新如果说,我缓存已经执行了上百次操作了,这个时候还没有触发异步的更新,那么在这一段时间内,我们的缓存数据库完全是不一致的,对不对?而且如果此时缓存出现了宕机,宏村大多数是内存存储,一旦宕机数据就丢失了,这个时候是不是就等于这段数据就完全丢失。 所以说它的一致性和可靠性都会存在一定的问题。这是第三种方案。

综上所述,其实尽管方案一需要我们的调用者自己编码,相对来讲可控性是不是更高一点,那么因此一般情况下我们在企业用的最多的正是这个方案一,那么开场赛的需要我们的开发者自己去编码,因此在编码的过程当中,我们还是需要去考虑哪几个问题。
第一个问题就是删除缓存还是更新缓存问题,因为我们需要在更新数据库的同时去更新缓存对吧?那么这个地方就有两种,一种是更新,一种是删除。更新就不用多解释了,你数据库做了什么样的更新,我们的缓存也做什么样的更新对吧?删除是什么意思?就是你这儿对数据库的更新我不更新缓存,我是直接删缓存,这两个又带来什么样的一些差异? 因为更新缓存是每次更新数据库都更新缓存,如果说我对数据库做了上百次操作,那么我就需要对缓存也做上百次操作,但是如果在这上百次操作的过程当中,没有任何一个人来做查询,也就是写多读少。这个时候你对缓存做的N次修改是不是都是无效的一些操作?还是这样的。删除操作则不存在这个问题。为什么?因为我更新数据库时我让缓存失效把它删了。 好,我更新了100次,其实。只删一次是不是就够了?而在这100次之间如果没有任何人来访问,那么我也不会去更新缓存。什么时候有人来访问了,什么时候我去更新缓存,这样是不是等于是一种延迟的加载模式?因此这种方案写的频率会更低有效,更新会更多,所以说我们一般会选择什么?删除缓存的方案,而不是更新缓存。好,这是第一个要考量的。
第二,我们更新数据的同时要去删缓存,那么你需要确保更新数据库与删除缓存两个操作的同时成功或失败,也就是保证两个操作的原则性。如果说我更新数据库的时候删缓存这件事失败了,这个就没有意义了对不对?所以你要保证它突然成功或失败,怎么保证投入成功失败呢? 如果说我们是一个单体系统,就像我们现在这个案例是不是单体系统了,那么单体系统因为缓存和数据库在一个项目当中,甚至于我们是在一个方法里,我们可不可以把它做成一个事物,是不是可以? 所以我们利用事物本身的这种特性,是不是就能保证同时成功失败了?但是如果你是一个分布式的系统,分布式系统我们的缓存操作和数据库操作很有可能是两个不同的服务,你怎么保证这两个东西的一致性呢?那么这个就不得不用到类似于gtc这样的分布式事务的方案了。好,那么有同学可能不知道什么叫分布式事务是吧?好,在如果有兴趣或者有疑问的同学,可以去B站上搜索一下我讲解的另外一门课程, spring cloud微服务的一个课程史上最全的微服务课程里面就可以讲到全套的微服务的各种各样的问题的解决方案,就包括了分布式的解决方案。好,那么这是原则性的问题,确保这两个操作都能成功。我说来这个时候如果我们能保证这种原则性了,那么是不是意味着我们这个更新就一定能成功?还不是。
还要考虑一个什么线程安全的问题。还有我们在操作的时候,因为有缓存操作,数据库搜索两个操作对吧?那么这个时候在独者程并发的情况下,那么这两个操作之间可能会有多个线程,同时你执行我执行这样来回穿插,那么这个时候谁先做谁后操作就会带来不一样的现场安全问题。那么我们该选择什么呢?Ok这个地方不太好说,其实两种都可以,先删缓存再操作数据库,还是先做数据库,再缓存其实都ok。那么具体选哪一个我们需要对比之后再来看。

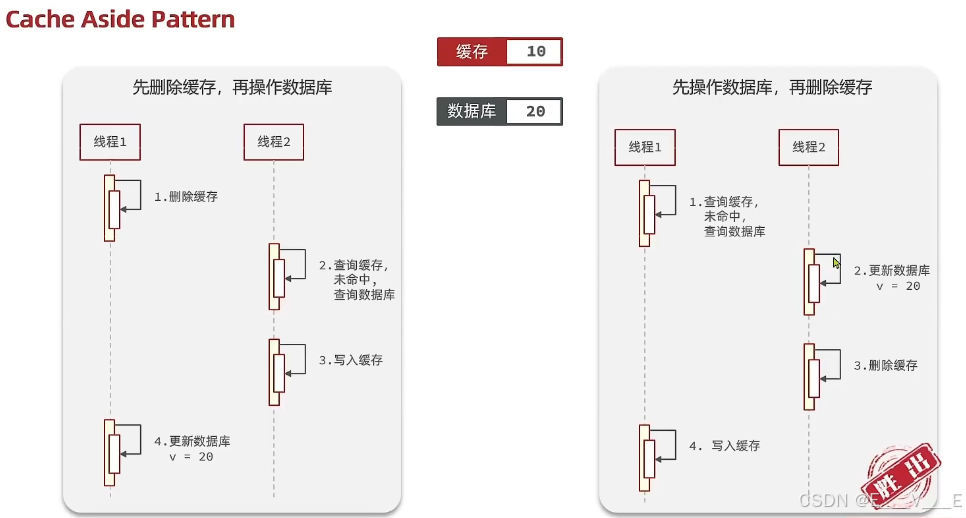
好,那么这里我们先来看一下千山合同的操作数据库,这种方案我们现在看正常的,假如说它这里有缓存和数据库,这里面我要存数据对吧?初始化的时候两个值都是10,然后我们有两个线程并发的执行,我们知道线程的执行往往是无法控制的,CPU在这之间去做切换,你也不知道他会先请谁对不对? 那么这个时候假设说线程一他要来去更新我们的缓存,按照我们的逻辑第一种方法是先删缓存再做数据库。所以如果我现在要更新缓存的话,我是不是先删缓存?对吧?我删缓存以后是不是就被删掉了,然后我去更新数据库,我把数据库更新成20。 好了,到这我的缓存操作其实就结束了。好,那么结束了以后,如果这个时候不管是谁任意一个人只要来查询都会出现一个情况,就是缓存走了,为民众缓存如果为民众他会干什么?是吧?查数据库。这个数据库只是以还是20,所以他此时到时候20,好得到20以后他就把数据写到缓存,他把数据写到缓存,那么20写进去变成是不是还是20?所以这时候两者是不是一致了?这是正常的情况。
好,我们再来讨论一下异常的情况,我们现在假设那么现在都是10,所以在异常情况就是指什么?在线程执行的过程中,另外一个线程它也进来执行了,因为我们没有加锁了,所以他们是可以并行执行的对不对?好,那么假如说县城一要来更新缓存,它是先删再更新对吧?它先删于是缓存没了,好,那么接着他要去更新,但是因为更新的业务比较复杂,所以说这时候谁趁虚而入了,我们现场二趁虚而入,他干了什么事, ok他去查询。 可以查询去了,那么这边因为保存删了,他来查询的时候保存显然是什么了?未命中了对不对?所以未命中他就会干什么?数据库,因为他是趁虚而入的,此时数据库还没有完成更新,所以依然是旧的值,所以他查到了什么?旧的值对不对?好,他查到旧的值10,紧接着他去干什么了?写入缓存,那么当它写入缓存时,同学们写的是不是旧的纸?好。他写完了。这个时候县城一终于开始执行更新的操作了,那么执行更新操作的时候把值改成20,改成20,于是数据库数据就与缓存数据产生了不一致的情况。明白了吗?Ok,这就是线程安全问题产生的原因,那么这种线程安全问题发生的概率高不高?其实还是挺高的,同学们想一下为什么呢?因为你是删缓存,更新数据库同学们删缓存很快,但是更新数据库的动作是不是很慢?你首先要组织数据然后去更新,而且这是个写操作对不对?然后线程二是干什么?线程二是查询缓存。查询然后直接写缓存,写缓存因为写的是release的,写操作往往是非常快的微秒级别的,所以它跟写数据库相比更快。是不是新缓存?查也很快写也很快,那么这个操作是不是就很有可能在它俩之间?所以说这种发生的情况还是我们主要是电视上面,那么我们再看第二种方案,先操作数据库再删缓存,我们先要假设这有两个线程把数据来恢复一下,我们先看正常情况,现在假设我们的线程二他要来去完成更新,它要完成更新,它做的是先数据库再缓存对吧?
