




 本文介绍了在数据库扩展和负载均衡中使用的一致性Hash算法,以及为解决数据倾斜问题引入的虚拟节点概念。通过一致性Hash算法,可以在节点增减时保持数据分布的稳定性,而虚拟节点则能有效平衡各个数据库的负载。
本文介绍了在数据库扩展和负载均衡中使用的一致性Hash算法,以及为解决数据倾斜问题引入的虚拟节点概念。通过一致性Hash算法,可以在节点增减时保持数据分布的稳定性,而虚拟节点则能有效平衡各个数据库的负载。
缘起
今天我们来说说“一致性Hash”算法,以及虚拟节点。
这并不是一个难理解的概念,希望一篇文章下来,你能完全吃透。
在网站系统发展初期,前辈工程师探索出了数据库这一系统核心组件,
数据的持久化被与系统本身解耦开,独立发展且愈加可靠。
时间往后推移,随着互联网的普及,一个系统需要承载的用户数量指数级增长,
开发者不得不横向扩展服务器,通过负载均衡技术,使用户分散到各个服务器上。
随着服务器的增多,可靠的数据库系统也不堪重负,
开发者不得不将数据库中的数据通过“分库分表”技术,切分到不同的数据库中,
减轻单一数据库系统的压力。
那么问题来了,如何知道我们需要的数据在哪个数据库中?
没错。hash!
正如我们在 HashMap 中做的一样,对参数取 hash 值,再对 hash 值取模,
就可以既均匀切分存储数据,又知道数据在哪个库中。
简单hash
举个例子,现在有A,B,C,D共4个库,和参数为1,2,3……9,10共10个数据。

我们简化hash算法为乘以1,
即 (1*1)%4=1,参数为1的数据落在A库中。
即 (2*1)%4=2,参数为2的数据落在B库中。
即 (3*1)%4=3,参数为3的数据落在C库中。
即 (4*1)%4=0,参数为4的数据落在D库中。
……
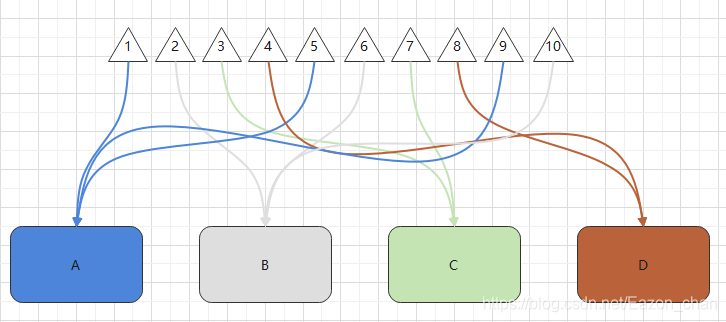
嗯!我很满意,一切井然有序。
当系统需要参
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章






















 491
491



 到【灌水乐园】发言
到【灌水乐园】发言









