







包含所有集群及组件安装、持续更新汇总,可以根据左侧目录观看有需要的。
一、CentOS安装
1.1 用Hyper-V安装CentOS7
CentOS镜像:CentOS-7-x86_64-DVD-2009
下载地址:http://mirrors.aliyun.com/centos/7.9.2009/isos/x86_64/
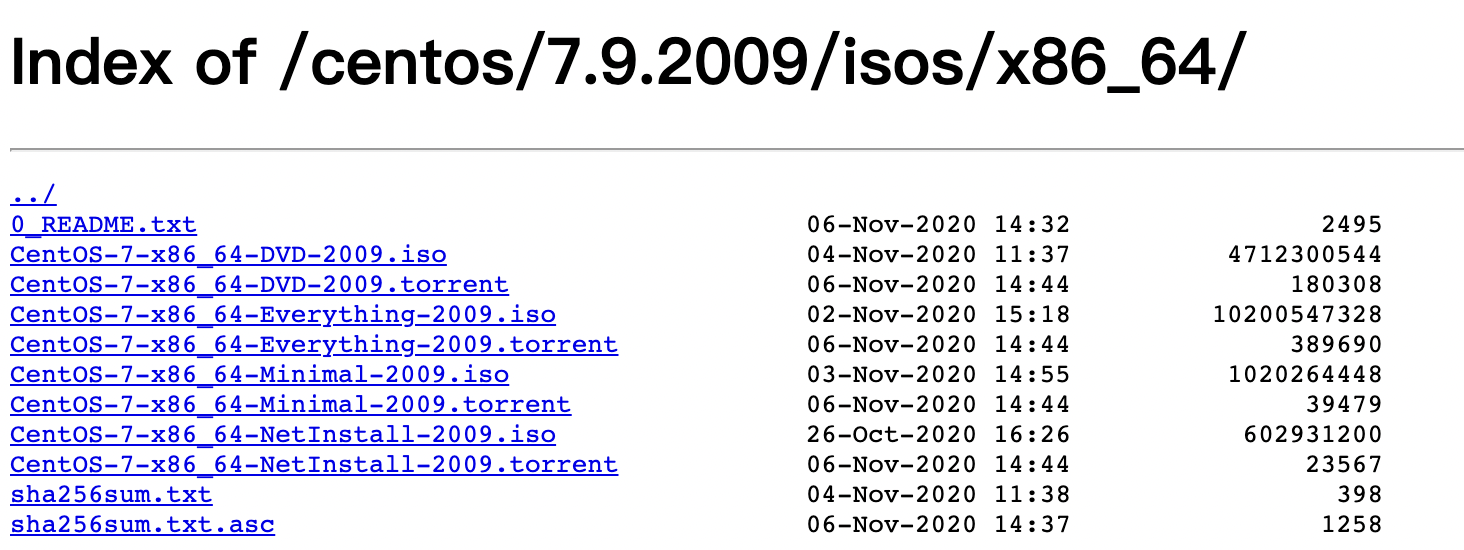
其中DVD版为标准版
1.2 搭建虚拟网卡
为了把虚拟机的ip通宿主服务器网段隔离开来,需要使用NAT网段,在Hyper-V中使用内部网络:(虚拟机和虚拟机之间,虚拟机和宿主机之间通讯,可以通过宿主机访问物理网络)



这样就建立好了内网的虚拟网卡。
二、CentOS7的基本配置
2.1 CentOS7的IP设置
输入如下命令,修改虚拟机hadoop01的ip配置
# vi /etc/sysconfig/network-scripts/ifcfg-eth0
【注意】:ifcfg-eth0为网卡名

输入
# ip addr
检查ip地址是否更改

发现ip地址还是不存在,输入如下命令重启网卡
# systemctl restart network
再次检查ip地址,发现已经更新为我们设置的ip地址了

2.2 更改主机名
用如下命令修改主机名为hadoop01
永久修改(推荐)
# vi/etc/hostname
或者用(临时)
# hostname hadoop01
# 以上二选一都可以
将里面的内容修改为hadoop01

同时修改ip地址映射
# vi /etc/hosts
#添加内容
192.168.10.101 hadoop01
192.168.10.102 hadoop02
192.168.10.103 hadoop03
192.168.10.104 hadoop04
192.168.10.105 hadoop05

完成【五、克隆子机】后再来检验
子机与母机之间可以通过映射名来ping通了,用hadoop02来ping hadoop01
ping -c 3 hadoop01

2.3 开启SSH控制虚拟机
2.3.1 开放CentOS7 22号端口
用如下命令将22号端口的注释关闭
# vi /etc/ssh/sshd_config

2.3.2 在服务器上开启端口转发
2.3.4 通过SSH连接CentOS
通过本机向服务器发送SSH命令
# ssh -p 88 root@192.168.20.124
# 88: 服务器上开放的端口号,例如hadoop1在服务器上开放端口为88
# root:用户名
# 192.168.20.124: 服务器的ip地址
结果出现了如下报错,是因为ssh会把你每个你访问过计算机的公钥(public key)都记录在~/.ssh/known_hosts。当下次访问相同计算机时,OpenSSH会核对公钥。如果公钥不同,OpenSSH会发出警告,如果我们重新安装系统,其公钥信息还在,连接会出现如下图所示
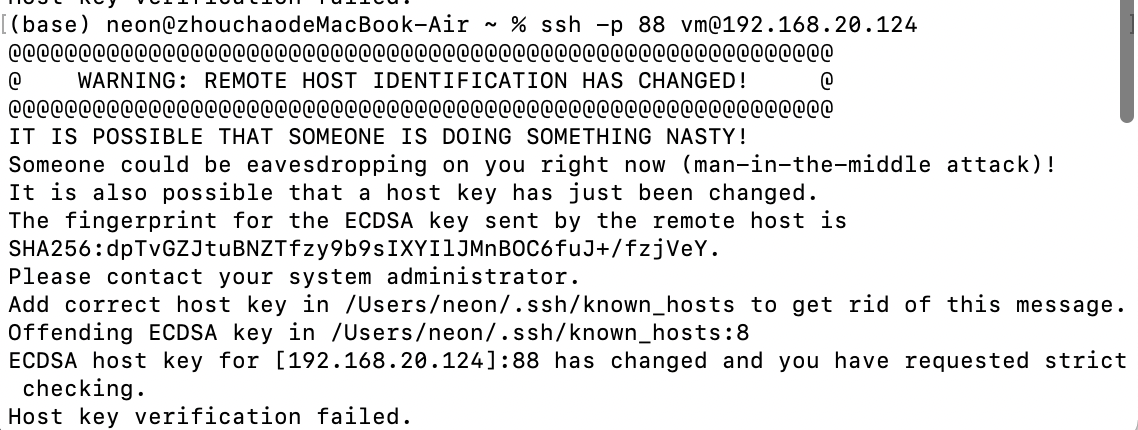
【解决办法】:在本机输入
方法一:
rm -rf ~/.ssh/known_hosts
优点:干净利索
缺点:把其他正确的公钥信息也删除,下次链接要全部重新经过认证
方法二:
ssh-keygen -R 192.168.20.124
优点:快、稳、狠
缺点:没有缺点
重新连接CentOS

连接成功!
2.4 安装JDK
2.4.1 OpenJDK 还是 Oracle JDK?
【OpenJDK】
openjdk是开源的jdk,可能会面临不稳定的问题,openjdk可以用yum指令安装到默认路径。
# yum install java-1.8.0-openjdk
【错误】:
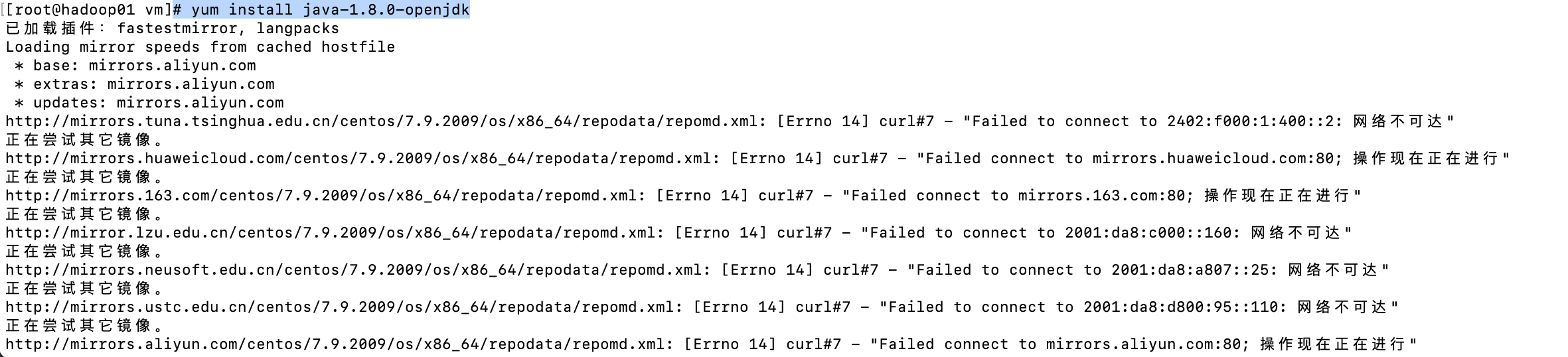
是由于yum访问国外源速度很慢导致。
【OracleJDK】
在opt目录下新建java文件夹,将jdk下载到该文件夹中
但要先安装wget
# yum -y install wget
# mkdir /opt/java
# cd /opt/java
# wget --no-cookies --no-check-certificate --header "Cookie: gpw_e24=http%3A%2F%2Fwww.oracle.com%2F; oraclelicense=accept-securebackup-cookie" "http://download.oracle.com/otn-pub/java/jdk/8u141-b15/336fa29ff2bb4ef291e347e091f7f4a7/jdk-8u141-linux-x64.tar.gz"
下载好的jdk压缩包
解压jdk至当前目录
# tar -zxvf jdk-8u121-linux-x64.tar.gz
解压完成后

2.4.2 修改配置文件
在etc/profile中加入如下配置
# vi /etc/profile
| 配置内容 |
|---|
| JAVA_HOME=/opt/java/jdk1.8.0_141CLASSPATH= : C L A S S P A T H : :CLASSPATH: :CLASSPATH:JAVA_HOME/lib/PATH= P A T H : PATH: PATH:JAVA_HOME/binexport PATH JAVA_HOME CLASSPATH |

保存命令
# source /etc/profile
检查是否安装成功
# java -version

可以看到我们已经成功安装了jdk1.8
【注意】:将配置内容(其实是命令脚本)写到/etc/profile中目的就是让任意用户登录后,都会自动执行该脚本,这样这些登录的用户就可以直接使用jdk了。如果因为某个原因该脚本没有自动执行,自己手动执行以下就可以了(也就是执行命令source /etc/profile)
2.5 虚拟机生成密钥文件
2.5.1生成密钥
# ssh-keygen -t rsa -P ''

秘钥文件保存到了/root/.ssh/目录内,可以使用命令查看,命令为
# ls /root/.ssh/

使用同样的方法为hadoop02和hadoop03生成秘钥(命令完全相同,不用做如何修改)。
2.5.2 创建authorized_keys文件
在所有虚拟机的/root/.ssh/目录下都存入一个内容相同的文件,文件名称叫authorized_keys,文件内容是我们刚才所有虚拟机生成的公钥。为了方便,我下面的步骤是现在hadoop01上生成authorized_keys文件,然后把所有机器刚才生成的公钥加入到这个hserver1的authorized_keys文件里,然后在将这个authorized_keys文件复制到hadoop02和hadoop03上面。
创建authorized_keys的文件
# touch /root/.ssh/authorized_keys
创建成功