08:37 原文: 好。我们现在根据数据库把值改成20,好,这个时候更新完数据库是不是删缓存了,于是他去删缓存,那么缓存一删就从20变成没有了,没有了以后,这个时候不管谁要任意一个人只要来查询,都可以触发什么了?完成同步,因为什么?未名中美为民众,你要去查他查到是不是就是更新好的数据,也就是一个20,于是他才去写缓存的时候,写到缓存里的自然也就是20,是不是保持一致了? 09:01 原文: 当然了,这是正常情况,他肯定也会出现两个线程穿插的这种情况。有可能。下面我们再来看一下异常的情况,这种穿插的情况。好,那么穿插是这样子的,我们先把数据恢复,先把数据恢复,我们假设说现在有一个线程来查询,当然如果现在缓存已经有了,他查的是不是就这个数据了,没什么好说的,我们假设一种比较特殊的情况,恰好缓存失效了,你不管什么原因,反正恰好缓存失效了。 09:26 原文: 比如有可能是缓存时间到了是吧?失效了,失效了以后县城一来查,比如现在已经是小心一来查,它一定是一个什么情况未名,那么为民众他来查,好,那么就要去查数据库了,数据库现在是10,于是他得到解决了。那么查到实了以后,紧接着因为为民众他要干什么?是不是要把数据写入缓存?要把数据写入缓存,但是正在此时另外一个线程插入进来了,那么这个线程来更新数据库只是被改成了20,然后这哥们删缓存去了,但是缓存已经被删掉了,这个删等于没删。紧接着好它结束了,线程一开始执行了,线程一写缓存就写缓存去了,这个时候一写缓存不得了,因为之前查的是旧数据是吧?
10:03 原文: 在这个地方现在数据库新的数据他不知道,因为他查完了人家才更新的,所以这时候写进去的。两者出现了不一致,明白了吗?这种情况发生的可能性高不高了?大家思考一下。它发生了要有这么几个条件,首先两个线程的并行执行。其次线程一来查询的时候二号划算失效了,是吧?然后恰好失效的同时,他查完了数据库要去写缓存,注意了查完数据库写缓存,写缓存的操作方法是不是微秒级别的,就在微秒的范围内突然来了一个线程,他先去更新数据库,同学们更新数据库的时候往往是比较慢的对吧? 10:35 原文: 更新完了以后又去删缓存,然后才轮到这哥们写。大家想想看,在这一个微秒甚至非常短的一个时间内,要完成这么多的数据库的写操作,它可能性高不高?显然不高,因为缓存的速度是远远高于数据库的,对吧?所以说你不太可能你的数据库更新操作竟然比我的缓存操作还要快,虽然这个可能性是比较低的,要同时满足这样三个巧合是吧?而方案一我刚才分析过它的方案是出现的可能性是比较高的,所以综上所述这两种方案都有可能发生现成的安全问题,但是方案二相对来讲出现的可能性那也不是完全没有,但这个概率可以认为是极低,几乎不太可能发生,但是还是有可能的对吧? 11:14 原文: 一旦发生了怎么办?我们将来加上一个超时,时间就行了,对吧?加上一个超时,时间,我们在写缓存加超时,时间万一我写了旧数据了没关系,过一段时间是不是也会清除?所以说我们从现场安全的概率角度来分析,最终胜出的就是方案二,先操作数据库再删缓存这种方式。好了,到这我们就把缓存同步策略全部给大家说完了,最后我们去做一个总结,做总结,缓存更新策略的最佳实践方案。我们讲它有地质性和高异质性两种场景了是吧?总共三种内存淘汰超时和主动更新,但是对于地质体来讲,一般我们用自带淘汰机制就行了,最多加一个超时更新。
11:47 原文: 而对于高主义执行要求,我们就必须去做主动更新了,并且赋予超时剔除作为兜底。因为只有这样才能在发生意外的时候去保证数据的恢复。那么主动更新我们讲又有三种开始set,还有 Restroom以及写回三种方法,但是后两种实现起来相对复杂,而且也找不到比较好的这样的一个第三方组件,所以一般情况下企业的选择都是开始赛的这种方案,而开始赛我们讲又有好多问题要考虑对吧是更新缓存还是删缓存,经过我们讨论我们觉得删除更好,因为更新有太多的无效写操作了对吧? 12:16 原文: 好那么如何保证原子性?好我们的单体系统它天生就是原子系统利用事物对吧?而控制系统我们说可以利用这种分布式事务方案,保证它的原则性同时成功同时失败。好,那么同时成功同时失败了以后,它还有现场安全问题对不对?那么现场安全问题又怎么保证呢?Ok现场安全问题我们经过讨论,我们选择的是先写数据库再删缓存这种,因为它的一个现场安全问题发生的概率是最低,所以最终我们的方案就确定下来了。 12:38 原文: 当我们写数据的时候,当我们要去写的时候,我们先写数据库再删缓存,这种发生信息安全问题的可能性会最低。这是写的时候,那么我们在读的时候读的时候跟以前来讲变化不大,读去看一下缓存有没有缓存,如果有直接返回缓存没有,咱是不是就查出有过? 12:52 原文: 查完数据库以后还要把它写回到缓存里,但是要注意的区别了,写缓存的时候要是什么长时间是不是作为兜底方案?
给查询商铺的缓存添加超时剔除和主动更新的策略
修改ShopController中的业务逻辑,满足下面的需求:
1)根据id查询店铺时,如果缓存未命中,则查询数据库,将数据库结果写入缓存,并设置超时时间
②根据id修改店铺时,先修改数据库,再删除缓存
修改shopserviceimpl的有效期
public interface IShopService extends IService<Shop> {
Result queryById(Long id);
Result update(Shop shop);
}// 6.存在,写入redis
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop),CACHE_SHOP_TTL, TimeUnit.MINUTES);
// 7.返回
return Result.ok(shop);修改ShopController,以及顺带的IShopService和shopserviceimpl
@PutMapping
public Result updateShop(@RequestBody Shop shop) {
// 写入数据库
return shopService.update(shop);
} @Override
@Transactional
public Result update(Shop shop) {
Long id =shop.getId();
if(id==null){
return Result.fail("店铺id不能为空!");
}
updateById(shop);
stringRedisTemplate.delete(CACHE_SHOP_KEY+id);
return Result.ok();
}这里的事务只是为了让数据库回滚的,重点在于当redis报错了,数据库能回滚,redis本身不需要回滚
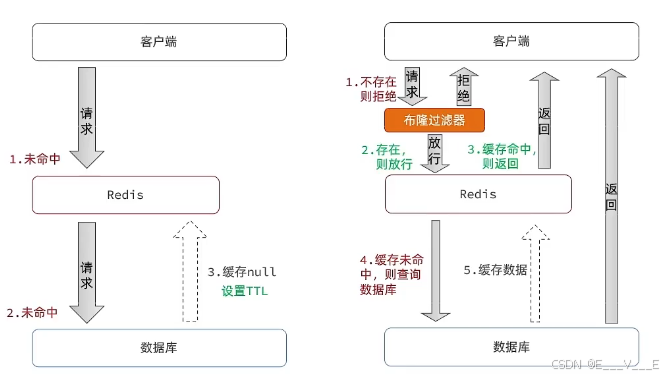
缓存穿透
缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。
常见的解决方案有两种:
1.缓存空对象
优点:实现简单,维护方便
缺点:额外的内存消耗,可能造成短期的不一致
2.布隆过滤
可以简单的理解为bit数组,其实并不是真的把数据存储到布隆过滤器,而是呢把这些数据基于某一种哈希算法计算出一个hash值,然后呢再将这些哈希值转化为二进制位保存到我们布隆过滤器里。对应的01方式保存,判断数是否存在就是0或者1.当然这不能它并不是真的就百分之百的准确,他说不存在这肯定不存在,但是说存在就不一定了,因为他告诉我说:这个数据它存在,放心了,于是就去redis查,然后去mysql查,又没有,又穿透了
如果说你想自己去实现布隆过滤器,其实还真的挺麻烦。好在我们redis其实提供了这个basemap,这种方式是它自带的一种不能过滤的实现
优点:内存占用较少,没有多余key
缺点:实现复杂;存在误判可能
首先通过缓存空对象的方式来解决缓存穿透
我们原来是通过如下过程,首先呢前端会提交商铺id去查询,先从redis查询,如果redis命中了就ok,没命中就查数据库,数据库有就写到redis并且返回,没有就404
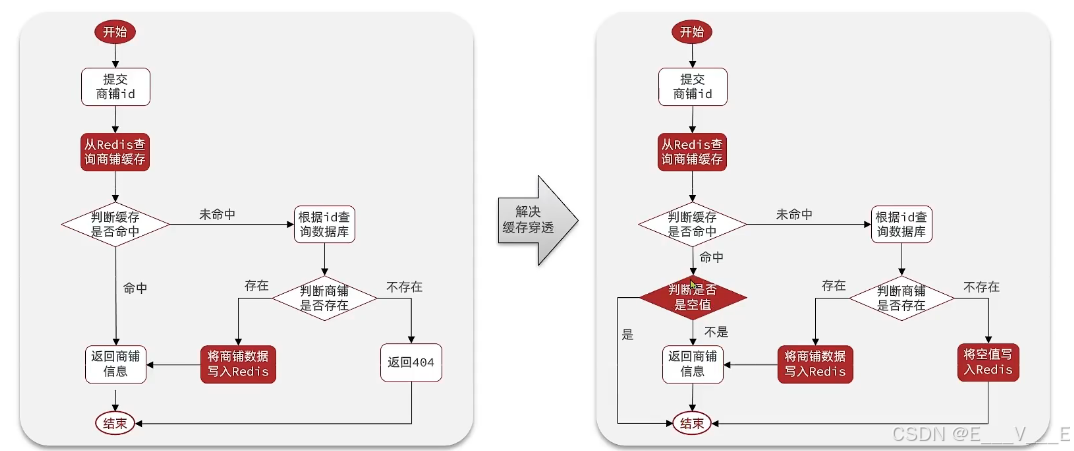
修改后那么你命中的就不一定是商铺信息了而是null,因此还要对这个结果做一个判断,判断一下命中的是不是空,为shopserviceimpl添加
@Resource
private StringRedisTemplate stringRedisTemplate;
@Override
public Result queryById(Long id) {
String key = CACHE_SHOP_KEY+ id;
// 1.从redis查询商铺缓存
String shopJson = stringRedisTemplate.opsForValue().get(key);
// 2.判断是否存在
