






简单用于原型展示的Rag应用并不复杂,但真要落地生产就会有很多现实的挑战,《AI工程化》在前面的文章里也介绍过很多领域内的一些解决思路和实践方案。这篇文章我们将介绍来自Florian June有关RAG落地时面临的三个常见挑战以及解决思路。
- 不规范的查询和短查询
在生产环境中,用户Query非常多样,也不一定标准;许多Query语义不完整、表述不清晰或表达多种意图。另外,用户的Query越短,就越难处理。比如,像 “推荐酒店”、"告诉我足球新闻和今天的天气 "或 "苹果的好处 "这样的查询,RAG 系统会很难处理。
通常有三种方法可以处理:
1)意图分析:确定一个或多个用户意图,缩小召回范围。
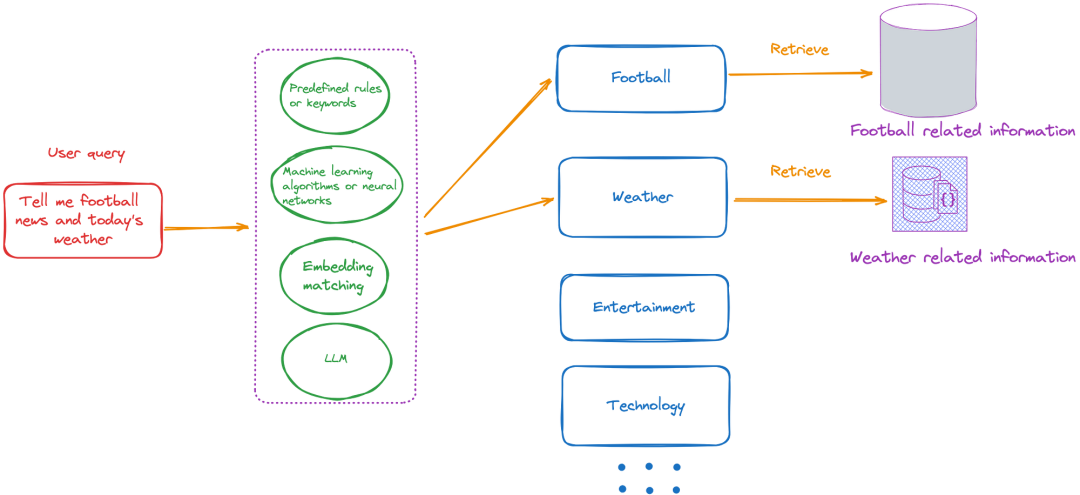
如图所示,意图分析包括将用户的查询归类为一个或多个预定义的意图,从而缩小搜索范围。
意图分析主要有以下四种方法:
a.基于预定义的规则或关键字,通过正则表达式进行匹配;
b.使用经典小模型分类,例如 Naive Bayes 分类器或 BERT。首先,我们需要训练一个分类器,BERT 的示例代码片段如下所示。然后,我们就可以用它对查询进行分类。
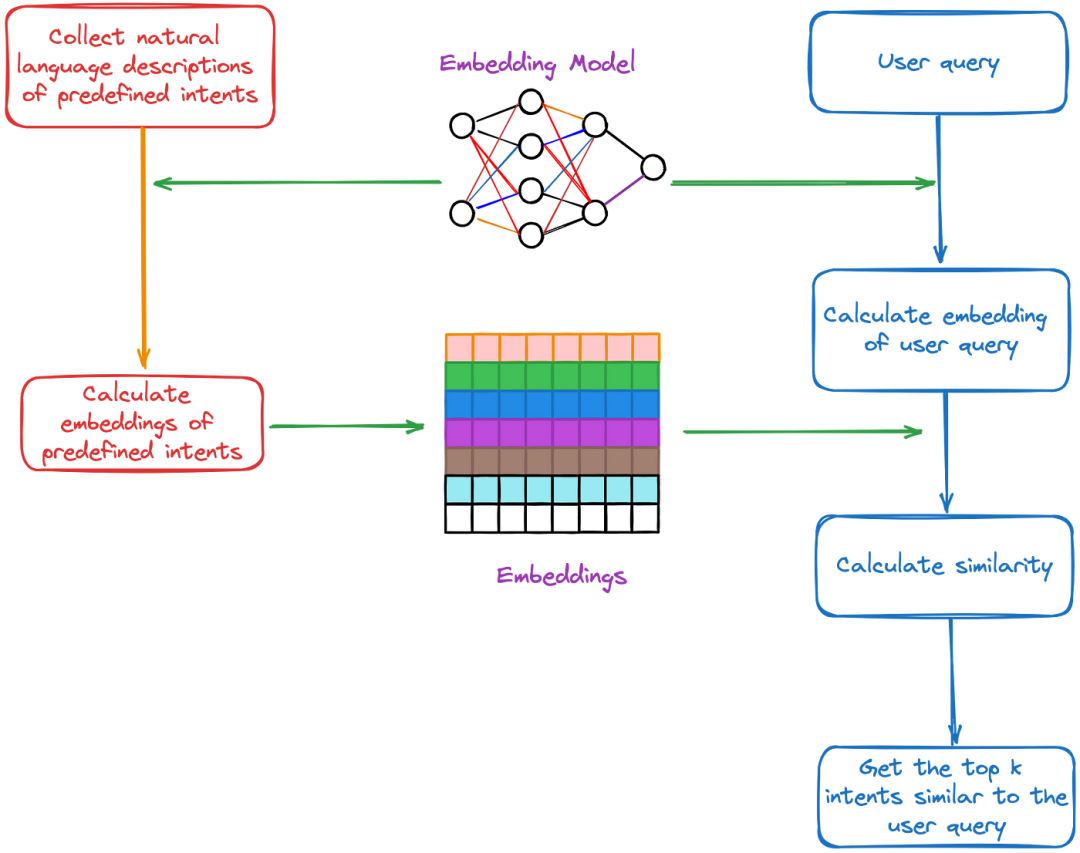
c.Query相似性检索。为预定义意图生成embedding,然后使用相同的嵌入模型为用户查询生成embedding。 通过向量相似性计算出最接近用户查询的前 k 个意图,如图所示。
d. LLM分类。构建一个提示,并利用 LLM 做出决策。此外,还可以提供用户的历史语境,以获得更准确的意图,如下图所示。
