






AIGC和生成式AI的关系:

AIGC:AI generate content
关系概览
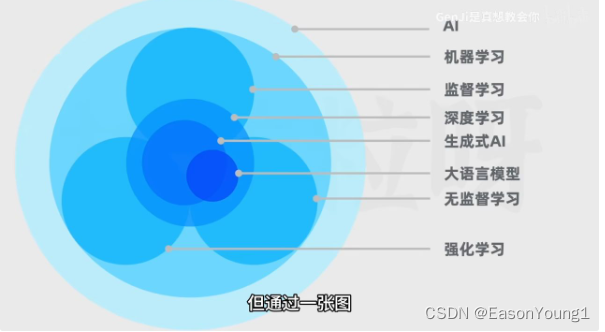

监督学习:类似于指令学习,给定一个范式,在这个范式范围内的学习,有一定的目的
无监督学习:类似案例学习,在海量的实际案例中学习,从中抽象出一定的规律
LLM大语言模型(Large Mode Language)
从输入和输出上看分为:
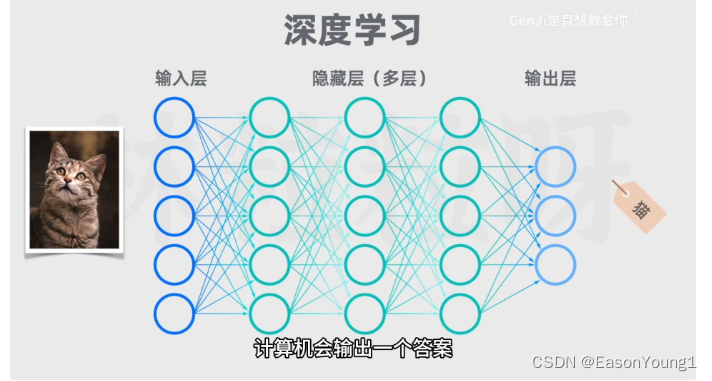
大语言模型的大体现在:训练的数据量大 和 模型自身的参数多

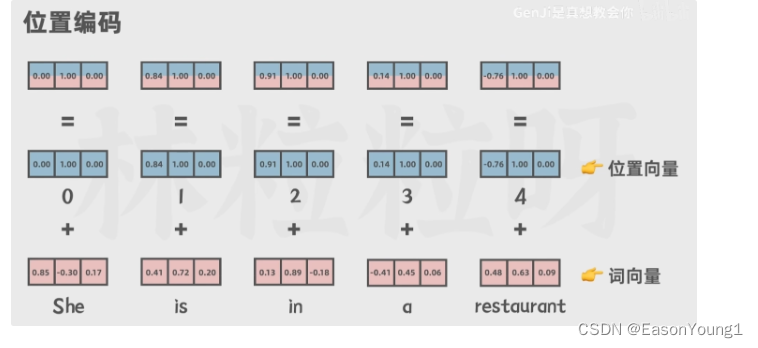
输入的提示词(prompt)会被拆解为一个个token(最小字符组成单位),GPT会分析每个token的权重以及每个token之间的关系。也叫自注意力机制 和 位置编码。

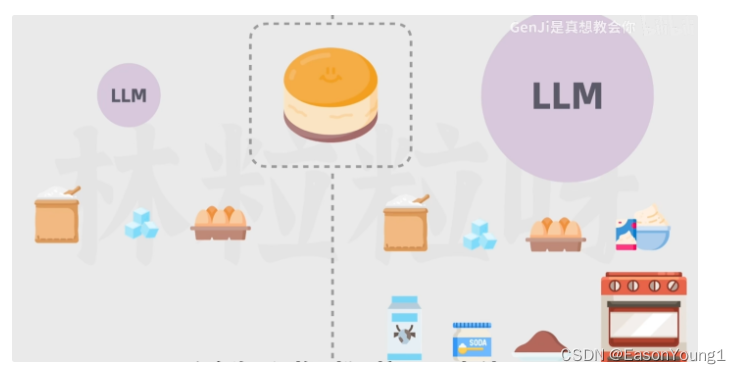
要想生成理想的效果,LLM的输入数据必须多 和 可调参数必须大。就像做蛋糕,材料和工具越多,意味着可塑性越强,越能得到美味的蛋糕。
attention is all you need
transformer模型会关注每个词的权重,以及和其他词的关系
transformer模型:输入、编码器、解码器、输出

