






1、XML
-
XML(EXtensible Markup Language),可拓展标记语言,以前叫GML
-
XML与HTML的对比
-
XML主要是来描述数据
-
HTML主要是来展现数据
-
XML的文档声明若存在则必须放在第一行,描述了XML版本和编码格式
-
空格和换行在Java中没关系,但是在XML中会被当做内容进行处理,但是现在大部分第三方封装好的解析工具类中会自动忽略
-
xml中会有很多头部文件,其实是一堆协议和名字空间引入。
-
xmlns:xmlNameSpace,即名称空间
-
1.1、作用
-
数据传输,不同语言不同机器都可互相传输
-
配置文件
-
数据存储,但存储量尽量少些
1.2、元素(标签、节点)
即XML中的标记,也被称为标签、节点
-
不能以数字或部分标点符号开头
-
不能包含空格和特定的几个符号
-
标签必须成对出现,不允许缺省结束标签
-
根元素有且只有一个,必须包含根元素,即</>
-
大小写敏感
-
允许多层嵌套但是不允许交叉嵌套
1.3、属性
-
属性是写在标签中的信息,属性值用双引号或单引号引起来,遵循外双内单(推荐),也可以是外单内双,多个属性使用 空格 分开,例如使用id进行唯一
-
现在大多使用 子标签 来描述数据,因为子标签还可以有子标签,更具有层次
1.4、实体
-
大多数特殊字符不能直接写在XML文件中,比如:<、>、&等
-
一般使用实体来代替特殊字符,当然也可以自定义
| 字符 | 实体 |
|---|---|
| < | |
| > | |
| & | |
| ' | |
| " |
<!DOCTYPE 根元素名称[ <!ENTITY 实体名 实体内容> ]> <!-- 使用的时候 --> <name>&company;</name>
1.5、注释
<!-- 这就是注释 -->
1.5.1、使用注释时需注意的点
-
注释内容中不要出现 --
-
不要把注释放在标签中间
-
注释不能嵌套
1.6、CDATA
XML解析器,会解析XML文档中所有的文本,当某个XML元素被解析时,其标签之间的文本也会被解析
-
解析器进行解析的内容,称为PCDATA(Parsed CDATA)
-
解析器不会解析的内容,称为CDATA(Character Data)
<![CDATA[在这里放需要原样输出的东西]]>
1.7、XML约束
使用dtd文件或schema文件对XML文件内容进行约束
1.7.1、良构、有效
-
良构:一个XML文件的内容若满足基本语法要求,那么此XML是良构的
-
有效:在良构基础上,若此XML文件还通过dtd或schema的约束验证,那么此XML是有效的
1.7.2、DTD
DTD(Document Type Define),dtd文件中描述并规定了元素、属性和其他内容在xml文档中的使用规则,DTD文件的后缀名为 .dtd
1.7.2.1、dtd描述元素(标签)
<!ELEMENT 元素名 内容模式>
-
内容模式有(4选1):
-
EMPTY:元素不能包含子元素和文本(即为空元素)
-
(#PCDATA):可以包含任何字符数据,但是不能在其中包含任何子元素
-
ANY:元素内容为任意的,主要是使用在元素内容不确定的情况下
-
修饰符:() | + * ? , 修饰符可以使用多个,只要不出现冲突
-
(): 用来给元素分用组
-
| :在列出的元素中选择一个
-
+:表示该元素最少出现一次,可以出现多次 (1或n次)
-
*:表示该元素允许出现零次到任意多次(0到n次)
-
?:表示该元素可以出现,但只能出现一次 (0到1次)
-
,:对象必须按指定的顺序出现
-
1.7.2.2、dtd描述属性
<!ATTLIST 元素名 属性名 属性类型 属性特点>
-
属性类型:
-
CDATA:属性值可以是任何字符(包括数字和中文)
-
ID:属性值必须唯一,属性值必须满足xml命名规则,只能是字符
-
IDREF:属性的值指向文档中其它地方声明的ID类型的值。
-
IDREFS:同IDREF,但是可以具有由空格分开的多个引用。
-
(枚举值1|枚举值2|枚举值3...):属性值必须在枚举值中
-
属性特点:
-
#REQUIRED:元素的所有示例都必须有该属性
-
#IMPLIED :该属性可以不出现
-
default-value:该属性可以不出现,但是会有默认值
-
#FIXED:属性可以不出现,但是如果出现的话必须是指定的属性值
1.7.3、引入 .dtd 文件
1.7.3.1、内部dtd(不常用)
dtd与xml在同一个文件中,元素名是什么,就代表作用在这个节点的内部
<!DOCTYPE 节点名[ <!ENTITY company "杰普软件科技有限公司"> <!ELEMENT students (student+)> ]>
1.7.3.2、外部dtd(常用)
-
本地dtd文件引入,不用些<!DOCUMENT 节点名[这些,只需要些<!ELEMENT 、<!ATTLIST这些就可以了
-
引用的时候<!DOCTYPE employees SYSTEM "employee.dtd">路径是相对于本文件的包目录下
-
公共dtd文件引入
<!DOCTYPE hibernate-configuration PUBLIC "-//Hibernate/Hibernate Configuration DTD 3.0//EN" "http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
-
Eclipse默认会根据第一个双引号中的内容,查找对应的DTD所在位置
-
如果有DTD文件,那么就读取并验证,同时可以根据DTD的内容给出自动提示的信息(Alt+/)
-
如果没有DTD文件,那么就根据第二个双引号中的内容(URL地址),去网络中下载并读取、验证
1.8、XML解析,使用JAXP、DOM4j
DOM4j和DOM都具有节点树结构,DOM4j集中了DOM和SAX的优点
1.8.1、DOM解析
-
DOM(Document Object Model)文档对象模型,是 W3C 组织推荐的处理 XML 的一种方式。
-
使用DOM方式解析,要求解析器把整个XML文档装载到一个Document对象中。Document对象包含文档元素,即根元素,根元素包含N个子元素
-
DOM适用于XML文档不大的情况,因为需要先将整个XML加载到内存
-
特点
-
加载XML全部内容
-
生成Document对象
-
所有标签元素对象都在Document对象中获取
-
DOM使用步骤:
-
创建DOM工厂类对象DocumentBuilderFactory.newInstance()
-
通过DOM工厂类对象创建DOM解析器对象.newDocumentBuilder(),得到DocumentBuilder对象
-
通过DOM解析器对象创建xml文件解析对象.parse(File对象或路径),进行解析xml文件,得到Document对象
-
通过xml文件解析对象获取所有的student节点对象,.getElementsByTagName("student"),得到NodeList对象
-
遍历student节点对象,并将节点对象中的子节点的文本给Student对象进行赋值,最后存入List集合
-
常用方法:nodelist.item(i)、element.getAttribute("id")、element.getChildNodes()、node.getNodeType()、Node.TEXT_NODE、Node.ELEMENT_NODE、node.getNodeName()、node.getFirstChild().getNodeValue()
try {
// 1、创建DOM工厂类对象
DocumentBuilderFactory domFactory = DocumentBuilderFactory.newInstance();
// 2、创建DOM解析器对象
DocumentBuilder dom = domFactory.newDocumentBuilder();
// 3、调用解析方法,解析xml文件
// File file = new File("src/jaxp/students.xml");//也可以直接传一个file
Document xmlDocument = dom.parse("src/jaxp/students.xml");
// 4、获取所有student节点对象
NodeList studentNodes = xmlDocument.getElementsByTagName("student");
List<Student> students = new ArrayList<Student>();
// 5、去遍历每一个student节点,取出每个student节点中的子节点及内容
for (int i = 0; i < studentNodes.getLength(); i++) {
Student student = new Student();
// 通过下标获取Element
Element node = (Element) studentNodes.item(i);
// 获取该节点属性内容
int id = Integer.parseInt(node.getAttribute("id"));
student.setId(id);
student.setMoney(Integer.parseInt(node.getAttribute("money")));
// 通过节点对象获取所有子节点对象
NodeList childNodes = node.getChildNodes();
for (int j = 0; j < childNodes.getLength(); j++) {
// 获取当前节点类型,去除文本内容
Node item = childNodes.item(j);
// 判断节点类型是否为元素节点,还有Node.TEXT_NODE,文本节点内容
if (item.getNodeType() == Node.ELEMENT_NODE) {
// 获取该节点名字
String nodeName = item.getNodeName();
// 获取文本内容
String nodeValue = item.getFirstChild().getNodeValue();
switch (nodeName) {
case "name":
student.setName(nodeValue);
break;
case "age":
student.setAge(Integer.parseInt(nodeValue));
break;
case "gender":
student.setGender(nodeValue);
break;
case "hobby":
student.setHobby(nodeValue);
break;
default:
break;
}
}
}
students.add(student); //将赋值完的student加入集合
}
students.forEach(System.out::println);
}
1.8.2、SAX解析
-
SAX,(Simple API for XML)它不是W3C标准,但它是 XML 社区事实上的标准,因为使用率也比较高
-
使用SAX方式解析,每当读取一个开始标签、结束标签或者文本内容的时候,都会调用我们重写的一个指定方法,该方法中编写当前需要完成的解析操作
-
直到XML文档读取结束,在整个过程中,SAX解析方法不会在内存中保存节点的信息和关系。
-
使用SAX解析方式,不会占用大量内存来保存XML文档数据和关系,效率高。
-
但是在解析过程中,不会保存节点信息和关系,并且只能从前往后,顺序读取、解析
-
SAX适用于数据量大的时候,因为读到哪解析到哪
-
特点
-
一次读取一个标签,读取到一个标签就开始解析,不会保存节点信息
-
读取到开始标签、文本内容、结束标签都会自动调用对应方法
-
5个常用SAX事件
-
startDocument(),解析器发现了文档的开始标签 ,会自动调用该方法
-
startElement(),解析器发 现 了一个起始标签,会自动调用该方法
-
character(),解析器发 现 了标签 里 面的文本值,会自动调用该方法
-
endElement(),解析器发 现 了一个结束标签,会自动调用该方法
-
endDocument(),解析器发 现 了文档结束标签,会自动调用该方法
-
SAX使用步骤:
-
创建SAX工厂类对象SAXParserFactory.newInstance()
-
通过SAX工厂类对象创建SAX解析器对象.newSAXParser(),得到SAXParser对象
-
创建一个StudentHandler类去继承DefaultHandler,重写父类的五个方法,然后创建出该类的实例对象,最好在StudentHandler创建能遍历输出List集合的方法,也可以把这块写在endDocument中
-
通过SAX解析器对象使用.parse(File对象或路径, DefaultHandler对象)进行解析xml文件,这个过程中会自动调用我们的StudentHandler中重写的方法
public class StudentSAX {
public static void main(String[] args) {
try {
// 1、创建SAX工厂类对象
SAXParserFactory saxFactory = SAXParserFactory.newInstance();
// 2、获取SAX解析器对象
SAXParser sax = saxFactory.newSAXParser();
// 3、调用解析方法,解析xml文件
StudentHandler handler = new StudentHandler();
sax.parse("src/jaxp/students.xml", handler);
handler.getList().forEach(System.out::println);
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
class StudentHandler extends DefaultHandler {
private List<Student> students = null;
private Student student = null;
private String tagName = null;// 当前标签名
// 开始文档解析
@Override
public void startDocument() throws SAXException {
students = new ArrayList<Student>();
}
// 读取开始元素(开始标签)
// uri:文件路径,localName:命名空间,qName:开始标签名,attributes:开始标签的属性
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
if ("student".equals(qName)) {
student = new Student();
student.setId(Integer.parseInt(attributes.getValue("id")));
student.setMoney(Integer.parseInt(attributes.getValue("money")));
} else {
tagName = qName;
}
}
// 读取文本内容
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
String content = new String(ch, start, length);