(这里还没有创建子机,完成【五、克隆子机】后再过来这里)
将所有虚拟机/root/.ssh/id_rsa.pub中内容全部复制到authorized_keys里面
# cat /root/.ssh/id_rsa.pub
# vi /root/.ssh/authorized_keys
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCu7WnPNNzYR55WMjs1kNuqPMUs2PJ8NLMozn3cVYLf2j32Ng7D5a5SL1ISARoCjxlXy03gyNF4udCOeuCRLPIBgaS0PdFSHQflXE/cBn7rUim3596WKneOiO79k+EMKDWdMC8nHfE48ZRVhFeFfDYvwGdD3gboda3w4AjzQwRnv38exN2JgObbNbp8ky3HJalAuaC0wIIv/CJyKiMirFP2lL5OoFe+NEScca27oHraxRWv2C06V+B4qm9/4gYxLDxR+xTzSd9ZW6+fDi1jzhpWOx56JU77QgLqu/1AUgzG6AwDpGpGz3gYxenzW/ybafgsBqFmTgM/q39Y1XSqSd5h root@hadoop01
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCjQL8/4bDTL+NrPolaLQtW014hyeYU45Q5DCLuwSSrECULYhrwTpnf4ItLCiPhMDPa120oFX72qpcilzr3isF7EmGE6vyO2508iJYVGxsfkXn0QVRftVx81qqpReN8sWN5q77UrUoVaTfqiTap8mk+PmC1OqBYhLyWnXaSTl+rw5LhaWB1PAlVmKPyoJU+cJLwLbhO5LwHL0kvwLTBbq8X2rp/vP6o97b+YOyc2pub5vIWLrLFFHWiclTMKwzsphwkS5Il6BKVpI1JBTAwha5/JKjwe3g9y0MOoK29vJo2XCzVgxNKErAd2nSI1AsMgyW8mr2jwJ0jJc0tYMymPUm9 root@hadoop02
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDSoq4b9I48LDht1emOOjmf296aorADOatB6YEOpna+Dei2FuHOgY9Lx6t1bhW0045Y0vwLjvDFQ4VoOUnYu0lHPTwYfGyro7nWweynz9+ortwugmsjDbix6TZcJ5PWSptumP52tJZgZ4aAngWqnfEjkNll9HbvUTFdplMu//Lg/c9n6ITPorwiL/00ywaJiWQnyNcl/kfqJl7mPEOdoVWB9dz5wRrs0GxLW24fHRBj6X+NH0bR11hzaO3+JnrsL16RyhiOUgYHVSX8FZQp7Jr3IzGmvwpu0gsFJJUwskxfsHTk/ThJjFtkCcMW7F6ahzuqQynPTpMnkavcEp5/+Bex root@hadoop03
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDvHlOr2J6fhDJTQfacdHvugUl7IMEQRIQeMOwW9QzdyNuVYGSJezUq30zBN1Q5OB0NLL1rUk7tBKpmHHpeYqn/y8Hh/ia06rFmLYTM352M/ViDAeGEOFnEQC5XHFsu5ELigwMMS//ivAKgjy4/ZUBSdaGrXSBPwC18WtptrQf79u2VKiPuiOoJpYwqepMOB5TtoS4p5v+cg11Z2Aj4slLh5SvWSfFN76OmevB25AmmRJqfroiuuvGekoO++DQuNp+oqEbUjIX/gQ6Sjlo+nZhkrrA6iJ4sKNJeJDecn71X/tpq1WXZGgSwLL7ngXaBB48ImmH8ZnIcRqTZZiB5bfqV root@hadoop04
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC2VdqfaIQfLqh+jtI0EtcgZd7b7F29qwrakmMRVw+srhwp9thKIBl3OH5CiDq0HiIBtlF8buY432YvGwnz3FKwKOYSnVFLfx2rTGEwLfjgUOiTEk8UgjpwB3LWIk0JGH13ODNo1cHSF4RoZTMLGiYNPVnO7oevjIyjiHpMy4VZV5W3EFHevEKybg3h5/98xBaX5hpODwUsKOeHa8DgDNGz1uFXP/lM16MU9BW51q+dKcz6XIv1JCi3KlsjRUNx/N66w+GJeTPz684OmYkIpsA91vOAfMAFeWXmqjnsqcogM2WSuWpSdE46ya4xCPidk7p0N9sNHiBfRr2pSUZ4tj6l root@hadoop05
用ssh可以无密码在虚拟机之间相互访问啦!
# ssh hadoop01

hadoop02访问hadoop01成功!!!
# exit
记得访问后退出。
三、 集群规划与部署
【注意】
- NN和NNA不要搭在同一个虚拟机上
- RM很耗内存,最好不要和NNA、NNS配置在同一个虚拟机上
- ZKFC必须和NN在同一个机器上
- DM最好和DN在同一个机器上
| Hadoop01(NNA) | Hadoop02(NNS) | Hadoop03(DN1) | Hadoop04(DN2) | Hadoop05(DN3) | |
|---|---|---|---|---|---|
| IPv4 | 192.10.10.101 | 192.10.10.102 | 192.10.10.103 | 192.10.10.104 | 192.10.10.105 |
| 职责 | ZK ZKFC | ZK ZKFC JN | ZK JN | ZK JN | ZK JN |
| HDFS | NameNode | NameNode DataNode | SecondaryNameNode DataNode | DataNode | DataNode |
| YARN | ResourceManager | NodeManager | NodeManager | NodeManager | NodeManager |
| 端口 | 8020 | 8020 | 8485 | 8485 | 8485 |
四、安装Hadoop
4.1 下载Hadoop
在下载安装Hadoop前先创建虚拟机快照!防止版本问题需要重装
在/opt下创建hadoop文件夹,在该文件夹中下载hadoop
# mkdir /opt/hadoop
# cd /opt/hadoop
# wget https://mirrors.cloud.tencent.com/apache/hadoop/core/hadoop-2.10.1/hadoop-2.10.1.tar.gz
解压hadoop
# tar -xvf hadoop-2.10.1.tar.gz

4.2 新建目录
新建如下目录
# mkdir /root/hadoop
# mkdir /root/hadoop/tmp
# mkdir /root/hadoop/var
# mkdir /root/hadoop/dfs
# mkdir /root/hadoop/dfs/name
# mkdir /root/hadoop/dfs/data
执行
进入hadoop目录
# cd /opt/hadoop/hadoop-2.10.1/etc/hadoop
4.3 Core-site.xml
# vi core-site.xml
<configuration>
<!-- namenode的入口 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoopcluster</value>
</property>
<!-- 配置HDFS的工作目录(元数据加载在这里) -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/tmp</value>
</property>
<!-- 配置zookeeper的集群 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181,hadoop04:2181,hadoop05:2181</value>
</property>
</configuration>
4.4 Hdfs-site.xml
# mkdir /opt/hadoop/journaldata
# vi hdfs-site.xml
<configuration>
<!--指定hdfs的nameservice,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>hadoopcluster</value>
</property>
<!-- 配置所有的NameNode的名字,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.hadoopcluster</name>
<value>nn1,nn2</value>8
</property>
<!-- nn1的RPC协议的IP和端口 -->
<property>
<name>dfs.namenode.rpc-address.hadoopcluster.nn1</name>
<value>hadoop01:8020</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.hadoopcluster.nn1</name>
<value>hadoop01:50070</value>
</property>
<!-- nn2的RPC协议的IP和端口 -->
<property>
<name>dfs.namenode.rpc-address.hadoopcluster.nn2</name>
<value>hadoop02:8020</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.hadoopcluster.nn2</name>
<value>hadoop02:50070</value>
</property>
<!-- 配置NameNode的元数据在JournalNode上的存放位置 配置所有JournalNode的IP和端口 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop02:8485;hadoop03:8485;hadoop04:8485;hadoop05:8485/hadoopcluster</value>
</property>
<!-- 配置JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/hadoop/journaldata</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 客户端使用这个类去找到active namenode-->
<property>
<name>dfs.client.failover.proxy.provider.hadoopcluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa.pub</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
4.5 Mared-site.xml
# vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:19888</value>
</property>
</configuration>
4.6 yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop2</value>
</property>
<!-- 启用RM重启的功能-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
<description>启用RM重启的功能,默认为false</description>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
<description>用于状态存储的类,采用ZK存储状态类</description>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181,hadoop04:2181,hadoop05:2181</value>
</property>
<!-- 指定做中间数据调度的时候使用的是哪一种机制 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hadoop01:8088</value>
<description>提供给web页面访问的地址,可以查看任务状况等信息</description>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hadoop02:8088</value>
<description>提供给web页面访问的地址,可以查看任务状况等信息</description>
</property>
<!-- 配置通讯的地址和端口,有多少个RM就配置多少组property -->
<!-- RM1-->
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>hadoop01:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>hadoop01:8031</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>hadoop01:8032</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>hadoop01:8033</value>
</property>
<!-- RM2 -->
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>hadoop02:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>hadoop02:8031</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>hadoop0:8032</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>hadoop02:8033</value>
</property>
</configuration>
4.7 hadoop-env.sh
# vi hadoop-env.sh
修改export JAVA_HOME=${JAVA_HOME} 为 export JAVA_HOME=/opt/java/jdk1.8.0_141
4.8 slaves
修改slaves
# vi slaves
将里面的localhost删除,添加如下内容
hadoop02
hadoop03
hadoop04
hadoop05
五、克隆子机与配置
5.1 克隆子机
关闭正在运行的hadoop01,在hyper-v中导出虚拟机

