







一、什么是数组
-
一组相同类型的变量,为了方便读写,采用另外一种表示形式
/*void Function(){ int v_0 = 1; int v_1 = 2; int v_2 = 3; int v_3 = 4; int v_4 = 5; int v_5 = 6; int v_6 = 7; int v_7 = 8; int v_8 = 9; int v_9 = 10; }*/ //使用数组表示 void Function(){ int arr[10] = {1,2,3,4,5,6,7,8,9,10}; } -
注意:在数组声明时,必须用常量来指明长度,不能使用变量
-
为什么数组声明时不能用变量来指明长度呢?
void Func(){ int x = 10; int arr[x] = {1,2,3,4,5,6,7,8,9,10}; //错误的!在数组声明时,必须用常量来指明长度(根据编译器版本决定是否可以,这里学的是不可以的) }从编译器给函数开辟缓冲区角度分析这个问题:我们先来看一看正常的数组是如何分配堆栈的
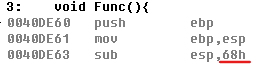

我们知道VC6编译器提升堆栈时开辟的缓冲区大小默认为0x40字节,每有一个局部变量就增加4字节,我们定义的数组大小为10个元素,即等于10个局部变量,任意类型的局部变量都用32位容器存储,上一章提过,所以这里要开辟40h + 28h大小的缓冲区。
但是现在如果我们定义成
int arr[x],数组的长度用一个变量表示,变量的值是不确定的且随时可以修改的,那么编译器就无法提前给数组分配好内存,就不知道要开辟多少缓冲区,所以数组声明时一定要用常量指明长度(先不提动态数组,后面学)
二、数组的使用
-
数组在使用时,可以通过常量、变量来定位数据
-
数组定位时,可以超过数组的长度,编译不会有错,但读取的数据是错的
void Function() { int arr[10] = {1,2,3,4,5,6,7,8,9,10}; int x = 1; int y = 2; int r ; r = arr[1]; r = arr[x]; r = arr[x+y]; r = arr[x*2+y]; r = arr[arr[1]+arr[2]]; r = arr[Add(1,2)]; int a5 = arr[100]; //不会报错 } -
数组中各元素赋初始值为0
int arr[5] = {0};
数组正向基础补充:
-
定义数组:
int num[100]; int a[] = {1,2,3,4}; int a[3] = {1}; //1,0,0 void max(int a[]){} void max(int* a){} -
二维数组列不能省略
int a[][3] = {{1,2,3},{4,5,6}}; -
&i:地址的长度是4字节还是8字节,取决于32位还是64位
-
指针是保存地址的变量
int* p = &i; //把变量i的地址传给p int *p,*q; -
*p是把p的地址中的值取出来
-
[]:可以对指针,也可以对数组做;还可以对指针做“p + 1“的操作
-
int* const b --> int b[] //b这个地址不能变,数组b不能再指向别的数组 const int* p = &i; //变量i的值不能变 -
指针可以做+,+=,-,-=,++,–,两个指针相减
-
*p++:先把p所指的值取出来,p指针再++(本质上++的优先级高于*) -
不同指针类型也可以相互转换
-
动态分配内存:·
int* a = (int*)malloc(number * sizeof(int));(字节为单位) -
只用free申请空间的首地址
三、数组反汇编
-
编译器会根据数组声明时指定的长度来开辟指定大小的空间,无论当中元素有没有赋初始值
-
数组元素存入缓冲区是正着存的,但是在栈中存的位置是从低地址向高地址存的,比如
int arr[3] = {1,2,3};,先把1存入[ebp-0xC],再将2存入[ebp-8],最后把3存入[ebp-4]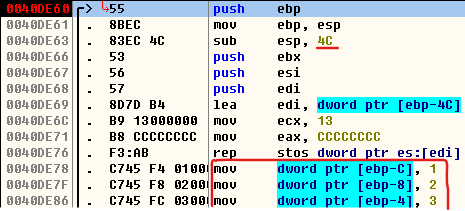
-
所以如果按照下标取数据:arr[0]取的是[ebp-0xC],arr[1]取的是[ebp-8],arr[2]取的是[ebp-4],arr[3]虽然越界了但是里面是有值的,即取的[ebp]中的值,即源栈底内存地址编号,arr[4]还是越界了但是取的是[ebp+4]中的值,即函数的返回地址值!!