content.trim();// 去除前后空格
if ("name".equals(tagName)) {
student.setName(content);
} else if ("age".equals(tagName)) {
student.setAge(Integer.parseInt(content));
} else if ("gender".equals(tagName)) {
student.setGender(content);
} else if ("hobby".equals(tagName)) {
student.setHobby(content);
}
}
// 读取结束元素(结束标签)
// uri:文件路径,localName:命名空间,qName:结束标签名
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
tagName = null;
if ("student".equals(qName)) {
students.add(student);
}
}
@Override
public void endDocument() throws SAXException {
super.endDocument();
}
public List<Student> getList() {
return students;
}
}
1.8.3、DOM4j
-
DOM4j需要使用jar包,它是一个十分优秀的Java XML API,具有性能优异、功能强大和极其易使用的特点,且开源免费
-
集合了DOM、SAX的优点,使用了节点树结构
1.8.3.1、DOM4j读取xml文件
-
使用DOM4j读取xml文件的使用步骤
-
创建SAXReader对象new SAXReader()
-
使用SAXReader对象解析xml文件.read(File对象或路径),得到Document对象
-
通过Document对象获取根节点.getRootElement(),得到Element对象
-
通过根节点获取所有子节点集合.elements(),得到List<Element>对象
-
遍历子节点集合,获取属性集合.attributes()、属性的值.getValue()、子节点集合.elements()、子节点的文本内容.getText(),把这些给Teacher对象赋值后加入到List集合中
try {
// 1、创建解析器对象
SAXReader saxReader = new SAXReader();
// 2、解析xml文件
Document document = saxReader.read("src/jaxp/teachers.xml");
// 3、获取根节点
Element rootElement = document.getRootElement();
// System.out.println(rootElement.getName());
// 4、通过根节点获取其所有子节点集合
List<Element> elements = rootElement.elements();
List<Teacher> teachers = new ArrayList<Teacher>();
// 5、遍历子节点集合
for (Element element : elements) {
Teacher teacher = new Teacher();
// 获取teacher的属性集合
List<Attribute> attributes = element.attributes();
// 循环teacher的属性
for (Attribute attribute : attributes) {
teacher.setId(Integer.parseInt(attribute.getValue()));
}
// 获取teacher的子节点
for (Element e : element.elements()) {
switch (e.getName()) {
case "name":
teacher.setName(e.getText());
break;
case "age":
teacher.setAge(Integer.parseInt(e.getTextTrim()));
break;
case "salary":
teacher.setSalary(Double.parseDouble(e.getTextTrim()));
break;
default:
break;
}
}
teachers.add(teacher);
}
teachers.forEach(System.out::println);
}
1.8.3.2、DOM4j创建并写xml文件
-
使用DOM4j创建并写xml文件的使用步骤
-
得到你想要写入的数据,例如List集合
-
创建Document对象DocumentHelper.createDocument()
-
通过Document对象给Document对象添加节点document.addElement("teas"),因为是第一个也就是根节点了,得到Element对象
-
循环你要添加的子节点个数,也可以遍历List,然会通过根节点来给根节点添加子节点.addElement("tea"),得到Element对象
-
再通过子节点来给子节点添加属性.addAttribute("id", String.valueOf(teacher.getId()))
-
再通过子节点给子节点添加子节点,得到Element对象
-
然后再通过子节点的子节点来添加文本内容.addText(String.valueOf(teacher.getId()))
-
通过以上步骤的Document就被添加完成了,可以通过XMLWriter对象来写入(write),创建XMLWriter对象,要给输出流、Format作参数
XMLWriter xmlWriter = new XMLWriter(new FileOutputStream("src/jaxp/teas.xml"),
OutputFormat.createPrettyPrint());
List<Teacher> teachers = new ArrayList<Teacher>();
teachers.add(new Teacher(1, "潘广闯", 18, 100000));
teachers.add(new Teacher(2, "孙江宝", 18, 80000));
teachers.add(new Teacher(3, "崔略", 18, 120000));
// 1、创建document对象
Document document = DocumentHelper.createDocument();
Element teas = document.addElement("teas");
for (Teacher teacher : teachers) {
//给子节点添加属性
Element tea = teas.addElement("tea");
tea.addAttribute("id", String.valueOf(teacher.getId()));
//给子节点添加id子节点
Element id = tea.addElement("id");
id.addText(String.valueOf(teacher.getId())); // 或者teacher.getId()+""
Element name = tea.addElement("name");
name.addText(teacher.getName());
Element age = tea.addElement("age");
age.addText(String.valueOf(teacher.getAge()));
Element salary = tea.addElement("salary");
salary.addText(String.valueOf(teacher.getSalary()));
}
try {
XMLWriter xmlWriter = new XMLWriter(
new FileOutputStream("src/jaxp/teas.xml"),
OutputFormat.createPrettyPrint());
xmlWriter.write(document); //将Document对象写入
xmlWriter.flush();
xmlWriter.close();
}
3、JDBC
3.1、Junit
JUnit,是一个Java语言的单元测试框架,用于编写和运行可重复的测试
3.1.1、Junit5的三个模块
JUnit5 与以前版本的 JUnit 不同,拆分成由三个不同子项目的几个不同模块组成:
-
JUnit Platform: 用于JVM上启动测试框架的基础服务,提供命令行,IDE和构建工具等方式执行测试的支持
-
JUnit Jupiter:包含 JUnit 5 新的编程模型和扩展模型,主要就是用于编写测试代码和扩展代码
-
JUnit Vintage:用于在JUnit 5 中兼容运行 JUnit3.x 和 JUnit4.x 的测试用例

3.1.2、导入Junit5
3.1.2.1、eclipse
右键项目名 -> build path -> add libraries -> Junit5 -> finish
3.1.2.2、maven
<!-- 核心功能的依赖 --> <dependency> <groupId>org.junit.jupiter</groupId> <artifactId>junit-jupiter-engine</artifactId> <version>5.5.2</version> <scope>test</scope> </dependency> <!-- 参数化测试功能的依赖 --> <dependency> <groupId>org.junit.jupiter</groupId> <artifactId>junit-jupiter-params</artifactId> <version>5.5.2</version> <scope>test</scope> </dependency>
3.1.2、使用Junit5
@DisplayName 用于标注测试类和测试方法的名字 @Test 用于标注这个方法是测试方法 @BeforeAll 在所有测试方法开始之前,执行一次(静态方法) @AfterAll 在所有测试方法结束之后,执行一次(静态方法) @BeforeEach 在每一个测试方法,执行开始之前,都会执行(非静态方法) @AfterEach 在每一个测试方法,执行结束之后,都会执行(非静态方法) @Disabled 注解,那么在运行这个测试类的时候,该方法会被忽略 去掉 @Test ,而使用 @RepeatedTest 注解,则表示该方法要重复测试 @RepeatedTest 注解内,可以使用以下几个变量: currentRepetition ,表示已经重复的次数 totalRepetitions ,表示总共要重复的次数 displayName ,表示测试方法显示名称 使用@ValueSource 配合 @ParameterizedTest 注解,可以表示当前测试方法,需要进行传参测试 @ValueSource 支持 Java 的基本类型、字符串,Class,使用时参数以数组方式传递 @ParameterizedTest 替代 @Test 注解,任何一个参数化测试方法都需要标记上该注解
@DisplayName("单元测试类")
public class JunitTest {
@BeforeAll
public static void init() {
System.out.println("初始化数据");
}
@AfterAll
public static void cleanUp() {
System.out.println("清理数据");
}
@BeforeEach
public void methoedStart() {
System.out.println("当前测试方法开始");
}
@AfterEach
public void methoedEnd() {
System.out.println("当前测试方法结束");
}
@DisplayName("测试1")
@RepeatedTest(value = 3, name = "{displayName} 的第 {currentRepetition} 次测试")
void test1() {
System.out.println(" 测试1执行");
}
@DisplayName("测试2")
@Test
void test2() {
System.out.println(" 测试2执行");
}
@ParameterizedTest
@ValueSource(strings = { "tom", "mary", "poly" })
void test3(String name) {
System.out.println(" hello!" + name);
}
}
3.2、JDBC
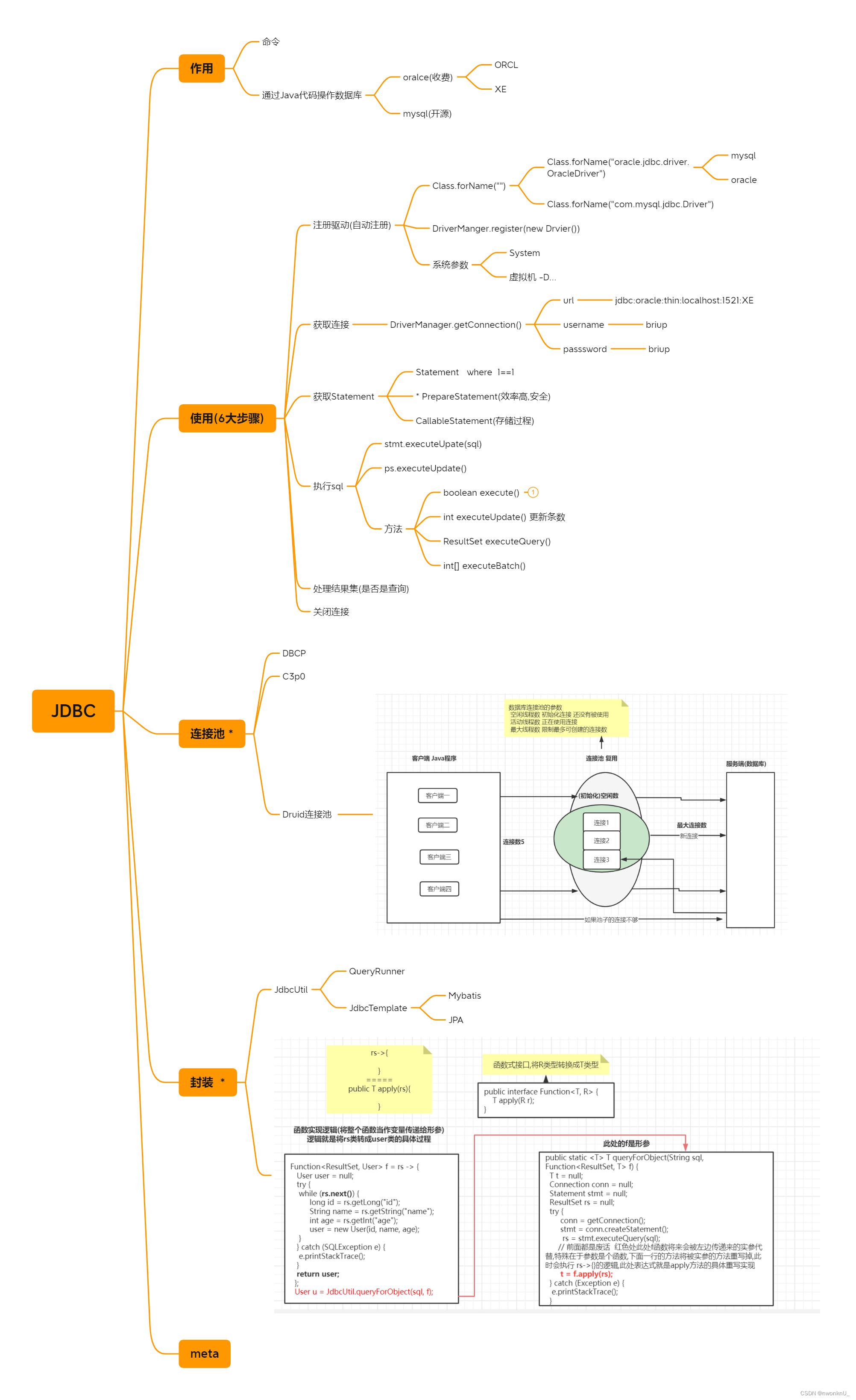
-
JDBC(Java DataBase Connectivity)Java数据库连接(技术),也就是能够通过java代码,连接到数据库,并可以使用SQL语句,对数据库进行各种操作
-
即把Java代码中的SQL语句送进数据库
-
JDBC ,是一种技术规范,它制定了程序中连接不同数据库的标准API
-
JDBC就相当于Java版本的ODBC
-
JDBC就是Java与数据库的接口(标准),即API
-
程序员使用Sun公司实现的JDBC和jar包,让JDBC连接、操作数据库
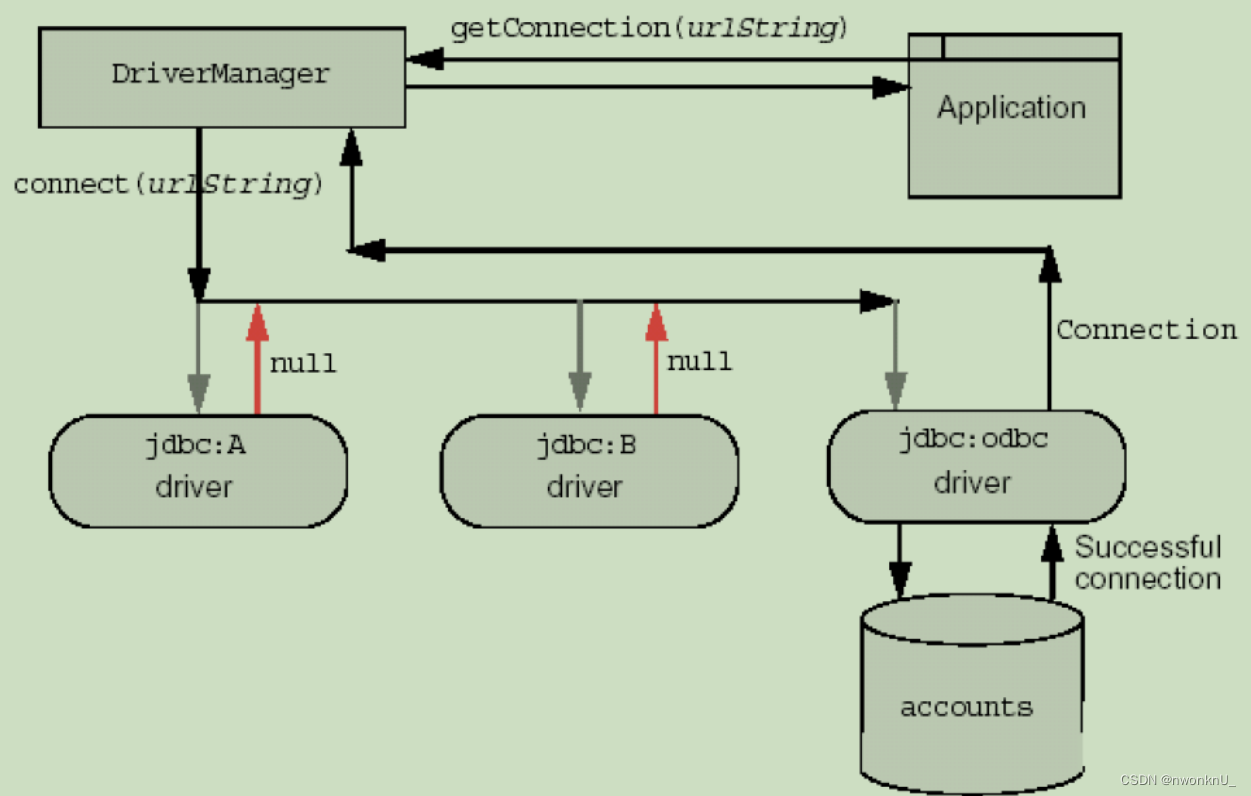
3.2.1、历史版本ODBC
最早连接数据库的标准还有 ODBC(Open Database Connectivity),开放式数据库连接。使用C语言实现。
它提供了一套连接并操作数据库的API接口,使得程序员可以使用同一套标准的代码,去访问不同数据库,而不需要改变代码。
ODBC提供了一套用来访问数据库的标准API,同时提供了驱动管理器,允许第三方开发驱动程序连接特定的数据库,并将驱动注册到驱动管理器里面
3.2.2、驱动
-
JDBC-ODBC桥 此类驱动程序将JDBC调用转换成ODBC调用 , 然后使用一个ODBC驱动程序与数据库进行通信
早期Java包含了驱动程序: sun.jdbc.odbc.JdbcOdbcDriver。但是使用之前需要对ODBC数据源进行配置。JDK1.8不再提供JDBC/ODBC桥的支持
-
本地API驱动 用来和数据库的客户端API进行通信。
使用前,需要安装Java类库和一些平台相关的代码(特定的驱动程序,类似ODBC)
通过驱动程序的转换,把Java程序中使用的JDBC API转换成NativeAPI,进而存取数据库
-
网络协议驱动 使用与具体数据库无关的协议,将数据库请求发送给服务器中间件。
中间件服务器,再将数据库请求翻译成符合数据库规范的调用,再把这种调用传给数据库服务器。
由于在交互中间多了一层中间件,所以执行效率较低。
-
本地协议驱动 将JDBC请求直接转换成符合相关数据库系统规范的请求。
可以直接和数据库通信,这种类型的驱动完全由Java实现,因此实现了平台独立性。
执行效率相对于其他三种类型,不需要将jdbc调用转换成odbc/本地数据库接口/中间层服务器,效率高。我们常用的驱动方式,也是第四类驱动
3.2.3、连接
在使用JDBC操作数据库之前,需要先获取到数据库的连接对象,而获取连接对象之前,需要先注册驱动到驱动管理器中,而注册驱动之前,需要先加载驱动类到内存中