导出后通过导入新建子机

目录一定选择导出hadoop01的目录
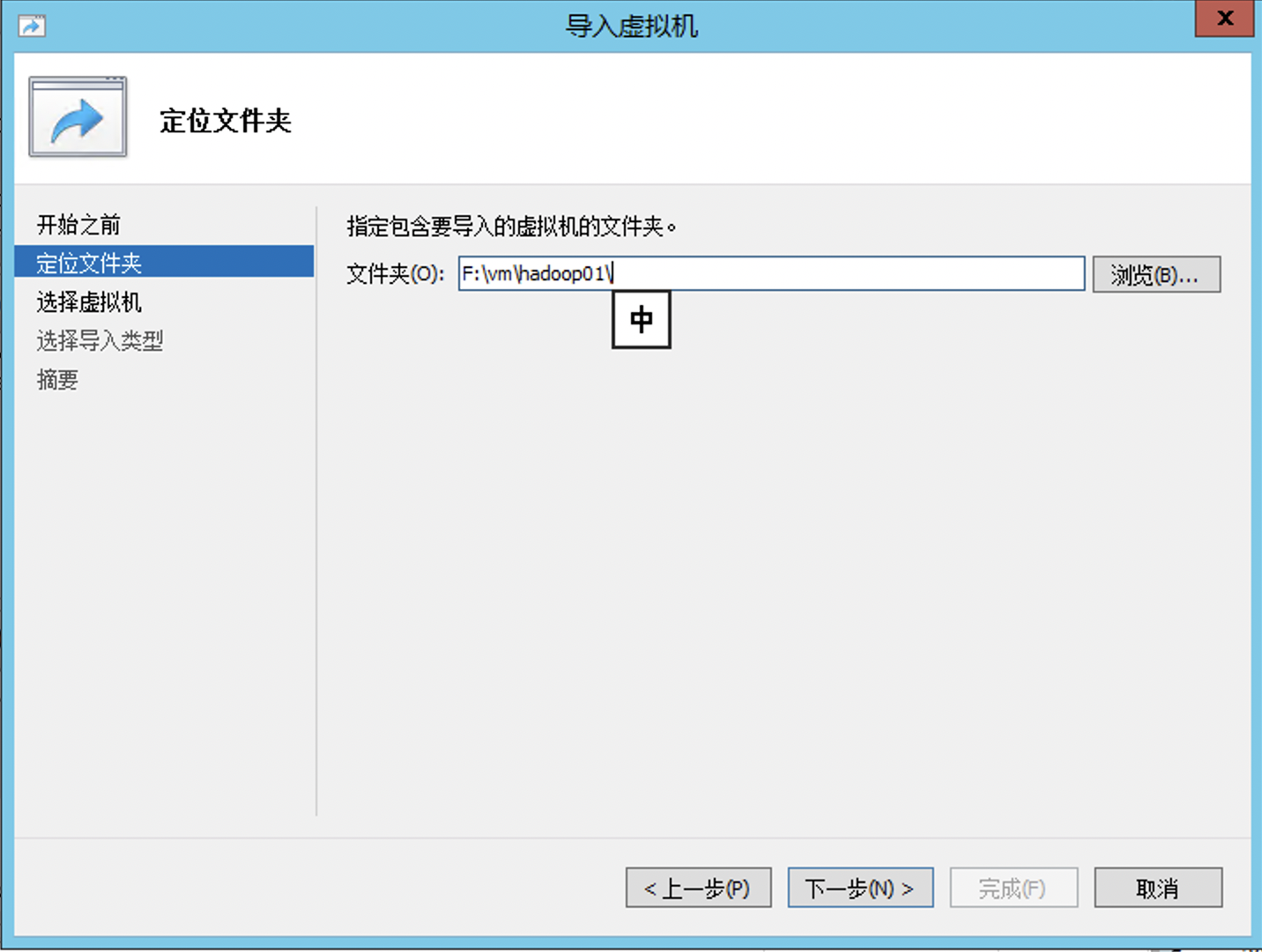
根据hadoop01位置指定文件夹,最后摘要为
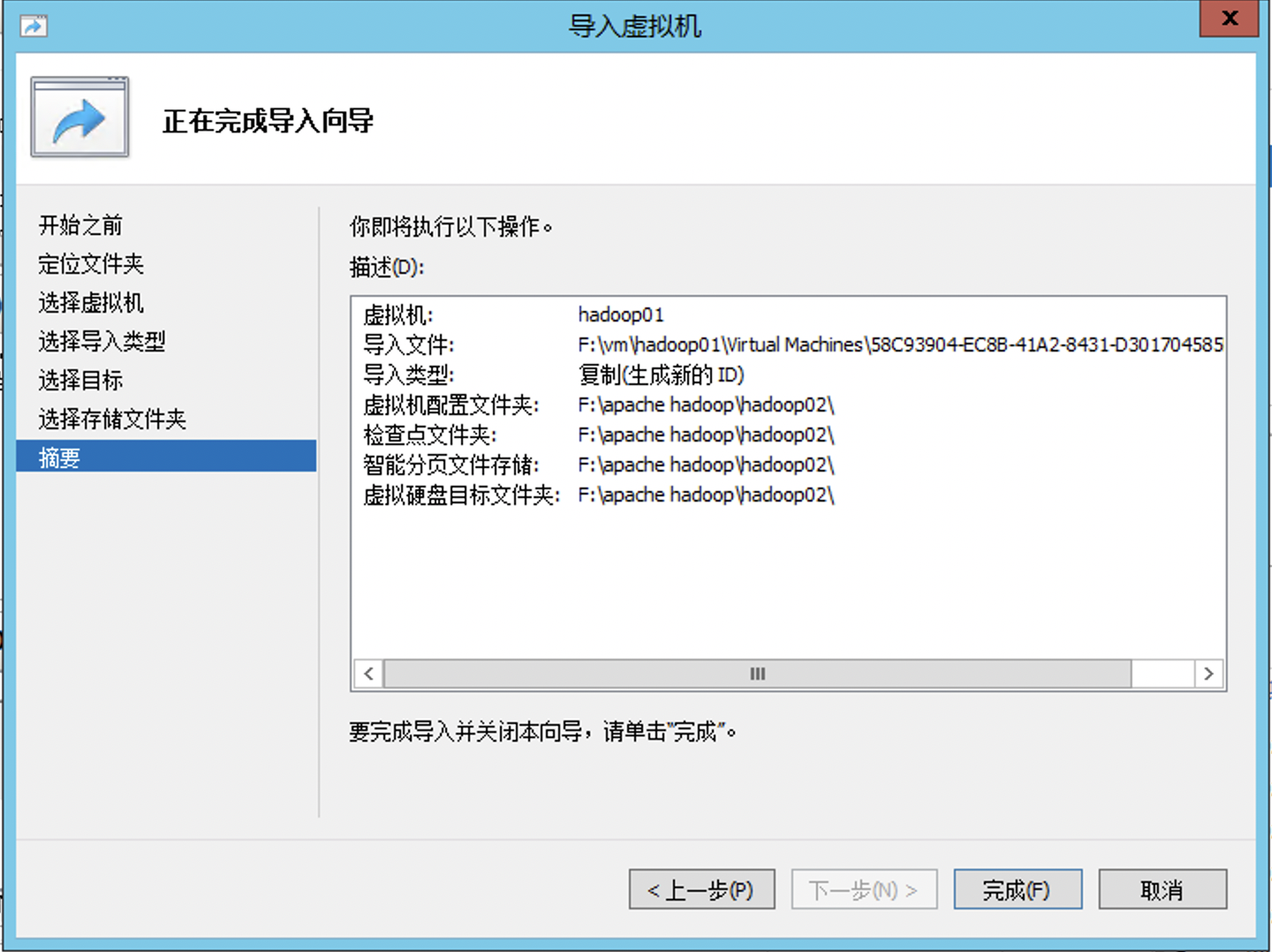
相同的方法,克隆其他虚拟机
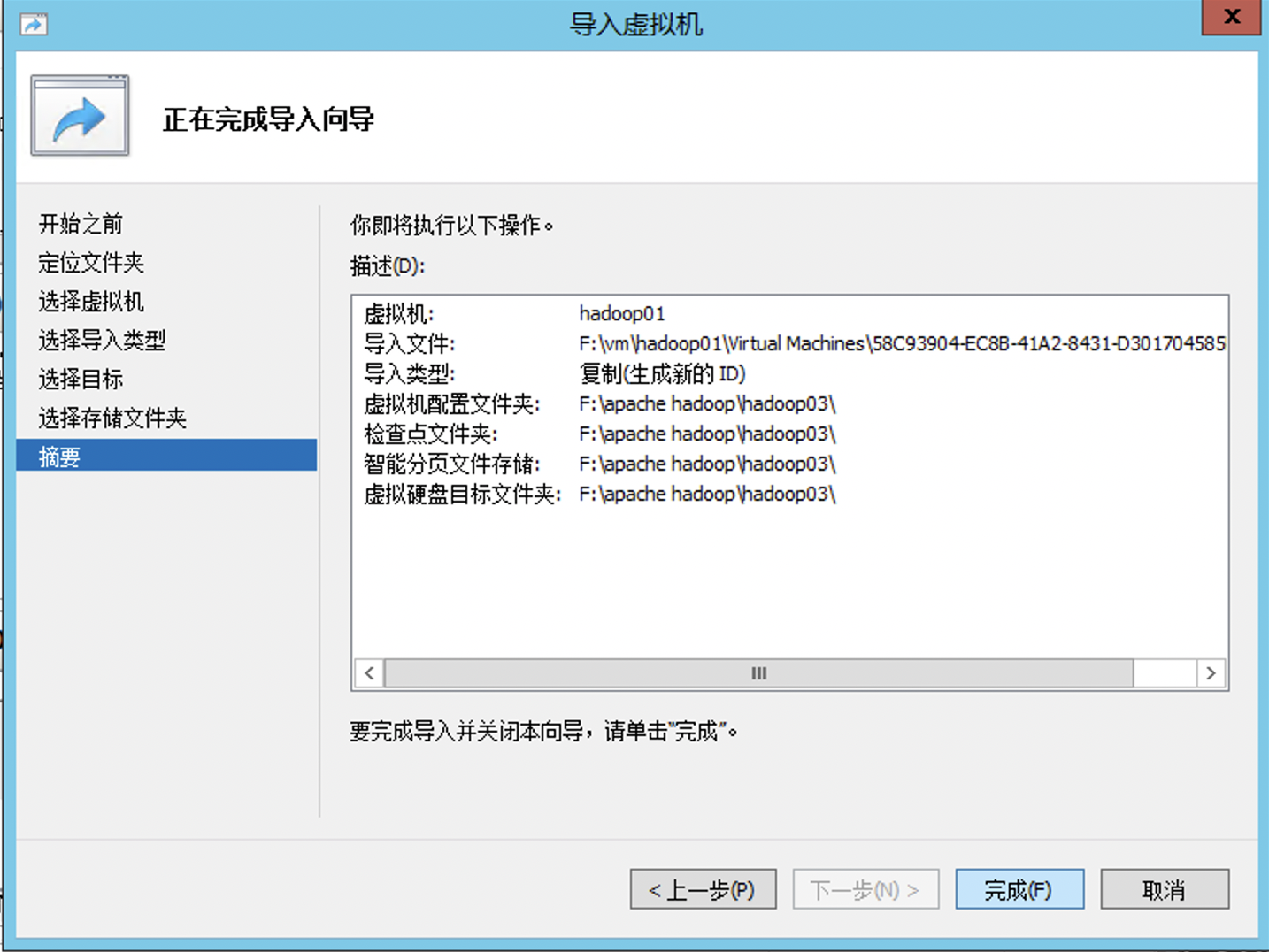
5.2 配置子机
重新命名虚拟机
采用本文档2.1的方法修改虚拟机的ip地址
192.168.10.102 对应 hadoop02
192.168.10.103 对应 hadoop03
采用本文档2.2~2.3的方法开启SSH命令
成功登入hadoop02、hadoop03

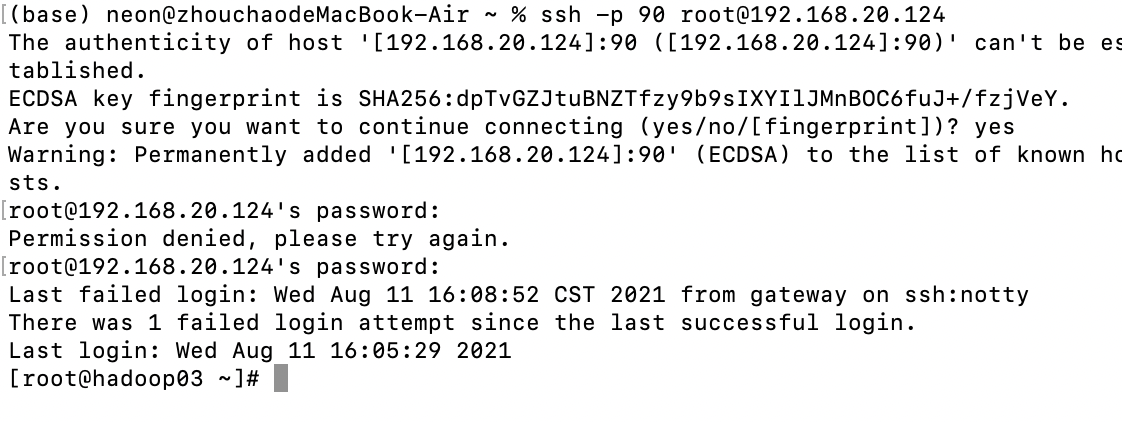
六、配置zookeeper
在opt目录下下载并解压zookeeper
# cd /opt
# wget http://archive.apache.org/dist/zookeeper/zookeeper-3.4.9/zookeeper-3.4.9.tar.gz
# tar -zxvf zookeeper-3.4.9.tar.gz