四、作业
-
char arr[3] = {1,2,3};与char arr[4] = {1,2,3,4};,哪个更节省空间,从反汇编的角度来说明你的观点void Func(){ char arr[3] = {1,2,3}; } void Func2(){ char arr[4] = {1,2,3,4}; } void main(int argc,char* argv[]){ Func(); Func2(); }-
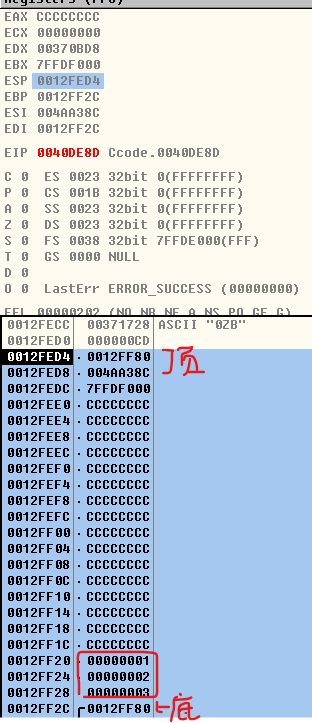
反汇编分析Func中的数组arr[3]:数组还是从正着从1存到3,但是是从低地址向高地址存,而且我们发现char类型的1,2,3,只需要占内存8bit,即一个字节,所以是byte,那么由于OD的堆栈一个地址0x12FF28表示4个内存块,即8字节,从右到左依次是0x12FF28,0x12FF29,0x12FF2A,0x12FF2B,即是[ebp-4],[ebp-3],[ebp-2],[ebp-1],那么由于char arr[3]只占用了0x12FF28的三个字节,剩下还有[ebp-1]就浪费了,如果有另外一个局部变量,那么就不能挨着存了,要从另外一个新的栈地址开始存

温馨提示:如果是用VC6的反汇编,那么0x12FF28也表示四个内存单元,但是它已经帮我们把顺序倒过来了,所以从左到右依次是[ebp-4],[ebp-3],[ebp-2],[ebp-1]

-
反汇编分析Fun2中arr[4]数组:可以看到arr[4]中元素的数据类型为char,即加起来一共占用内存空间4个字节,刚好是一个堆栈地址所表示的4个内存单元,即四个元素刚好存到0x0012FF28这个地址所表示四个内存单元中,分别是[ebp-4],[ebp-3],[ebp-2],[ebp-1]。不会浪费空间内存