-
加载驱动类
-
将驱动类注册到驱动管理器中(可以自动完成),加载后自动完成注册
-
通过驱动管理器获取数据库连接对象
3.2.3.1、加载驱动类
java.sql.Driver:是JDBC中提供的驱动接口,每一种数据库的驱动类都要实现这个接口。
java.sql.DriverManager:是JDBC中提供的驱动管理器(类),注册驱动后,可通过它获取到数据库连接对象
3.2.3.1.1、加载驱动类的三种方式
每开个Driver都会开个JVM
public class JDBCDriverTest {
@DisplayName("加载驱动类方法1")
@Test
public void test1() {
String driverClass = "oracle.jdbc.driver.OracleDriver";
try {
Class.forName(driverClass);
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
@DisplayName("加载驱动类方法2")
@Test
public void test2() {
// 创建出驱动对象
Driver driver = new oracle.jdbc.driver.OracleDriver();
}
@DisplayName("加载驱动类方法3")
@Test
public void test3() {
// 设置环境变量
// jdbc.drivers=oracle.jdbc.driver.OracleDriver
// java -Djdbc.drivers=oracle.jdbc.driver.OracleDriver com.chw.test.Hello
// 驱动管理器会自动加载该驱动类
System.setProperty("jdbc.drivers", "oracle.jdbc.driver.OracleDriver");
System.out.println(System.getProperty("jdbc.drivers"));
}
}
-
其中,第三种方式,还可以在运行java程序的时候,通过给JVM传参的方式进行设置: Eclipse中选择Window=>Preferences=>Java=>Installed JRES=>选中安装的jdk或者jre并进行编辑=>在Default VM Arguments中输入需要设置的jvm参数=>点击Finish完成设置。
-Djdbc.drivers=oracle.jdbc.driver.OracleDriver
-
还可以在代码中右键=>run configurations=>VM arguments进行设置
3.2.3.1.2、注册驱动的三种方式
-
Class.forName("驱动全限定名");
-
DriverManager.registerDriver(驱动实例)
-
使用jdbc.drivers 选项来指定,在运行程序时,使用-D选项,如: java -Djdbc.drivers=oracle.jdbc.driver.OracleDriver
3.2.3.2、获取连接
-
获取数据库连接对象,需要三个参数:
-
url,需要连接的数据库地址
-
user,登录数据库的用户名
-
password,登录数据库的密码 这是Oracle本地协议
String url = "jdbc:oracle:thin:@127.0.0.1:1521:ORCL";
thin 是oracle的一种连接方式 后边必须有数据库所在主机的IP和PORT
XE表示连接的oracle数据库的名字
3.2.3.2.1、获取数据库连接对象的种方式
//第一种
Class.forName(driverClass); // 静态代码块中做了装载,以及自动加载
Connection conn = DriverManager.getConnection(url, user, password);
//第二种
OracleDriver driver = new OracleDriver();
//通过上面的OracleDriver类的反编译源码可知,我们不手动注册的话,它也会自动注册的
DriverManager.deregisterDriver(driver);
conn = DriverManager.getConnection(url,user,password);
//第三种
System.setProperty("jdbc.drivers","oracle.jdbc.driver.OracleDriver");
Connection conn = DriverManager.getConnection(url,user,password);
//第四种,在没有主动加载或配置驱动类的情况下,也可以获取oracle数据库的连接对象,
//那是因为在当前使用的驱动包中,已经默认配置了需要加载的驱动类
//就在oracle的jar包的这个目录下:/META-INF/services/java.sql.Driver
Connection conn = DriverManager.getConnection(url,user,password);
3.2.3.3、获取properties配置文件内容
Properties pro = new Properties();
pro.load(new FileInputStream("src/oracle.properties"));
driverClass = pro.getProperty("driverClass");
url = pro.getProperty("url");
user = pro.getProperty("user");
password = pro.getProperty("password");
3.2.3.4、使用DOM4j从xml文件中获取Connection
public class DOM4jConnectionTest {
private static String driverClass;
private static String url;
private static String user;
private static String password;
Connection conn = null;
@Test
public void connectionByDOM4j() {
try {
new SAXReader()
.read("src/com/chw/jdbc/oracle.xml")
.getRootElement()
.elements()
.forEach((e) -> {
switch (e.getName()) {
case "driverClass":
driverClass = e.getText();
break;
case "url":
url = e.getText();
break;
case "user":
user = e.getText();
break;
case "password":
password = e.getText();
break;
default:
break;
}
});
Class.forName(driverClass);
conn = DriverManager.getConnection(url, user, password);
} catch (Exception e) {
e.printStackTrace();
}
}
}
3.2.3.5、使用src目录寻找文件的缺点
-
如果将来项目成型打包,最终变成jar/war,就没有src目录了,文件就找不到了
-
最好通过此方法: Properties properties = new Properties();
InputStream inputStream =
当前类名.class.getClassLoader().getResourceAsStream("文件名");
properties .load(inputStream);
3.2.4、JDBC的六大步骤
-
注册驱动(自动)Class.forName(driverClass); 一般程序员加载驱动类Class.forName(driverClass)后就自动注册
-
获取数据库连接Connection conn = DriverManager.getConnection(url, user, password);
-
创建 Statement类型或子类型
-
执行sql语句
-
处理结果集(一般查询语句才需要处理)
-
关闭资源
3.2.5、Statement
-
用于执行静态 SQL 语句并返回它所生成结果的对象
-
在默认情况下,同一时间每个 Statement 对象只能打开一个 ResultSet 对象。
-
因此,如果读取一个 ResultSet 对象与读取另一个交叉,则这两个对象必须是由不同的 Statement 对象生成的
-
如果有多条sql语句要执行,他们的格式相同,只是要操作的数据不同,那么可以称他们为同构的sql语句,Statement处理大量的同构的SQL语句没PreparedStatement快
-
在Statement的SQL语句中想放入自定义的字符串对象,要 '"+nowStr+"'
-
Java的Statement都有默认的自动提交事务conn.setAutoCommit(false);可以取消自动提交事务,
-
自动提交事务是在conn关闭的时候自动提交的

3.2.5.1、常用方法
java.sql.ResultSet接口,专门用来表示select查询语句返回的结果集,表示当前sql的查询结果
-
boolean execute(String sql) throws SQLException 执行sql,返回boolean类型数据
true表示返回结果是一个ResultSet
false表示返回结果是一个数据更新的条数或者没有返回结果
-
int executeUpdate(String sql) throws SQLException 执行sql,返回int类型数据
返回0,表示没有结果返回
返回其他数字,表示操作数据的条数
-
ResultSet executeQuery(String sql) throws SQLException 执行sql,返回ResultSet 类型结果
一般查询语句使用该方法,可以返回结果集ResultSet ,然后再遍历结果集,拿到每条数据
-
int[] executeBatch() throws SQLException 执行批处理操作,返回每条sql命令的执行结果,放到int数组中
数组中每个数字对应一条命令影响的行数,但是在Oracle的驱动中没有实现该功能,即插入数据SQL命令提交成功后不会返回影响的行数,则返回-2
3.2.5.2、PreparedStatement(Statement的子接口)
-
表示预编译的 SQL 语句的对象
-
PreparedStatement执行大量同构SQL语句时才明显快 简称PS,它除了拥有Statement 的功能特点之外,它还有有着自己的特
点:可以对sql语句进行预处理
Statement,是每次执行一个sql语句,就要把一个完整的sql语句发送给数据库进行执行,然后取回返回的结果。
PreparedStatement,可以把一个sql语句的结构,提前发送给数据库进行预处理,然后在专门给发送要操作的具体的值,在数据量大的时候,这种方式会大大提高执行效率
使用批处理,在set完后直接addBatch方法就可以,最后executeUpdate
3.2.5.2.1、PreparedStatement的优点
-
使用 Statement,每次都需要,使用字符串拼接出一个完整的sql语句,再发送给数据库,如果sql语句比较复杂,需要拼接的数据比较多,那么在字符串拼接过程中,就很容易出错误。
-
Statement传输Date类型的数据很麻烦,需要to_date函数
-
使用 PreparedStatement,就不需要拼接字符串,因为只需要先把带占位符的sql发给数据库,之后在专门发送数据,代替占位符就可以了,这里基本不会出现在sql中拼接字符串的情况
3.2.5.3、CallableStatement(PreparedStatement的子接口)
-
用于执行 SQL 存储过程的接口 简称CS,它除了拥有 俩个父接口 的功能特点之外,它还有有着自己的特
点:可以调用数据库中的存储过程
3.2.5.3.1、在数据库中创建存储过程
-
先有t_user表
create table t_user( id number primary key, name varchar2(100), salary number );
-
在数据库中创建存储过程
create or replace procedure insert_user_procedure (id in number, name in varchar2,salary in number,result out varchar2) is begin insert into t_user values(id,name,salary); result:='调用存储过程成功'; Exception when others then result:= '调用存储过程出错: ' || SQLERRM; end; /
-
参数列表中的in代表输入参数,out代表返回值
-
SQLERRM表示执行sql时候出现的错误信息(sql-error-message)
-
sql中的字符串拼接使用双竖杠(||)
-
JDBC中使用CS(CallableStatement)调用存储过程
public class CSTest {
private String driverClass = "oracle.jdbc.driver.OracleDriver";
private String url = "jdbc:oracle:thin:@127.0.0.1:1521:XE";
private String user = "chw";
private String password = "chw";
@Test
public void cs() {
Connection conn = null;
CallableStatement cs = null;
try {
//1.加载注册驱动
Class.forName(driverClass);
//2.获取连接对象
conn = DriverManager.getConnection(url,user,password);
//3.获取cs对象
cs = conn.prepareCall("{call insert_user_procedure(?,?,?,?)}");
cs.setObject(1, 1);
cs.setObject(2, "tom1");
cs.setObject(3, 4500);
cs.registerOutParameter(4, java.sql.Types.VARCHAR);
//4.执行存储过程
cs.execute();
//5.处理结果
//获取第四个参数的值,也就是返回结果
Object result = cs.getObject(4);
System.out.println("result = "+result);
} catch (Exception e) {
e.printStackTrace();
} finally {
//把资源关掉
}
}
}
3.2.5.4、Statement与PreparedStatement的区别
-
Statement是每次执行一个sql语句,就要把一个完成的sql语句发送给数据库进行执行,然后取回返回的结果
-