将解压文件zookeeper-3.4.9改名为zookeeper
# mv zookeeper-3.4.9 zookeeper
在zookeeper新建tmp和log用来存放快照和日志
# mkdir /opt/zookeeper/tmp
# mkdir /opt/zookeeper/log
修改配置文件
# cd /opt/zookeeper/conf
# cp zoo_sample.cfg zoo.cfg
# vi zoo.cfg
修改如下几点
dataDir=/opt/zookeeper/tmp
dataLogDir=/opt/zookeeper/log
*******************************************
server.1=192.168.10.101:2888:3888
server.2=192.168.10.102:2888:3888
server.3=192.168.10.103:2888:3888
server.4=192.168.10.104:2888:3888
server.5=192.168.10.105:2888:3888
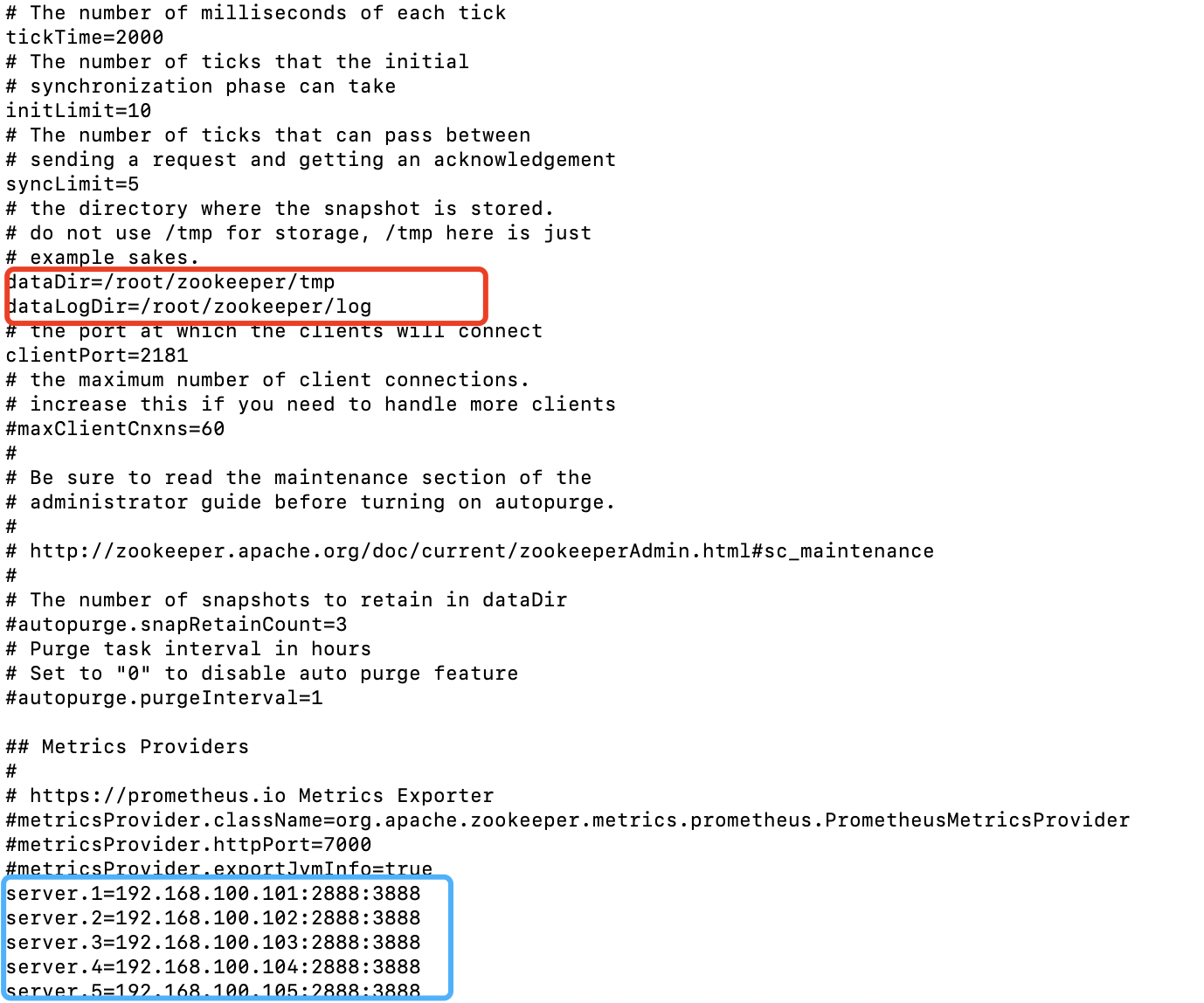
【备注】:
server.A = B:C:D
-
A:其中 A 是一个数字,表示这个是服务器的编号;
-
B:是这个服务器的 ip 地址;
-
C:Zookeeper服务器之间的通信端口;
-
D:Leader选举的端口。
创建myid文件
# cd /opt/zookeeper/tmp # vi myid上面A是多少,本机这里就填多少,例如hadoop01的myid为1
# cat my id配置环境变量
# vi ~/.bashrc新增
export ZOOKEEPER_HOME=/opt/zookeeper export PATH=:$PATH:$ZOOKEEPER_HOME/bin使环境变量生效
# source ~/.bashrc在所有节点上启动zookeeper集群
# cd /opt/zookeeper/bin # ./zkServer.sh start
七、测试Hadoop
7.1 关闭防火墙
# systemctl stop firewalld.service
# systemctl status firewalld.service
# systemctl disable firewalld.service
7.2 启动ZK
# sh /opt/zookeeper/bin/zkServer.sh start
7.3 启动JN
启动journalnode,即在hadoop02,hadoop03,hadoop04,hadoop05上启动:
# sh /opt/hadoop/hadoop-2.10.1/sbin/hadoop-daemon.sh start journalnode
7.4 在namenode上执行初始化
因为hadoop01是namenode,hadoop02和hadoop03都是datanode,所以只需要对hadoop01进行初始化操作,也就是对hdfs进行格式化。
进入到hadoop01这台机器的/opt/hadoop/hadoop-2.10.1/bin目录,也就是执行命令:
# cd /opt/hadoop/hadoop-2.10.1/bin
执行hdfs初始化脚本
# ./hadoop namenode -format
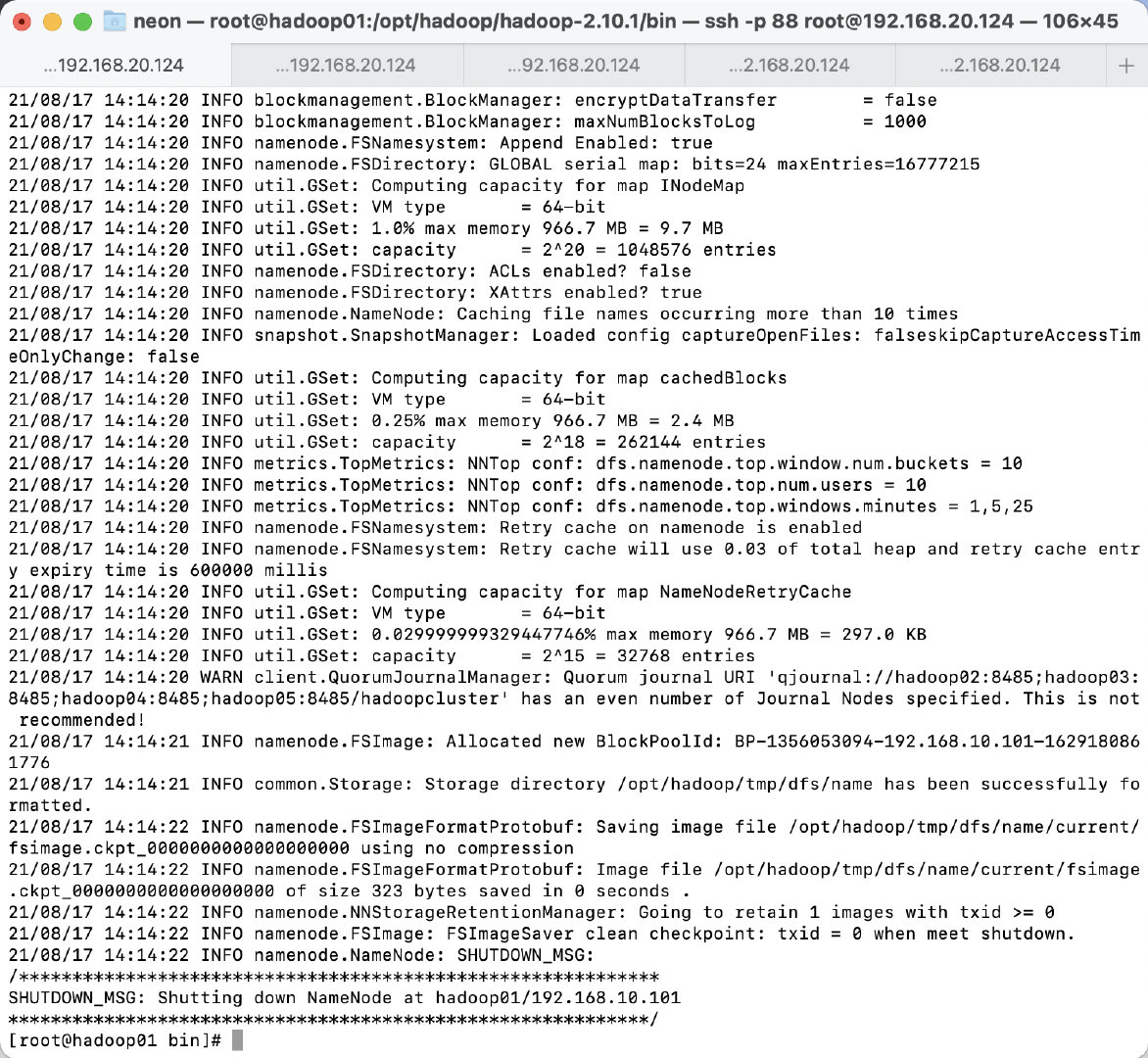
发现初始化成功,congratulations!😁
7.5 启动NNA
在NNA(hadoop01)上执行
# cd /opt/hadoop/hadoop-2.10.1/bin
# ./hadoop-daemon.sh start namenode
7.6 拷贝NNA到NNS
在NNS(hadoop02)上执行
# cd /opt/hadoop/hadoop-2.10.1/bin
# ./hdfs namenode -bootstrapStandby

7.7 初始化ZKFC
在任意一台namenode(hadoop01)上格式化ZKFC
# cd /opt/hadoop/hadoop-2.10.1/bin
# ./hdfs zkfc -formatZK