if (StrUtil.isNotBlank(shopJson)) {
// 3.存在,直接返回
Shop shop = JSONUtil.toBean(shopJson, Shop.class);
return Result.ok(shop);
}
//这个地方根本不用判断,除非前端代码被黑了
//判断命中的是否是空值
if(shopJson !=null) {
//返回一个错误信息
return Result.fail("店铺信息不存在!");
}
// 4.不存在,根据id查询数据库
Shop shop = getById(id);
// 5.不存在,返回错误
if (shop == null) {
//将空值写入redis
stringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);
return Result.fail("店铺不存在!");
}
// 6.存在,写入redis
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop),CACHE_SHOP_TTL, TimeUnit.MINUTES);
// 7.返回
return Result.ok(shop);
}
同样的清空idea日记后刷新界面没有打印查询过程,说明已经redis了, 请求没有经过数据库
总结一下,缓存穿透的解决方案有哪些?
- 缓存null值
- 布隆过滤
- 增强id的复杂度,避免被猜测id规律
- 做好数据的基础格式校验
- 加强用户权限校验
- 做好热点参数的限流(详见springcloud)
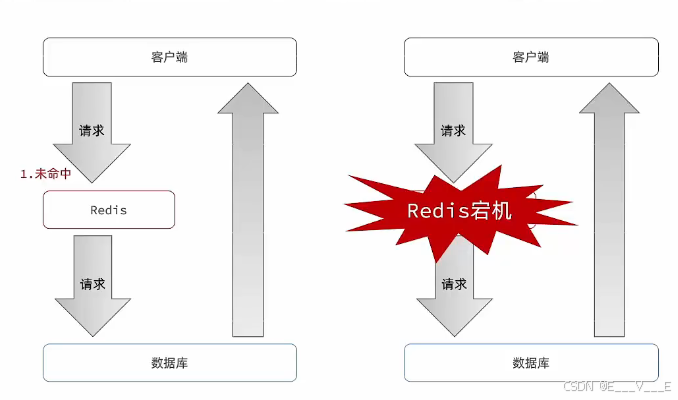
缓存雪崩
缓存雪崩是指在同一时段大量的缓存key同时失效或者Redis服务岩机,导致大量请求到达数据库,带来巨大压力。
解决方案:
- 给不同的Key的TTL添加随机值
- 利用Redis集群提高服务的可用性
- 给缓存业务添加降级限流策略
- 给业务添加多级缓存
缓存击穿
缓存击穿问题也叫热点Key问题,就是一个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。
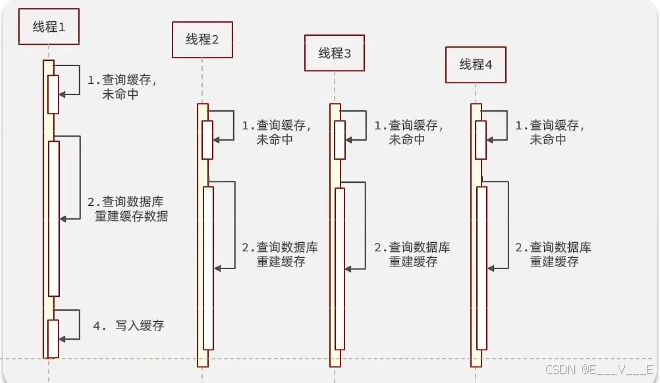
比方说我们现在就有无数的线程来访问我们这样的一个热点key了,好那么这个key它突然就失效了,到期了,于是我们这个线程来查询的时候自然就是未命中,他一定要去做缓存,然后重建
按照文件做重新去查询数据库,但是因为他这个业务比较复杂,所以他这个查询要耗时长就比较长,你看他们发的长一点,在他执行完了以后才可以把构建好的数据写入缓存。在它完成之前,我们是不是可以认为缓存率就没有了数据了,空的也就是说在这条线之前的这一段时间内整个环境都是空的,如果在这段时间内又有别的线程来了,他们去查询一定也是未命中,他们一定也会去做缓存重建; 不管是有3个行程4个行程还是无数个行程,只要是在这个时间节点,以前来访问都会走这个流程,你想想看这些请求都打到哪里去了,是不是数据库了?那么因为key的重建时间比较长,再加上它又是一个热点,可以访问的并发又非常高,那么在这么长的一段时间内,就可以有无数的请求涌进来,全部打到我们的数据库上,那可能就把数据库给整垮了
击穿这个词的重点就在于一个点的击穿,雪崩是数量级的非热点key失效。穿透是缓存和数据库都没数据缓存失效的现象
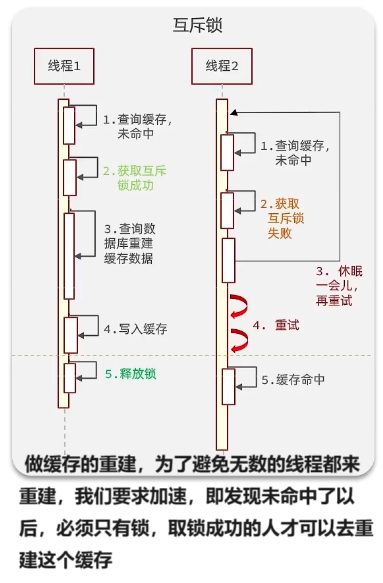
缺点就是互相等待,因为比如说我现在同一时刻有1000个线程来了,你其实只有一个线程在做构建,其他线程都在等待。那如果说这个构建的时间比较久,这段时间里涌入的所有的线程都只能做等待,因此它的性能会比较差一点。
之前产生的原因是因为设置了ttl 缓存突然间失效了,因为失效了,未命中,所以要重建出现问题了
这不设置我怎么知道这个缓存是不是过期了,所以也是逻辑过期就是说我们在存储一个数据的时候,咱们以前存储key value,现在在value里面我们加一个字段,比如说叫expire:过期时间,注意这里的过去时间并不是tt,而是我们再去添加缓存的时候,在当前时间基础加上一个过期时间,比如30分钟得到的一个时间存储进去,也就是说是我们逻辑上去维护的这样一个时间。
既然T它没有TTL,没有危机时间,是不是意味着将来可以一旦存储到类似的它就会永不过期?再加上我们配上了合适的一些内存淘汰策略的话,理论上讲你可以认为只要可以写到这里了以后,永远都能够查到,不会出现未命中的情况。
那么像这样的一些热点K往往都是在做活动的时候我们去添加进去的,我们在做活动的同时直接给他设置导入当中,添加上逻辑过期时间,活动结束我们再把它移除就ok了。因此任何的线程来去查询这样的热点商品的时候,理论上讲都是可以命中的。
那么它唯一需要判断的就是它逻辑上有没有过期,如果说逻辑上已经过期了,可能说明P它已经是一些旧的数据了,需要更新。
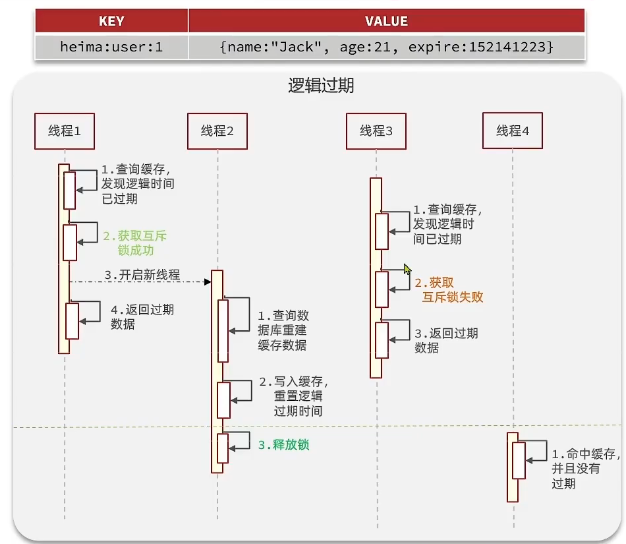
接下来我们需要肯定还是需要去重建缓存,但是为了避免有多个线程都来重建,他也要去获取锁。你这里也会去锁,跟前面不就一样了,也要等待。前面不就是因为获取锁,然后大家互相等待而导致性能下降,你这里又过去锁,所以为了避免获取锁以后等待时间过长,他拿到锁了以后他会干一件事情,他不是自己觉得构建,他会开启一个独立的新的线程,由这个线程去做查询数据缓存重建写入缓存这一段逻辑,当然了它写入缓存以后要重置逻辑轨迹时间,这些都做完了以后他就去释放锁了。
也就是说这一堆耗时比较久的任务不再是线程一自己做了,是不是交给另外一个线程做了?他做完了以后去释放锁。那么在他写入缓存之前这一段时间从这条线往上的时间,其实缓存是都是旧的数据 。这个时候线程一开启新线程就做这些事情,它干什么呢?Ok我安排了一个人去帮我重置缓存数据去了,我就不去做了,直接返回旧的数据,我之前查旧数据是什么,我直接返回,我不在乎,那就是旧了一点也能用。
返回这么来做。Ok这个时候如果再来了个线程,他也来执行的时候,因为是在绿线之上是吧?此时缓存还是旧的,所以他去查也发现过期,发现过期他也要求获取互斥锁,他一定会获取失败,因为所谓释放他获取失败了干什么,是不是像这些那样等待?重试。而不是如果这样就没什么区别了对吧?他干什么?Ok他也一样,原来已经有人帮我去更新了,包括获取失败肯定是有人更新了,直接把我查到的旧数据返回就行了,查到了个数据,结果是旧数据,然后别人已经在更新
了,行我先用这个旧的,你啥时候更新完了再说,我不管。不争不抢是吧?
这时候什么时候才能查到新数据,就是我们刚才知道这个线程二负责缓存重建的,线程执行完,如果有一个线程是在这个时间点来去读取,那么拿到的就是最新的数据,那么它就可以返回新数据。好,这就是逻辑过期这样一种方案。那么这两种方案我们来对比一下他们的一个优缺点。首先互斥锁这种方案他首先没有额外的内存消耗,为什么?这是相比于逻辑过去来讲的。逻辑过期的话,在原有的数据的基础上,你要多维护一个过期时间的字段,是不是有额外的内存消耗,而我们的互斥这种方案则不需要去保存逻辑归期,所以这块内存占用是比较小的,没有额外的内存消耗。
| 解决方案 | 优点 | 缺点 |
| 互斥锁 | 没有额外的内存消耗 保证一致性 实现简单 | 线程需要等待,性能受影响 可能有死锁风险 |
| 逻辑过期 | 线程无需等待,性能较好 | 不保证一致性 有额外内存消耗 |
基于互斥锁方式解决缓存击穿问题
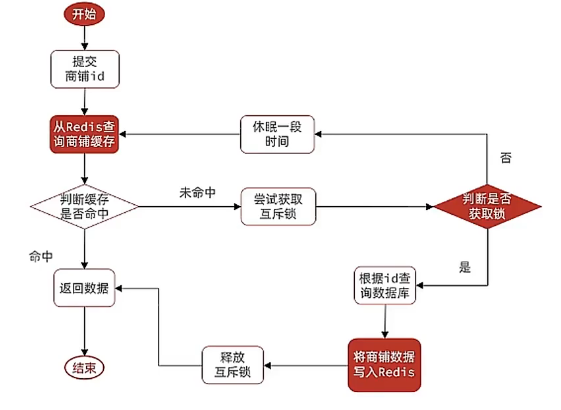
JUC 的
tryLock只能在单机情况下锁住:
JUC(Java Util Concurrency)的tryLock是基于本地线程的锁机制,适用于单机环境。它无法在分布式系统中协调多个节点的线程,因此无法解决分布式场景下的缓存击穿问题。Redis 的
SETNX可以做分布式锁:
Redis 的SETNX命令(SET if Not Exists)是一个原子操作,可以用来实现分布式锁。通过SETNX,只有当键不存在时才能设置成功,从而确保了锁的互斥性。此外,结合EXPIRE命令可以设置锁的过期时间,避免死锁问题。Redisson 也可以实现分布式锁:
Redisson 是一个基于 Redis 的分布式锁框架,底层使用SETNX和 Lua 脚本保证原子性,支持多种锁的实现方式(如可重入锁、公平锁等),并且提供了方便的 API,使得分布式锁的使用更加简单。
set nx命令,可以给一个key赋值,当且仅当这个key不存在的时候去执行。因为redis是单线程的 所以再多线程发起setnx请求 也都必须串行
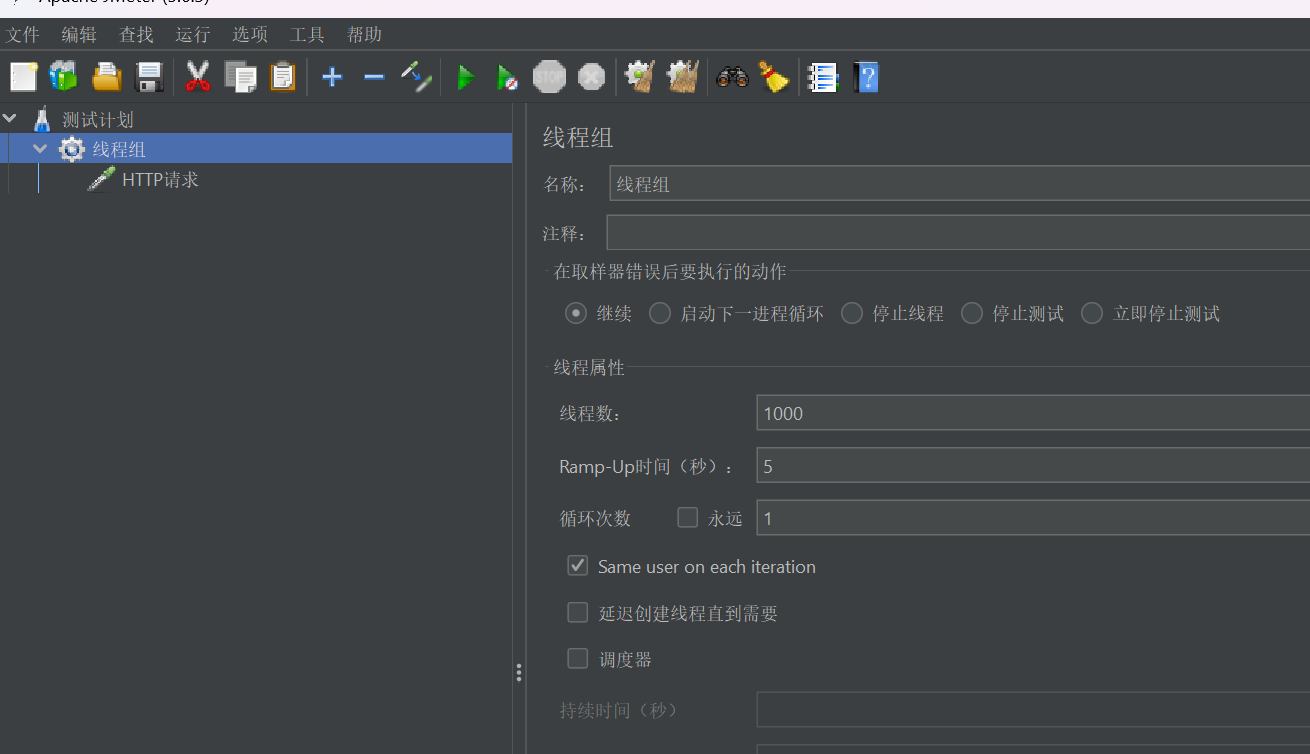
热点事件要满足两点条件,1.高并发2.缓存重建的时间比较久。下载Apache Jmeter的压缩包,打开bin/jmeter.bat即可,右键逐渐设置一个对端口号8081的QPS200的请求量