-
综上是
char arr[4] = {1,2,3,4};更节省空间,但是注意其实不管是char arr[3]还是char arr[4],反正都是要占一个堆栈地址所表示的空间的,由于arr数组也是定义在函数的局部变量,所以最开始开辟的堆栈大小都是0x44字节,而且如果函数中定义了一个新的局部变量,不能从0x12FF28开始存了,即使有空位也不行,要存到0x12FF24即[ebp-8]中,两者的区别只是一个没有完整的利用好分配的4字节内存空间浪费了一个字节,另一个全部用完了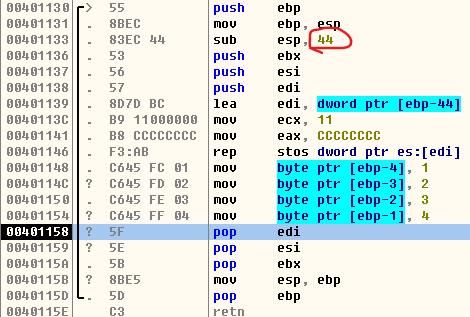
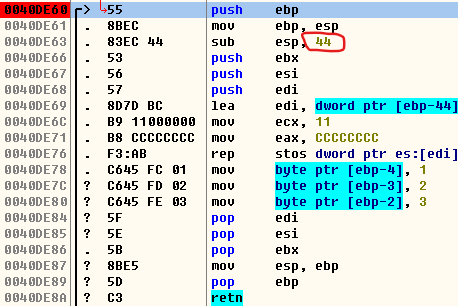
-
-
找出下面赋值过程的反汇编代码,体会如何根据下标在内存中找到对应的数组元素的
void Func(){ int x = 1; int y = 2; int r; int arr[10] = {1,2,3,4,5,6,7,8,9,10}; r = arr[1]; r = arr[x]; r = arr[x+y]; r = arr[x*2+y]; }-
分析反汇编:
-
因为Func函数中定义了13个局部变量,小于等于32位的任何类型的局部变量都会被分配32位内存来存储,所以VC6的编译器在提升堆栈时会开辟0x40 + 0x34h = 0x74字节的缓冲区
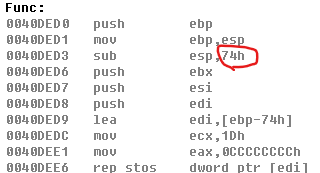
-
接着分析定义局部变量和赋值的反汇编:还是正着存局部变量,现存x = 1到[ebp - 4],再试y = 2到[ebp - 8],接着是int r,此时r会被分配内存空间[ebp - 0xC],但是没有赋值。接着就是存数组从1存到10,但是从低地址往高地址存,所以从[ebp - 0x34]每隔四个字节一直存到[ebp - 0x10]
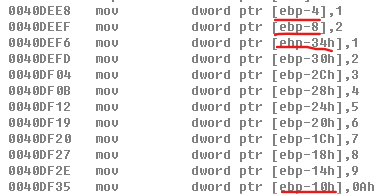
-
接着就开始分析如何根据下标找内存中数组元素:
-
如果是
arr[1]直接可以通过[ebp - 30h]来找到,因为从低地址[ebp - 34h]到高地址[ebp - 10h]分别是arr[0]到arr[9]
-
如果是
r = arr[x];,x也是一个局部变量,所以先把x的值从[ebp-4]中取出来赋给一个寄存器ecx,然后因为arr[0]所在地址为[ebp - 0x34],如果下标为1,则加一个0x4;如果下标为2,则加两个0x4。所以现在下标为寄存器ecx中存的值,那么就是[ebp - 34h + ecx * 4 ]
-
如果是
r = arr[x+y];,x和y都是局部变量,所以先把x的值从[ebp - 4]中取出来赋到一个寄存器eax中,同理也把y的值从[ebp - 8]中取出来与eax中的值相加后结果赋到寄存器eax中,那么arr[x + y]表示的地址即为[ebp - 0x34 + eax * 4],所以将[ebp - 0x34 + eax * 4]内存中的值取出来赋到一个寄存器ecx中,最后将ecx中的值赋给局部变量r所在内存地址[ebp - 0xC]中即可
-
如果是
r = arr[x*2+y];,这个要注意的是乘法编译器是如何翻译成汇编指令的?先将x,y的值从内存中以此取出存到edx和eax寄存器中,然后可以使用lea 寄存器,[立即数]的方式,直接将表达式edx * 2 + eax放到[]中当做一个地址立即数,那么lea是直接将这个计算出来的立即数存入ecx中,而不会去找这个立即数做表示的内存地址编号中的存的值。所以ecx中存的就是x * 2 + y的结果,再根据[ebp - 0x34 + ecx * 4]找到这个下标所在的内存空间,最后将当中的值存到edx中,再存到r表示的内存地址[ebp - 0xC]中
-
-
扩展:如果定义的数组为char类型,那么就是[ebp - … + 寄存器 * 1];如果定义的数组为short类型,那么就是[ebp - … + 寄存器 * 2];由数据宽度来决定
-
-
-
正向代码练习:桶排序
桶排序和冒泡排序一样都属于对数组中的元素排序的方法,但是在数组中的数相差不大,而且最大值也不大是很大时,桶排序的效率比冒泡排序高
桶排序算法思路:
- 先找数组中的最大元素假如是7,那么就创建一个长度为7 + 1的新数组,下标依次为0,1,2,3,4,5,6,7,每一个下标元素的值为0。
- 现在从要排序的数组中依次读取元素的值,如果为2,那么就将新数组下标为2的位置的元素值 + 1,如果为3,则将新数组下标为3的位置的元素值 + 1,如果此时又读到一个2,那么再将新数组下标为2的位置的元素值 + 1,直到遍历完要排序的数组。
- 然后顺序从下标0到下标7遍历新的数组,如果此时下标对应的元素值为1,那么就打印一个下标值;如果下标对应元素值为3,那么就打印3个下标值,最后达到将要排序的数组顺序输出的结果。(也可以不打印,按照此方法将下标值依次顺序覆盖原来要排序的数组中的元素)
#include "stdafx.h" #include <stdlib.h> void Func(){ int arr[10] = {1,5,3,11,6,3,7,2,10,3}; //先找到arr数组中的最大值 int max = arr[0]; int index = 0; //计数组下标到第几个了 for(int i = 1;i < sizeof(arr)/sizeof(arr[0]);i++){ if(arr[i] > max){ max = arr[i]; } } //动态申请一个新数组,赋初始值为0 int* p = NULL; p = (int*)malloc((max + 1) * sizeof(int)); for(int j = 0;j < max + 1;j++){ p[j] = 0; } //遍历原数组,为新数组赋值 for(int k = 0;k < sizeof(arr)/sizeof(arr[0]);k++){ p[arr[k]]++; } //遍历新数组,为原数组重新按大小排序赋值(可以直接在这里输出) for(int m = 0;m < max + 1;m++){ while(p[m]){ p[m]--; arr[index++] = m; } } //遍历排序好的数组 for(int a = 0;a < sizeof(arr)/sizeof(arr[0]);a++){ printf("%d ",arr[a]); } } void main(int argc,char* argv[]){ Func(); getchar(); }















 2095
2095

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









