






阳春三月,万物复苏。2025年3月中国数据库流行度排行榜的发布,不仅展现了中国数据库企业在技术创新、生态建设和应用深化方面的显著成就,也让人感受到市场的蓬勃生机。PolarDB凭借其强大的技术创新能力和完善的产品布局,成功重返排行榜榜首,彰显了其在数据库领域的领先地位和市场影响力。
国产数据库正在加速赶超国际同行,在云原生、分布式架构以及AI增强技术等关键领域取得了突破性进展。随着自主研发能力的持续提升和国际化战略的稳步推进,中国数据库产业必将迈向更加辉煌的未来。
一、榜单争锋战正酣,PolarDB夺桂冠,GoldenDB稳步攀
PolarDB凭借技术突破和生态影响力,时隔半年重返榜首。OceanBase紧随其后,GoldenDB持续上升,成功晋级至第三位。整体来看,排名层次逐渐清晰,头部厂商竞争白热化,而中坚力量则在技术创新与市场拓展中寻求更大突破。接下来,就和小编一同盘点榜单前十的表现。
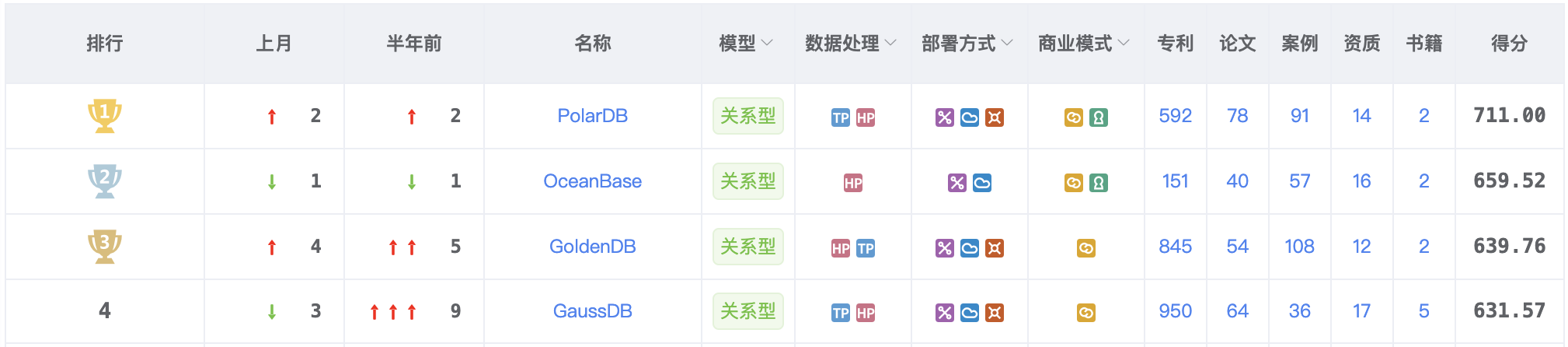
图1: 排行榜1-4位得分情况
PolarDB以711分的总分强势登顶排行榜,展现出强劲的市场竞争力。在TPC-C基准测试中,PolarDB以每分钟20.55亿笔交易(tpmC)和0.8元人民币/tpmC的成本,刷新了性能和性价比双榜世界纪录,相较于此前纪录,成本降低近40%。根据国际数据公司(IDC)发布的《2024年上半年中国分布式事务数据库软件市场跟踪报告》,2024上半年中国分布式事务数据库软件市场规模为1.5亿美元,其中阿里云在中国分布式数据库市场中排名第一。
近期举办的PolarDB开发者大会进一步提升了市场关注度。在大会上,阿里云宣布PolarDB将秉承软硬件协同设计理念,并计划于2025年下半年推出全球首款基于CXL(Compute Express Link)交换机的数据库专用服务器,这将推动数据库技术的进一步革新。
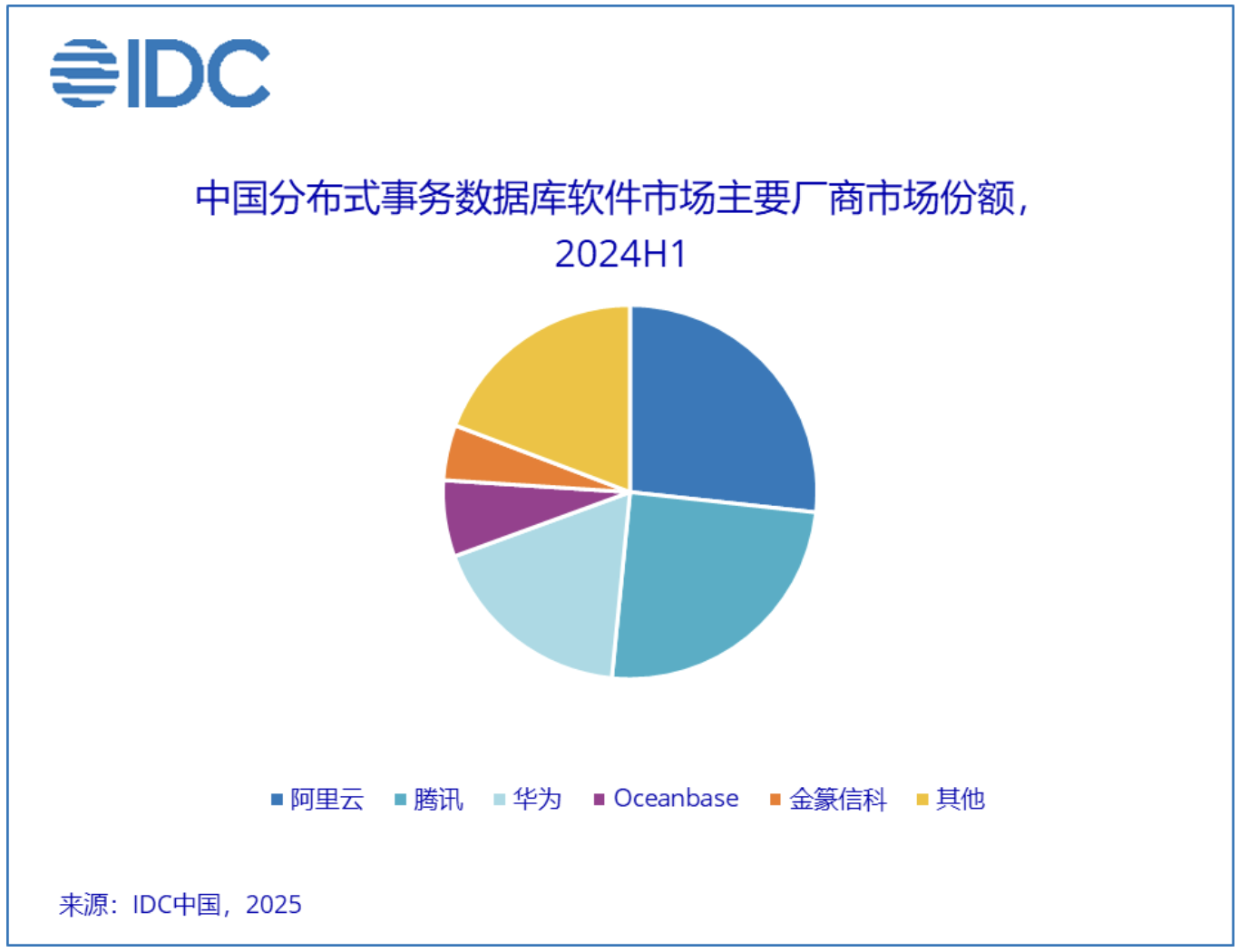
图2: 中国分布式事务数据库软件市场主要厂商市场份额