清除redis的所有缓存后小三角运行可以看到可以运行。idea只对sql查询了一次
基于逻辑过期方式解决缓存击穿问题
需求:修改根据id查询商铺的业务,过期方式来解决缓存击穿问题
因为这些是热点数据,缓存预热提前加载的,如果没有,则证明你查询的数据,不在这次活动中,也就是无效的数据,类似于布隆过滤器一样的感觉
好这里其实有两种思路,第一种是就是我们先去在utils/下定义一个对象RedisData.java:定义一个成员变量,类型的就是localdatetime。想要shop具备过期时间的属性,就让shop继承了我们的redisdata。第二种是redisdata自己带data,优先用组合,少用继承
package com.hmdp.utils;
import lombok.Data;
import java.time.LocalDateTime;
@Data
public class RedisData {
private LocalDateTime expireTime;
private Object data;
}装饰器模式:通过将对象放入包含行为的特殊包装类中来为原始对象动态的添加新行为。这种模式是继承的一种替代方案,可以灵活的扩展对象的功能,在shopserviceImpl中添加如下code
public void saveShop2Redis(Long id, Long expireSeconds){
//1.查询店铺数据
Shop shop = getById(id);
//2.封装逻辑过期时间
RedisData redisData = new RedisData();
redisData.setData(shop);
redisData.setExpireTime(LocalDateTime.now().
plusSeconds(expireSeconds));
//3.写入Redis
stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY+id, JSONUtil.toJsonStr(redisData));
}修改启动项的HmDianPingApplicationTests.java(test一定要junit的api的test)
package com.hmdp;
import com.hmdp.service.impl.ShopServiceImpl;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
import javax.annotation.Resource;
@SpringBootTest
class HmDianPingApplicationTests {
@Resource
private ShopServiceImpl shopService;
@Test
public void testSaveShop(){
shopService.saveShop2Redis(1L,10L);
}
}点击test左边的绿色三角, 正确运行设置逻辑过期时间
正确运行设置逻辑过期时间
{
"data": {
"area": "大关",
"openHours": "10:00-22:00",
"sold": 4215,
"images": "https://qcloud.dpfile.com/pc/jiclIsCKmOI2arxK
N1Uf0Hx3PucI
JH8q0QSz-Z8llzcN56-_QiKuOvyio1OOxsRtFoXqu0G3iT2T27qat3WhLVEuLYk00OmSS1
IdNpm8K8sG4JN9RIm2mTK
cbLtc2o2vfCF2ubeXzk49OsGrXt_KYDCngOyCwZK-s3fqawWswzk.jpg,https://qcloud.
dpfile.com
/pc/IOf6VX3qaBgFXF
Vgp75w-KKJmWZjFc8GXDU8g9bQC6YGCpAmG00QbfT4vCCBj7njuzFvxlbkWx5uwqY2qcjixFEuLYk
00OmSS1IdNpm8K8sG4JN9RIm2mTKcbLtc2o2vmIU_8ZGOT1OjpJmLxG6urQ.jpg",
"address": "金华路锦昌文华苑29号",
"comments": 3035,
"avgPrice": 80,
"updateTime": 1642066339000,
"score": 37,
"createTime": 1640167839000,
"name": "103茶餐厅",
"x": 120.149192,
"y": 30.316078,
"typeId": 1,
"id": 1
},
"expireTime": 1744298913115
}
package com.hmdp.service.impl;
import cn.hutool.core.util.BooleanUtil;
import cn.hutool.core.util.StrUtil;
import cn.hutool.json.JSONObject;
import cn.hutool.json.JSONUtil;
import com.hmdp.dto.Result;
import com.hmdp.entity.Shop;
import com.hmdp.mapper.ShopMapper;
import com.hmdp.service.IShopService;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.hmdp.utils.RedisData;
import org.apache.ibatis.annotations.Results;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import javax.annotation.Resource;
import java.time.LocalDateTime;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
import static com.hmdp.utils.RedisConstants.*;
/**
* <p>
* 服务实现类
* </p>
*
* @author 虎哥
* @since 2021-12-22
*/
@Service
public class ShopServiceImpl extends ServiceImpl<ShopMapper, Shop> implements IShopService {
@Resource
private StringRedisTemplate stringRedisTemplate;
@Override
public Result queryById(Long id) {
//缓存穿透
//Shop shop=queryWithPassThrough(id);
//互斥锁解决缓存击穿
//Shop shop = queryWithMutex(id);
//逻辑过期解决缓存击穿
Shop shop=queryWithLogicslExpire(id);
if (shop == null) {
return Result.fail("店铺不存在!");
}
//7.返回
return Result.ok(shop);
}
private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);
public Shop queryWithLogicslExpire(Long id) {
String key = CACHE_SHOP_KEY + id;
// 1.从redis查询商铺缓存
String shopJson = stringRedisTemplate.opsForValue().get(key);
// 2.判断是否存在
//为什么不用考虑缓存穿透的情况,因为所有的数据都放入到redis中预热了,一旦缓存查询出是null的,
//说明数据库没这个数据
if (StrUtil.isBlank(shopJson)) {
// 3.存在,直接返回
return null;
}
//缓存击穿就是解决热点key的,热点key直接去查数据库会爆的,所以会直接存到redis缓存中,和数据库没有关系
//这个逻辑还是有问题的,我更新店铺信息,肯定要删除缓存的,那么在这里肯定是未命中的,这啥呀
//4.命中,需要先把json反序列化为对象
//泛型处理RedisData redisData = JSONUtil.toBean(shopJson, new TypeReference<RedisData<Shop>>() {}, false);