- 编码器部分:
输入的文本会被token化(文本的最小组成部分),拆解为一个个词,再分配一个token ID

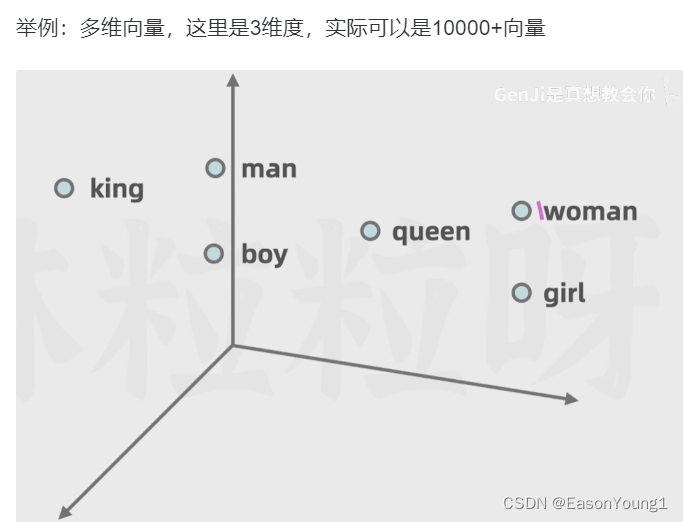
然后进入嵌入层,在原来的token上封装成多维向量,上面有每一个token更多的细节信息
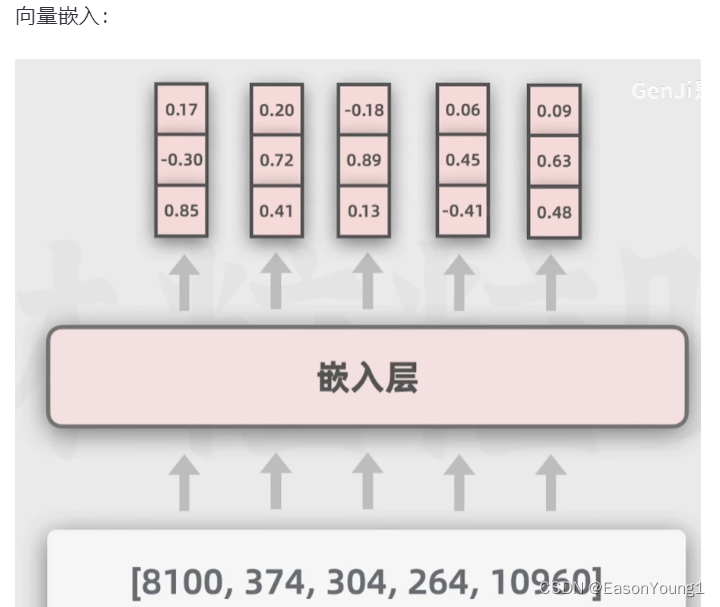
实际上编码器部分不止一个,可以由多个编码器连接
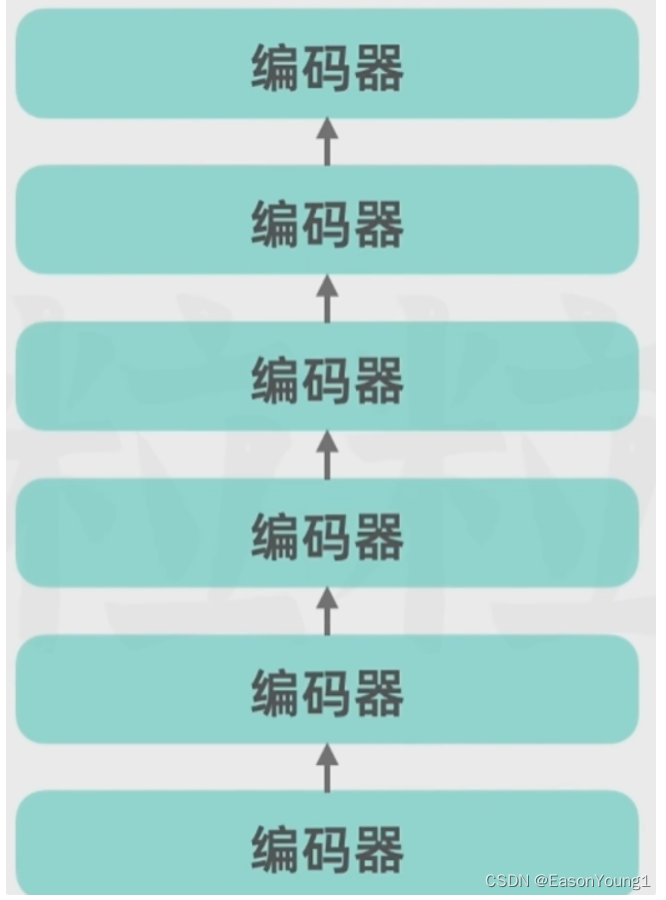
- 解码器部分
解码器会忽视当前词的后面部分,而专注当前词的前面部分