PreparedStatement是预编译的sql语句对象,可以把一个sql语句的结构,提前发送给数据库进行预处理,然后在专门给发送要操作的具体的值。sql语句结构中可以包含动态参数“?”,在执行时可以为“?”动态设置参数值。
-
使用PrepareStatement对象执行sql时,sql被数据库进行解析和编译,然后被放到命令缓冲区,每当执行同一个PreparedStatement对象时,它就会被解析一次,但不会被再次编译。
-
在缓冲区可以发现预编译的命令,并且可以重用。
-
PrepareStatement可以减少编译次数,提高数据库性能
-
但是PrepareStatement的预编译空间有限
-
PrepareStatement可以防止SQL注入,如: or 1=1;
3.2.6、transaction(事务)
-
主要作用就是当事务量很大的时候,你改成手动提交后,就不会执行一条提交一次了,而是全部做完之后统一提交,这样可以提高效率
-
默认情况下,在JDBC中执行的DML语句,所产生的事务,都是自动提交的,也就是,每执行一次DML语句,所产生的事务,就会自动提交,conn关闭的时候也会自动提交
-
手动提交需要在catch的Exception中加入conn.rollback方法,只要出现异常就回滚,最好是只有一个最大的Exception异常
-
conn.setAutoCommit(false);关闭自动提交功能
-
conn.commit();手动提交事务
-
改成手动提交时,finally语句中的 conn.close() 代码,也可以提交事务
-
Savepoint p1 = conn.setSavepoint("p1"); 设置回滚点
3.2.7、连接池(池化技术)
-
池(Pool)技术在一定程度上可以明显优化服务器应用程序的性能,提高程序执行效率和降低系统资源开销
-
数据库连接池是有大小的,即对象有上限
-
例如,数据库连接池,在系统初始化时创建一定数量数据库连接对象Connection,需要时直接从池中取出一个空闲对象,用完后并不直接释放掉对象,而是再放到对象池中,以便下一次对象请求可以直接复用。
-
这样可以消除对象创建和销毁所带来的延迟,从而提高系统的性能
-
在当前数据库环境中,创建出一定数据的数据库连接对象之后,就无法在创建新对象了
-
而数据库连接池,就可以在种情况下,预先创建出一批数据库连接对象,然后对它们进行管理,并反复使用,这样就不需要频繁的销毁和创建了,提供了资源的利用率 Druid连接池是阿里巴巴开源的数据库连接池项目
-
连接池拿出来的对象的getClass和JDBC的getClass是不同的,因为JDBC获取的连接是Driver的实际连接,而连接池的连接是从连接池获取的空闲连接对象,
-
所以JDBC的关闭资源是真正关闭资源,而连接池的关闭资源是让连接对象返回连接池,变回空闲连接对象 JAVA EE服务器启动时会建立一定数量的池连接,并一直维持不少于此数目的池连接。客户端程序需要连接时,池驱动程序会返回一个未使用的池连接并将其标记为忙。
如果当前没有空闲连接,池驱动程序就新建一定数量的连接,新建连接的数量由配置参数决定。当使用的池连接调用完成后,池驱动程序将此连接表记为空闲,其他调用就可以使用这个连接
3.2.7.1、使用连接池
修改单个文件的编码格式,右键文件,选Properties,改编码格式
javax.sql.DataSource是Java中定义的一个数据源标准的接口,通过它获取到的数据库连接对象,
-
如果调用 close() 方法,不会再关闭连接,而是归还连接到连接池中
Properties properties = new Properties();
InputStream inputStream = DruidTest.class.getClassLoader().getResourceAsStream("druid.properties");
properties.load(inputStream);
Connection conn = DruidDataSourceFactory.createDataSource(properties).getConnection();
3.2.7.2、手动配置连接池
public class ConnectionTest {
private String driverClass = "oracle.jdbc.driver.OracleDriver";
private String url = "jdbc:oracle:thin:@127.0.0.1:1521:XE";
private String user = "chw";
private String password = "chw
";
// 手动设置属性,创建连接池对象
@Test
public void test_druid() {
// 创建数据库连接池
DruidDataSource dataSource = new DruidDataSource();
dataSource.setDriverClassName(driverClass);
dataSource.setUrl(url);
dataSource.setUsername(user);
dataSource.setPassword(password);
// 设置创建连接池时创建多少个连接
dataSource.setInitialSize(5);
// 设置最大连接数,当从连接池里面获取的连接超过了5个会继续创建,超过了10个就需要等待
dataSource.setMaxActive(10);
Connection conn = null;
// 获取连接
try {
conn = dataSource.getConnection();
} catch (SQLException e) {
e.printStackTrace();
}finally {
if(conn!=null) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(dataSource!=null) {
dataSource.close();
}
}
}
}
3.2.8、封装
-
封装就是我们帮用户把需要的功能用方法封装起来,让用户只需要使用方法即可完成业务
-
所有的变量或方法都是static的
3.2.8.1、封装连接池
-
在static代码块中封装properties.load(通过当前类的类加载器获取指定文件名的资源)
-
再将全局静态变量DataSource通过装载好的properties创建出来DruidDataSourceFactory.createDataSource(properties)
static {
try {
Properties properties = new Properties();
properties.load(JDBCUtil.class.getClassLoader().getResourceAsStream("druid.properties"));
dataSource = DruidDataSourceFactory.createDataSource(properties);
} catch (Exception e) {
e.printStackTrace();
}
}
3.2.8.2、封装getConnection和close
-
获取数据库连接就是通过连接池获取一个空闲连接对象
-
关闭资源就通过rs,st,conn这个最大的方法进行重载
public static Connection getConnection() throws SQLException {
return dataSource.getConnection();
}
public static void close(ResultSet rs, Statement st, Connection conn) {
if (rs != null) {
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (st != null) {
try {
st.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
3.2.8.3、封装DML语句
-
就接收一个sql字符串,然后正常执行,返回int
-
这里封装的是Statement的方法,如果要封装PreparedStatement的方法,还需要传个集合或可变参数进来
public static int executeDML(String sql) {
int rows = 0;
Connection conn = null;
Statement st = null;
try {
conn = getConnection();
st = conn.createStatement();
rows = st.executeUpdate(sql);
} catch (SQLException e) {
e.printStackTrace();
} finally {
close(st, conn);
}
return rows;
}
3.2.8.3、封装DDL语句
-
就接收一个sql字符串,然后正常执行
-
因为DDL与DML执行方法一致,所以可以交给DML去做
public static void executeDDL(String sql) {
executeDML(sql);
}
3.2.8.4、封装DQL语句
-
因为是DQL语句,所以有返回值,且返回值要么是一个实体类对象,要么是多个实体类对象
-
但是为了通配各种实体对象,我们不可以指定方法的返回类型,所以就需要使用泛型
3.2.8.4.1、使用Function函数式接口将多个返回结果封装成List集合
-
我们可以将得到的ResultSet封装成List集合,但是我们并不知道我们要取的列名叫什么,也不知道该列名的数据类型
-
所以我们要使用Function这个函数式接口,传进去ResultSet对象,返回T(泛型)对象
-
我们负责从数据库拿到数据集,我们也帮忙循环rs.next,但是具体要取什么类型的什么名字的数据需要用户来做
public static <T> List<T> executeDQLforList(
String sql, Function<ResultSet, T> f) {
List<T> list = new ArrayList<T>();
Connection conn = null;
Statement st = null;
ResultSet rs = null;
try {
conn = getConnection();
st = conn.createStatement();
rs = st.executeQuery(sql);
while (rs.next()) {
list.add(f.apply(rs));
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
close(st, conn);
}
return list;
}
// 使用
@Test
void test_DQLforList1() {
String sql = "select id,name,age from t_user";
List<User> users = JDBCUtil.executeDQLforList(sql, rs -> {
User obj = null;
try {
obj = new User(rs.getLong("id"), rs.getString("name"), rs.getInt("age"));
} catch (SQLException e) {
e.printStackTrace();
}
return obj;
});
users.forEach(System.out::println);
}
3.2.8.4.2、使用Function函数式接口将返回结果封装,并作情况判断
-
在返回List集合的基础上进行判断List的size是否大于1个,因为我们要的是单个返回结果,若大于1个就抛出异常,
-
因为若我们不去判断,size为0的时候我们取拿就会报下标越界异常
public static <T> List<T> executeDQLforObject(
List<T> list = executeDQLforList(sql, f);
if (list.size() > 1) {
throw new Exception("查询结果数量过多,有" + list.size() + "条,与期望不符!");
}
return list.size() > 0 ? list.get(0) : null;
}
// 使用
@Test
void test_DQLforObject() {
String sql = "select id,name,age from t_user where id=1";
User user = null;
try {
user = JDBCUtil.executeDQLforObject(sql, rs -> {
User obj = null;
try {
obj = new User(rs.getLong("id"), rs.getString("name"), rs.getInt("age"));
} catch (SQLException e) {
e.printStackTrace();
}
return obj;
});
} catch (Exception e) {
e.printStackTrace();
System.out.println(e.getMessage());
}
System.out.println(user);
}
3.2.8.4.3、使用反射将返回结果封装成List集合
-
这个不需要用户去取什么类型的数据什么的,用户也不需要实现Function这个函数式接口的方法,用户只需要传sql和想要封装成的class类型
-
我们通过反射,把用户给的class类型进行解析,实体类中需要什么类型的数据我们就用rs去取
-
我们要解决的问题是:需要通过用户给的class类型知道字段名、字段类型,需要将获取到的值封装到泛型对象中
public static <T> List<T> executeDQLforList(String sql, Class<T> c) {
T obj = null; //将来要将数据库的值封装到该泛型对象中
List<T> list = new ArrayList<T>(); //将每个封装好的obj加进来,最后返回
// Map用来接收用户给的Class类型c的属性名和属性类型
// key是类中的属性名,value是类中的属性类型
// parseClass是我们自己写的方法,使用反射机制解析Class的所有属性
Map<String, String> map = parseClass(c);
// sql=generateSQL(map); //我们可以再定义一个根据map创建SQL语句的方法,就不需要用户提供sql语句了
Connection conn = null;
Statement st = null;
ResultSet rs = null;
try {
conn = getConnection();
st = conn.createStatement();
rs = st.executeQuery(sql);
while (rs.next()) {
obj = c.newInstance(); //让泛型对象得到指定类型的实例对象
// attributeName就是map中的key,属性名
// attributeType就是map中的value,属性值
for (String attributeName : map.keySet()) {