You are an advanced AI language model tasked with identifying the intent behind user queries. Given a user input, you need to classify the intent into one of the predefined categories.` ` `` ``## Categories`` ``1. Fruit: The user is asking about fruits, their benefits, types, or any other fruit-related information.``2. Technology: The user is inquiring about technology-related topics, including gadgets, software, hardware, or tech news.``3. Entertainment: The user is seeking information related to entertainment, such as movies, music, games, or celebrities.``4. Sports: The user is asking about sports-related topics, including scores, teams, players, or sporting events.``5. Other: Any other intent not covered by the above categories.`` ``Please provide the user input and the identified intent category.`` `` ``## Example`` ``### Example 1`` ``User Input: "How many calories are in an orange?"`` ``Historical Context: "Give me some low-calorie fruits."`` ``Identified Intent: Fruit`` `` ``### Example 2`` ``User Input: "What were the results of last night's NBA game?"`` ``Historical Context: "I like basketball very much"`` ``Historical Context: "What are the rules of basketball"`` ``Identified Intent: Sports`` `` ``## Now it's Your Turn`` ``Please provide the identified intent for each user input based on the historical context.`` ``User Input: {user_input}`` ``Historical Context: {historical_context}`` ``Identified Intent:
通过确定问题的意图,我们可以缩小需要检索的知识库范围。这样就能减少容易混淆的查询的影响,提高检索的准确性。这里介绍一个开源项目可以参考:https://github.com/answerlink/IntelliQ 。
更多可参看:大模型应用与LUI(自然语言交互)落地的关键模块——语义路由实现总结。
2)关键词提取:确定查询的关键词,并根据关键词进行检索。
关键词提取的目的是从给定文本中识别出最具代表性和意义的单词或短语,如图 所示。

这些关键词反映了文本的主题、内容或重要信息。如图,在 RAG 中使用关键词提取的目的是从用户查询和文档中提取关键词,以方便检索。在图中,可以看到两个虚线框:红色虚线框代表通过关键词检索获得的原始信息块,蓝色虚线框代表通过普通检索获得的原始信息块。在获得这两个虚线框后,我们可以执行重新排序或其他后处理方法。很明显,关键词检索可以辅助普通检索。
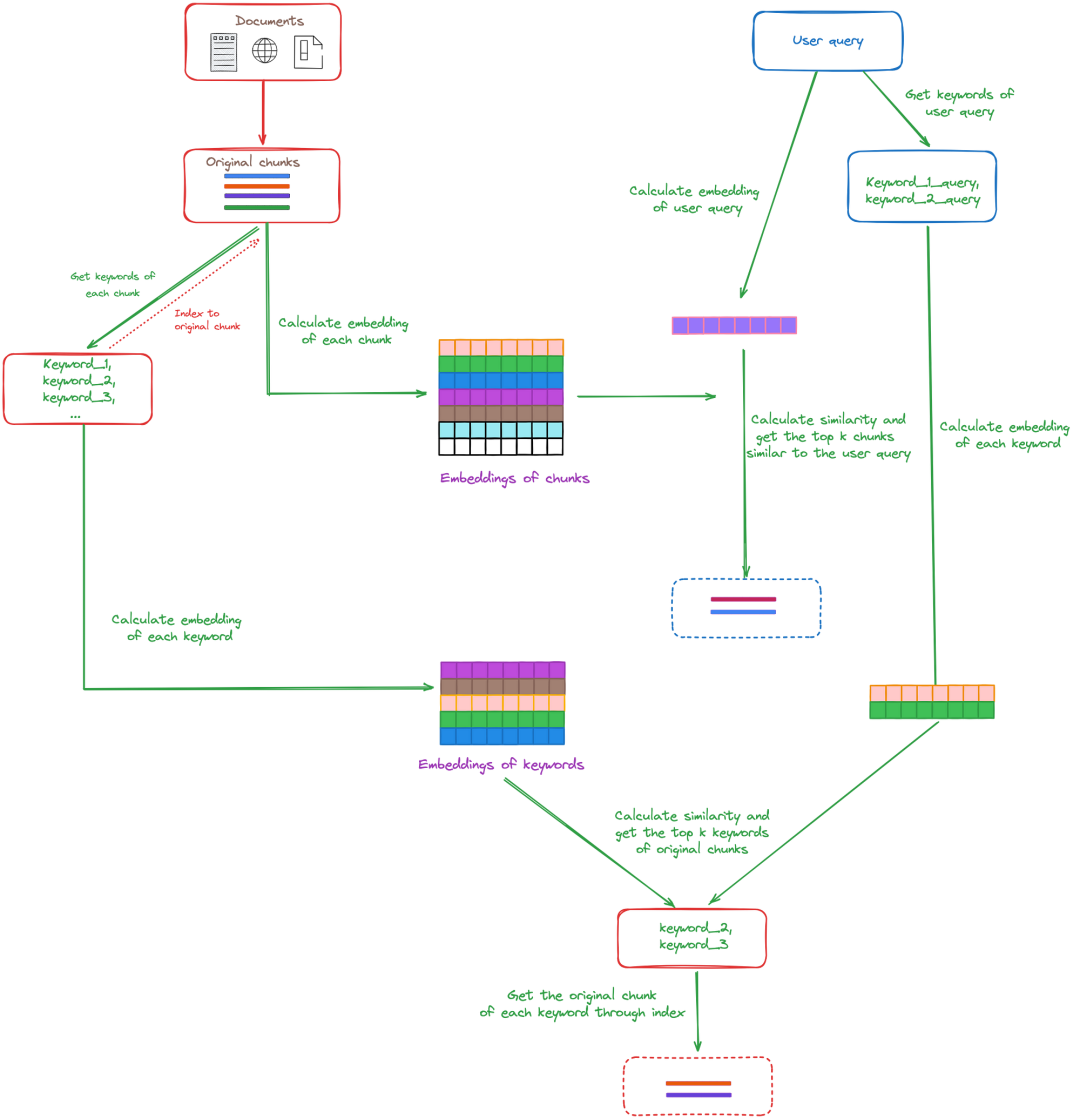
有以下三种方法从原始数据块或用户查询中获取关键词。
a.TF-IDF:首先,进行标记化和停止词去除。然后,计算每个标记的反文档频率(IDF)和每个标记的 TF-IDF 分数。最后,根据计算出的 TF-IDF 分数对词语进行排序。标记词的排名越靠前,说明它在文档中的重要性越高。
b.训练Bert模型或使用现有模型,如 KeyBERT:直接提取关键词,形成最终的关键词列表。
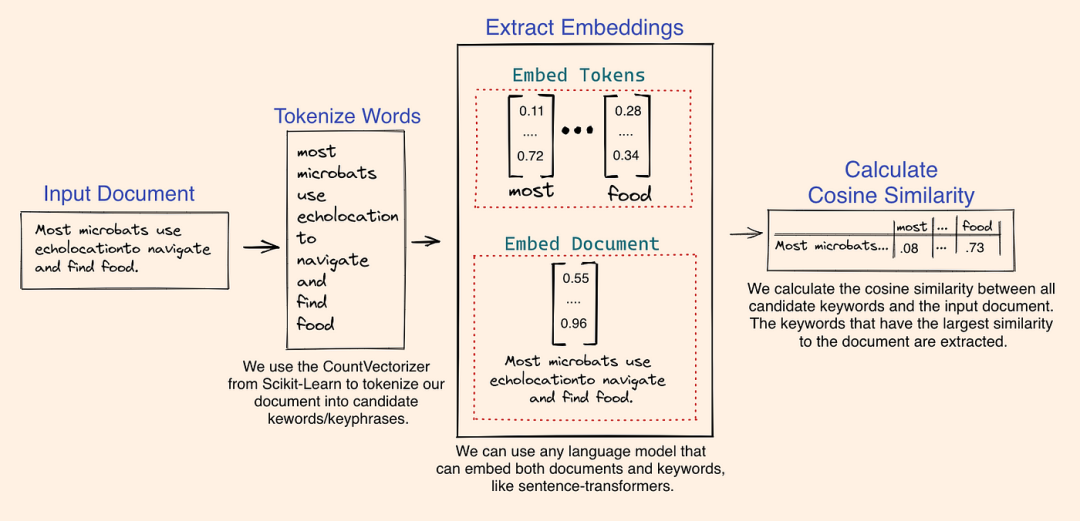
c.使用 LLM 提取关键词。流程如下图。
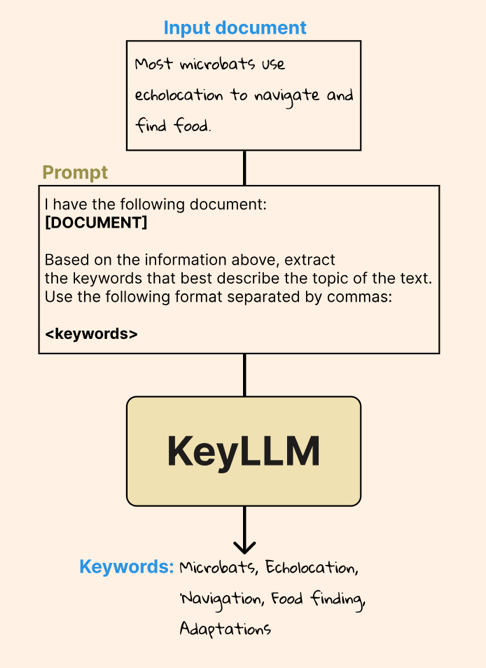
3)澄清和询问:主动向用户提问,以获取更多信息。例如,对于 "苹果的好处 "这一查询,系统可以提问:"您是指水果还是技术公司?