7.8 停止HDFS所有服务
# cd /opt/hadoop/hadoop-2.10.1/sbin
# ./stop-dfs.sh

7.9 在namenode上执行启动命令
因为hadoop01是namenode,hadoop02和hadoop03都是datanode,所以只需要对hadoop01进行启动命令。
进入到/opt/hadoop/hadoop-2.10.1/sbin目录
# cd /opt/hadoop/hadoop-2.10.1/sbin
# sh start-all.sh

7.10 查看各节点服务
-
hadoop01

-
hadoop02

-
hadoop03

-
hadoop04

-
hadoop05

7.11 集群任务测试
只用在namenode上面执行,即是hadoop01
在HDFS上创建路径
# cd /opt/hadoop/hadoop-2.10.1/bin
# hdfs dfs -mkdir -p /data/input
在/opt新建一个测试文件wordcount.txt
# vi /opt/wordcount.txt
输入
Join us this winter for a virtual series of public conversations entitled, The Black Matter is Life: Poetry for Engagement and Overcoming. In this series, we will explore and discuss the rich tradition and innovation found in African American poetry.
Poetry is a powerful art form, one that offers profound insights into what it means to be human. Through the creative, succinct, and melodious use of language, poets render into words their joys, their challenges, their vulnerabilities, and their discoveries, thus providing shape and meaning to the human connection and shared emotional experience.
In the wake of our nation’s current unrest, this program is designed to build bridges across the racial divide by introducing the audience to the writings of a number of African American poets whose work has shone a light on a rich cultural heritage that has often gone unexplored. This program asks the audience to consider how African American poetry provides tools for healing our nation’s deep racial wounds.
ABOUT THE POETS
STATEMENT OF INTENT
POETRY STUDY GUIDE
POETRY EVENT FLYER (PDF)
Program Description
To begin this exploration of the vast diversity within African American poetic tradition, UNH professors Reginald Wilburn and Dennis Britton will facilitate three online conversations. Each discussion deconstructs four poems grouped by themes. Conversations will center these poems within the context of the African American literary tradition, their cultural heritage, the traditions they encompassed, and the relevance this tradition has to us today. The series will also explore the question, “Why does African American Poetry matter?”
November 18 | 5:00 PM
Signifyin(g) on a Tradition
Featuring guest poet Lynne Thompson
Phillis Wheatley—Imagination
Lawrence Dunbar—When Malindy Sings
Langston Hughes—Harlem & Theme for English B
Sonia Sanchez—Haiku and Tanka for Harriet Tubman
Read Rye Public Library Community Poem by Mimi White, Lisa Houde, Jess Ryan & Andrew Richmond here Helicon
VIEW EVENT HERE
December 9 | 5:00 PM
In Protest
Featuring guest poet Patricia Smith
James Weldon Johnson—The Creation
Audre Lorde—Litany for Survival
Danez Smith—dear white america
Elizabeth Alexander— Ars Poetica #1,002: Rally
Read Keene Public Library Community Poem by Rodger Martin, Skye Stephenson, Linda Warren, and Gail Zachariah here
VIEW EVENT HERE
January 21 | 5:00 PM
Love, Love, Love
Featuring guest poet Jericho Brown
George Moses Horton—The Lover’s Farewell
Gwendolyn Brooks—Lovely Love
Nikki Giovanni—Resignation
Jericho Brown—Like Father
Read the Community Poem by Roy Goodman from Poetry as Spiritual Practice
group at the Unitarian Universalist Church here
执行
# hdfs dfs -put ~/test.txt /data/input
# hdfs dfs -ls /data/input

成功放入了文件。
接下来用wordcoun函数统计单词
# cd /opt/hadoop/hadoop-2.10.1
# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.1.jar wordcount /data/input /data/output/test

7.12 端口查看
在服务器上进入localhost:192.168.10.101:50070 和 localhost:192.168.10.102:50070 进入overview界面
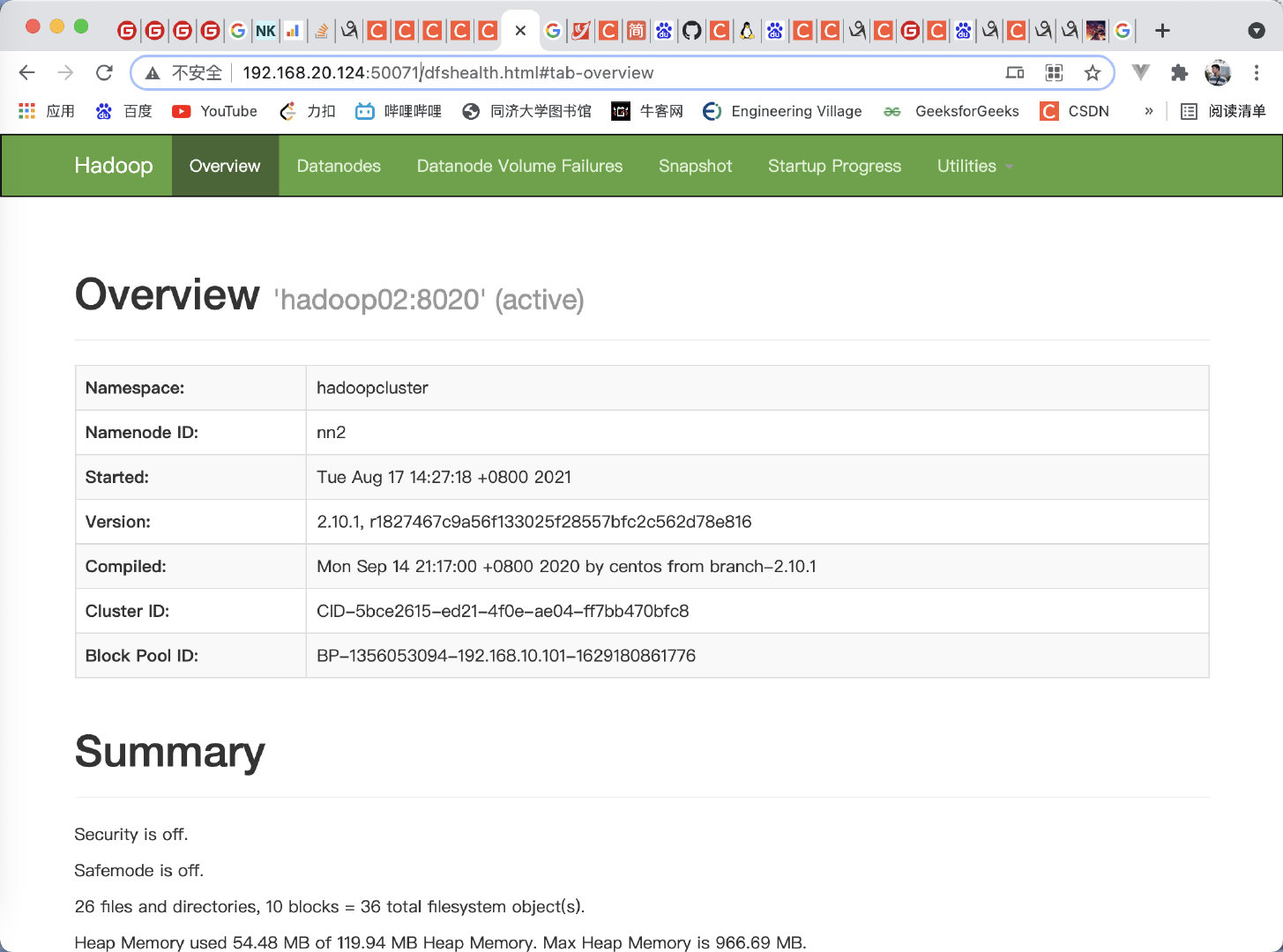
在本地浏览器里访问如下地址: http://192.168.10.101:8088/ 自动跳转到了NNA的cluster页面

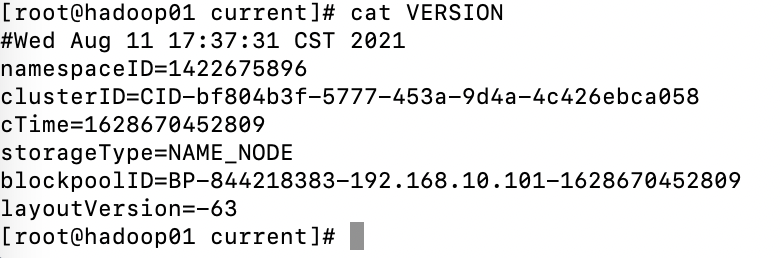
namespaceID=1422675896
clusterID=CID-bf804b3f-5777-453a-9d4a-4c426ebca058
cTime=1628670452809
storageType=NAME_NODE
blockpoolID=BP-844218383-192.168.10.101-1628670452809
layoutVersion=-63
八、常用组件安装
8.1 mysql8安装
# cd /opt
8.1.1 安装MySQL Server
因为CentOS 7默认安装的数据库是Mariadb,所以使用YUM命令是无法安装MySQL的,只会更新Mariadb。
因此使用rpm来进行安装。
这里,我们使用国内的清华大小的镜像源安装,地址:
清华大学开源镜像源
添加国内安装源并安装
切换目录,如果没有,需新建:
下载:
# wget http://mirrors.tuna.tsinghua.edu.cn/mysql/yum/mysql80-community-el7/mysql80-community-release-el7-1.noarch.rpm
安装
# rpm -ivh mysql80-community-release-el7-1.noarch.rpm
下载完成后,yum安装:
# yum install mysql-server
如果显示以下内容说明安装成功:
Complete!
检查是否已经设置为开机启动MySQL服务
# systemctl list-unit-files|grep mysqld
则表示已经设置为开机启动,如果没有设置为开机启动则执行
# systemctl enable mysqld.service
8.1.2 启动MySQL
# systemctl start mysqld.service
初始化
# mysqld --initialize
查看默认密码
# grep 'temporary password' /var/log/mysqld.log
localhost后面的最后的那一大串字符,就是密码,复制下来。【 7ZWYzNEIgJ+7】
登录
# mysql -uroot -p
输入刚刚的密码。【 7ZWYzNEIgJ+7】
重置root密码
> alter user 'root'@'localhost' identified by '12345678';
建议设置较为复杂的密码。
如果设置密码时候出现提示:
ERROR 1819 (HY000): Your password does not satisfy the current policy requirements
执行:
> set global validate_password.policy=0;
8.1.3 新建用户
建议不要使用root用户作为日常开发,新建一个用户使用:
> create user 'hadoop'@'localhost' identified by 'hadoop123';
授予全部权限:
> GRANT ALL PRIVILEGES ON *.* TO 'hadoop'@'localhost' WITH GRANT OPTION;
刷新:
> flush privileges;
8.2 HBASE安装
8.2.1 下载hbase
# cd /opt
# wget https://mirrors.cloud.tencent.com/apache/hbase/2.2.7/hbase-2.2.7-bin.tar.gz
# tar -zxvf hbase-2.2.7-bin.tar.gz
8.2.2 配置环境变量
# vi /etc/profile
加入如下配置
export HBASE_HOME=/opt/hbase-2.2.7
export PATH=$HBASE_HOME/bin:$PATH
更新环境变量
# source /etc/profile
8.2.3 检查是否安装成功
# hbase version