String attributeType = map.get(attributeName);
Object value = null; //用一个Object来获取任何的属性值
switch (attributeType) {
case "int":
value = rs.getInt(attributeName);
break;
case "long":
value = rs.getLong(attributeName);
break;
case "String":
value = rs.getString(attributeName);
break;
default:
break;
}
// 将值封装到泛型对象中,obj是引用类型,所以传的是引用
setValue(obj, attributeName, value);
}
list.add(obj); // 将对象封装到list中
}
} catch (Exception e) {
e.printStackTrace();
} finally {
close(st, conn);
}
return list;
}
/**
* 使用反射的方式,将值设置到对象的属性中
*
* @param obj 目标对象
* @param attrName 属性名
* @param value 属性值
*/
private static void setValue(Object obj, String attrName, Object value)
throws IllegalArgumentException, IllegalAccessException, NoSuchFieldException, SecurityException {
Class<?> c = obj.getClass(); //不指定类型,也可以不写<?>
// 开始反射解析
Field declaredField = c.getDeclaredField(attrName);
declaredField.setAccessible(true);
declaredField.set(obj, value);
}
// 使用反射,解析指定类型,获取该类型的属性名字和属性类型
private static Map<String, String> parseClass(Class<?> c) {
Map<String, String> map = new HashMap<String, String>();
Field[] declaredFields = c.getDeclaredFields();
for (Field field : declaredFields) {
String fieldName = field.getName();
String fieldType = field.getType().getSimpleName();
map.put(fieldName, fieldType);
}
return map;
}
3.2.8.4.4、使用反射将返回结果封装
public static <T> T executeDQLforObject(String sql, Class<T> c) throws Exception {
List<T> list = executeDQLforList(sql, c);
if (list.size() > 1) {
throw new Exception("查询结果数量过多,有" + list.size() + "条,与期望不符!");
}
return list.size() > 0 ? list.get(0) : null;
}
3.2.9、MetaData(获取数据库的所有信息)
-
元数据(MetaData),即定义数据的数据 使用jdbc,可以查询到数据库中,指定表中的数据,与此同时,还可以获取到数据库本身的信息、表本身的信息、结果集本身的信息,这些都需用到MetaData:java.sql.DatabaseMetaData、java.sql.ResultSetMetaData
3.2.9.1、数据库中的 schema 与 catalog
-
按照SQL标准的解释,在SQL环境下Catalog和Schema都属于抽象概念,主要用来解决命名冲突问题。
-
就比如JVM解决命名冲突是ClassLoader+包+类名,这也解释了不同的ClassLoader装载同一个类也会产生两个不同的对象 从概念上说,一个数据库系统包含多个Catalog,每个Catalog又包含多个Schema,而每个Schema又包含多个数据库对象(表、视图、序列等)
| 数据库 | Catalog | Schema |
|---|---|---|
| Oracle | 不支持 | 用户名 |
| MySQL | 不支持 | 数据库名 |
3.2.9.2、Oracle删除表后产生的BIN开头的垃圾信息
3.2.9.2.1、查询垃圾信息
select object_name
from user_objects
where object_type = upper('table');
3.2.9.2.2、清除垃圾信息
purge recyclebin;
3.2.9.3、使用MetaData
3.2.9.3.1、通过DatabaseMetaData获取数据库的信息
Connection conn = JdbcUtils.getConnection(); //DatabaseMetaData实例的获取 DatabaseMetaData metaData = conn.getMetaData(); //获得数据库的名字 System.out.println(metaData.getDatabaseProductName()); //获得数据库的版本 System.out.println(metaData.getDatabaseProductVersion()); //获得数据库的主版本 System.out.println(metaData.getDatabaseMajorVersion()); //获得数据库的小版本 System.out.println(metaData.getDatabaseMinorVersion());
3.2.9.3.2、通过DatabaseMetaData获取数据库中,指定用户下的,所有表的名字
Connection conn = JdbcUtils.getConnection();
//DatabaseMetaData实例的获取
DatabaseMetaData metaData = conn.getMetaData();
//获得数据库中表的信息,null代表不指定表名,就是全都要
// metaData.getTables(catalog, schema, tableName, types);
rs = metaData.getTables(null, "chw", null, new String[]{"TABLE"});
while(rs.next()){
String tableName = rs.getString("TABLE_NAME");//表名
String typeName = rs.getString("TABLE_TYPE");//表的类型名称,table、view等
System.out.println(tableName+" : "+typeName);
}
3.2.9.3.3、通过DatabaseMetaData获取数据库中指定用户下,指定表的,列的信息
Connection conn = JdbcUtils.getConnection();
//DatabaseMetaData实例的获取
DatabaseMetaData metaData = conn.getMetaData();
//获得表中列的信息
// metaData.getColumns(catalog, schema, tableName, columnName)
// rs = metaData.getColumns(null, "chw", "T_USER", "ID");
rs = metaData.getColumns(null, "chw", "T_USER", null);
while(rs.next()){
String colName = rs.getString("COLUMN_NAME");//列名
String typeName = rs.getString("TYPE_NAME");//类型名称
System.out.println(colName+" : "+typeName);
}
3.2.9.3.4、通过ResultSetMetaData获取查询结集中,列的数量,每列的类型和名字
Connection conn = JDBCUtil.getConnection();
Statement st = conn.createStatement();
String sql = "select id myid,name,age from t_user where id=1";
ResultSet rs = st.executeQuery(sql);
ResultSetMetaData metaData = rs.getMetaData();
// 返回RusultSet结果中的列的数量
int columnNum = metaData.getColumnCount();
System.out.println("查询结果中的列数为: " + columnNum);
for (int i = 1; i <= columnNum; i++) {
// 返回列序号为 i 的数据类型
// 可以获取到别名
String columnType = metaData.getColumnTypeName(i);
// 返回此列的列名(字段名)
String columnName = metaData.getColumnName(i);
System.out.println(columnType + " : " + columnName);
}
3.2.10、由指定用户的指定表生成实体类
-
想通过Oracle数据库中指定用户的指定表生成对应实体类,那用户必须要传的参数有:schema,即用户名、tableName,即表名、packageName,即想要生成在本项目下的什么路径下
3.2.10.1、生成步骤
-
解析指定的表,得到表中的 字段名、字段对应的类型,这个信息一看就得存在Map集合中,所以这个方法需要返回一个Map集合,map1
-
记得要把用户给我们的schema和tableName变成大写
-
我们得到了数据表的字段和字段类型,我们就需要通过map1来得到实体类对应的属性名、属性类型的集合,map2
-
值得注意的是,数据库中的数据类型名字与Java中的不一样,所以我们需要一个映射表,这个表肯定是Map集合,typeMapping,并且为了让这个集合一开始就能使用,我们把它放在static代码块中,并且记得把数据库的字段类型名变成大写
-
现在我们已经得到了实体类的属性名和属性类型,我们现在需要的就是该实体类的类名,这个通过表名就可以得到,规则自定
-
还需要得到这个实体类该放置的路径,我们可以通过System.Properties得到这个项目的工作路径,这个路径是绝对路径,然后再通过用户给的packageName和你自己设置的类名,就可以得到绝对路径
-
Windows中的路径有两种方式:src\com\和src/com,第一种是默认
-
但是在Java中\是转义符,所以我们想通过拼接得到绝对路径,就会使用到分隔符,你要么把所有的\变成一个/,要么就使用4个\\来把得到路径中的一个\变成2个\,因为你是使用Java的流来写入的,四个\只是因为Java中的\路径需要用\来表示,然后你赋值的时候就需要用4个\
-
我们已经得到了要写的属性名和属性值,得到了要写的路径,还差要写的内容
-
package部分,将用户给的packageName放进去
-
import部分(可以没有)
-
class声明部分
-
class正文——属性部分
-
class正文——getter、setter部分
-
将得到的内容写入到指定文件下
3.2.10.2、代码
public class GenerateClassUtil {
// typeMapping中保存数据库中类型和Java中类型的映射关系
private static Map<String, String> typeMapping;
static {
typeMapping = new HashMap<String, String>();
typeMapping.put("NUMBER", "int");
typeMapping.put("VARCHAR2", "String");
typeMapping.put("VARCHAR", "String");
}
public static void generateClass(String schema, String tableName, String packageName) {
// 1、解析指定表,得到表中的 字段、字段类型类型 的信息 map1
Map<String, String> map1 = parseTable(schema, tableName);
// 2、将map1转换为map2,map2中是要生成类中的 属性、属性类型 的信息
Map<String, String> map2 = transformFieldInfo(map1);
// 3、将表名转换为要生成的类名
String clasaName = transformClassName(tableName);
// 4、获取要生成的Java文件所在的路径
String javaFilePath = getJavaFilePath(packageName, clasaName);
// 5、生成Java文件中要写入的内容 (String)
String javaFileContent = generateJavaFileContent(packageName, clasaName, map2);
// 6、把5中生成的内容写入到4中获取的Java文件中
writeJavaFile(javaFileContent, javaFilePath);
System.out.println("表" + tableName + "对应的实体类,已经自动生成!");
}
private static void writeJavaFile(String javaFileContent, String javaFilePath) {
FileWriter out = null;
File file = new File(javaFilePath);
// 如果Java文件所在目录不存在,就创建
if (!file.getParentFile().exists()) {
file.getParentFile().mkdirs();
}
try {
out = new FileWriter(file);
out.write(javaFileContent);
out.flush();
} catch (Exception e) {
e.printStackTrace();
} finally {
if (out != null) {
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
private static String generateJavaFileContent(String packageName, String clasaName, Map<String, String> map2) {
StringBuilder sb = new StringBuilder();
// package部分