RedisData redisData=JSONUtil.toBean(shopJson,RedisData.class);
Shop shop=JSONUtil.toBean((JSONObject)redisData.getData(),Shop.class);
LocalDateTime expireTime =redisData.getExpireTime();
//加了泛型会在编译的时候被擦除,获得依旧是JSON;
// Object对象强转的自己试一下再来吧,老师都说了 拿到的实际是JSONObject,不能强转为shop
//泛型的用这个:JSONUtil.toBean(shopJson, new TypeReference<RedisData<Shop>>() {}, false)
//5.判断是否过期
if(expireTime.isAfter(LocalDateTime.now())) {
//5.1.未过期,直接返回店铺信息
return shop;
}
//5.2.已过期,需要缓存重建
//6.缓存重建
//6.1.获取互厅锁
String lockKey=LOCK_SHOP_KEY+id;
boolean isLock=tryLock(lockKey);
//6.2.判断是否获取锁成功
if(isLock) {
//6.3.成功,开启独立线程,实现缓存重建
//注意:获取锁成功应该再次检测redis,缓存是否过期,做DoubleCheck,如果存在则无需重建缓存。
//这里需要双重检查!如果线程a还没走到获取锁这步,b已经重建完释放锁了,那么a就会拿到锁再次重建;
// 不双重检查的话后面的线程无脑重建缓存,哪怕缓存已经是正确的了
CACHE_REBUILD_EXECUTOR.submit(()-> {
try {
///重建缓存I
this.saveShop2Redis(id, 20L);
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
//释放锁
unlock(lockKey);
}
});
}
//6.4.返回过期的商铺信息
return shop;
}
public Shop queryWithMutex(Long id) {
String key = CACHE_SHOP_KEY + id;
// 1.从redis查询商铺缓存
String shopJson = stringRedisTemplate.opsForValue().get(key);
// 2.判断是否存在
if (StrUtil.isNotBlank(shopJson)) {
// 3.存在,直接返回
return JSONUtil.toBean(shopJson, Shop.class);
}
//这个地方根本不用判断,除非前端代码被黑了
//判断命中的是否是空值
if (shopJson != null) {
//返回一个错误信息
return null;
}
//4.实现缓存重建
//4.1.获取互斥锁
String lockKey = "lock:shop:" + id;
Shop shop = null;
try {
boolean isLock = tryLock(lockKey);
//4.2.判断是否获取成功
if (!isLock) {
//4.3.失败,则休眠并重试
Thread.sleep(50);
return queryWithMutex(id);
}
/*注意:获取锁成功应该再次检测redis 缓存是否存在,做DoubleCheck。如果存在则无需重建缓存。*/
//重新把第一步和第二步的代码拷贝一下,放在4.4前面就行
// 4.4.success,根据id查询数据库
shop = getById(id);
// 5.不存在,返回错误
if (shop == null) {
//将空值写入redis
stringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);
return null;
}
// 6.存在,写入redis
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop), CACHE_SHOP_TTL, TimeUnit.MINUTES);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
// 7.释放互斥锁
unlock(lockKey);
}
// 8.返回
return shop;
//高并发的情况下,自旋你得CPU足够多,否则上下文切换,一样一直阻塞。
//这里有问题,当你休眠之后若没有修改完,那么他就会去释放锁,但是修改的那个还没有改完,这样不就会报错吗
// 这里的finally里的unlock会在前面的return 递归前执行,也就是说会先释放锁
}
public Shop queryWithPassThrough(Long id) {
String key = CACHE_SHOP_KEY + id;
// 1.从redis查询商铺缓存
String shopJson = stringRedisTemplate.opsForValue().get(key);
// 2.判断是否存在
if (StrUtil.isNotBlank(shopJson)) {
// 3.存在,直接返回
Shop shop = JSONUtil.toBean(shopJson, Shop.class);
return shop;
}
//这个地方根本不用判断,除非前端代码被黑了
//判断命中的是否是空值
if (shopJson != null) {
//返回一个错误信息
return null;
}
// 4.不存在,根据id查询数据库
Shop shop = getById(id);
// 5.不存在,返回错误
if (shop == null) {
//将空值写入redis
stringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);
return null;
}
// 6.存在,写入redis
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop), CACHE_SHOP_TTL, TimeUnit.MINUTES);
// 7.返回
return shop;
}
private boolean tryLock(String key) {
Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "", CACHE_NULL_TTL, TimeUnit.SECONDS);
return BooleanUtil.isTrue(flag); //拆箱底层就是调用booleanValue()方法,如果flag为null的话就会空指针异常,自动拆箱会出现空指针
}
private void unlock(String key) {
stringRedisTemplate.delete(key);
}
public void saveShop2Redis(Long id, Long expireSeconds){
//1.查询店铺数据
Shop shop = getById(id);
//2.封装逻辑过期时间
RedisData redisData = new RedisData();
redisData.setData(shop);
redisData.setExpireTime(LocalDateTime.now().
plusSeconds(expireSeconds));
//3.写入Redis
stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY+id, JSONUtil.toJsonStr(redisData));
}
@Override
@Transactional
public Result update(Shop shop) {
Long id =shop.getId();
if(id==null){
return Result.fail("店铺id不能为空!");
}
updateById(shop);
stringRedisTemplate.delete(CACHE_SHOP_KEY+id);
return Result.ok();
}
}
这里如果缓存中没有就一直返回不存在,现在redis中的是103餐厅,我们修改sql,改成101

jmeter设置成100请求在1s内完成。如期修改

缓存工具封装
