






1. 在python中调用命令行执行代码:subprocess
参考:python subprocess - 刘江的python教程
`subprocess.Popen(args, stdout, stdin, stderr )`类完成创建子进程,并连接它们的输入、输出和错误管道,获取它们的返回状态等操作。
首先第一个参数`args`可以直接时字符串,就是直接用到命令行里的命令,比如"python main.py --input xxx --output xxx"这种。还有一种是参数列表比如["python", "main.py", ...]等。
然后`stdout`, `stdin`, `stderr`用于保存命令行运行之后的输出,`stdout`一般设置为`subprocess.PIPE`,用来捕获print的输出,也可以设置为文件句柄,将输出写到文件里。`stderr`可以设置为`subprocess.PIPE`,也可以设置为`subprocess.STDOUT`与`stdout`合并输出。`stdin`可以用来交互式输入,比如"python"然后输入一个"print("hahaha")"。其他暂时还用不到。
import subprocess
ret = subprocess.Popen("dir", shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
ret.communicate() #等待完成,不然python代码执行完了,你那个还没跑完
print(ret.stdout.read().decode("GBK"))
# >>>2024/02/26 19:00 <DIR> .
# >>>2024/02/26 19:00 <DIR> ..
# >>>2024/03/03 14:24 <DIR> config
# >>>2024/02/26 19:00 1,095 download.sh
# >>>2024/03/03 14:24 <DIR> nought
# >>>2024/02/26 19:00 <DIR> utils
# >>>2024/03/03 16:37 150 __init__.py
# >>> 2 个文件 1,245 字节
s = subprocess.Popen("python", shell=True, stdout=subprocess.PIPE, stderr=subprocess.STDOUT, stdin=subprocess.PIPE)
s.stdin.write(b"print('hello')")
s.stdin.close()
out = s.stdout.read().decode("GBK")
s.stdout.close()
print(out)
# >>>hello2. albumentations库对图像进行数据增强
参考:最快最好用的数据增强库「albumentations」 一文看懂用法-CSDN博客
这个库中的对图像及逆行变换的方法更全面也比torch自带的增强方法更快。
其中主要可以用到的方法包括`albumentation.Compose`以及`albumentation.Oneof`前者表示将不同的transform组合起来,后者表示随机的从Oneof中的transform选一个出来。
每一个transform都会包含一个p的参数,表示该transform发生的概率。Oneof中p也表示Oneof中transform发生的概率,然后再对里面的p进行归一化,比如里面有三个transform,概率分别是0.2,0.1, 0.1那三者选择的概率分别是0.5,0.25,0.25。
3.正则表达式之零宽前向断言和后向断言
参考:正则表达式的先行断言(lookahead)和后行断言(lookbehind) | 菜鸟教程
验证正则表达式的网站:regex101: build, test, and debug regex
包括这几个:
(?=pattern)、(?!pattern)、(?<=pattern)、(?<!pattern)
这几个我觉的不用死记硬背,了解一下大体,用的时候去验证正则表达式的网站验证一下就行了。
先解释一下为啥叫零宽,因为这个匹配不匹配任何的字符,只匹配某个符合条件的位置,具体看下面的例子就明白了。
(一)首先`()`和`?`是断言的开始,然后如果跟的是`=`的话,就表示如果pattern里面的表达式匹配上了,那么就返回匹配上的内容最前面的位置。如下图:
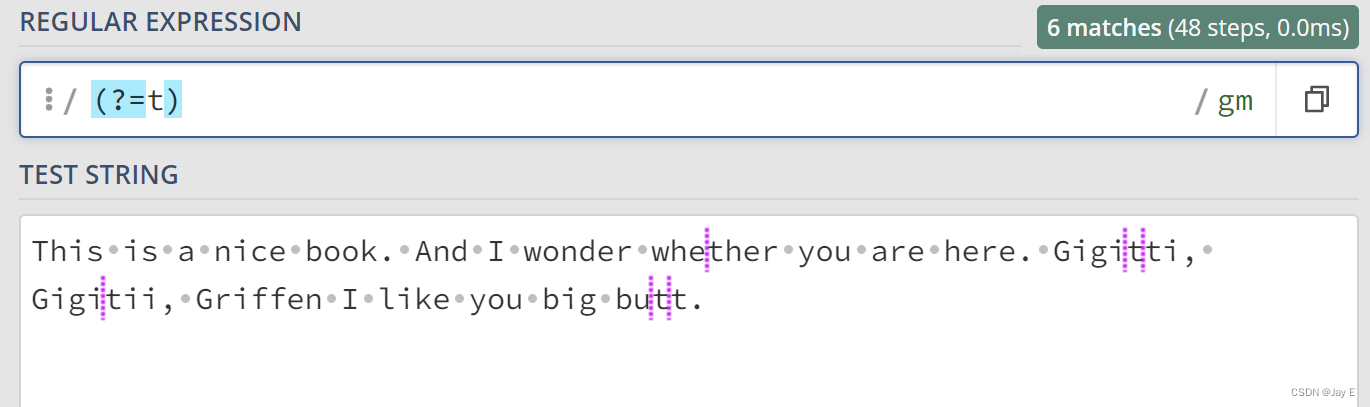
可以看到,如果t被匹配上了那么前面的位置就被返回了。
如果前面有其他东西,那么往前匹配上了就返回匹配的内容,如上图。
(二)如果不是`=`是`!`,那么就表示是上面的反,凡是不符合t位置的都返回,如下图所示:

(三) 如果给`=`前面加个`<`,那么就表示不返回匹配上了t前面的位置了,返回匹配上了t的后面的位置,如下图所示:

可以很清楚的看到,它的和`(?=t)`的差别,一个前面的位置,一个后面的位置。
(四)同样的如果把`=`变成`!`那就会返回上面结果的反。

4.快速的json管理库orjson
可以不去使用原来的json库,用这个。这个要更快更好用。
orjson只提供`loads()`和`dumps()`方法,用来读取和写入字节流。
使用示例如下:
您通常可以通过write()函数轻松地将字节内容保存到文件中。 以二进制的方式写入:
data = [xxx, xxx, ....]
with open("example.json", "wb") as f:
f.write(orjson.dumps(data))
with open("example.json", "rb") as f:
json_data = orjson.loads(f.read())5. torch.utils.data.dataloader.default_collate
参考:torch.utils.data — PyTorch 2.2 documentation
自动将batch中的数据组合成tensor类型,比如default_collate([(1,2), (3, 3)])默认给变成了[tensor(1, 3), tensor(2, 3)]
from torch.utils.data.dataloader import default_collate
import torch
a = torch.randn((2, 2))
b = torch.randn((2, 2))
a_l = 1
b_1 = 0
c = [(a, a_l), (b, b_1)]
print(default_collate(c))
# >>>[tensor([[[-0.4551, 0.4584],
# >>> [ 1.0218, -1.6992]],
# >>> [[-0.8612, 0.8289],
# >>> [ 2.0996, 1.8008]]]), tensor([1, 0])]6.异常链
参考:如何在Python中处理异常链(Exception Chaining)?-阿里云开发者社区
异常链是指可以在一个异常中去追踪产生这个异常的异常。看个例子:
def func1():
try:
1/0
except ZeroDivisionError as e:
raise ValueError("除数不能为0") from e
try:
func1()
except ValueError as e:
print(e)
print(e.__cause__)
# >>> 除数不能为0
# >>> division by zero在上面这个例子里,try执行func1之后会抛出一个异常ValueError,这个ValueError是来自与ZeroDivisionError的,也就是 ZeroDivisionError是ValueError的原因。
下面如果再捕获到ValueError的话就可以通过异常链,追溯到ZeroDivisionError。
我觉得这个东西的用法的话可能就是可以自定义异常的输出吧?
7. pathlib中的方法
- `with_name()`用于修改path路径的最后一个文件的name
from pathlib import Path
a = Path("./path/to/nougat.txt")
print(a)
a = a.with_name("nougat-0.1.0.txt")
print(a)
# >>>path\to\nougat.txt
# >>>path\to\nougat-0.1.0.txt8. 查看GPU的显存总量
使用`torch.cuda.get_device_properties`查询指定gpu的属性,可以算出所有显存数,最后单位时GB。
import torch
# 回收没有用到的显存
torch.cuda.empty_cache()
# 计算一共有多少显存
total_memory = torch.cuda.get_device_properties(0).total_memory
print(total_memory/1024/1024/1000)