sb.append("package " + packageName + ";").append("\n");
sb.append("\n");
// import部分
// class声明开始
sb.append("public class " + clasaName + "{").append("\n");
// class正文-属性部分
for (String attributeName : map2.keySet()) {
String attributeType = map2.get(attributeName);
sb.append("\t").append("private " + attributeType + " " + attributeName + ";").append("\n");
}
sb.append("\n");
// class正文-方法部分
for (String attributeName : map2.keySet()) {
String attributeType = map2.get(attributeName);
// getter
sb.append("\t").append("public " + attributeType + " get" + initCap(attributeName) + "(){").append("\n");
sb.append("\t\t").append("return " + attributeName + ";").append("\n");
sb.append("\t").append("}");
// setter
sb.append("\t").append(
"public void set" + initCap(attributeName) + "(" + attributeType + " " + attributeName + "){")
.append("\n");
sb.append("\t\t").append("this." + attributeName + " = " + attributeName + ";").append("\n");
sb.append("\t").append("}");
}
sb.append("\n");
// class声明结束
sb.append("}").append("\n");
return sb.toString();
}
private static String getJavaFilePath(String packageName, String className) {
// com.chw.pojo
// com/chw/pojo
// src/com/chw/pojo
// D:\SpringToolSuiteWorkPlace\jd2107test01\src\com\chw\pojo\xxx.java
String basePath = System.getProperty("user.dir"); // 项目路径
String separator = System.getProperty("file.separator"); // 分隔符
String packagePath = null;
// 把点变成路径分隔符
// "\\"是一个\的意思,因为\是转义符
if ("\\".equals(separator)) {
// 我们要两个\\,所以需要转义两个\,就是\\\\
// 即变成 src\\chw这种样子,因为Java中的\是转义符
// 直接一个点在λ表达式和其他地方有特殊含义,所以要用空括号引起来
packagePath = packageName.replaceAll("[.]", "\\\\");
} else {
packagePath = packageName.replaceAll("[.]", "/");
}
// 拼成绝对路径
String javaFilePath = basePath + separator + "src" + separator + packagePath + separator + className + ".java";
return javaFilePath;
}
private static String transformClassName(String tableName) {
// t_user ---> T_user
return tableName.substring(0, 1).toUpperCase() + tableName.substring(1).toLowerCase();
}
private static Map<String, String> transformFieldInfo(Map<String, String> map1) {
Map<String, String> map2 = new HashMap<String, String>();
// map1 ID NUMBER
// map2 id int
for (String colName : map1.keySet()) {
String colType = map1.get(colName);
String javaFieldName = colName.toLowerCase();
String javaTypeName = typeMapping.get(colType);
map2.put(javaFieldName, javaTypeName);
}
return map2;
}
private static Map<String, String> parseTable(String schema, String tableName) {
Map<String, String> map1 = new HashMap<String, String>();
Connection conn = null;
ResultSet rs = null;
try {
conn = JDBCUtil.getConnection();
DatabaseMetaData metaData = conn.getMetaData();
rs = metaData.getColumns(null, schema.toUpperCase(), tableName.toUpperCase(), null);
while (rs.next()) {
String colName = rs.getString("COLUMN_NAME");
String typeName = rs.getString("TYPE_NAME");
map1.put(colName, typeName);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
JDBCUtil.close(rs, conn);
}
return map1;
}
private static String initCap(String name) {
return name.substring(0, 1).toUpperCase() + name.substring(1).toLowerCase();
}
}
4、SVN(不重要,没有git好用)
-
Subversion(SVN),是一个自由开源的版本控制软件
-
是本地服务器存储,用的不多
-
要下载可以去官方下载,开源的
4.1、安装
安装顺序:VisualSVN Server -> TortoiseSVN -> LanguagePack -> 在eclipse中安装
即:服务器、客户端、语言包、开发工具安装(去Marketplace或压缩包)
5、Maven
Maven是Apache下的一个开源项目,它是一个创新的项目管理工具,它用于对Java项目进行项目构建、依赖管理及项目信息管理。(开源、免费、Java语言实现)
pom.xml结构:
<dependencies><dependency>
<build><plugins><plugin>
5.1、基础设置
5.1.1、作用
5.1.1.1、项目构建
是指一个项目清理、编译、测试、报告、打包、安装、部署等过程,Maven中把这些过程进行了标准化管理,可以通过一个命令,自动按照顺序,依次执行这里面的每一个步骤
-
清理clean:将之前编译得到的旧文件class字节码文件删除
-
编译compile:将java源程序编译成class字节码文件
-
测试test:自动测试,自动调用junit程序
-
报告report:测试程序执行的结果
-
打包package:动态Web工程打War包,java工程打jar包6.
-
安装install:Maven特定的概念,将打包得到的文件复制到maven仓库中的指定位置
-
部署deploy:将工程生成的结果放到服务器中或者容器中,使其可以运行
5.1.1.2、依赖管理
-
是指Maven将项目中所依赖的外部jar包,进行统一的管理
-
它会对项目中依赖的jar包自动管理
5.1.2、下载、安装、配置
5.1.2.1、下载
去Maven官网下载
5.1.2.2、安装
找个没文字的文件夹解压就好,最好只有一个带版本号的文件夹
5.1.2.3、配置
配置环境变量,可以只配置一个path,也可以配一个home再配一个path
是你的bin目录绝对路径
5.1.2.4、检查
全部做完之后,mvn -v检查是否成功
5.1.3、仓库
5.1.3.1、本地仓库
-
项目中所依赖的第三方jar,最终都会下载存放到自己电脑中的本地仓库中,本地仓库的位置可以自己指定,也可以使用默认路径: ${user.home}/.m2/repository
-
项目是先去找本地是否有jar,没有的话才会去中央仓库下载
5.1.3.2、中央仓库
-
这是Maven官方提供的远程仓库,仓库中存放了,日常项目中所会使用到的几乎所有jar包,当我们自己电脑中的本地仓库中,没有要依赖的jar的时候,Maven默认会从中央仓库中查找并下载需要的jar包
-
但是速度特别慢,因为是在国外
5.1.3.3、私有仓库
-
私有仓库,也称为私服,一般是由公司自己设立的,只为本公司内部共享使用
-
可以使用 Nexus软件工具,来搭建局域网中的私有的远程仓库,也就是私服,我们使用的阿里云镜像就用了nexus
5.1.3.4、仓库配置
-
maven会先找 ${user.home}/.m2/settings.xml ,如果找不到,会再找安装目录的\conf\settings.xml
-
因为默认情况下,本地仓库的位置是:${user.home}/.m2/repository ,如果想修改这个地址,可以在maven的配置文件中,进行配置
-
当然也可以把本地仓库分出来,方便管理,分出来的时候记得修改安装目录中的conf的setting.xml,
<localRepository>D:\apache-maven-3.6.3-bin\MavenRepo</localRepository>
-
配置路径为新的仓库路径和阿里云镜像,然后复制一份setting.xml到新的仓库中
<mirror> <id>nexus-aliyun</id> <!-- <mirrorOf>*</mirrorOf> --> <mirrorOf>central</mirrorOf> <name>aliyun maven</name> <url>http://maven.aliyun.com/nexus/content/groups/public/</url> </mirror>
5.1.4、坐标
在maven中,每一个项目都有三个坐标(GAV),用来唯一标识这个项目
-
groupId ,该元素定义当前Maven项目隶属的实际项目, 一般用的名字:公司或者组织域名倒序+项目名
-
artifactId ,该元素定义当前maven项目表示的具体子项目(模块) 一般用的名字:模块名
-
version ,该元素定义当前maven项目的具体版本 一般用的名字:版本
5.1.4.1、依赖引入
-
<dependency> 标签表示依赖的意思
-
<scope> 是可选的标签,用来指定这个依赖的作用范围,test表示只有在测试的时候才有效
<dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.13</version> <scope>test</scope> </dependency>
5.1.5、目录结构
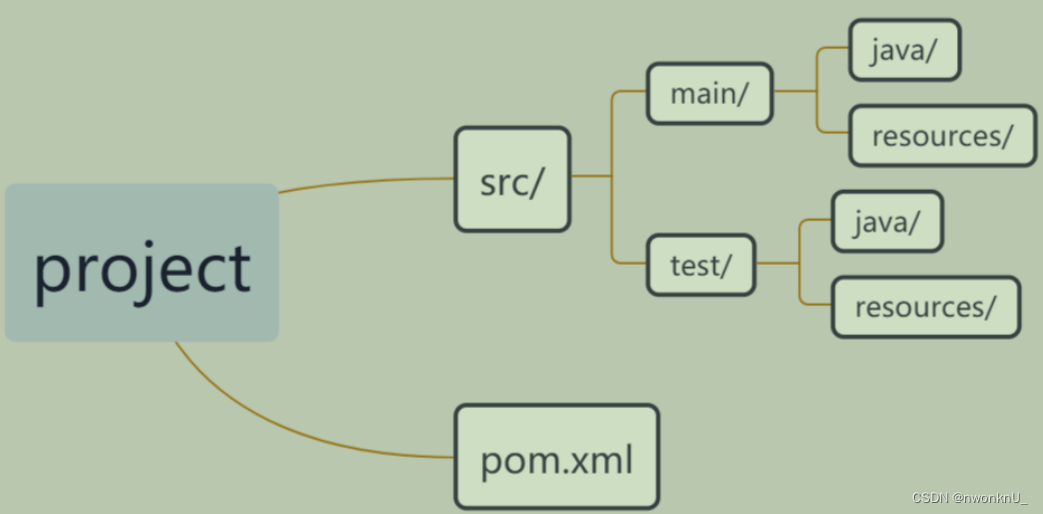
5.1.6、pom.xml的结构
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.chw.invoke</groupId>
<artifactId>demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<hello.version>0.0.1-SNAPSHOT</hello.version>
</properties>
<dependencies>
<dependency>
<groupId>com.chw.demo</groupId>
<artifactId>hello</artifactId>
<version>${hello.version}</version>
</dependency>
</dependencies>
<build>
<!-- 打包后项目的名字,可以使用变量表示 -->
<!-- 项目坐标中的artifactId标签只,就是打包后jar名字 -->
<finalName>${project.artifactId}</finalName>
<!-- 描述项目中资源的位置 -->
<resources>
<!-- 自定义资源,可以有多个 -->
<resource>
<!-- 资源目录 -->
<directory>src/main/resources</directory>
<!-- 包括哪些文件参与打包 -->
<includes>
<include>**/*</include>
</includes>
<!-- 排除哪些文件不参与打包 -->
<excludes>
<exclude>config/*</exclude>
</excludes>
</resource>
</resources>
<!-- 设置构建时候的插件 -->
<plugins>
<!-- 资源编码插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-resources-plugin</artifactId>
<version>3.1.0</version>
<configuration>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<!-- 代码编译插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<!-- 源码打包插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-source-plugin</artifactId>
<version>3.1.0</version>
<executions>
<execution>
<!-- 绑定source插件到Maven的生命周期 (compile) -->
<phase>compile</phase>
<!--在生命周期后执行绑定的source插件的goals(jar-no-fork) -->
<goals>
<goal>jar-no-fork</goal>
</goals>
</execution>
</executions>
</plugin>
<!-- 可执行jar插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.1</version>