OceanBase本月以659.52分位列第二,尽管排名有变动,但其在分布式事务数据库市场的领导地位依然稳固。根据IDC报告,在独立数据库厂商中,OceanBase 市场份额位居第一,同时位列市场整体第四。此外,在「本地部署」中位列独立数据库厂商第一、整体排名第三。凭借卓越的事务处理能力,OceanBase正持续助力金融、政企等关键行业的数字化升级。
金篆信科GoldenDB以639.76分摘得探花,继续保持稳步攀升的态势。GoldenDB在市场表现方面尤为亮眼,其在国家开发银行的授权及服务采购项目中成功中标,金额高达3347.6万元,成为2月份金额最高的项目。
GaussDB持续保持前列,根据IDC报告,2024年上半年中国分布式事务数据库市场规模达1.5亿美元,同比增长18.5%,华为GaussDB位列市场前三,在分布式数据库赛道展现出强大实力。
尽管本月榜单中第五-十位的产品排名未变,但市场竞争同样激烈,各大数据库厂商在技术创新、市场拓展和生态建设上持续发力,进一步巩固自身优势,力求在未来的排名争夺中占据更有利的位置。
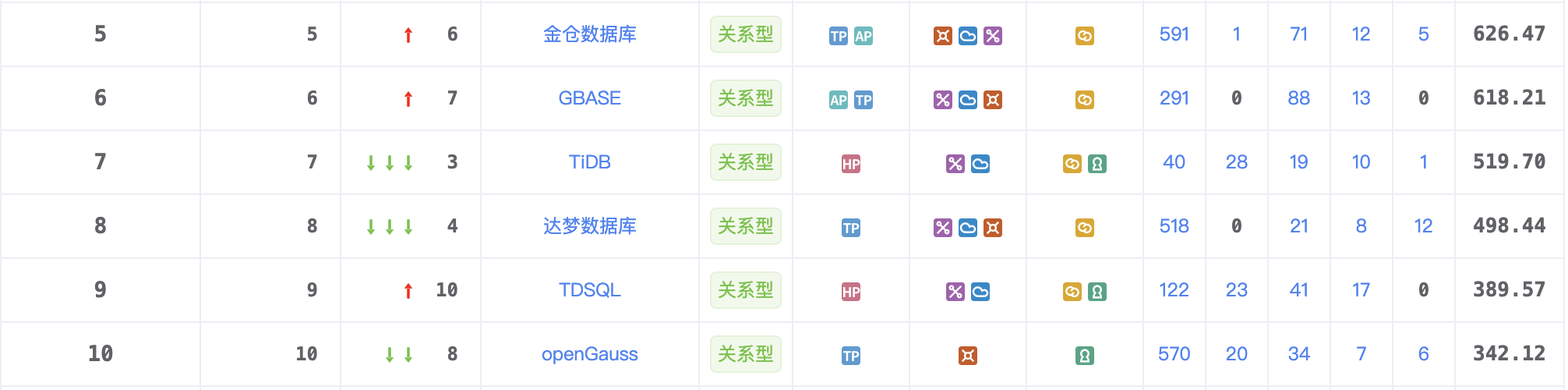
图3: 排行榜5-10位得分情况
金仓数据库 本月得分626.47分,稳居第五。其产品已全面覆盖医院信息化建设的五大核心系统,在医疗行业提供高效、安全、稳定的数据支撑。此外,金仓数据库管理系统(KingbaseES)入选《2024年度专利密集型产品名单》,进一步巩固了其在国产数据库领域的技术积累和生态建设。
GBASE 以609.27分稳步前行。近期,南大通用成功中标广西商务厅数据库采购项目,成为唯一入围的分布式数据库厂商,进一步展现了其在政府和企业数字化转型中的竞争优势。
PingCAP数据库产品 TiDB 继续保持榜单第七名,并在全球市场影响力不断增强。其分布式架构、高可扩展性和HTAP能力,使其在金融、电信、互联网等行业广泛应用。随着云原生架构和AI时代的到来,TiDB正成为现代企业数据库解决方案的关键选择。
达梦数据库本月得分498.44分。上市首年,达梦数据发布的2024年度业绩报告显示,全年营业收入增长31.49%,净利润增长22.26%。这一成绩展现了达梦作为“国产数据库第一股”的稳健增长势头。
