






 该博客介绍了使用Python编写网络爬虫从中文乐高论坛抓取数据,并利用matplotlib生成统计图的过程。代码分为三个部分:web_spider.py负责爬取并保存数据到data.json,plot.py读取数据并生成统计图,reset_json.py用于格式化data.json。数据以日期为键,列表为值存储,包含每日帖子数量等信息。博客提供了数据结构及代码实现细节。
该博客介绍了使用Python编写网络爬虫从中文乐高论坛抓取数据,并利用matplotlib生成统计图的过程。代码分为三个部分:web_spider.py负责爬取并保存数据到data.json,plot.py读取数据并生成统计图,reset_json.py用于格式化data.json。数据以日期为键,列表为值存储,包含每日帖子数量等信息。博客提供了数据结构及代码实现细节。
最近想写几个程序巩固一下最近的python知识,所以写了这个程序。想法是用网络爬虫从中文乐高论坛上爬取数据并用matplotlib生成统计图。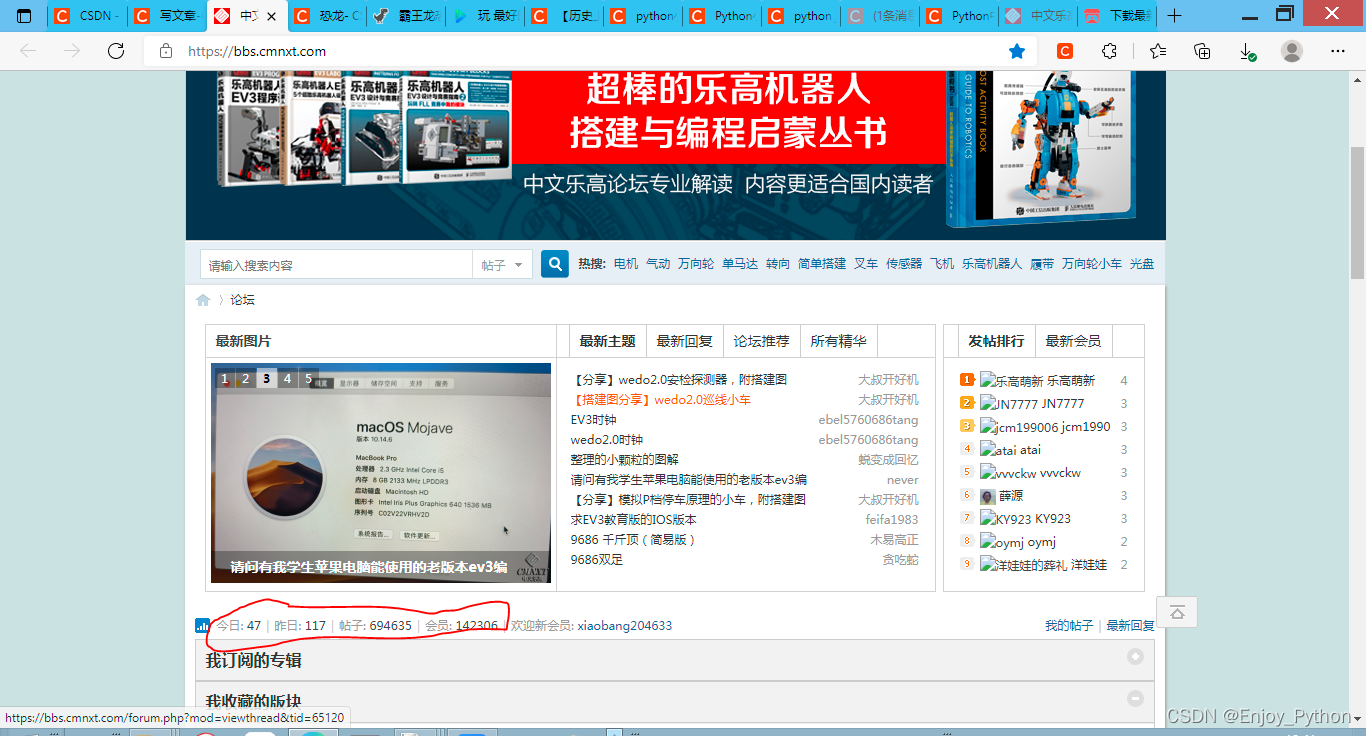
红框中是要获取的数据
结构:
- web_spider.py——负责从网页上爬取数据并保存于data.json
- plot.py——负责读取data.json中的数据并生成统计图,每天运行
- reset_json.py——负责将data.json格式化,一般不用
- data.json——储存着网页数据的.json文件,需要导入json包进行读取和写入
data.json的详细结构:
