









支持库安装
pip install request
pip install beautifulsoup4
pip install Pillow
Requests :唯一的一个非转基因的 Python HTTP 库,人类可以安全享用。
Beautiful Soup :是一个可以从HTML或XML文件中提取数据的Python库。它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式。
Pillow 是一个对 PIL 友好的分支,而 PIL 是一个 Python 图像处理库。
网页分析
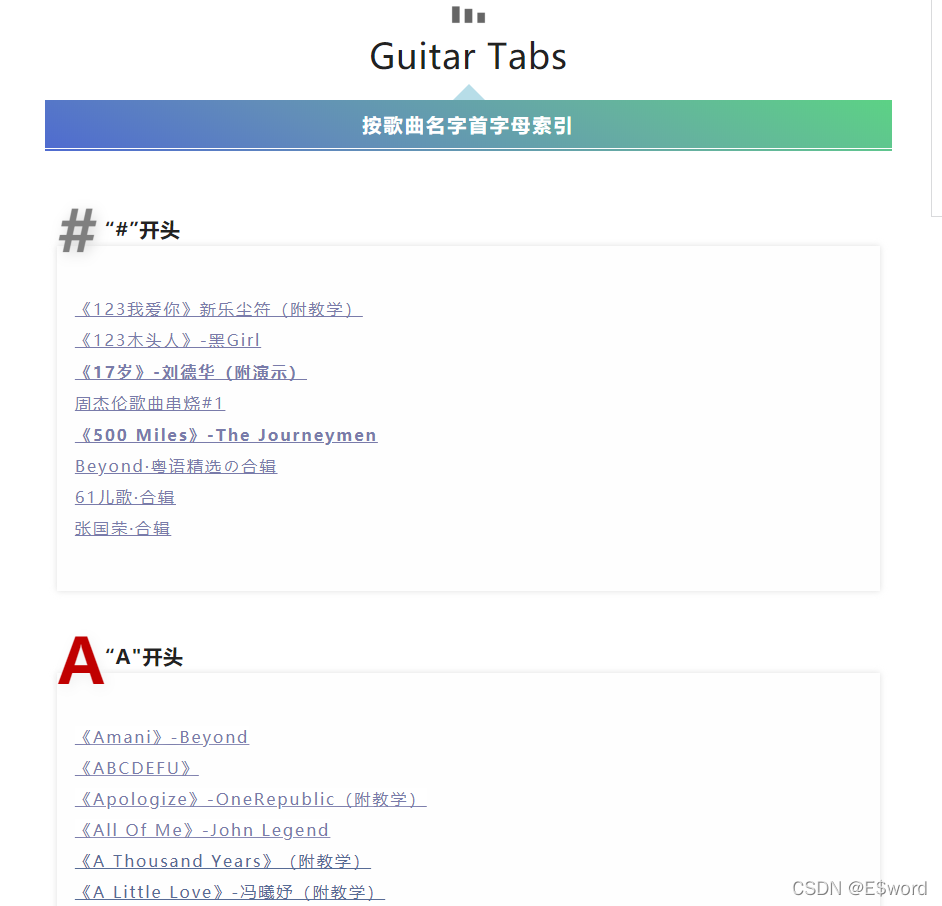
网页地址:
https://mp.weixin.qq.com/s/RQKeWQuOgtCnml-prMXC5w
爬取步骤:
- 爬取文章列表
- 文章页面发请求
- 爬取图片列表
- 保存图片
代码部分分析
文章列表爬取
find_all方法参数:
find_all( name , attrs , recursive , string , **kwargs )
| 参数名 | 描述 |
|---|---|
| name | 标签名,如“a”筛选<a>标签 |
| attrs | 参数字典 |
| recursive | 是否递归?默认真,遍历所有子节点 |
| limit | 返回一定数目的节点 |
| String | string 参数接受 字符串 , 正则表达式 , 列表, True |
| **kwargs | 过滤器 |
**返回值:**节点集合ResultSet
详细信息:
https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/#id27
def get_article_list(web_url):
ans = {}
html = requests.get(web_url).text
soup = BeautifulSoup(html, 'html.parser')
result_set = soup.find_all('section', attrs={
'style': 'padding-right: 0.6em;padding-bottom: 1em;padding-left: 0.6em;box-sizing: border-box;'})
for result in result_set:
category = result.find('span').text #不同类别
sub_result_set = result.find_all('a')
article_list=[]
for sub_result in sub_result_set:
article_url = sub_result['href']
song_name = sub_result.text
song_name = song_name.split('》')[0].replace('《','')
article_list.append({'name':song_name,'url':article_url})
if len(article_list)!=0: ans[category] = article_list
return ans
图片列表爬取
find_all(使用了匿名函数布尔表达式)
不是很容易判断图片位置(微信网页结构太乱)
def get_img_url(web_url):
html = requests.get(web_url).text
soup = BeautifulSoup(html, 'html.parser')
imgs = soup.find_all(lambda x:x.has_attr('data-src') and x.name=='img' and x['data-w']!='' and int(x['data-w'])>1000)
imgs_url_list = [imgs[i]['data-src'] for i in range(len(imgs))]
return imgs_url_list
图片保存
根据图片的url判断图片的尺寸
再决定是否保存
def write_img(file_path,img):
with open(file_path, 'wb') as fd:
fd.write(img)
def write_img_from_list(img_url_list,song_name):
num=0
for idx,img_url in enumerate(img_url_list,1):
img = requests.get(img_url).content
im = Image.open(BytesIO(img))
if im.width < im.height:
num += 1
file_path = os.path.join(key, song_name + '_' + str(num) + '.jpg', )
write_img(file_path,img)
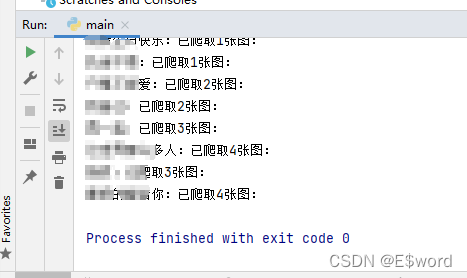
print(song_name+':已爬取' + str(num) + '张图:')
未来工作
- 模拟添加cookie和header(暂时不需要 )
- 加快速度(并行多任务处理)
下载
开源地址:
https://github.com/ESwordCn/crawler_wechat_subscriptions
打包下载:
已按照不同首字母排序
上千张图片
下载地址:
https://download.csdn.net/download/Ejzq1/85065181
想免费下载?
下方点赞+关注+评论




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