腾讯云TDSQL本月得分389.57,排名第九。在富融银行核心系统升级项目中,TDSQL凭借100%兼容MySQL的特性,实现无感迁移,保障业务连续性,降低运营成本,展现了其在金融数字化转型中的强大技术实力。
openGauss本月得分342.12分,位居第十。作为国产开源数据库的代表,其正积极探索AI与数据库的融合。近期,openGauss结合DeepSeek的RAG框架,实现了本地知识库的智能问答,提升了AI助手的准确性,为企业级用户提供了更安全、可控的本地化解决方案。
二、国产数据库竞速升级,榜单黑马崭露锋芒
本月的中国数据库排行榜中,一些排名上升或在技术创新、市场影响力方面表现突出的数据库产品同样备受关注,由于篇幅有限,接下来我们就挑选部分产品进行盘点。
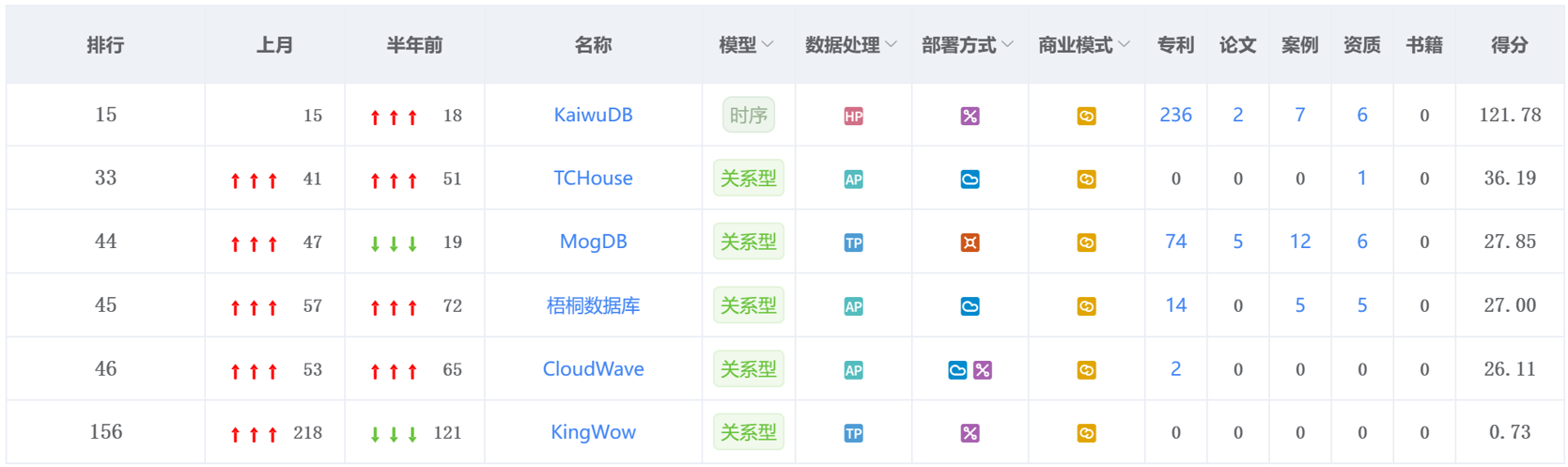
图4: 本月榜单热度上升产品的得分情况
排名第 15 位的 KaiwuDB ,其社区版本 KWDB 成为国内唯一入选 “2024 全球新势力项目 OpenRank Top10” 的开源项目,充分体现了其在全球开源生态中的活跃度与影响力。
自开源以来,KWDB 在项目推广、体系建设、人才培养和生态协作等方面取得了显著进展,逐步构建起开放且活跃的社区生态。未来,随着其在开源领域的持续深耕,KaiwuDB 有望在排行榜中进一步突破,为中国数据库产业的崛起贡献更多力量。
腾讯云的企业级托管型数据仓库 TCHouse 本月排名 上升 8 位,位列第 33 名。TCHouse 在稳定性、安全性方面表现优秀,同时提供 自主运维工具和自主开发环境,满足用户在 移动互联、广告、银行、保险、游戏、教育、地图 等行业的数仓需求。其高效的数据分析能力,为用户提升查询效率、释放数据价值提供了有力支撑。
由云和恩墨打造的MogDB本月排名上升 3 位,市场影响力持续扩大。近期,MogDB 在电力行业等关键领域的广泛应用和技术突破,进一步彰显了其技术实力和竞争优势。凭借高并发处理能力、快速故障恢复机制和全方位数据安全防护,MogDB 不仅为企业的数字化转型提供了有力支持,还通过优化 IT 基础设施,帮助企业有效降低了运营成本。