解码器也可以存在多个连接
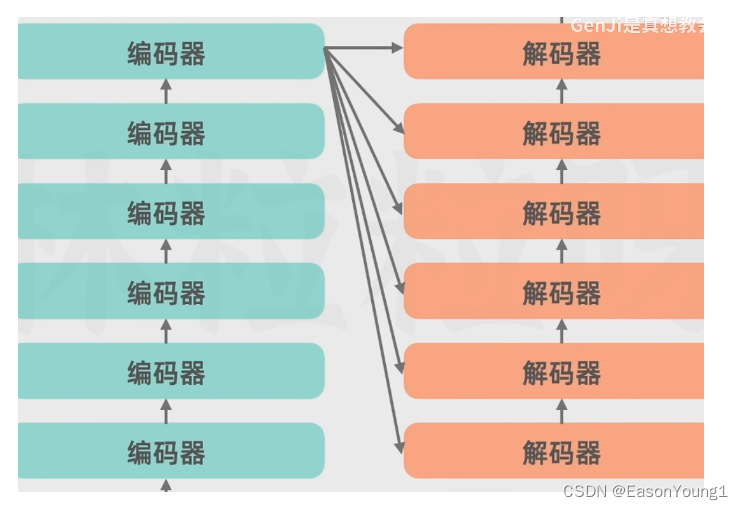
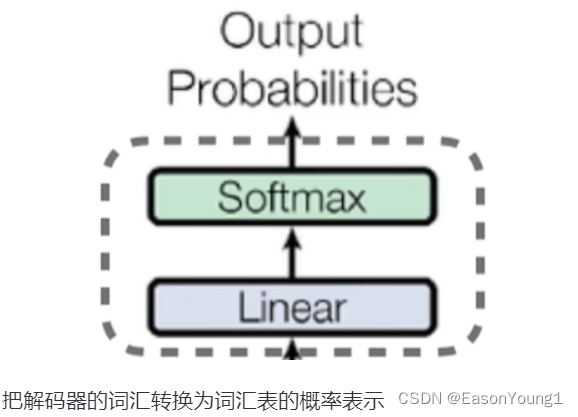
- 输出部分
transform模型的变种
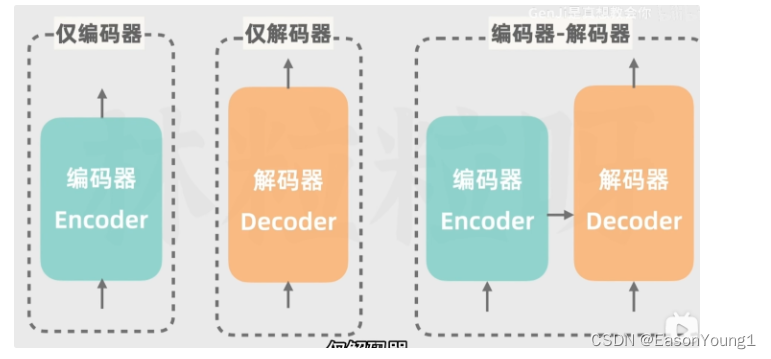
仅编码器:如谷歌的Bard
仅解码器:如GPT
AI存在的局限

捏造事实:生成的内容是靠‘猜’的,所以只能保证文字的连贯性,但是内容真实性无法保真
计算不正确:实际上AIGC并不能直接数学运算
数据过时:训练的数据具有时效性,训练的材料过时
prompt改进办法:

小样本提示:在提示词中加入一些案例,让AI解决同样的问题
思维链:把复杂的问题拆解,让AI回答
分步骤思考:在prompt中加入:’step by step‘ 关键词
AIGC辅助:

-
RAG:retrieval augmented generation
让模型访问外部文档,获得实时数据,获得更好的回答。外部材料分段,并生成一系列向量,并保存在数据库中。此时输入提示词,也转换成向量,并在数据库中查找。最后查找的结果和提示词一并提交给gpt,生成可靠的结果。


-
PAL:program-aided language models
借助思维链,把让ai生成解决问题的代码,再借助编程语言解释器返回结果 -

-ReAct: Reason + Action
提示词中借助思维链,让AI根据提示词,选择合适的外部工具检索,再返回检索的结果

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