8.2.4 配置文件
执行
# cd /opt/hbase-2.2.7/conf
# vi hbase-env.sh
修改jdk和默认使用的zookeeper
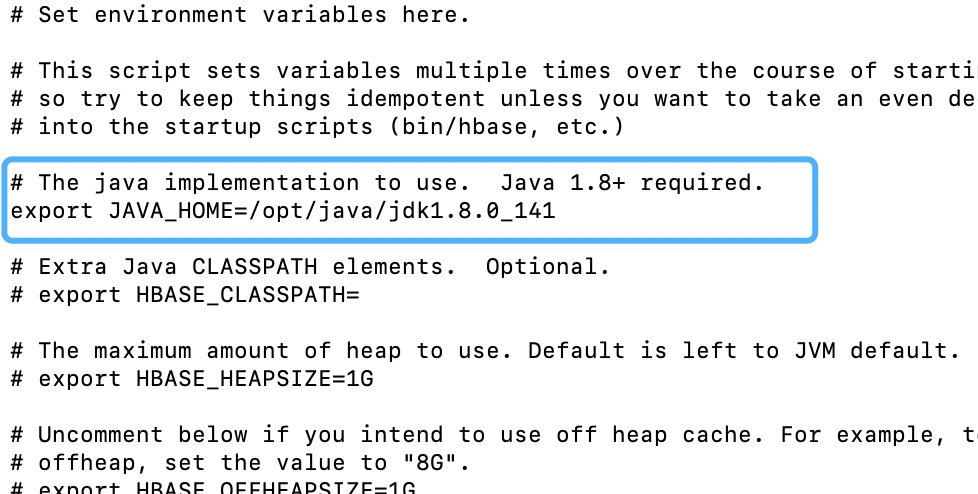

修改hbase-site.xml
# vi hbase-site.xml
加入如下配置
<!--指定为分布式-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!--指定存储路径-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop01:8020/hbase</value>
</property>
<!--指定zk的地址,用,分割-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181,hadoop04:2181,hadoop05:2181</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>./tmp</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>

执行
# vi regionservers
删掉原有的localhost加入
hadoop01hadoop02hadoop03hadoop04hadoop05
配置备用主机
# vi /opt/hbase-2.2.7/conf/backup-masters
加入hadoop02
把配置好的hbase-2.2.7压缩
# tar -czvf hbase-2.2.7.tar.gz
拷贝到其他节点
# scp hbase-2.2.7.tar.gz root@hadoop02:/opt# scp hbase-2.2.7.tar.gz root@hadoop03:/opt# scp hbase-2.2.7.tar.gz root@hadoop04:/opt# scp hbase-2.2.7.tar.gz root@hadoop05:/opt
去其他机器解压
# tar -xzvf hbase-2.1.2.tar.gz# rm –rf hbase-2.1.2.tar.gz
8.2.5 启动HBASE
重启hadoop
# sh /opt/hadoop/hadoop-2.10.1/sbin/stop-all.sh
# sh /opt/hadoop/hadoop-2.10.1/sbin/start-all.sh
主机启动hbase
# sh /opt/hbase-2.2.7/bin/start-hbase.sh
# sh /opt/hbase-2.2.7/bin/stop-hbase.sh
从机启动hbase
# sh /opt/hbase-2.2.7/bin/hbase-daemon.sh start regionserver
# sh /opt/hbase-2.2.7/bin/hbase-daemon.sh stop regionserver
8.2.6 端口查看
前往http://192.168.20.124:16010/查看HBSE启动页面(192.168.20.124为服务器ip,16010是从hadoop01的16010映射出来的端口)

前往http://192.168.20.124:16030/查看资源管理器页面

8.3 Kafka安装
8.3.1 下载kafka
# cd /opt
# wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.6.2/kafka_2.13-2.6.2.tgz
# tar -zxvf kafka_2.13-2.6.2.tgz
# mv kafka_2.13-2.6.2 kafka
8.3.2 启动ZK
Kafka使用ZooKeeper,所以要先启动一个ZooKeeper服务器。
8.3.3 KAFKA基本配置
Kafka在config目录下提供了一个基本的配置文件。为了保证可以远程访问Kafka,我们需要修改两处配置。打开config/server.properties文件。
# vi config/server.properties
更改brokeid,每台机器都有自己的id。在很靠前的位置有listeners和 advertised.listeners两处配置的注释,去掉这两个注释,并且根据当前服务器的IP修改如下:

更改日志存放路径

更改zookeeper连接

拷贝到其他虚拟机
# scp -r kafka hadoop02:$PWD# scp -r kafka hadoop03:$PWD# scp -r kafka hadoop04:$PWD# scp -r kafka hadoop05:$PWD
配置环境变量
# vi /etc/profile
export KAFKA_HOME=/opt/kafkaexport PATH=$PATH:$KAFKA_HOME/bin

拷贝到其他虚拟机
scp /etc/profile root@hadoop02:/etc
scp /etc/profile root@hadoop03:/etc
scp /etc/profile root@hadoop04:/etc
scp /etc/profile root@hadoop05:/etc
记得修改其他虚拟机的brokeid!
8.3.4 启动KAFKA
# sh /opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties
# sh /opt/kafka/bin/kafka-server-stop.sh /opt/kafka/config/server.properties
# sh /opt/kafka/bin/kafka-server-start.sh -daemon /opt/kafka/config/server.properties // 后台启动

8.3.5 设置topic
创建topic
# sh /opt/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic demo
查看topic列表
# sh /opt/kafka/bin/kafka-topics.sh --list --zookeeper hadoop01:2181
查看描述topics信息
# sh /opt/kafka/bin/kafka-topics.sh --describe --zookeeper hadoop01:2181 --topic demo

返回信息说明:
-
第一行给出了所有分区的摘要,每个附加行给出了关于一个分区的信息。 由于我们只有一个分区,所以只有一行。
-
“Leader”: 是负责给定分区的所有读取和写入的节点。 每个节点将成为分区随机选择部分的领导者。
-
“Replicas”: 是复制此分区日志的节点列表,无论它们是否是领导者,或者即使他们当前处于活动状态。
-
“Isr”: 是一组“同步”副本。这是复制品列表的子集,当前活着并被引导到领导者。
8.3.6 启动生产者
# bin/kafka-console-producer.sh --topic first --broker-list hadoop01:9092
8.3.7 启动消费者
# bin/kafka-console-consumer.sh --topic first --bootstrap-server hadoop01:9092
–from-beginning 表示从起始位读取
8.3.8 测试
在生产者窗口输入,可以在消费者端查看输入的内容
生产端:
>test message
>{}
>{"id":"1"}


特别提示:
一定要先启动ZooKeeper 再启动Kafka 顺序不可以改变。
先关闭kafka ,再关闭zookeeper。
8.4 Spark安装
8.4.1 下载spark
去官网https://spark.apache.org/downloads.html查找合适的版本,这里选用【spark-3.1.2-bin-hadoop2.7.tgz】
进行创建目录、下载、解压、改名四连操作
# cd /opt
# wget https://www.apache.org/dyn/closer.lua/spark/spark-3.1.2/spark-3.1.2-bin-hadoop2.7.tgz
# tar -zxvf spark-3.1.2-bin-hadoop2.7.tgz
# mv spark-3.1.2-bin-hadoop2.7 spark
8.4.2 配置环境变量
# vi /etc/profile
新增
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin
拷贝到其他虚拟机
# scp /etc/profile root@hadoop02:/etc
# scp /etc/profile root@hadoop03:/etc
# scp /etc/profile root@hadoop04:/etc
# scp /etc/profile root@hadoop05:/etc
在各机器分别重启环境变量
# source /etc/profile
8.4.3 修改spark的配置文件
# cd /opt/spark/conf/
# cp spark-env.sh.template spark-env.sh # 拷贝一份配置文件
# vi spark-env.sh
新增
export JAVA_HOME=/opt/jdk1.8.0_141export HADOOP_HOME=/opt/hadoop-2.10.1export HADOOP_CONF_DIR=/opt/hadoop-2.10.1/etc/hadoop# export SPARK_MASTER_IP=hadoop01 # 集群中Master地址是不固定的 所以必须把这行注释掉export SPARK_MASTER_PORT=7077export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop01:2181,hadoop02:2181,hadoop03:2181,hadoop04:2181,hadoop05:2181 -Dspark.deploy.zookeeper.dir=/spark"

如果需要使用浏览器查看日志则需要开启历史日志服务:
# cp spark-defaults.conf.template spark-defaults.conf# vi spark-defaults.conf// 加入:spark.master spark://hadoop01:7077# spark.eventLog.enabled true# spark.eventLog.dir hdfs://hadoop01:8021/directoryspark.serializer org.apache.spark.serializer.KryoSerializerspark.driver.memory 5gspark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"

重命名并修改slaves.template文件
# mv workers.template workers
# vi workers
加上
hadoop02
hadoop03
hadoop04
hadoop05
拷贝到其他机器
# cd /opt
# scp -r spark hadoop02:$PWD
# scp -r spark hadoop03:$PWD
# scp -r spark hadoop04:$PWD
# scp -r spark hadoop05:$PWD
8.4.4 启动Spark
启动zk,查看zk是否已经启动
# /opt/zookeeper/bin/zkServer.sh status
启动spark
在hadoop01启动
# sh /opt/spark/sbin/start-all.sh

在hadoop02启动master
# sh /opt/spark/sbin/start-master.sh

8.4.5端口查看

在服务器把hadoop01的8080端口转给服务器的8080端口,访问 【服务器ip:8080】

可以看到hadoop01的spark为active状态
在服务器把hadoop02的8080端口转给服务器的8080端口,访问 【服务器ip:8081】

hadoop02的spark为standby状态
测试停用hadoop01的master
# jps

# kill -9 38533
刷新hadoop2的spark

发现这时hadoop02的spark已经接替了hadoop01进行工作
8.4.6 测试spark
启动spark shell,方便用户进行交互式编程,用户可以在该命令行下用scala编写spark程序。
# hdfs dfs -mkdir -p /spark/input
# cd /opt
# vi test
// 输入测试文本
I LOVE TONGJI
I AM CHINESE
I LOVE CHINA
# hdfs dfs -put test /spark/input
8.5 Flume 安装
8.5.1 flume下载
# cd /opt
# wget https://mirrors.huaweicloud.com/apache/flume/1.8.0/apache-flume-1.8.0-bin.tar.gz
# tar -zxvf apache-flume-1.9.0-bin.tar.gz
# mv apache-flume-1.9.0-bin/ flume
删除lib/guava-11.0.2.jar 防止不兼容
# cd /opt/flume/lib
# rm -rf guava-11.0.2.jar
8.5.2 配置环境变量
# vi /etc/profile
export FLUME_HOME=/opt/flume/bin
export PATH=$PATH:$FLUME_HOME/bin
# source /etc/profile
拷贝到其他虚拟机
# scp /etc/profile root@hadoop02:/etc
# scp /etc/profile root@hadoop03:/etc
# scp /etc/profile root@hadoop04:/etc
# scp /etc/profile root@hadoop05:/etc
修改flume配置
# cd /opt/flume/conf
//加入
export JAVA_HOME=/opt/java/jdk1.8.0_141
8.5.3 监听端口测试
- 通过netcat工具向本机44444端口发送数据
- flume监控本机44444端口,通过flume的source端读取数据
- flume将获得的数据通过sink端写到控制台
安装netcat工具
# yum install -y nc
在flume中执行
# mkdir /opt/flume/job
# cd /opt/flume/job
# touch net-flume-logger.conf
粘贴如下配置
# example.conf: A single-node Flume configuration
# Name the components on this agent 这个名字在单台flume唯一
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
在本机执行
# bin/flume-ng agent -n a1 -c conf/ -f job/net-flume-logger.conf -Dflume.root.logger=INFO,console
复制一份本机ssh
# nc localhost 44444
就可以在本机通信了

