







 本文详细介绍了双向带头循环链表的结构、关键函数实现,包括打印、初始化、销毁、节点操作以及查找、插入和删除。重点展示了其复杂结构带来的优势及代码实现的简洁性。
本文详细介绍了双向带头循环链表的结构、关键函数实现,包括打印、初始化、销毁、节点操作以及查找、插入和删除。重点展示了其复杂结构带来的优势及代码实现的简洁性。
目录
前言
前面我们讲过,链表分为带头和不带头,双向和单向,循环和非循环链表。
那么经过排列组合之后,就会有8中链表结构。
其中最常用的是单向不带头非循环链表和双向带头循环链表。
前者在之前已经实现过了,今天的内容主要是双向带头循环链表的实现。
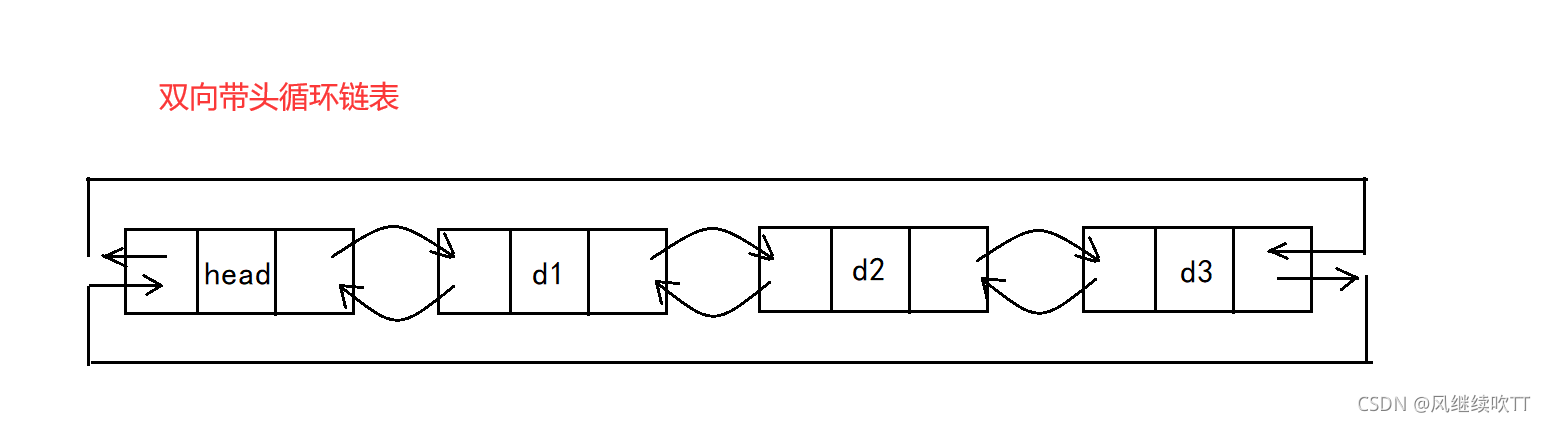
双向带头循环链表
结构
1. 无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。
2. 带头双向循环链表:结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势,实现反而简单了,后面我们代码实现了就知道了。
实现
函数声明
注意:
- 因为是双向链表所以在结构体中不仅会保存下一个结点的地址,而且会保存前一个结点的地址。
- 使用哨兵位的头结点就不会改变头结点,所以在传参时就不需要传二级指针。
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
typedef int DataType;
typedef struct ListNode
{
DataType data;
struct ListNode* next;
struct ListNode* prev;
}ListNode;
//打印链表
void PrintList(ListNode* phead);
//初始化
ListNode* Init(ListNode* phead);
//销毁链表
void ListDestroy(ListNode* pphead);
//申请结点
ListNode* BuyNode(DataType x);
//尾插
void ListPushBack(ListNode* phead, DataType x);
//头插
void ListPushFront(ListNode* phead, DataType x);
//尾删
void ListPopBack(ListNode* phead);
//头删
void ListPopFront(ListNode* phead);
//查找
ListNode* ListFind(ListNode* phead, DataType x);
// 在pos的前面进行插入
void ListInsert(ListNode* pos, DataType x);
// 删除pos位置的节点
void ListErase(ListNode* pos);打印链表
这里与单链表的区别在于,如何判断打印结束。
使用cur指针遍历链表,初始化 cur = phead->next 循环链表中尾结点不会指向NULL,而是会指向头结点。
那么当 cur = phead 时循环结束,打印完成。
void PrintList(ListNode* phead)
{
assert(phead);
ListNode* cur = phead->next;
while (cur!=phead)
{
printf("%d->", cur->data);
cur = cur->next;
}
printf("NULL\n");
}初始化链表
初始化时需先创建头结点,但这样会改变头结点,为了使原结构体指针改变,这里可以传二级指针或者返回头结点。但后面的参数我们都会传一级指针,为了使代码具有一致性,这里我们选择用返回值的方法改变原指针。
ListNode* Init(ListNode* phead)
{
phead = (ListNode*)malloc(sizeof(ListNode));
if (phead == NULL)
{
perror("malloc");
exit(-1);
}
phead->next = phead;//前后指针均指向自己形成循环
phead->prev = phead;
return phead;
}销毁链表
同单链表一样,使用循环依次释放。
但不要忘记释放头结点!