<configuration>
<!-- 设置打包时候生成dependency-reduced-pom.xml文件为false -->
<createDependencyReducedPom>false</createDependencyReducedPom>
</configuration>
<executions>
<execution>
<!-- 绑定shade插件到Maven的生命周期 (package) -->
<phase>package</phase>
<!--在生命周期后执行绑定的shade插件的goals -->
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<!--指定程序入口类 -->
<mainClass>com.chw.invoke.Demo</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
5.1.7、target目录
maven在运行(构建)构成中,所产生的文件都会默认存放到target目录
可以使用mvn clean清理掉target文件夹
5.1.8、打包
-
mvn package
-
打包后会将生成的jar存到target目录中,并且打包时默认会执行测试程序
-
打包时,也可以指定参数,跳过测试: mvn package -Dmaven.test.skip=true
-
也可以先清空项目,再打包: mvn clean package
-
也可以先清空项目,再打包,同时跳过测试: mvn clean package -Dmaven.test.skip=true
-
注意,测试代码(test目录)是不会被打入jar包的
5.1.8、install
mvn install
如果maven项目A,想使用maven项目B中的代码,那么就需要将B项目先安装到仓库中,然后项目A通过项目B的坐标,从仓库中找到项目B的jar,并引用到项目A的classpath中,这时候就可以使用了
5.1.9、三种下载jar包的方式
5.1.9.1、直接或间接从中央仓库下载
5.1.9.2、有源码后在项目目录下的cmd中mvn install
5.1.9.3、在有的jar包的目录下cmd执行命令
mvn install:install-file -DgroupId=com.oracle -DartifactId=ojdbc6 -Dversion=6 - Dpackaging=jar -Dfile=ojdbc6.jar -DgeneratePom=true mvn install:install-file -DgroupId=com.oracle -DartifactId=ojdbc7 -Dversion=7 - Dpackaging=jar -Dfile=ojdbc7.jar -DgeneratePom=true mvn install:install-file -DgroupId=com.oracle -DartifactId=ojdbc8 -Dversion=8 - Dpackaging=jar -Dfile=ojdbc8.jar -DgeneratePom=true
5.1.10、compile(编译)
mvn compile 编译主程序(main目录中)
mvn clean test-compile 编译测试程序(test目录中)
5.1.11、scope范围
-
compile ,默认值,适用于所有阶段(开发、测试、部署、运行),jar包会一直存在所有阶段
-
provided ,只在开发、测试阶段使用,目的是不让将来部署的容器和你本地仓库的jar包冲突,因为有些jar包在将来部署的服务器或者容器中是存在的,所以打包的是就不需要把这些jar添加进来了,如servlet相关jar包
-
runtime ,只在运行时使用,如JDBC驱动,适用运行和测试阶段。
-
system ,类似provided,需要显式提供包含依赖的jar的路径,Maven不会在Repository中查找它
-
test ,只在测试时使用,用于编译和运行测试代码。不会随项目发布,如JUnit相关jar包
5.2、在开发工具中使用
5.2.0、pom.xml样例
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.chw.demo</groupId>
<artifactId>jd2107-webtest-01</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>war</packaging>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<!-- 选择让项目使用jdk11 -->
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<!-- 打包后项目的名字,可以使用变量表示 -->
<!-- 项目坐标中的artifactId标签只,就是打包后jar名字 -->
<finalName>${project.artifactId}</finalName>
<!-- 描述项目中资源的位置 -->
<resources>
<!-- 自定义资源,可以有多个自定义资源文件夹 -->
<resource>
<!-- 资源目录 -->
<directory>src/main/resources</directory>
<!-- 包括哪些文件参与打包 -->
<includes>
<!-- **/*代表所有目录的所有子文件都包括 -->
<include>**/*</include>
</includes>
<!-- 排除哪些文件不参与打包 -->
<excludes>
<exclude>config/*</exclude>
</excludes>
</resource>
</resources>
<plugins>
<!-- 可以配置多个插件,要什么自己去找,并且插件会有相关参数 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-war-plugin</artifactId>
<version>3.3.2</version>
<configuration>
<failOnMissingWebXml>false</failOnMissingWebXml>
</configuration>
</plugin>
<!-- 配置tomcat插件,可以不要,因为我们自己有安装tomcat -->
<plugin>
<groupId>org.apache.tomcat.maven</groupId>
<artifactId>tomcat7-maven-plugin</artifactId>
<version>2.2</version>
<configuration>
<!-- 设置web项目的根目录为/ -->
<path>/</path>
<!-- 设置web项目的端口号为8989 -->
<port>8989</port>
<!-- 设置编码为UTF-8 -->
<uriEncoding>UTF-8</uriEncoding>
</configuration>
</plugin>
<!-- 源码打包插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-source-plugin</artifactId>
<version>3.1.0</version>
<executions>
<execution>
<!-- 绑定source插件到Maven的生命周期 (compile) -->
<phase>compile</phase>
<!--在生命周期后执行绑定的source插件的goals(jar-no-fork) -->
<goals>
<goal>jar-no-fork</goal>
</goals>
</execution>
</executions>
</plugin>
<!-- 可执行jar插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.1</version>
<configuration>
<!-- 设置打包时候生成dependency-reduced-pom.xml文件为false -->
<createDependencyReducedPom>false</createDependencyReducedPom>
</configuration>
<executions>
<execution>
<!-- 绑定shade插件到Maven的生命周期 (package) -->
<phase>package</phase>
<!--在生命周期后执行绑定的shade插件的goals -->
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<!--指定程序入口类 -->
<mainClass>com.chw.MainApplication</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
5.2.1、配置maven
在开发工具中使用maven时,要配置关联maven、仓库信息、下载内容信息等
5.2.2、maven项目
File中new一个maven project,环境黄色警告可以自己修改,右键JRE System Library,选其首选项,修改成对应的JRE和JDK即可
5.2.2.1、更新maven项目
Alt+F5,使用Maven中的Update Project
5.2.2.2、maven测试,不是junit测试
右键项目 -> Run As -> Maven test
5.2.2.3、使用maven命令
-
右键项目 -> Run As -> Maven build 写goals类似clean package等
-
在里面输入命令,不需要写mvn,还可以勾选一些方法,比如跳过测试
-
还可以删除历史执行命令:右键项目 -> Run As -> Run Configurations
-
也可以show in -> 想展示的地方
5.2.2.4、在新项目中使用旧maven项目
-
但是容易产生冲突,例如A中引用了junit4,并且依赖范围是可传递的,那么当B引用A并且引用junit5,这样就产生冲突了
-
但是maven会帮我们管理,选择最短路径的依赖
<dependency> <groupId>com.chw.demo</groupId> <artifactId>hello</artifactId> <version>0.0.1-SNAPSHOT</version> </dependency>
5.2.2.5、在properties标签中可以定义变量,然后${变量名}使用
<properties>
<!-- 这三个变量,其实使用让maven默认自带的插件使用的 -->
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<!-- 指定hello项目的版本(变量) -->
<hello.version>0.0.1-SNAPSHOT</hello.version>
</properties>
<dependencies>
<dependency>
<groupId>com.chw.demo</groupId>
<artifactId>hello</artifactId>
<!-- 使用上面定义的变量 -->
<version>${hello.version}</version>
</dependency>
</dependencies>
5.2.2.6、依赖
-
依赖有直接依赖和间接依赖,依赖可以传递
-
在hello项目中,直接依赖了junit-4.13.jar,而junit-4.13.jar又依赖了hamcrest-core-1.3.jar,那么hello项目就间接依赖了hamcrest-core-1.3.jar (依赖传递)
5.2.2.6.1、scope范围及依赖是否传递
-
compile ,默认值,适用于所有阶段(开发、测试、部署、运行),jar包会一直存在所有阶段 会依赖传递
-
provided ,只在开发、测试阶段使用,目的是不让将来部署的容器和你本地仓库的jar包冲突,因为有些jar包在将来部署的服务器或者容器中是存在的,所以打包的是就不需要把这些jar添加进来了,如servlet相关jar包 不会依赖传递
-
runtime ,只在运行时使用,如JDBC驱动,适用运行和测试阶段。 会依赖传递
-
system ,类似provided,需要显式提供包含依赖的jar的路径,Maven不会在Repository中查找它 不会依赖传递
-
test ,只在测试时使用,用于编译和运行测试代码。不会随项目发布,如JUnit相关jar包 不会依赖传递
5.2.2.6.2、依赖排除
<dependency>
<groupId>com.chw.demo</groupId>
<artifactId>hello</artifactId>
<version>${hello.version}</version>
<!-- 排除依赖传递,这里不用指定版本,因为它是确定的 -->
<exclusions>
<exclusion>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
</exclusion>
</exclusions>
</dependency>
5.2.3、maven项目的生命周期
项目在Maven中,有三套相互独立的生命周期,这三套生命周期分别是:
-
Clean Lifecycle,在进行真正的构建之前进行一些清理工作
-
Default Lifecycle,构建的核心部分,编译,测试,打包,测试、安装、部署等等
-
Site Lifecycle,生成项目报告,站点,发布站点
5.2.3.1、phase
这三套生命周期中,又分别包含了若干个阶段(phase),每一个阶段(phase)可以理解为一个步骤,这些步骤按照既定好的顺序执行,从而完成一个项目的构建
-
Clean Lifecycle,分为以下几个阶段(phase)
-
pre-clean 执行一些需要在clean之前完成的工作
-
clean 移除所有上一次构建生成的文件(常用)
-
post-clean 执行一些需要在clean之后立刻完成的工作
-
Default Lifecycle,分为以下几个阶段(phase)
-
validate
-
generate-sources
-
process-sources
-
generate-resources
-
process-resources 复制并处理资源文件,至目标目录,准备打包
-
compile 编译项目的源代码 (常用)
-
process-classes
-
generate-test-sources
-
process-test-sources
-
generate-test-resources
-
process-test-resources 复制并处理资源文件,至目标测试目录
-
test-compile 编译测试源代码 (常用)
-
process-test-classes
-
test 使用合适的单元测试框架运行测试。这些测试代码不会被打包或部署 (常用)
-
prepare-package
-
package 接受编译好的代码,打包成可发布的格式,如 jar war等 (常用)
-
pre-integration-test
-
integration-test
-
post-integration-test
-
verify
-
install 将包安装至本地仓库,以让其它项目依赖。 (常用)