本月,梧桐数据库 排名上升了12 位,相较半年前已累计提升 近 30 位。其是由 中移动信息技术有限公司(中国移动集团大数据中心) 研发的一款 分布式 OLAP 数据库,支持 存算分离、无状态架构,具备 高可用、高可靠、高扩展 等特性,并采用 向量化计算 提升查询性能。其在大数据分析场景下的卓越表现,使其成为企业级 OLAP 解决方案的重要选择。
CloudWave 排名 第 46 位。相比传统数据库,CloudWave 解决了 云上弹性伸缩、数据格式单一、数据共享受限 等问题,采用 多集群共享数据架构,实现存算分离、弹性扩展,提供安全、高效、低成本的解决方案,广泛适用于 数据科学、数据治理、商业智能、现代数据共享等场景。
本月榜单中还有一款备受关注的黑马——Kingwow(金乌数据库),其排名从上月的 218 位大幅跃升至 156 位,展现出强劲的增长势头。就在上月,金乌数据库成功中标贵州农信国产分布式数据库项目,中标金额高达 405 万元,随着国产数据库在金融、能源等核心领域的加速渗透,金乌数据库的市场潜力和发展前景值得期待。
三、专家视角:解读中国数据库榜单

林春 太平洋保险数智研究院首席数据库专家。 PostgreSQL ACE,PGFans社区签约作者,中国PG分会专家。先后就职于平安科技,腾讯云等大厂。熟悉PG/Oracle等主流数据库相关技术,拥有丰富的实施、维护、管理经验,曾服务于通信、金融、电商、医疗等领域客户。热衷于开源PG技术研究及推广,活跃于PG技术社群,提倡DBA向内核精进,多次参加《中国PostgreSQL数据库生态大会》、《PostgreSQL中国技术大会》、《ACDU中国行》等技术大会。
25年的第一季度,国产数据库赛道的竞争十分激烈,前几名的排名变动频繁。3月PolarDB凭借技术突破和生态影响力重返榜首,这得益于其持续的技术创新。其他数据库也展现出强劲的实力,OceanBase在本地化部署上的优势明显,GoldenDB和GaussDB分别在案例和论文数量上有不错的表现。从榜单中可以感觉到,国内市场的头部企业对分布式的数据库架构越来越认可,这也给中国的IT数据库基础设施建设和创新带来更多利好。
