









算法通关村第一关——链表(Java)
链表是一种经典的数据结构,在很多软件里大量使用,例如操作系统、JVM等。
在面试中链表题目数量少,类型也相对固定,考察频率高,因此只要将常见题目都学完即可。
1 单链表的概念
1.1 链表的概念
单向链表就像铁链一样,元素之间相互连接,包含多个结点,每个结点有一个指向后继元素的next指针。表中最后一个元素的next指向null。

思考,如下二图是否都满足单链表的要求?
图一

图二
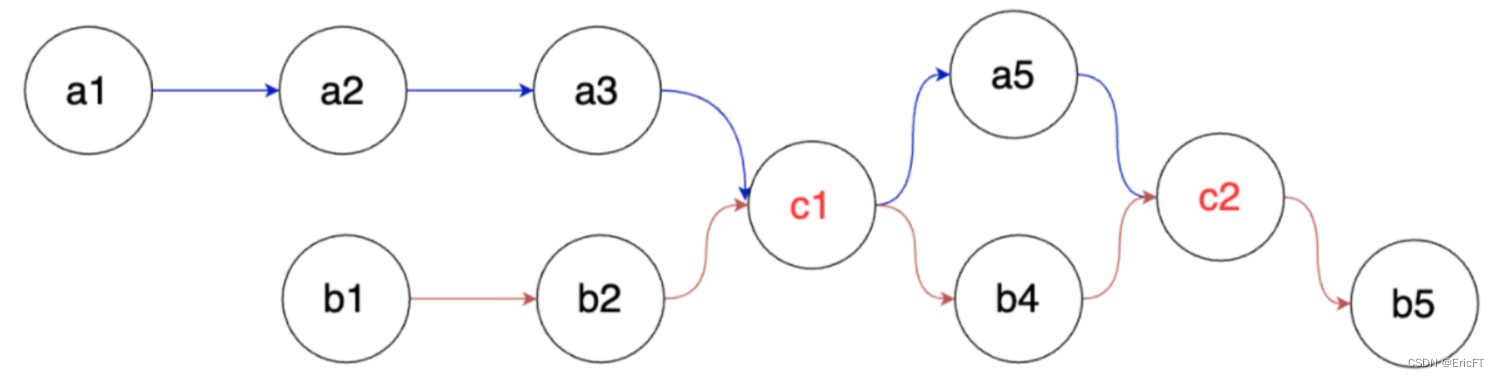
解析:
图一满足要求,因为链表要求环环相扣,核心是一个结点只能有一个后继,但不代表一个结点只能有一个被指向。
显然图一满足,图二不满足,c1有两个后继。
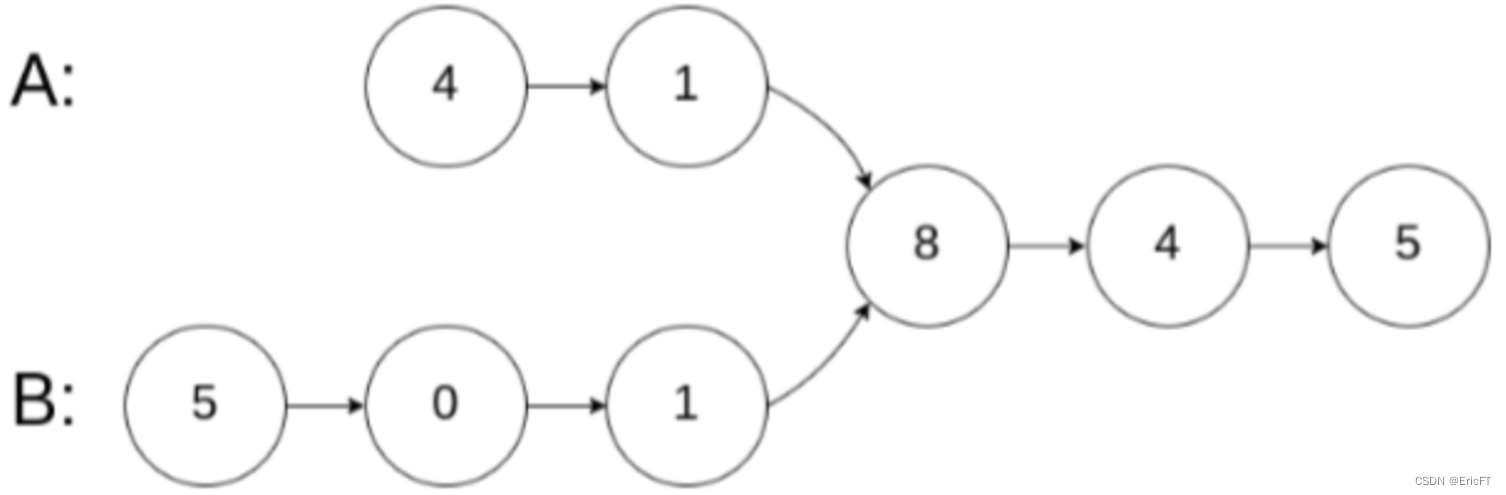
做题时还需注意比较的是值还是结点,有时可能两个结点的值相等,但不是同一个结点,如下图:
2 链表的相关概念
-
结点和头结点
在链表中,每个点都是由值和指向下一个结点的地址组成的独立单元,称为一个结点,有时也称节点。
对于单链表,如果知道了第一个元素,就可以通过遍历访问整个链表,因此第一个结点最重要,一般称为头结点。 -
虚拟结点
dummyNode,其next指针指向head,也就是dummyNode.next=head。
因此,如果使用了虚拟结点,若要获得head结点,或者从方法里返回的时候,则应使用dummyNode.next。
另外注意,dummyNode的val不会被使用,初始化为0或者-1等都是可以的。简单来说,虚拟结点就是为了方便我们处理首部结点,否则我们需要在代码里单独处理。在链表反转里,我们可以看到该方式大大降低解题难度。
3 创建链表
根据面向对象的理论,在Java里规范的链表应该按如下方式定义:
public class ListNode {
private int data;
private ListNode next;
public ListNode(int data) {
this.data = data;
}
public int getData() {
return data;
}
public ListNode getNext() {
return next;
}
public void setNext(ListNode next) {
this.next = next;
}
public void setData(int data) {
