







一、C程序的执行步骤
-
C --> 替换 --> 编译 --> 链接 --> 装入内存 --> 执行
-
C就是写好的源代码;替换就是C中可能用到了一些符号来表示某个功能或者代码,替换就是某工具将这些符号替换成代码;编译就是将C编译成硬编码(汇编);最后由于你的函数中可能还引用了别人的函数或者代码,就要将所有编译的目标模块链接起来装入模块,形成完整的逻辑地址;最后装入内存;等待CPU的分配执行

今天要涉及的知识就跟替换有关系,即在编译前做什么
二、宏定义
1.无参数宏定义
-
形式:(一般定义在代码开头)
#define 标识符 字符序列写代码时用标识符。在替换时,替换工具会直接用字符序列替换标识符
-
举例:
#define TRUE 1 #define FALSE 0 int Function(){ return TRUE; //替换时TRUE会被替换成1 }#define DEBUG 1 void Function(){ //.... if(DEBUG) printf("测试信息"); }我们平时写代码时,如果代码数量很庞大,那么肯定少不了在中间要输出测试一下结果是否正确,但是如果我写了成千个测试printf,那么最后发布程序时,不可能一个一个修改,那么此时只要在每一条测试printf语句前加if,然后使用宏定义把DEBUG的值赋值为1供测试执行,发布时再将DEBUG值改为0即可
-
与typedefine不同,define可以定义任何东西,typedefine只能定义类型名;它和常量也不同,常量是在常量区开辟了内存,最后直接将内存地址引用过来;但是宏定义则是直接替换
-
注意事项:
- 只作字符序列的替换工作,不作任何语法的检查
- 如果宏定义不当,错误要到预处理(替换)之后的编译阶段才能发现
2.带参数宏定义
-
格式:
#define 标识符(参数表) 字符序列有点像定义函数一样,但是只是将标识符(参数表)用字符序列替换
-
举例:
#define MAX(A,B) ((A) > (B)?(A):(B)) void Func(){ p = 1; q = 2; int x = MAX(p,q); } -
好处:宏定义相比使用函数来完成MAX的功能,虽然用法一样,但是宏定义不用额外给MAX开辟一块内存,而是在替换时即编译器,直接用宏定义时后面的字符序列来替换MAX部分,而且参数也可以很好的传递;不像函数,需要单独开辟一块内存,来存储函数信息
-
注意事项:
-
宏名标识符与左圆括号之间不允许有空白符,应紧接在一起
-
宏与函数的区别:函数分配额外的堆栈空间,而宏只是替换
-
为了避免出错,宏定义中给形参加上括号
-
末尾不需要分号
-
define可以替代多行的代码,记得后面加
\(一行写不下,就加\接着下一行写)#define MALLOC(n,type)\ ((type*)malloc((n)*sizeof(type)))
-
三、头文件
1.头文件的使用
-
头文件一般就是
.h结尾的文件 -
一般自己写的头文件就用
" "引用,如果是系统提供的头文件就用< >引用。 -
何时使用:我们平时写C语言代码,如果我们在调用一个函数时,必须将函数的定义写在调用函数之前,否则会报错。那么我们如何避免这个问题呢?就可以使用包含头文件的方式
-
新增头文件:
-
打开Classview,先新建一个类:右键 – new class – 取一个名字
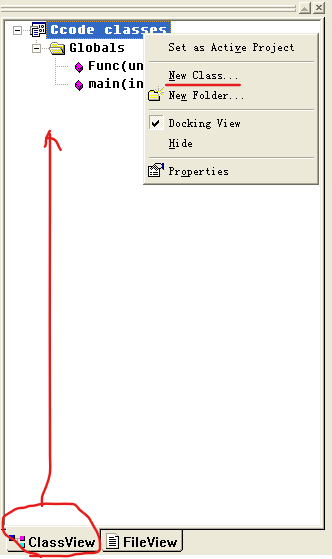

-
接着就可以点FileView,就可以看到刚创建好的.c文件和.h文件

-
此时就可以在XYZ.c文件中定义函数:
void Function(){ printf("Hello World!"); } -
在XYZ.h文件中对函数进行声明:
void Functions(); -
接着想在哪个.c文件或者.h文件中使用这个函数,包含XYZ的头文件就可以使用了
#include "stdafx.h" #include "XYZ.h" //引入了XYZ头文件 int main(int argc,char* argv[]){ Functions(); return 0; }
-
2.重复包含问题
-
现在在z.h头文件中声明了一个结构体,x.h头文件中包含了z.h头文件,而且y.h头文件中也包含了z.h头文件;现在如果有一个文件同时包含了x.h和y.h头文件,就会出现重复包含问题