void ListDestroy(ListNode* phead)
{
assert(phead);
ListNode* cur = phead->next;
while (cur!=phead)
{
ListNode* next = cur->next;
free(cur);
cur = next;
}
free(phead);//释放头结点
phead = NULL;
}
申请结点
ListNode* BuyNode(DataType x)
{
ListNode* newnode = (ListNode*)malloc(sizeof(ListNode));
if (newnode == NULL)
{
perror("malloc");
exit(-1);
}
newnode->data = x;
newnode->next = newnode;
newnode->prev = newnode;
return newnode;
}尾插
尾插相对于单链表来说更加简单,因为这里不需找尾结点。
phead->prev就是尾结点,而且只有头结点时也能解决。
时间复杂度为O(1)。
void ListPushBack(ListNode* phead, DataType x)
{
assert(phead);
ListNode* newnode = BuyNode(x);//申请结点
ListNode* tail = phead->prev;//保存尾结点
tail->next = newnode;//尾插
phead->prev = newnode;
newnode->prev = tail;
newnode->next = phead;
}头插
保存第一个有效结点的地址,将新结点插入。
与单链表不同的是,这里不需要移动头结点。
void ListPushFront(ListNode* phead, DataType x)
{
assert(phead);
ListNode* newnode = BuyNode(x);
ListNode* next = phead->next;
phead->next = newnode;
newnode->next = next;
newnode->prev = phead;
next->prev = newnode;
}尾删
找到尾结点的前一个位置的地址,将他的next指向结点,而头结点的prev指向他。
再释放掉原尾结点。
注意:删除结点时需保证链表中存在有效结点。
void ListPopBack(ListNode* phead)
{
assert(phead && phead->next != phead);
ListNode* tail = phead->prev;
ListNode* tailprev = tail->prev;
tailprev->next = phead;
phead->prev = tailprev;
free(tail);
tail = NULL;
}头删
与尾删类似,保存第一个有效节点的下一个结点的地址,
将头结点的next指向他,他的prev指向头结点,
最后释放掉原第一个有效结点。
void ListPopFront(ListNode* phead)
{
assert(phead && phead->next != phead);
ListNode* next = phead->next;
ListNode* nextnext = next->next;
phead->next = nextnext;
nextnext->prev = phead;
free(next);
next = NULL;
}
查找
ListNode* ListFind(ListNode* phead, DataType x)
{
assert(phead);
ListNode* cur = phead->next;
while (cur != phead)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}在pos位置前面插入
与单链表不同,单链表在pos前面插入时,会比较复杂,需要找到pos位置前面的地址。
而双向链表中,在pos前面和后面插入均可。时间复杂度都是O(1)。
而且这个函数相当于可以实现任何位置的插入,当然前面的尾插,头插都可复用此函数。
void ListInsert(ListNode* pos, DataType x)
{
assert(pos);
ListNode* prev = pos->prev;
ListNode* newnode = BuyNode(x);
prev->next = newnode;
newnode->prev = prev;
newnode->next = pos;
pos->prev = newnode;
}
删除pos位置的结点
同样此函数也可以删除任意位置的结点(头结点除外),
前面的头删,尾删也可以复用此函数。
void ListErase(ListNode* pos)
{
assert(pos);
ListNode* prev = pos->prev;
ListNode* next = pos->next;
prev->next = next;
next->prev = prev;
free(pos);
pos = NULL;
}


















 470
470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