this.data = data;
}
}
在LeetCode中算法题经常用这种方式创建:
public class Node {
public int val;
public Node next;
public Node(int x) {
val = x;
//这个一般作用不大,写了会更加规范
next = null;
}
}
Node node = new Node(1);
val就是当前结点的值,next指向下一个结点。两个变量都是public的,所以创建对象后能直接使用listnode.val和listnode.next来操作,虽然违背了面向对象的设计要求,但是代码更为精简,因此在算法题中应用广泛。
4 链表的增删改查
4.1 遍历链表
对于单链表,不管进行什么操作,一定是从头开始逐个向后访问,所以操作之后是否还能找到表头非常重要。(我的理解:如下,遍历时,表头node对象传入形参head,head的引用指向了表头位置,然后node的引用指向的是当前遍历到的位置,在循环遍历中不断变化指向下一个结点)
public static int getListLength(Node head) {
int length = 0;
Node node = head;
while(node != null) {
length++;
node = node.next;
}
return length;
}
4.2 链表插入
-
1. 表头插入
创建新结点newNode,执行newNode.next=head即可,再让head重新指向新的表头head=newNode。
如图,头结点初始是1,最终是new。
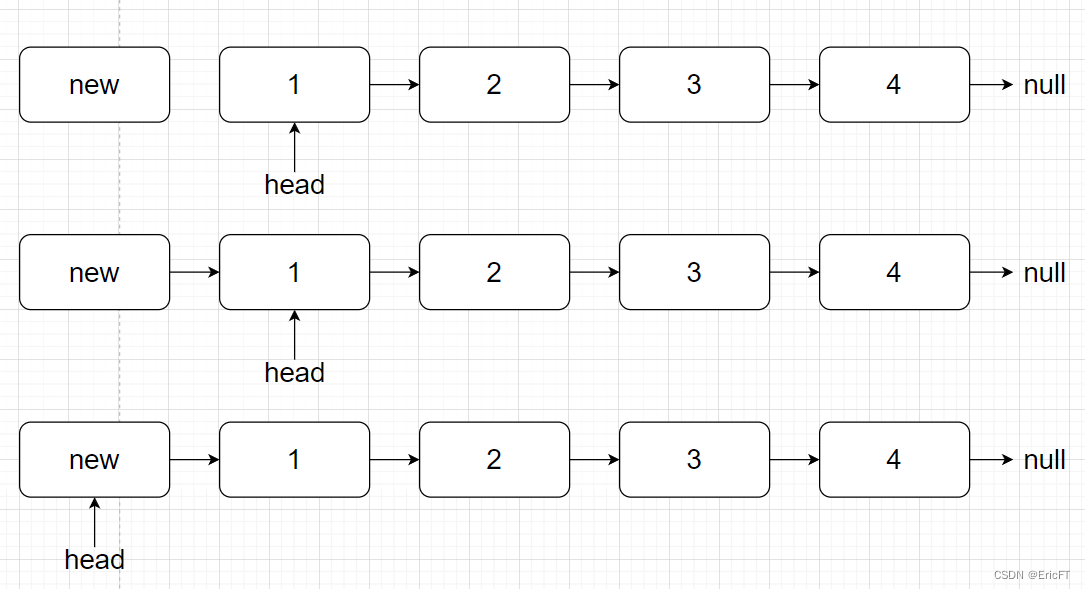
-
2. 结尾插入
将尾节点指向新结点即可。
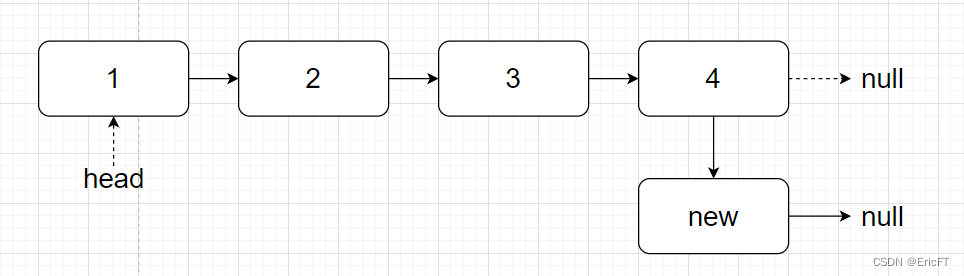
-
3. 中间插入
首先要遍历找到要插入的位置。然后,如图,如果要在2和3之间插入,必须先让new.next=node(2).next,再将node(2).next=new。即使用current.next的值,而不是next,如下:new.next = current.next; current.next = new;
顺序不能颠倒!!! 因为每个结点只有一个next,如果先让current.next = new,那么2和3之间的连线就会自动断开,就无法找到原来的后继结点了