-
解决方案(在z.h中加上下面两句):
#if !defined(ZZZ) //宏定义 #define ZZZ struct Student{ int level; }; #endif比如现在我在x.h中包含了以后,在y.h文件中包含时就可以加上一个判断宏定义
这句话的意思可以这样去理解,如果ZZZ已经存在了,就不再声明,ZZZ相当于一个编号,唯一的,越复杂越好,(但是一般不用我们来写)。而且没有这么简单,重复包含问题还要其他解决方案,后面遇到会说明
-
我们看看编译器是怎么帮我们解决重复包含问题的:(下面是stdafx.h头文件中的内容)

第一、二行就是使用我们说的:解决方案定义了一个编号,如果定义了就不定义了
#if _MSC_VER > 1000 #program once:表示如果编译器的版本>1000,那么#program once就有意义,而#program once的作用和最开始的!define作用是一样的,可以没有#if _MSC_VER > 1000 #program once,但是不能没有一二两行,因为#program的对编译器的兼容性不好,可能会失败
四、动态分配内存
1.何时使用
- 我们前面学过静态申请内存,比如
int x;、char arr[100];。但是现在如果我要存的数我不确定个数,就不能使用静态申请内存分配固定大小的内存,而是要使用动态申请内存
2.malloc函数
后面的学习会遇到各种各样的函数,如果看不懂,先去百度,百度解决不了,就下载MSDN官方文档,接着选中函数名,F12,就会进入MSDN中,显式这个函数的详细信息和用法
-
malloc函数的作用:C 库函数,分配所需的内存空间,并返回一个指向它的指针,如果内存空间不够,则返回NULL
-
声明:
#include "stdlib .h" void* malloc(size_t size)- size_t是一个宏定义类型,就表示一个无符号整数类型,是sizeof关键字的结果。字节为单位
void*就表示任何类型的指针,因为使用malloc动态申请内存,最后要返回一个指向整块内存的指针,但是不知道具体是一个什么类型的指针,那么返回值类型使用void*,就表示是任何类型的指针,因此宽度就不确定了,所以void*类型指针无法做++、–等运算。所以void*相当于一个临时的类型,占4字节位置,遵循语法规则,到底是什么类型的指针用,就要在使用的时候强转成对应的类型指针即可
3.使用malloc动态申请内存
-
格式:
//在堆中申请内存,分配128个int int* ptr = (int *)malloc(sizeof(int)*128); //假设这块内存要给一个int型数组使用,将void*强转int* //无论申请的空间大小,一定要进行校验,判断是否申请成功 if(ptr == NULL){ return 0; } //初始化分配的内存空间,将分配的这片内存中全设为0(可以不用加,这里是害怕这块内存中有别人留下的数据) memset(ptr,0,sizeof(int)*128); //使用内存 *(ptr) = 1; //使用指针来操作指向的内存中的数据 //使用完毕,释放申请的堆空间 free(ptr); //将指针设置为NULL。因为这次我使用了ptr指针,我用完之后ptr应该还是指向了最后的内存中的地址,如果有坏蛋尝试使用了ptr指针,即用完后又使用了ptr指针,那很可能把原先指向的内存中的其他数据给读出来了,不安全。如果设置了NULL,后面不小心使用ptr,会报错 ptr = NULL; -
内存泄露问题:
- 我们平时如果在函数外定义一个变量,分配的内存在全局区;在函数内定义一个变量,分配的内存在堆栈;使用完这个变量,也不用我们手动的去释放分配的内存空间,因为堆栈平衡等原因,使用完后这些内存中的数据就变成了垃圾,下一次再使用赋初始值覆盖这块内存中的数据即可。
- 但是现在如果我们使用malloc函数动态申请内存,分配的内存空间在堆中,堆有一个特点,如果此时一个数据占用了堆中的某块内存,那么操作系统就会记住这块内存已经分配出去了,其他数据就不能占用了,要么等待释放、要么此exe程序退出后,其他的数据才能再使用这块内存。
- 但是像服务器上运行的程序,会长时间运行,使用malloc函数申请内存,如果使用完没有释放,就会造成这块内存一直被占用,当数据庞大时,会将堆全部占住,最后内存占用率会很高,程序就会奔溃,这就是内存泄露问题(堆)。所以一定要释放内存!
-
malloc能申请多大的内存呢?
- 学过操作系统知道,如果一个32位计算机,任何一个.exe程序运行时都会分配4GB的虚拟内存,2GB是系统区,2GB是用户区,系统区我们不能轻易使用(后面学中级课程的时候,就会学操作任意内存地址)
-
注意事项:
- 使用
sizeof(类型) * n来定义申请内存的大小 - malloc返回类型为void*类型 需要强制转换
- 无论申请的内存有多小 一定要判断是否申请成功
- 使用完一定要释放申请的空间
- 最后将指针的值设置为NULL
- 使用















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