基于StringRedisTemplate封装一个缓存工具类,满足下列需求:
- 方法1:将任意Java对象序列化为json并存储在string类型的key中,并且可以设置TTL过期时间
- 方法2:将任意Java对象序列化为json并存储在string类型的key中,并且可以设置逻辑过期时间,用于处理缓存击穿问题
- 方法3:根据指定的key查询缓存,并反序列化为指定类型,利用缓存空值的方式解决缓存穿透问题
- 方法4:根据指定的key查询缓存,并反序列化为指定类型,需要利用逻辑过期解决缓存击穿问题
在utils中新建cacheclient
泛型出错会在编译器报错,object出错就是运行时异常了
package com.hmdp.utils;
import cn.hutool.core.util.StrUtil;
import cn.hutool.json.JSONUtil;
import io.lettuce.core.GeoArgs;
import lombok.extern.slf4j.Slf4j;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Component;
import java.time.LocalDateTime;
import java.util.concurrent.TimeUnit;
import java.util.function.Function;
import static com.hmdp.utils.RedisConstants.CACHE_NULL_TTL;
@Slf4j
@Component
public class CacheClient {
private final StringRedisTemplate stringRedisTemplate;
public CacheClient(StringRedisTemplate stringRedisTemplate) {
this.stringRedisTemplate = stringRedisTemplate;
}
public void set(String key, Object value, Long time, TimeUnit unit) {
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(value), time, unit);
}
public void setWithLogicalExpire(String key, Object value, Long time, TimeUnit unit){
//设置逻辑过期
RedisData redisData = new RedisData();
redisData.setData(value);
redisData.setExpireTime(LocalDateTime.now().plusSeconds(unit.toSeconds(time)));
//写入Redis
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(value));
}
public <R, ID> R queryWithPassThrough(String keyPrefix, ID id , Class<R> type, Function<ID,R> dbFallback,Long time, TimeUnit unit) {
String key = keyPrefix + id;
//1.从redis查询商铺缓存
String json = stringRedisTemplate.opsForValue().get(key);
//2.判断是否存在
if (StrUtil.isNotBlank(json))
//3.存在,直接返回
return JSONUtil.toBean(json, type);
//判断命中的是否是空值
if(json !=null){
//返回一个错误信息
return null;
}
//4.不存在,根据id查询数据库
R r= dbFallback.apply(id);
//5.不存在,返回错误
if(r== null) {
//将空值写入redis
stringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);
//返回错误信息
return null;
}
//6.存在,写入redis
this.set(key,r, time, unit);
return r;
}
}
修改shopserviceimpl
@Override
public Result queryById(Long id) {
//解决缓存穿透
Shop shop = cacheClient.queryWithPassThrough(CACHE_SHOP_KEY,id,Shop.class,this::getById,CACHE_SHOP_TTL,TimeUnit.MINUTES);
if (shop == null) {
return Result.fail("店铺不存在!");
}
//7.返回
return Result.ok(shop);
}
把queryWithMutex注释掉进一步集合 CacheClient
package com.hmdp.utils;
import cn.hutool.core.util.BooleanUtil;
import cn.hutool.core.util.StrUtil;
import cn.hutool.json.JSONObject;
import cn.hutool.json.JSONUtil;
import io.lettuce.core.GeoArgs;
import lombok.extern.slf4j.Slf4j;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Component;
import java.time.LocalDateTime;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
import java.util.function.Function;
import static com.hmdp.utils.RedisConstants.CACHE_NULL_TTL;
import static com.hmdp.utils.RedisConstants.LOCK_SHOP_KEY;
@Slf4j
@Component
public class CacheClient {
private final StringRedisTemplate stringRedisTemplate;
public CacheClient(StringRedisTemplate stringRedisTemplate) {
this.stringRedisTemplate = stringRedisTemplate;
}
public void set(String key, Object value, Long time, TimeUnit unit) {
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(value), time, unit);
}
public void setWithLogicalExpire(String key, Object value, Long time, TimeUnit unit){
//设置逻辑过期
RedisData redisData = new RedisData();
redisData.setData(value);
redisData.setExpireTime(LocalDateTime.now().plusSeconds(unit.toSeconds(time)));
//写入Redis
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(redisData));
}
public <R, ID> R queryWithPassThrough(String keyPrefix, ID id , Class<R> type, Function<ID,R> dbFallback,Long time, TimeUnit unit) {
String key = keyPrefix + id;
//1.从redis查询商铺缓存
String json = stringRedisTemplate.opsForValue().get(key);
//2.判断是否存在
if (StrUtil.isNotBlank(json))
//3.存在,直接返回