# >>> 11.1785 (GB)9. linux中删掉仍然占用的显存
参考:Linux显存占用无进程清理方法_sudo fuser -v /dev/nvidia* | awk '{for(i=1;i<=nf;i-CSDN博客
当自己结束代码训练之后,发现还有显存占用这个时候可以首先在终端输入:
fuser -v /dev/nvidia*得到如下输出:
USER PID ACCESS COMMAND
/dev/nvidia0: jihuawei 519163 F...m python
/dev/nvidia1: jihuawei 519163 F...m python
/dev/nvidia2: jihuawei 519163 F...m python
/dev/nvidia3: jihuawei 519163 F...m python
/dev/nvidiactl: jihuawei 519163 F...m python
/dev/nvidia-uvm: jihuawei 519163 F...m python然后把对应的PID进程kill掉就ok了。
kill -9 519163 这个操作之后,在服务器端的GPU占用就没有了。
10. permutation()随机产生/打乱一个序列/array
参考:numpy.random.RandomState.permutation — NumPy v1.26 Manual
numpy中的一个类RandomState的方法permutation返回一个随机打乱的序列。而sklearn中的check_random_state又返回一个RandomState的实例。具体用法见下面的程序:
from sklearn.utils import check_random_state
import numpy as np
random_state = check_random_state(0)
print(random_state.permutation(10))
# >>> [2 8 4 9 1 6 7 3 0 5]
print(random_state.permutation([1, 2, 4, 5]))
# >>> [2 5 4 1]
print(random_state.permutation(np.arange(9).reshape(3, 3)))
# >>> [[3 4 5]
# >>> [6 7 8]
# >>> [0 1 2]]这个方法可以用来自己对自己的数据集进行shuffle。
11.sklean中fit,fit_transform,transform的区别
以一个简单的例子为例,sklearn.preprocessing.StandardScaler用来对样本进行标准化的类。
它的fit方法就是把给定样本的mean,variance,num_features存到实例中。
它的transform方法就是当你fit完了之后,实例中有了一些参数,这个时候你用这些参数去对输入到transform中的输入进行标准化操作,就是减去fit之后存起来的mean,除以fit之后存起来的variance。
它的fit_transform方法就是上面两步合起来了,既fit又transform。
from sklearn.preprocessing import StandardScaler
data = [[0, 0], [0, 0], [1, 1], [1, 1]]
scaler = StandardScaler()
# fit用来计算data样本的一些mean, var等
scaler.fit(data)
# scaler中已经有mean,var等参数了,fit之前是没有的,打印会报错
print(scaler.mean_)
# >>> [0.5 0.5]
print(scaler.var_)
# >>> [0.25 0.25]
# 将输入的data标准化
print(scaler.transform(data))
# >>> [[-1. -1.]
# >>> [-1. -1.]
# >>> [ 1. 1.]
# >>> [ 1. 1.]]
# 一步到位
print(scaler.fit_transform(data))
# >>> [[-1. -1.]
# >>> [-1. -1.]
# >>> [ 1. 1.]
# >>> [ 1. 1.]]














 356
356











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