拷贝到其他机器
# cd /opt
# scp -r flume hadoop02:$PWD
# scp -r flume hadoop03:$PWD
# scp -r flume hadoop04:$PWD
# scp -r flume hadoop05:$PWD
8.6 Elasticsearch安装
8.6.1 下载elasticsearch
# cd /opt
# wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.4.3.tar.gz
# tar -zxf elasticsearch-6.4.3.tar.gz
# mv elasticsearch-6.4.3/ elasticsearch
8.6.2 修改elasticsearch配置文件
# cd /opt/elasticsearch/config
# vi elasticsearch.yml
修改集群名,节点名,network下内容为实际的ip地址

修改端口号:Elasticsearch有两个端口号是 9200和9300,那他们有什么区别?
9200:http协议端口号,暴露ES RESTful接口端口号, ES节点和外部通信的端口号
9300: TCP协议端口号,ES集群之间通讯端口号

后续查看集群健康度:添加这行是因为elasticsearch服务与elasticsearch-head之间可能存在跨越,修改elasticsearch配置即可,在elastichsearch.yml中添加如下命名即可:
#allow origin
http.cors.enabled: true
http.cors.allow-origin: "*"
拷贝到其他虚拟机
# cd /opt
# scp -r elasticsearch hadoop02:$PWD
# scp -r elasticsearch hadoop03:$PWD
# scp -r elasticsearch hadoop04:$PWD
# scp -r elasticsearch hadoop05:$PWD
8.6.3 启动elasticsearch
# cd /opt/elasticsearch/bin
# ./elasticsearch
【报错】root用户无法启动

-
解决方案:
因为安全问题Elasticsearch 不让用root用户直接运行,所以要创建新用户
第一步:liunx创建新用户 adduser XXX 然后给创建的用户加密码 passwd XXX 输入两次密码。
第二步:切换刚才创建的用户 su XXX 然后执行elasticsearch 会显示Permission denied 权限不足。
第三步:给新建的XXX赋权限,chmod 777 * 这个不行,因为这个用户本身就没有权限,肯定自己不能给自己付权限。所以要用root用户登录付权限。
第四步:root给XXX赋权限,chown -R XXX /你的elasticsearch安装目录。
然后执行成功。
# add user hadoop 【密码为hadoop123】
# chown -R hadoop /opt/elasticsearch/
# su hadoop
# cd /opt/elasticsearch/bin
# ./elasticsearch
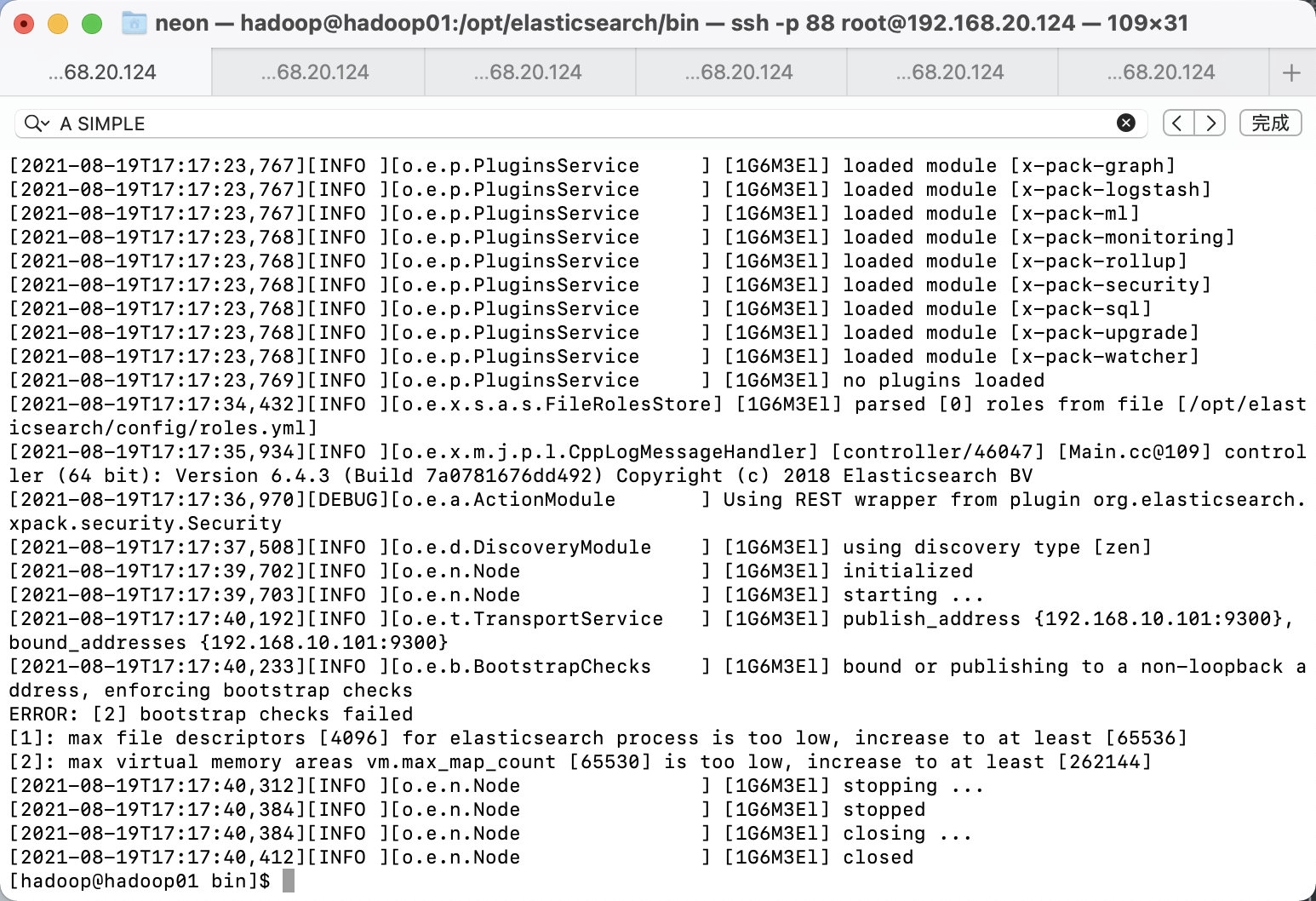
再次报错, 解决
# su root
# vi /etc/sysctl.conf
vm.max_map_count=655360
# cd /etc
# sysctl -p
再次切换到hadoop用户,再次启动
# su hadoop
# cd /opt/elasticsearch/bin
# ./elasticsearch
解决方案:
切换到root
# su root
# vi /etc/security/limits.conf
在最后添加(*要加上)
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
启动成功

启动其他机器之前,克隆data文件会导致数据不同步
报该错误解决办法
failed to send join request to master
因为克隆导致data文件也克隆呢,直接清除每台服务器data文件
# cd /opt/elasticsearch/data
# rm -rf nodes/
当启用其他机器的es后,会更新出

8.6.4 端口查看
前往192.168.10.101:9200/_cat/nodes/pretty
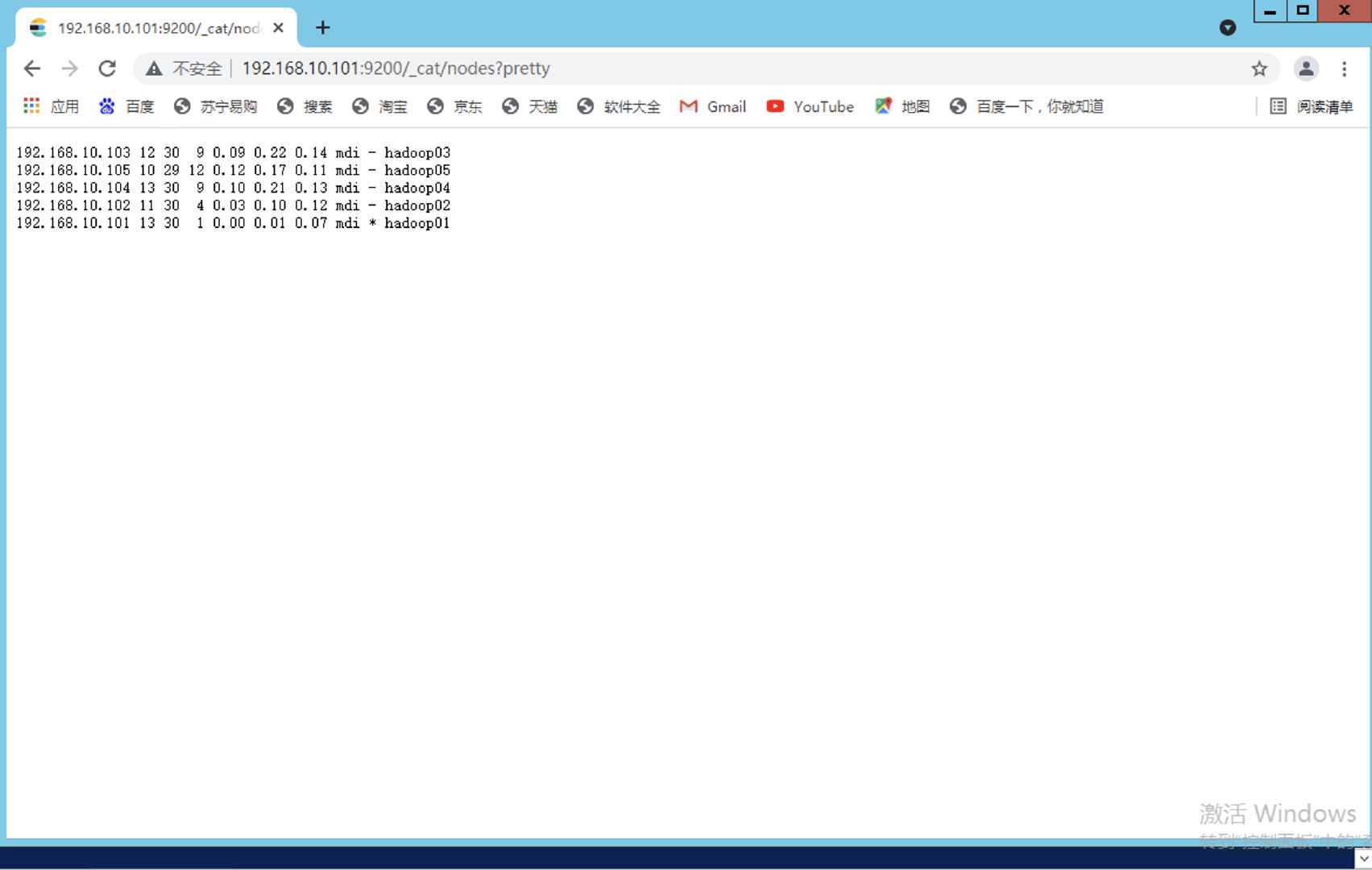
发现启动成功 *是主机
当hadoop01挂掉后

hadoop03接替成为主机
9.7 Flink安装
8.7.1 下载
与hadoop2.10.1兼容的flink版本为flink 1.10.0
# cd /opt
# wget https://mirrors.tuna.tsinghua.edu.cn/apache/flink/flink-1.11.4/flink-1.11.4-bin-scala_2.11.tgz
# tar -zxf flink-1.11.4-bin-scala_2.11.tgz
# mv flink-1.11.4 flink
8.7.2 修改环境变量
# vi /etc/profile
export FLINK_HOME=/opt/flink
export PATH=$FLINK_HOME/bin:$PATH
加载
# source /etc/profile
8.7.3修改flink配置
# cd flink/conf
# flink-conf.yaml
修改为
jobmanager.rpc.address: hadoop-master
high-availability: zookeeper
high-availability.storageDir: hdfs:///flink/ha/
high-availability.zookeeper.quorum: hadoop01:2181,hadoop02:2181,hadoop03:2181,hadoop04:2181,hadoop05:2181