return JSONUtil.toBean(json, type);
//判断命中的是否是空值
if(json !=null){
//返回一个错误信息
return null;
}
//4.不存在,根据id查询数据库
R r= dbFallback.apply(id);
//5.不存在,返回错误
if(r== null) {
//将空值写入redis
stringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);
//返回错误信息
return null;
}
//6.存在,写入redis
this.set(key,r, time, unit);
return r;
}
private static final ExecutorService CACHE_REBUILD_EXECUTOR= Executors.newCachedThreadPool();
public <R, ID> R queryWithLogicalExpire(String keyPrefix, ID id, Class<R> type, Function<ID, R> dbFallback,Long time, TimeUnit unit) {
String key = keyPrefix + id;
// 1.从Redis查询商铺缓存
String json = stringRedisTemplate.opsForValue().get(key);
// 2.判断是否存在
if (StrUtil.isBlank(json)) {
// 3.存在,直接返回
return null;
}
// 从Redis中,需要先把json反序列化为对象
RedisData redisData = JSONUtil.toBean(json, RedisData.class);
R r = JSONUtil.toBean((JSONObject) redisData.getData(), type);
LocalDateTime expireTime = redisData.getExpireTime();
//5.判断是否过期
if(expireTime.isAfter(LocalDateTime.now())){
//5.1.未过期,直接返回店铺信息
return r;
}
//5.2.已过期,需要缓存重建
//6.缓存重建
//6.1.获取互斥锁
String lockKey = LOCK_SHOP_KEY + id;
boolean isLock = tryLock(lockKey);
//6.2.判断是否获取锁成功
if(isLock){
//6.3.成功。开启独立线程,实现缓存重建
CACHE_REBUILD_EXECUTOR.submit(() -> {
try {
//查询数据库
R r1 =dbFallback.apply(id);
//写入redis
this.setWithLogicalExpire(key,r1,time,unit);
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
//释放锁
unlock(lockKey);
}
});
}
//6.4.返回过期的商铺信息
return r;
}
private boolean tryLock(String key) {
Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "", CACHE_NULL_TTL, TimeUnit.SECONDS);
return BooleanUtil.isTrue(flag); //拆箱底层就是调用booleanValue()方法,如果flag为null的话就会空指针异常,自动拆箱会出现空指针
}
private void unlock(String key) {
stringRedisTemplate.delete(key);
}
}
修改HmDianPingApplicationTests.java
package com.hmdp;
import com.hmdp.entity.Shop;
import com.hmdp.service.impl.ShopServiceImpl;
import com.hmdp.utils.CacheClient;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.cache.CacheManager;
import org.springframework.data.redis.core.RedisTemplate;
import javax.annotation.Resource;
import java.util.concurrent.TimeUnit;
import static com.hmdp.utils.RedisConstants.CACHE_SHOP_KEY;
@SpringBootTest
class HmDianPingApplicationTests {
@Resource
private ShopServiceImpl shopService;
@Resource
private CacheClient cacheClient;
@Test
void testSaveShop()throws InterruptedException {
Shop shop= shopService.getById(1L);
cacheClient.setWithLogicalExpire(CACHE_SHOP_KEY+1L,shop, 10L,TimeUnit.SECONDS);
}
}
 成功出现,这种泛型与函数式接口的应用给我打开的新世界的大门;看着简单,自己实际遇到一个问题想要封装成这样,就很困难了😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭
成功出现,这种泛型与函数式接口的应用给我打开的新世界的大门;看着简单,自己实际遇到一个问题想要封装成这样,就很困难了😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭
缓存总结
好,那么在本章的最后呢给大家总结一下啊,我们整个这一章所学的知识点,在这呢就罗列了一下啊,嗯我们总共是有七张,首先是带人家去认识缓存,然后呢就是去实现这个瑞士缓存啊,解决这个上诉查询内问题,然后呢就是缓存更新呀,穿透雪崩击穿啊等等这些热点的问题了啊,那在认识缓存这一块呢,我们其实是主要啊讲了三个点啊,第一就是什么是缓存啊,缓存呢就是一种具备高效读写能力的数据缓存区啊,它可以去啊把数据暂存起来,因为它的读写能力比较强,所以说呢他的查询效率啊,写的效率都会比较高啊,同时也可以减轻啊对于我们后端的压力啊,所以这是它的一个作用啊,降低后端负载和提高多少显应速度,那它带来的一个成本呢主要就是三点啊,一般是开发的成本,那加了缓存以后啊,它的代码就会比较复杂了,那通过我们后面讲解,大家也发现了对吧,那第二个呢是运维的成本啊,那首先呢rise为了保证高可用,将来要去做集群,那么这些集群的部署,其实就会给运维带来很多的麻烦啊,并且呢你去部署这些啊大量的集群还需要一些机器这样一些经济上的一些成本对吧啊,那最后呢还有就是s会有这样一个一致性的问题,这就是我们传说中的双写一致性对吧,数据库和缓存里都有数据,能怎么保证两者数据是一致的啊,那这其实就要靠我们缓存更新的一个策略去维护了啊,好这是第一部分,第二部分呢我们就是添加缓存这块,没什么好聊的,就是呢在查询数据的时候,优先查缓存,缓存未命中啊,再查数据库啊,当然了,这样是一个基本模型啊,那后来我们发现这个模型存在好多好多问题,所以呢我们就去解决它对吧,那在我们3456啊这几节都是在解决问题的,比方说缓存更新,那么它解决的其实就是一致性的问题啊,在缓存更新里边呢,我们讲了有三种策略啊,内存淘汰,过期淘汰和主动更新,n淘汰呢是rate里面自带的一种这样一种机制啊,默认呢它可以采用lru的一种方式啊,当然我们也可以自己配各种不同的策略啊,那么当rise的内存不足的时候,它就会将部分数据给它淘汰掉,清空一些空间出来啊,然后去存储新的数据,那利用这种方式呢可以一定程度上保证这个数据可以得到更新,但是呢它的这种更新的时间也好啊,周期也好,都是不可控的,所以说呢这种方案呢它的一致性是比较差的啊,但它的好处就是简单,你不用管哈,那第二种方法过去淘汰,过去淘汰呢是利用pl命令给我们的key是指ttl过期时间,那么到期以后自动就会清除,那一旦清除了缓存,下次再查询自然就会查数据库得到最新数据了,所以呢这种方案的话,它是可以人为控制ttl时间从而来保证这个更新频率的,不过呢在更新时间啊,ttl过期之前的这一段时间啊,如果数据库发生变更,还是会出现不一致的情况,所以说呢它的一致性比内存淘汰这种方法好,但还不是强的这种一致性,并且呢这种方式也会存在一些问题啊,后期呢我们也讲过啊,怎么去解决定的这些问题,第三种方法是主动更新,主动更新呢就是我们去写代码的时候,主动的在更新数据库的同时,把缓存也给更新了啊,这是主动更新,但是呢主动更新实现起来比较复杂,我们讲过主动更新有很多种不同的方案对吧,那么在地质需求的情况下,我们建议大家使用内存淘汰和过期这种方式就行了啊,因为它比较简单啊,而对于一些数据啊有高一致性需求的了,你再去使用主动更新啊,主动更新为主,过期淘汰去兜底,因为主动更新啊他也不能百分之百保证一致,万一出现问题了呢,还有一个过期的策略,就做一个兜底啊,而主动更新呢我们讲常见的有三种方案catch