data.json中有一个字典,字典的每一个键值对都代表了一天的数据。其中键是当天的日期,而值是一个列表,储存着当天的数据。例如{"2022-02-24": ["108", "95", "694463", "142281"], "2022-02-25": ["79", "116", "694550", "142281"], "2022-02-26": ["45", "117", "694633", "142306"]}储存了三天的数据,其中第一天是2022年2月24日,截止至当天有694463篇帖子等等
下面开始讲代码
web_spider.py
第一部分是数据获取
先用datetime.date.today获取实时日期,然后用网络爬虫获取网络数据,爬下来的数据是列表形式,如['47', '117', '694635', '142306']。
第二部分是数据储存
用json.load()打开data.json,加入新的键值对,然后再用json.dump()保存。保存的数据会覆盖之前的数据。
plot.py
第一部分是数据解析
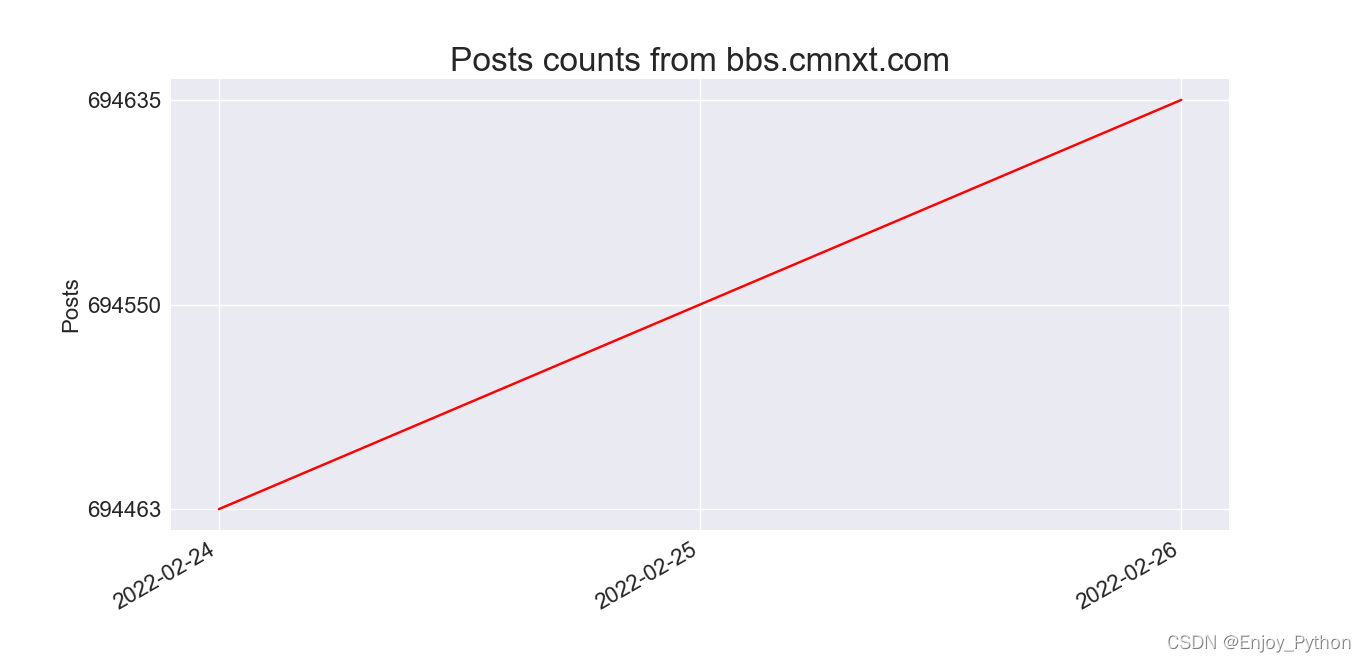
生成统计图需要xy轴上数据的列表
打开data.json,用for循环将所有的值写入列表web_datas,并将每个值的第三项(截止至当天的帖子总数)写入列表post_count。将所有的键(日期)写入列表dates。
然后生成统计图


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