配置高可用的master
# vi masters
hadoop01:8081
hadoop02:8081
# vi workes
hadoop03
hadoop04
hadoop05
将配置文件发送至各节点
8.7.4 启动flink
在hadoop01启动flink
# /opt/flink/bin/start-cluster.sh
8.7.5 端口测试
连接192.168.10.101:18081

9
9.1 jps群起脚本
批量查看服务 jps
执行
# cd /usr/local/bin
# vi xcall.sh
写入
#!/bin/bash
case $1 in
"jps"){
for i in hadoop01 hadoop02 hadoop03 hadoop04 hadoop05
do
echo "-------------$i---------------"
ssh $i jps
done
};;
esac
在【所有机器】建立软连接
# cd /usr/local/bin
# ln -s /opt/jdk/bin/jps jps
执行
# xcall.sh

9.2 zk 群起脚本
#!/bin/bash
case $1 in
"start"){
for i in hadoop01 hadoop02 hadoop03 hadoop04 hadoop05
do
echo "*************$i*****************"
ssh $i "sh /opt/zookeeper/bin/zkServer.sh start"
done
};;
"stop"){
for i in hadoop01 hadoop02 hadoop03 hadoop04 hadoop05
do
echo "*************$i*****************"
ssh $i "sh /opt/zookeeper/bin/zkServer.sh stop"
done
};;
esac
9.3 kafka群起脚本
#!/bin/bash
case $1 in
"start"){
for i in hadoop01 hadoop02 hadoop03 hadoop04 hadoop05
do
echo "*************$i*****************"
ssh $i "/opt/kafka/bin/kafka-server-start.sh -daemon /opt/kafka/config/server.properties"
done
};;
"stop"){
for i in hadoop01 hadoop02 hadoop03 hadoop04 hadoop05
do
echo "*************$i*****************"
ssh $i "/opt/kafka/bin/kafka-server-stop.sh"
done
};;
esac
在粘贴到/usr/local/bin目录
# cd /opt/kafka/bin
# touch kafka.sh
# chmod 777 kafka.sh
# kafka.sh start
启动不了

缺少这个目录就需要建立软连接
# ln -s /usr/local/bin/kafka.sh /opt/kafka/bin/kafka.sh

附录
附录1 组件版本汇总
| 组件名称 | 版本 | 端口 |
|---|---|---|
| CentOS | CentOS-7 | 88-92 |
| JDK | JDK1.8.0 | |
| MySQL | 8.0 | 3306 |
| Apache Hadoop | 2.10.1 | |
| Zookeeper | 3.7.0 | 2181 |
| Hbase | 2.2.7 | 16010/16030 |
| Hive | 2.3.6 | |
| Kafka | 2.6.2 | |
| Spark | 3.1.2 | 8080 |
| Flume | 1.9.0 | |
| Elasticsearch | 6.4.3 | 9200 |
| Flink | 1.10.0 | 18081 |
附录2 Bug汇总
| Bug编号 | 详情 | 解决方法 | 参考链接 |
|---|---|---|---|
| 080801 | bash: 找不到文件内容 | 输入: # export PATH=/bin:/usr/bin:$PATH | reference |
| 081601 | root@zServer-2-8:/opt/zookeeper-3.4.13/bin# sh zkServer.sh start JMX enabled by default bin/zkServer.sh: 95: /opt/zookeeper-3.4.13/bin/zkEnv.sh: Syntax error: “(” unexpected (expecting “fi”) | zookeeper版本不对,需要重新下载3.4.9的zookeeper | reference |
| 081701 | 格式化HDFS时,core.xml报错 报错信息:21/08/17 09:53:48 ERROR conf.Configuration: error parsing conf core-site.xml com.ctc.wstx.exc.WstxParsingException: Illegal processing instruction target (“xml”); xml (case insensitive) is reserved by the specs. at [row,col,system-id]: [2,5,“file:/opt/hadoop/hadoop-2.10.1/etc/hadoop/core-site.xml”] at com.ctc.wstx.sr.StreamScanner.constructWfcException(StreamScanner.java:621) at com.ctc.wstx.sr.StreamScanner.throwParseError(StreamScanner.java:491) at com.ctc.wstx.sr.BasicStreamReader.readPIPrimary(BasicStreamReader.java:4019) at com.ctc.wstx.sr.BasicStreamReader.nextFromProlog(BasicStreamReader.java:2141) at com.ctc.wstx.sr.BasicStreamReader.next(BasicStreamReader.java:1181) at org.apache.hadoop.conf.Configuration.loadResource(Configuration.java:2826) at org.apache.hadoop.conf.Configuration.loadResources(Configuration.java:2755) at org.apache.hadoop.conf.Configuration.getProps(Configuration.java:2635) at org.apache.hadoop.conf.Configuration.get(Configuration.java:1097) at org.apache.hadoop.conf.Configuration.getTimeDuration(Configuration.java:1704) at org.apache.hadoop.conf.Configuration.getTimeDuration(Configuration.java:1685) at org.apache.hadoop.util.ShutdownHookManager.getShutdownTimeout(ShutdownHookManager.java:183) at org.apache.hadoop.util.ShutdownHookManager.shutdownExecutor(ShutdownHookManager.java:145) at org.apache.hadoop.util.ShutdownHookManager.access$300(ShutdownHookManager.java:65) at org.apache.hadoop.util.ShutdownHookManager$1.run(ShutdownHookManager.java:102) | core.xml内zookeeper和hadoop路径错误,位于/opt路径写成了/root路径 | |
| 081702 | java.io.IOException: Invalid configuration: a shared edits dir must not be specified if HA is not enabled. at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.(FSNamesystem.java:767) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.(FSNamesystem.java:712) at org.apache.hadoop.hdfs.server.namenode.NameNode.format(NameNode.java:1189) at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:1655) at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1782) | hdfs.xml文件内配置写错了,正确应该如下 dfs.ha.namenodes.hadoopcluster nn1,nn2 dfs.namenode.rpc-address.hadoopcluster.nn1 hadoop01:8020 | reference |
| 081703 | 执行JN启动命令后,JN未启动 | 前往【 /opt/hadoop/hadoop-2.10.1/logs/hadoop-root-journalnode-hadoop05.out 】查看日志,一般为拼写错误 | |
| 081801 | nodemanager did not stop gracefully after 5 seconds: killing with kill -9 | 是因为资源管理器 (RM) 在节点管理器 (NM) 之前停止。NM 需要从 RM 中注销自己。因此,当 NM 尝试与 RM 连接(以注销自己)时,它会失败,因为 RM 已经停止。因此发生超时(等待 5 秒后 - 在 start-yarn.sh 中提到)导致 NM 被杀死并且不允许正常停止。 | reference |
| 081802 | java.nio.file.NoSuchFileException: server.properties at sun.nio.fs.UnixException.translateToIOException(UnixException.java:86) at sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:102) at sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:107) at sun.nio.fs.UnixFileSystemProvider.newByteChannel(UnixFileSystemProvider.java:214) at java.nio.file.Files.newByteChannel(Files.java:361) at java.nio.file.Files.newByteChannel(Files.java:407) at java.nio.file.spi.FileSystemProvider.newInputStream(FileSystemProvider.java:384) at java.nio.file.Files.newInputStream(Files.java:152) at org.apache.kafka.common.utils.Utils.loadProps(Utils.java:623) at kafka.Kafka . g e t P r o p s F r o m A r g s ( K a f k a . s c a l a : 51 ) < b r / > a t k a f k a . K a f k a .getPropsFromArgs(Kafka.scala:51)<br/> at kafka.Kafka .getPropsFromArgs(Kafka.scala:51)<br/>atkafka.Kafka.main(Kafka.scala:67) at kafka.Kafka.main(Kafka.scala) | 使用的命令错误 # sh /opt/kafka/bin/kafka-server-start.sh config/server.properties 后面的文件路径不明确,要明确后面的路径 | |
| 081901 | /usr/libexec/grepconf.sh:行5: grep: 未找到命令 | 重启环境变量出错,原因是环境变量里面出现了语法错误 | |
| 081902 | -bash: hdfs: 未找到命令 | 环境变量未配置,需要在/etc/profile中配置hadoop环境变量,注意路径 :export HADOOP_HOME=/opt/hadoop/hadoop-2.10.1 export PATH= P A T H : PATH: PATH:HADOOP_HOME/bin: H A D O O P H O M E / s b i n : HADOOP_HOME/sbin: HADOOPHOME/sbin:PATH | |
| 082001 | 2021-08-20 14:06:07,494 ERROR org.apache.flink.runtime.entrypoint.ClusterEntrypoint [] - Could not start cluster entrypoint StandaloneSessionClusterEntrypoint. org.apache.flink.runtime.entrypoint.ClusterEntrypointException: Failed to initialize the cluster entrypoint StandaloneSessionClusterEntrypoint. at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.startCluster(ClusterEntrypoint.java:200) ~[flink-dist_2.11-1.11.4.jar:1.11.4] at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.runClusterEntrypoint(ClusterEntrypoint.java:577) [flink-dist_2.11-1.11.4.jar:1.11.4] at org.apache.flink.runtime.entrypoint.StandaloneSessionClusterEntrypoint.main(StandaloneSessionClusterEntrypoint.java:67) [flink-dist_2.11-1.11.4.jar:1.11.4] Caused by: java.io.IOException: Could not create FileSystem for highly available storage path (hdfs:/flink/ha/default) | 新版本的flink缺少jar包,需要前往flink/lib下载 # wget https://repo.maven.apache.org/maven2/org/apache/flink/flink-shaded-hadoop-2-uber/2.7.5-7.0/flink-shaded-hadoop-2-uber-2.7.5-7.0.jar | |
| 082002 | Trying to fail over after sleeping for 8412ms. java.net.ConnectException: Call From hadoop01/192.168.10.101 to hadoop02:8020 failed on connection exception: java.net.ConnectException: 拒绝连接; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused | 8020为namenode端口,namenode未开启 | |
| 082003 | Caused by: java.net.BindException: Could not start rest endpoint on any port in port range 8081 at org.apache.flink.runtime.rest.RestServerEndpoint.start(RestServerEndpoint.java:234) ~[flink-dist_2.11-1.11.4.jar:1.11.4] at org.apache.flink.runtime.entrypoint.component.DefaultDispatcherResourceManagerComponentFactory.create(DefaultDispatcherResourceManagerComponentFactory.java:171) ~[flink-dist_2.11-1.11.4.jar:1.11.4] | 8081端口被spark占用了,flink换成18081端口,去flink/conf/masters内修改端口 | reference |
参考链接
【HA配置】:https://blog.csdn.net/jy02268879/article/details/80245881?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-10.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-10.control
【HBASE版本】:https://blog.csdn.net/weixin_38797111/article/details/104525584
【HBASE集群配置】:https://blog.csdn.net/u014454538/article/details/83625554
【KAFKA集群配置】:https://zhuanlan.zhihu.com/p/127124014
【Flink集群配置】:https://blog.csdn.net/UncleZzz/article/details/106131543















 3483
3483











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}