said read rush through和rebe呃,这三种方案呢后两种虽然都挺优秀的,但是实现起来相对比较复杂,而且呢最后一种write back呢它的一致性还比较差,所以说呢我们一般呢没有选择后两种,都是选择第一种catch set,那个cch set呢,它其实就是由调用者自己更新数据库的同时去更新缓存,但是呢这种方案在实现的时候呢,他就需要考虑几个问题啊,就是你更新缓存是删缓存还是更新缓存啊,那这两个呢其实它的区别主要就在于什么呢,你更新的话,在于是每次更新数据库都要更新缓存,这样来如果用户不查啊,他只是在更新,那你就有很多无效的更新,对不对啊,所以说呢有很多无效操作啊,另外呢,其实我们没有给大家分析,更新缓存的安全问题啊,大家可以自己尝试去分析一下啊,采用更新缓存方案会有很大的线程安全的问题,所以说呢这也是我们不选择更新缓存的一个原因,而删除缓存呢相对来讲,他第一呢是没有这种无效的更新,因为你更新完了数据库,我只是删缓存,我不更新,它什么时候更新呢,当用户查的时候再更新,没有人查我就不更新,所以没有无效更新,其次呢,它的线程安全问题出现的概率相对比较低,而且我们还可以去控制它,对吧好,这是这两个选择,然后选择了删除或者更新以后,你还要判断是先删除还是先投的数据库,还是先投的缓存好,先操作数据库啊,再去操作缓存,这种方案呢它的安全性相对较高,出现问题的概率比较低,而先删缓存再操作数据库呢,它的安全问题出现的概率会相对较高一点啊,所以说最终我们选择第一种啊,先更新数据库,再删缓存方案,当然这里是有个前提的,就是这两个操作要确保原子性,如果你不能确保原子性的话,那就白扯啊,那就完蛋了,那怎么保证原子性呢,这里单体系统我们是利用了事物的机制,分布式系统的话,我们就利用分布式事务机制,来确保整体的一个原子性啊,要么都成功,要么都失败是吧好,那么最后的最佳时间呢其实就是这样了,在查询的时候呢,先查缓存,缓存命中,直接返回缓存未命中,再去查数据库,然后呢将数据库数据啊还给他写到缓存里去,确保下一次能够命中,而在修改的时候呢,我们会先修改数据库,再删缓存,确保两者的原子性唉,这是缓存更新的一个策略啊,那缓存穿透啊,那么它产生的原因主要是在于用户查询的数据,在缓存和数据库中都没有,那既然都没有,那就永远不可能有缓存,那就永远查的数据库,那那些不怀好意的人啊,不停的去访问这样的数据,那就会给你的数据库带来巨大压力啊,所以说呢那我们要解决它呢,就有两种常见方案,一种是缓存空对象,一种是布隆过滤,很多空对象比较简单暴力,就是你来查不存在不存在,我就给你放个空的进去不就好了,下次来我就照样给你返回空,那这样来缓存就有了啊,就不会查数据库了啊,所以呢它的优点就是简单啊方便,但它的缺点呢就是会带来额外的内存消耗啊,因为你空直接存进去了,对不对啊,而且呢还会有一致数据不一致的情况发生,比方说你一开始是没有,后来有了,而你存的还是那个空值,这不就不一致了吗,所以啊会存在这样的一些问题,而第二种的布隆过滤啊,它是利用布隆过滤的算法,在进入rise之前先判断存不存在,如果不存在啊,根本就不给你往后访问的机会,所以呢他这种方案的话,是在前置去做了拦截的啊,但是呢它有一个问题就是什么,它实现起来比较复杂,而且还有误判的可能,因为它采用这种不同过滤算法是一种统计的啊,基于二进制位的方式进行一个统计,它不一定百分之百是准确的啊,所以说呢这种方案呢存在误判可能性,因此呢从这个角度考虑啊,我们一般选择缓存空对象,因为它比较简单,而且呢实现起来也比较方便一点啊,虽然说有额外内存消耗,但是我们可以通过设置过期时间的方式,来去弥补啊,那当然还有一些其他的方案,我们以前也聊到过,比如说是做好这种基础的数据格式的校验,如果id不符合我们的规范,比如说传了个零,那你就应该直接拒绝,而不是让他访问,对不对,还有呢做一些用户权限的经验,还有热电参数的一些限流啊,这些都是可以去做的好,那么很多血崩的问题呢,他是因为k过期导致的,比如说有无数的k啊,非常非常多同时到期,那这样一来这也可以,虽然单个可以访问量不大,但是因为过期的比较多,这样一来访问量就大了,那么就会给数据库带来积攒一下压力啊,还有一种可能性呢就是rise直接挂了,race一旦挂了,那请求肯定直接打到数据库了呀是吧,这两种情况呢可能就是导致雪崩,好直接呢就是把数据库给整卡了,那它的解决方案就是针对这两个点,第一个是同时过期,第二是宕机站在亭,同时当同时过期的这个问题呢,你可以给他的过期时间啊,加上随机值,让他们的过期时间不一样,这样就不会同时过期了,而针对宕机的情况呢,我们首先是要建立集群对吧,利用我们瑞士哨兵啊,而是集群啊,这样的方案确保高可用性啊,另外呢我们还可以给缓存的业务啊,去添加这种限流,降级,还有隔离的这种策略啊,那么这种隔离和降级的策略呢,在陈瑞斯失败的时候,他不会说直接就去打到数据库了,有可能呢可以去做一个降级,快速失败啊,避免的业务继续往后进行,这样就可以给我们的数据库带来一些保护措施了,是吧啊,另外呢我们也可以利用这种多级缓存的方案啊,那多级缓存方案呢,就是在我们从请求进入浏览器发出,一直到最后到我们服务端的这整个流程当中啊,添加多种不同的缓存啊,一个不行,总有另外一个缓存吧,总不可能所有缓存都挂了,对不对,所以说呢通过这种方案呢,一级一的去拦,从而保证整个后端的一个安全啊,那么缓存击穿呢,这个问题产生的原因,往往是因为一些热点的k啊,热点可以满足两个特点,首先呢就是高并发,其次呢就是缓存的重建时间比较长啊,那么因为缓存重建时间比较长,那么在它重建的过程当中,缓存是不存在的,那这个时候又因为它时间比较长,在这一段时间内,无数的请求就会涌进来对吧,因为它高并发嘛,那么这样一来呢,这些请求查不到缓存,都会去查数据库,那么就会导致我们的数据库啊,产生巨大的一个压力啊,甚至出现宕机的情况,那针对这种问题呢,我们要解决的就是干什么呢,就是热点key再去重建的时候,不要有无数的先生进来,那怎么让它不要有无数性能进来呢,第一种方案会是锁,那也就是说加个锁呗,重建的时候我加个锁,只能一个线程来重建,其他线程等待不就好了,这个思路是非常简单粗暴的,所以它的优点就是实现简单,但是呢它会带来啊一些其他的问题啊,因为你要等你要等的话,就会有性能的下降,并且还有死锁的一个风险啊,而第二种方案是逻辑过期,逻辑过期呢就是我们甚至可以永不过期,不过期,那就不需要重建,不需要重建,是不是就不会给数据库带来压力了啊,当然了,那如果说不做重建,那永远都是旧的数据也不行,所以我们会加一个逻辑过期时间啊,每次查到数据以后呢,我们会判断一下这个k啊是不是已经过期了,需要更新啊,如果是我再去更新,那么这个时候如果有n多的线程都来判断,发现要更新,那不还会有问题吗,所以我们还要加互斥锁,但是呢你加了护士锁后那不就跟之前一样,所以呢为了避免这个问题呢,我们加了护士锁后不是自己去更新,我们会让他开启一个独立的线程去做更新,那么我们的在这个独立线程去更新缓存的这个时间段内,其他所有的行程不用等,而是直接查到什么就用什么就行了,而是用旧的数据,这样呢就解决了这个等待导致的性能下降和死锁的问题了,不过呢同样是因为这个问题,那么因为你不用等查拿到什么就用什么,那很有可能你拿到的就是旧数据,对不对,实际上它会有这样的一个不一致的情况发生啊,好嗯这是缓存击穿的这些解决方案啊,嗯那么最后我们还带着大家封装的工具类,在封装工具类的时候,主要是利用了我们java提供的这个函数式编程这种思想啊,去将数据库查询啊传递给我们的工具类,从而实现任意数据的这样一个数据库查询,缓存的这种同步策略都给他加入进去了,所以说呢这是一个小技巧啊,嗯那么以上呢就是我们raise缓存的常见的一些使用技巧和解决方案啊,嗯除了这些以外,还有一些像多级缓存啊,还有rise的缓存集群等等,这样的一些高级的知识点啊,我们呢也会在rise的高级课程当中啊,继续给大家去讲解,所以说呢大家呢紧跟我们的课程啊,千万不要半途而废,那么学完以后绝对会给大家带来巨大的收获啊,行吧,那我们这章内容呢就到这里,我们下周再见啊。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