PolarDB:云原生生态构建者
作为云原生数据库标杆,PolarDB 以计算存储分离架构为核心,支持超大规模横向扩展,在弹性伸缩、混合负载处理等方面表现突出。其通过深度优化云原生技术栈,形成覆盖 IaaS/PaaS/SaaS 的完整生态,持续领跑云数据库市场,展现出强大的技术整合能力与行业适配性。
OceanBase:分布式与 AI 融合先锋
以分布式事务处理技术为核心竞争力,OceanBase 在高并发、低时延场景下保持行业领先水平。其通过 AI 增强技术实现数据库自治运维,形成 “分布式架构 + 智能算法” 的双轮驱动模式,在金融、政务等对数据一致性要求极高的领域建立稳固护城河。
GoldenDB:金融级核心系统攻坚者
作为金融级分布式数据库代表,GoldenDB 以 SQL 兼容性和高可用性为核心优势,在关键业务系统替换中展现出成熟的迁移能力。其独创的全局事务管理技术,使其在保障业务连续性的同时,实现传统架构与分布式架构的无缝衔接。
GaussDB:全栈协同创新者
依托华为全栈技术优势,GaussDB 在分布式架构、硬件协同优化等方面形成差异化竞争力。其通过开源社区构建开放生态,在金融、能源等领域加速渗透,展现出从芯片到应用的垂直整合能力与行业解决方案深度。
随着DeepSeek的大热,AI与数据库的深度融合正在重构数据处理范式。面向AI,各大厂商相续发力向量索引以便数据库能更好的承载AI时代的业务需求。运用AI,不断推动数据库自治运维能力提升,更将催生数据价值挖掘的全新模式。这种技术融合不仅是数据库技术的迭代升级,更是各行业实现数据驱动创新的核心基础设施变革。
相关阅读
原文链接:https://www.modb.pro/db/1897207724635598848
更多精彩内容尽在墨天轮数据社区,围绕数据人的学习成长提供一站式的全面服务,持续促进数据领域的知识传播和技术创新。

















 1925
1925

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