代码如下:
/**
* 链表插入
* @param head 链表头结点
* @param nodeInsert 待插入结点
* @param position 待插入位置,从1开始
* @return 插入后得到的链表头结点
*/
public static Node insertNode(Node head, Node nodeInsert, int position) {
//先判断头结点是否为空
if (head == null) {
//可以认为待插入的结点就是链表的头结点,也可以抛出不能插入的异常,推荐前者
return nodeInsert;
}
//判断插入的位置
int size = getLength(head);//得到目前已经存放的元素个数
if (position > size + 1 || position < 1) { //注意size+1位置其实就是最后一个结点的下一个位置就是新的尾部。
System.out.println("位置参数越界");
return head;
}
//表头插入
if (position == 1) {
nodeInsert.next = head;
//下面也可以简化直接 return nodeInsert;
head = nodeInsert;
return head;
}
//其他
Node pNode = head;
int count = 1; //记录遍历到的元素的位置,和pNode相匹配
while (count < position -1) { //在目前结点位置的前一个即position-1的地方停下来
pNode = pNode.next;
count++;
}
nodeInsert.next = pNode.next;
pNode.next = nodeInsert;
return head;
}
写代码的时候其实中间和结尾的插入都写在同一类步骤里了,因为尾部插入,目标位置就是size+1的位置,前一位就是原来的尾部,所以相当于把待插入的node的下一位next指向null,然后将原来的尾部的下一位指向待插入的node,和中间插入是一个道理。
4.3 链表删除
-
1. 删除表头结点
head = head.next

-
2. 删除最后结点
找到最后结点的前一个位置,current.next = null,此时结点4变得不可达,最终会被JVM回收

-
3. 删除中间结点
找到要删除结点的前一个位置,将current.next = current.next.next
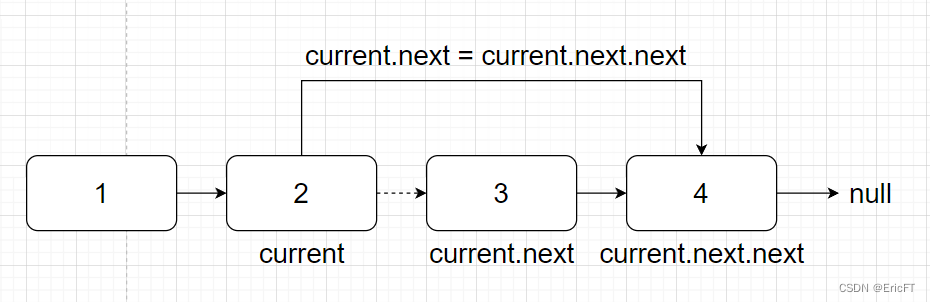
代码如下:
/**
* 链表删除结点
*
* @param head 链表头结点
* @param position 删除节点位置,从1开始
* @return 删除后的链表头结点
*/
public static Node deleteNode(Node head, int position) {
if (head == null) {
return null;
}
int size = getLength(head);
if (position > size || position < 1) {//因为是要删除的结点位置,必须是已有的位置里找
System.out.println("输入的位置参数有误");
return head;
}
//删除表头
if (position == 1) {
head = head.next;
return head;
}
//中间与尾部
Node curNode = head;
int count = 1;
while (count < position - 1) {
curNode = curNode.next;
count++;
}
curNode.next = curNode.next.next;
return head;
}
课后总结
今天学习了数据结构与算法最基本的知识,如时间复杂度空间复杂度等,记录在了前一篇笔记中。然后开始学算法村第一关——链表,知晓了java中链表的概念,以及链表创建、遍历、插入、删除等。
今天是写算法的第一篇笔记,我把算法村课件里的部分内容也码在笔记里了,感觉有点冗长,单纯的重复码下课件里的一些内容也有些浪费时间,之后准备简化笔记,只把最关键的几个知识点和代码以及自己的理解写在笔记里,比较细节的内容直接去算法村的课件里看。
完成了青铜挑战,再接再厉!
















 325
325











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