澄清和询问是一种重要的策略,尤其是在处理模糊、不完整或含糊的用户询问时。例如,如果用户直接询问 “推荐酒店”,我们就可以通过澄清和询问收集用户的首选地点、价格范围和其他偏好等信息,从而提供更准确的回复。
a.传统方法。首先,检测用户输入中的模糊或不清晰部分。这可以通过关键词提取来实现,即找出常见的模棱两可或不清楚的词语。 另外,也可以使用意图分析技术来分析输入的含义和上下文。生成澄清或询问回复,这可以通过预定义模板或使用生成模型来实现。处理用户的后续输入,并根据新输入更新理解和任务执行。
b.使用 LLM。可以在提示中加入以下内容:“如果您无法根据背景知识回答用户的询问,那么您可以向用户提出后续问题,但仅限于 4 个问题”。
针对于不规范的查询和短查询处理的三种方法并不是孤立的,可以相互结合。例如,可以通过关键词提取实现意图分析,澄清和查询可以与意图分析相结合。
2.集成结构化数据
通常RAG处理的都是一些非结构化的文档数据,比如 markdown,PDF等 。之前也有一些关于pdf解析的文章,大家可以翻阅,如:gptpdf:一个简单巧妙的复杂pdf解析工具,提升RAG效果
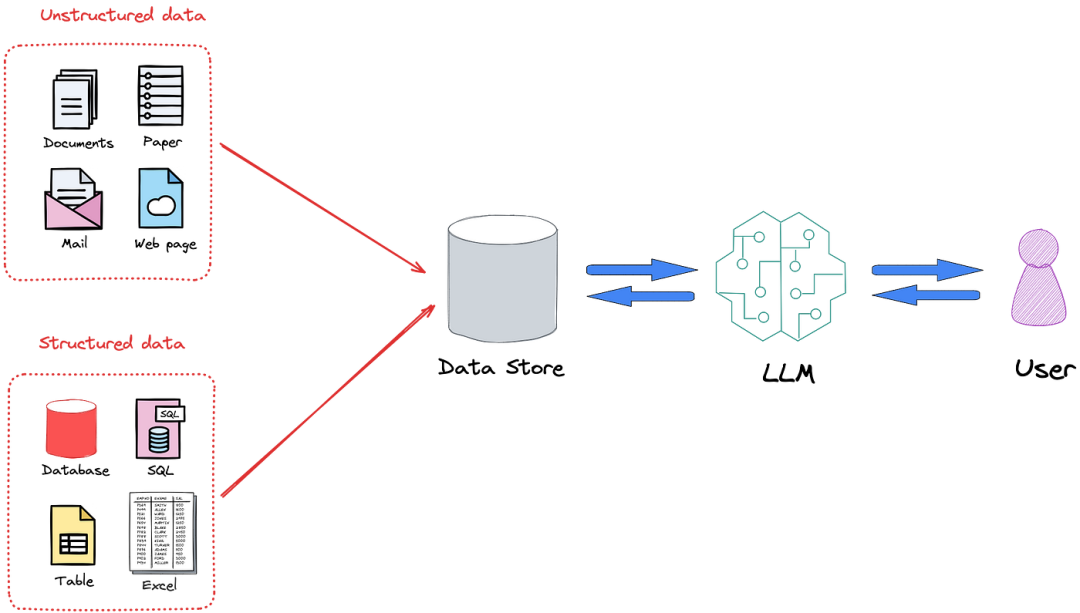
但在实际生产环境中,仅使用非结构化数据完成整个业务流程是很少见的。一般来说,有需求将公司现有关系数据库甚至 Excel 文件中的信息整合到 RAG 流程中。
将结构化数据整合到 RAG 流程中有三种方法:
a.将关系数据库中每个表的每一行视为一个块,然后进行嵌入。但这种方法忽略了表的整体信息,破坏了表内的相关性,往往会导致检索结果不佳。
b.与其将表中每一行的信息向量化不如嵌入元数据,如表描述、视图描述和字段信息。在对用户的查询进行向量化后,使用嵌入来查找相应的表、视图或字段。然后使用一些预先编写的 SQL 函数进行查询。这种方法在事先编写 SQL 函数时工作量较大,但与其他方法相比,执行起来相对稳定。
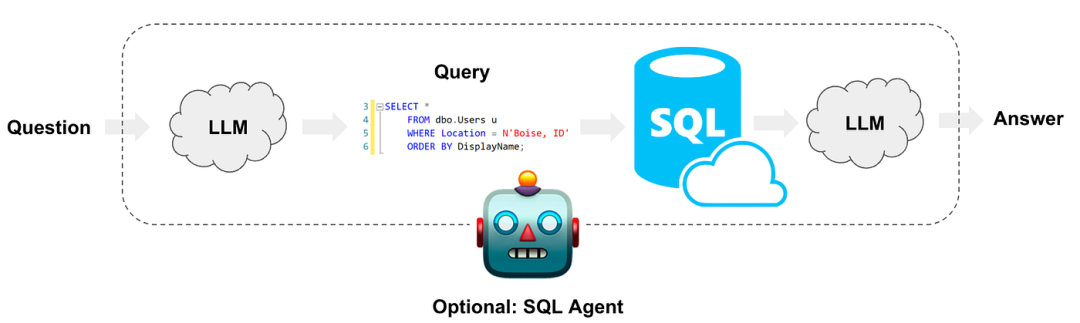
c.Text2SQL。使用 LLM 将用户的问题转换为 SQL 语句。然后,它将数据库查询结果发送给 LLM,生成最终答案。这种方法相对优雅,对于简单的查询效果很好。但是,如果用户的查询比较复杂,结果就会不稳定。
3.私有化部署
在 RAG 的实际应用中,有些客户对数据的保密性要求很高,因此需要在企业内部进行私有部署。需要注意以下三点:
1)模型参数的选择:如果 LLM 的主要功能是归纳和生成,那么 7B 或 13B 等较小的规模是可以接受的。如果对知识推理、逻辑推理、多步骤推理等有较高要求,则参数越多越好,如 33B 或 70B。
2)如果客户端处于没有外部互联网接入的环境,则有必要提前下载 PyTorch 和 Transformers 等 Python 库的所有依赖项。
3)容器化(如 Docker)可以简化环境配置和管理。为了提高推理速度并减少资源消耗,我们可以对模型进行量化。 此外,为确保高效的请求处理和响应,应选择高效的 LLM 服务框架来部署 RAG 系统。如果某些开源框架无法满足您的需求,请自行编写必要的模块。
小结
前面介绍了生产RAG常见的三个挑战,并给出了相应的解决思路。
随着大模型的持续爆火,各行各业都在开发搭建属于自己企业的私有化大模型,那么势必会需要大量大模型人才,同时也会带来大批量的岗位?“雷军曾说过:站在风口,猪都能飞起来”可以说现在大模型就是当下风口,是一个可以改变自身的机会,就看我们能不能抓住了。
那么,我们该如何学习大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、大模型全套的学习路线
学习大型人工智能模型,如GPT-3、BERT或任何其他先进的神经网络模型,需要系统的方法和持续的努力。既然要系统的学习大模型,那么学习路线是必不可少的,下面的这份路线能帮助你快速梳理知识,形成自己的体系。
L1级别:AI大模型时代的华丽登场

L2级别:AI大模型API应用开发工程

L3级别:大模型应用架构进阶实践

L4级别:大模型微调与私有化部署

一般掌握到第四个级别,市场上大多数岗位都是可以胜任,但要还不是天花板,天花板级别要求更加严格,对于算法和实战是非常苛刻的。建议普通人掌握到L4级别即可。
以上的AI大模型学习路线,不知道为什么发出来就有点糊,高清版可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

以上的AI大模型学习资料,都已上传至CSDN,需要的小伙伴可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。
















 486
486

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