-
deploy
-
Site Lifecycle,分为以下几个阶段(phase)
-
pre-site 执行一些需要在生成站点文档之前完成的工作
-
site 生成项目的站点文档
-
post-site 执行一些需要在生成站点文档之后完成的工作,并且为部署做准备
-
site-deploy 将生成的站点文档部署到特定的服务器上
5.2.3.2、常用命令
-
mvn clean
-
mvn compile
-
mvn test-compile
-
mvn test
-
mvn package
-
mvn install
-
mvn tomcat7:run
-
mvn spring-boot:run
5.2.4、plugin
-
生命周期中,各个步骤/阶段(phase)的工作,是由相应的插件(plugin)来完成的,不同的插件结合起来,就可以完成整个项目的构建
-
一个插件通常完成一个或多个步骤的工作,每个步骤的工作对应插件的一个目标(goal)。
-
默认情况下,我们不需要任何插件配置,Maven中就已经设置好了不同的插件,来处理相应的步骤
-
maven官方插件https://maven.apache.org/plugins/
//tomcat插件 <plugin> <groupId>org.apache.tomcat.maven</groupId> <artifactId>tomcat7-maven-plugin</artifactId> <version>2.2</version> <configuration> <path>/</path> <port>8989</port> <uriEncoding>UTF-8</uriEncoding> </configuration> </plugin>
5.2.5、maven、生命周期(lifecycle)、阶段(phase),插件(plugin)、目标(goal)间的关系
-
一个maven项目有三个生命周期,一个生命周期对应多个阶段,
-
一个插件有一个或多个目标
-
一个目标对应完成一个阶段
5.2.6、build标签
在pom文件中的 <build>标签中,可以配置打包后jar的名字、项目中资源文件的位置、配置构建时候的插件等
5.2.7、继承
-
有jar(通用)、war(web项目)、pom(方便子项目继承)
-
父项目是创建Maven Project,是pom打包方式
-
子项目可以是Maven Project,但如果是Maven Module就一定是子项目,然后就去使用父项目就行,子项目只需要在parent外写 artifactId 这个就行,其他的父项目中都有写,并且使用的时候不需要给版本,只需要使用就行<dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> </dependency> </dependencies>
-
即只需要写groupId和artifactId就行,其余的都使用父项目的
-
也可以直接在父项目中new Maven Module
-
子项目一定是被父项目包含的,就算是新创建Maven Project,看起来是平行目录,但其实是包含关系
-
使用父项目方便管理,父项目只需要一个pom.xml
-
一般打包是去打包父项目,因为父项目中的modules,可以把所有的子项目都一块打包,这个modules是创建子模块的时候自动创建的
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.chw.demo</groupId>
<artifactId>mvn-parent</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>pom</packaging>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<junit.version>4.13</junit.version>
</properties>
<!-- dependencyManagement标签,用来管理依赖,并不是直接给子项目引入 -->
<!-- 子项目中可以自己去引入使用这里管理的依赖,不需要配置版本 -->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
<scope>test</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<finalName>${project.artifactId}</finalName>
<pluginManagement>
<plugins>
</plugins>
</pluginManagement>
</build>
<modules>
<module>mvn-child</module>
</modules>
</project>
5.2.8、聚合
-
聚合项目,一般是将一个项目拆分成多个模块项目,每个模块是一个独立的工程,负责完成一个独立的任务,但是在运行的时候,必须把所有模块项目聚合到一起,才是一个完整的工程
-
先创建一个聚合项目,此项目类似于之前的父项目,打包方式一定要为pom
-
即父项目提供pom,子模块实现独立业务
-
父项目里面有modules,然后父项目需要把各个子项目放到依赖里面,这样就可以实现各个子项目之间的互相引用了
<dependency>
<groupId>com.chw.smart</groupId>
<artifactId>env-gather-entity</artifactId>
<version>${env.gather.version}</version>
</dependency>
<dependency>
<groupId>com.chw.smart</groupId>
<artifactId>env-gather-interface</artifactId>
<version>${env.gather.version}</version>
</dependency>
5.2.9、Working Set
-
用来归类项目的
-
三个竖点,然后点Select Working Set,就可以创建或者选择工作集了
-
三个竖点,然后点Edit Active Working Set,就可以选择什么项目是什么工作集了
5.2.10、自定义Plugin开发(插件)
-
进入maven官网,然后进入Plugin Developer Centre
-
引入接口后,将自己写的代码当作插件
-
写一个Mojo,给他定义目标,然后重写个execute方法
-
我们自定义的插件和官方给的插件的运行方式、打包方式等都有些不一样
-
项目就是一个插件,我们需要修改打包方式,引入依赖后实现目标
-
通过实现别人的接口、使用注解等方法,就能接入别人的体系了
5.2.10.1、开发步骤
-
使用插件的打包方式maven-plugin,如果报错,就选择第二个,忽略,然后它会帮你自动生成一个插件,这个插件是用来配置我们生命周期的映射的,不以为是没用的就直接删掉了
<groupId>com.chw.demo</groupId> <artifactId>jd2107-webtest-01</artifactId> <version>0.0.1-SNAPSHOT</version> <!-- <packaging>war</packaging> --> <packaging>maven-plugin</packaging>
-
复制两个依赖,api、annotations(注解)
<dependency> <groupId>org.apache.maven</groupId> <artifactId>maven-plugin-api</artifactId> <version>3.0</version> <scope>provided</scope> </dependency> <!-- dependencies to annotations --> <dependency> <groupId>org.apache.maven.plugin-tools</groupId> <artifactId>maven-plugin-annotations</artifactId> <version>3.4</version> <scope>provided</scope> </dependency>
-
继承AbstractMojo,使用@Mojo注解,重写execute方法
@Mojo(name = "sayhi")
public class HelloPlugin extends AbstractMojo {
@Override
public void execute() throws MojoExecutionException {
getLog().info("Hello, world.");
}
}
-
引用自定义插件,就在pom文件的插件plugin通过groupId、artifactId、version来引用,但是记住,要加个执行标签,即挂载点,<executions>,里面写阶段和目标,然后<execution>报错的话就选第二个
<build> <plugins> <plugin> <groupId>com.chw.demo</groupId> <artifactId>jd2107-webtest-01</artifactId> <version>0.0.1-SNAPSHOT</version> <executions> <execution> <phase>compile</phase> <goals> <goal>sayhi</goal> </goals> </execution> </executions> </plugin> </plugins> </build>
-
最好把插件下载到本地:右键项目->Run As->Maven install,然后通过5Maven build... goals写上阶段(compile)
-
传参,在插件中加上<configuration>标签,里面写的就算自定义的变量名标签,使用的时候加注解@Parameter
<groupId>com.chw.demo</groupId> <artifactId>jd2107-webtest-01</artifactId> <version>0.0.1-SNAPSHOT</version> <configuration> <name>jack</name> </configuration> <executions><execution><phase>compile</phase><goals> <goal>sayhi</goal></goals></execution></executions>
6、ServerSocket服务器
6.1、使用服务器去关闭另一个服务器
-
新增一个端口,给专门的服务器,让其去监听客户端是否想要关闭服务器
-
这样就会有A服务器专门处理业务,accept阻塞等待客户端的业务调用,B服务器专门监听关闭业务,accept阻塞等待客户端的关闭指令
-
使用服务器去关闭服务器的原因是,你不可能在服务器里面关闭,因为是要客户端说想关了才能关,但你也不可能让客户端去使用服务器的内部细节
-
主要的原因是因为不写死,想关就关
6.2、volatile使用场景
-
使用场景是:两个或多个线程访问同一个堆内变量时
-
堆里的needStop变量,A、B线程都要去访问
-
一般而言,JVM会允许线程复制变量拿到栈里去使用,更高效,但是为了线程同步,我们希望线程每次取变量的时候是去取堆内变量,而不是复制一份到栈中使用,这样的话就不会有B线程改变变量但是A线程仍然不变的情况了
-
volatile可以强制让线程每次都去堆里面拿,以免出错
-
如果使用synchronized的话,这个关键字太霸道了,消耗太大,我们只想要轻量级的volatile
7、Log4j
-
轻量的日志管理框架,4是for的意思
-
开发调试日志、系统运行日志
7.1、级别
-
级别从高到低:OFF、 FATAL、ERROR、WARN、INFO、DEBUG、TRACE、ALL或用户自定义的级别
-
程序会打印高于或等于所 设置级别的日志,设置的日志等级越高,打印出来的日志就越少,修改log4j.properties里面的log4j.rootLogger=debug,contrl,file的debug,改成别的级别
-
当输出低等级的日志时候,相对于此等级的高等级也会全都输出
7.2、log4j对比System.out.println优势
-
分级别控制日志的输出与开关 调试阶段写了100system语句,上线时需不需要这些语句?
(不需要手动删除,自己就能不输出)
-
按不同的类和包进行输出控制 很多模块都有输出语句,但是不能很好区分是哪一个输出?
(不需要区分,可以根据不同的包,不同的类分情况输出)
-
控制日志不同的输出位置
7.3、定义log4j.properties配置文件
-
配置根Logger
-
配置日志信息输出目的地 Appender,Appender 负责控制日志记录操作的输出
-
配置日志信息的格式(布局)Layout,Layout 负责格式化Appender的输出
7.3.1、格式化日志信息
Log4J采用类似C语言中的printf函数的打印格式格式化日志信息,打印参数如下:
-
%m 输出代码中指定的消息
-
%p 输出优先级,即DEBUG,INFO,WARN,ERROR,FATAL
-
%r 输出自应用启动到输出该log信息耗费的毫秒数
-
%c 输出所属的类目,通常就是所在类的全名
-
%t 输出产生该日志事件的线程名
-
%n 输出一个回车换行符,Windows平台为“rn”,Unix平台为“n”
-
%d 输出日志时间点的日期或时间,默认格式为ISO8601,也可以在其后指定格式,比如:%d{yyyy MMM dd HH:mm:ss,SSS},输出类似:2002年10月18日 22:10:28,921
-
%l 输出日志事件的发生位置,包括类目名、发生的线程,以及在代码中的行数。
8、开发中常见的问题
-
修改session、aplication
8.1、日期格式问题
8.1.1、将数据库中的数据在后端转换
8.1.1.1、在jsp页面中使用的方式
-
在实体类中定义getter方法,然后在遍历对象的时候使用这个方法得到时间
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss");
String date = sdf.format(mydate);
-
使用jstl的 fmt 标签库,
<%@ taglib uri="http://java.sun.com/jsp/jstl/fmt" prefix="f"%>
<li>出版时间:<f:formatDate value="${book.pubDate}"
pattern="yyyy-MM-dd" /></li>
-
8.2、表单提交问题
8.2.1、表单提交方式
-
input普通方式
-
onclick方式,方便添加样式
<script type="text/javascript">
function submitForm() {
document.getElementById("addCar").submit();
}
</script>
<div class="pro_addshop" οnclick="submitForm()">加入购物车</div>
-
href方式,方便添加样式
<div class="pro_addshop"> <a href="javascript:submitForm()">加入购物车</a> </div>


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









