







前端点滴(JS核心)(四)----倾尽所有
一、正则表达式(上)
1. 前言
正则表达式基础:https://blog.csdn.net/Errrl/article/details/103880657
2. 匹配模式
参考blog:https://blog.csdn.net/weixin_42516949/article/details/80858913
// 贪婪: 尽可能多的匹配
// 非贪婪: 尽可能少的匹配
// 语法:将?紧跟在任何量词 *、 +、? 或 {} 的后面,将会使量词变为非贪婪的(匹配尽量少的字符),和缺省使用的贪婪模式(匹配尽可能多的字符)正好相反。
//不加问号默认为贪婪
var reg = /a.*c/
var string = 'aaaccaa'
var result = string.match(reg)
console.log(result) //=> ["aaacc"]
//加上问号为非贪婪
var reg = /a.*?c/
var string = 'aaaccaa'
var result = string.match(reg)
console.log(result) //=> ["aaac"]
3. 正则表达式分组/捕获和反向引用
捕获和反向引用的语法的解释:
正则中出现的小括号,就叫捕获或者分组
在正则语法中(在/…/内),在捕获的后面,用 “\1” 来引用前面的捕获。用 “\2” 表示第二个捕获的内容….
注意: 在正则语法外(如replace时),用 “$1” 来引用前面的捕获。
<script>
var str = '1122 3434 5678 9090 1516';
// 要求:匹配连续四个数字
// var res = str.match(/\d{4}/g);
// var res = str.match(/[0-9]{4}/g);
// var res = str.match(/\d\d\d\d/g);
// 捕获与引用
// 要求:匹配连续四个数字。要求1,3相同
// var res = str.match(/(\d)\d\1\d/g);
// 要求:匹配连续四个数字。要求1,3相同;2,4相同
// var res = str.match(/(\d)(\d)\1\2/g);
// 要求:匹配连续四个数字。要求1,2相同;3,4相同
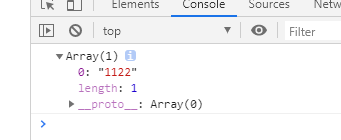
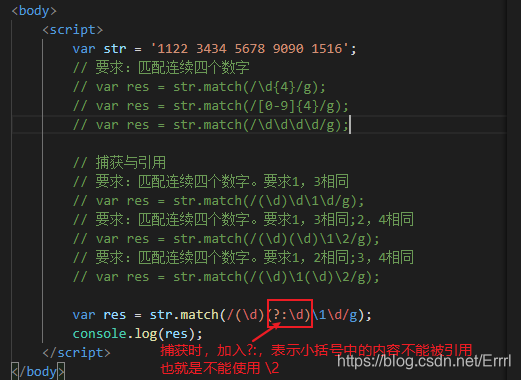
var res = str.match(/(\d)\1(\d)\2/g);
console.log(res);
</script>
输出结果:
禁止引用
(?:正则) 这个小括号中的内容不能够被引用
4. 正则表达式匹配中文(utf-8编码)
每个字符(中文、英文字母、数字、各种符号、拉丁文、韩文、日文等)都对应着一个Unicode编码。
查看Unicode编码,找到中文的部分,然后获取中文的Unicode编码的区间,就可以用正则匹配了。
前面我们用[a-z]表示小写字母,[0-9]表示数字,这就是一个范围表示,如果有一个数x能够表示第一个中文,有一个数y能够表示最后一个中文,那么[x-y]就可以表示所有的中文了。
中文的Unicode编码从4E00开始,到9FA5结束。
[4E00-9FA5]这个区间就能够表示中文。
JS语法:[\u4e00-\u9fa5]
完整的Unicode编码表:http://blog.csdn.net/hherima/article/details/9045861
<script>
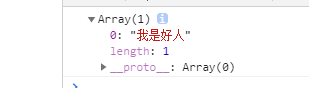
var str = '我是好人I’m a good man';
var result = str.match(/[\u4E00-\u9FA5]{4}/g);
console.log(result)
</script>
输出结果:
5. 环视(断言/零宽断言/正向预测/负向预测)
(?=n)匹配任何其后紧接指定字符串 n 的字符串。
有一个字符串是“abacad”,从里面查找a,什么样的a呢?后面必须紧接b的a。
正则语法是: /a(?=b)/g
相反
(?!n)匹配任何其后没有紧接指定字符串 n 的字符串。
有一个字符串是“abacad”,从里面查找a,什么样的a呢?后面不能紧接b的a。
正则语法是: /a(?!b)/g
<!-- 环视(断言/零宽断言/正向预测/负向预测) -->
<script>
var str = 'abacad';
// 查询后面是 b 的 a
var res = str.match(/a(?=b)/g);
console.log(res); //=> ["a"]
</script>
<script>
var str = 'abacad';
// 查询后面不是 b 的 a
var res = str.match(/a(?!b)/g);
console.log(res); //=> ["a", "a"]
</script>
<!-- 小例子 -->
<script>
var str = 'php7 and HTML5';
// 匹配后面跟着数字的字母字符串
var res = str.match(/[A-Za-z]+(?=\d)/g);
var res2 = str.match(/[A-Za-z]+(?!\d)/g);
console.log(res,res2) //=>["php", "HTML"], ["ph", "and", "HTM"]
</script>
输出结果:

(1)环视的过滤效果
(?!B)[A-Z]这种写法,其实它是[A-Z]范围里,排除B的意思,前置的(?!B)只是对后面数据的一个限定,从而达到过滤匹配的效果。
<!-- 环视的过滤效果 -->
<script>
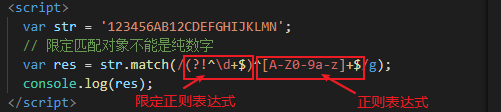
var str = 'ABCDEFGHIJKLMN';
var res = str.match(/(?!B)[A-Z]/g);
console.log(res); //=> ["A", "C", "D", "E", "F", "G", "H", "I", "J", "K", "L", "M", "N"]
</script>
输出结果:

(2)环视的限定效果
在过滤的基础上,限定正则表达式。用法相同。
输出结果:

6. 正则对象的属性和方法
正则对象中的成员方法和属性的正确调用方式:
和String对象类似:
一种是直接量语法(/[a-z]/.exec())
另一种方法是实例化正则对象,然后通过对象去调用成员方法(var reg = new RegExp(/[a-z]/); reg.exec())
类似字符串:
- ‘hello’.substr(1);
- var s = new String(‘hello’); s.substr(1);
(1)exec方法和lastIndex属性
exec方法执行一个正则匹配,只匹配一次,匹配到结果就返回一个数组类型的结果,匹配不到就返回null。并将表示匹配的位置 置为下一个匹配的位置。
lastIndex一个整数,标示开始下一次匹配的字符位置。没有更多匹配重置lastIndex为0.
依次调用exec匹配下一个的例子:
依次调用exec,会将匹配的位置不断的后移,直至结尾。
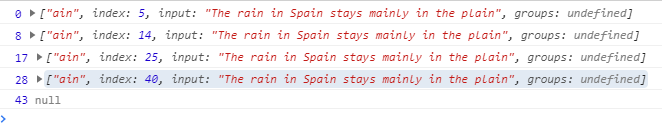
<script>
var str="The rain in Spain stays mainly in the plain";
var rex =/ain/g;
var i = rex.lastIndex;
var res = rex.exec(str);
console.log(i,res);
var i = rex.lastIndex;
var res = rex.exec(str);
console.log(i,res);
var i = rex.lastIndex;
var res = rex.exec(str);
console.log(i,res);
var i = rex.lastIndex;
var res = rex.exec(str);
console.log(i,res);
var i = rex.lastIndex;
var res = rex.exec(str);
console.log(i,res);
</script>
输出结果:
(2)test 方法
test方法检测目标字符串和正则表达式是否匹配,如果匹配返回true,不匹配返回false。
<!-- test方法 -->
<script>
/* 直接量语法调用 */
var str="The rain in Spain stays mainly in the plain";
var rex =/ain/g;
var res = rex.test(str);
console.log(res); //=> true
</script>
<script>
/* 实例化对象进行调用 */
var rex = new RegExp(/ain/,'g')
var str="The rain in Spain stays mainly in the plain";
var res = rex.test(str);
console.log(res); //=> true
</script>
输出结果:

7. 支持正则表达式的 String 对象的方法
(1)search()
在字符串中搜索符合正则表达式的结果。如果找到结果返回结果的位置,停止向后检索,也就是说忽略全局标识符g;如果没有匹配结果,返回-1。
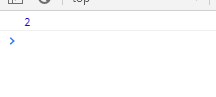
<script>
var str = 'Hello world';
var rex = /l/;
var res = str.search(rex);
console.log(res);
</script>
输出结果:
(2)match()
在字符串中检索匹配正则表达式的子串;如果匹配,返回包含匹配结果的一个数组;不匹配返回null。
不加全局g的情况:
获取的结果只是第一个匹配的内容,匹配的内容中的第一个单元是匹配的结果,后面的单元是子表达式
非全局下:
<script>
var str = '1122 3434 5656 1234 1221 2002';
var rex = /\d(\d)\1\d/;
var res = str.match(rex);
console.log(res);
</script>
输出结果:

全局下:
获取的结果是所有匹配的内容,但是不包含子表达式。
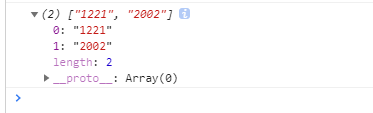
<script>
/* 全局 */
var str = '1122 3434 5656 1234 1221 2002';
var rex = /\d(\d)\1\d/g;
var res = str.match(rex);
console.log(res);
</script>
输出结果:
注意: 不管全局还是非全局调用多次和调用一次的结果相同
(3)split()
将字符串分割成数组:
特点是可以用正则表达式来分割字符串。
<!-- split -->
<script>
var str = '1131260584@qq.com';
// 用@来分割邮箱
var rex = /@/g;
var res = str.split(rex);
console.log(res); //=> ["1131260584", "qq.com"]
</script>
输出结果:

(4)replace()
默认只替换一次,加g全部替换。加入全局的g:
<!-- replace -->
<script>
var str = 'hello world';
// var res = str.replace('l','L');//=>heLlo world
// var res = str.replace(/l/,'L');//=>heLlo world
var res = str.replace(/l/g,'L');//=>heLLo worLd
console.log(res);
</script>
替换的时候,使用"$1"表示第一个子表达式:
用$2表示第二个子表达式,以此类推。
/* 将abc替换成aabbcc */
<script>
var str = 'abc';
var res = str.replace(/([a-z])/g,'$1$1');
console.log(res);
</script>
输出结果:

替换abc为a[a-b-c]c ghk g[g-h-k]k

<script>
var str = 'abc';
var res = str.replace(/(b)/g,"[$` -$1- $']");
console.log(res);
</script>
输出内容:

替换aaa bbb ccc为Aaa Bbb Ccc,演示可以用函数来进行复杂的替换。
说明: replace具有遍历的效果。
<script>
var str = 'aaa bbb ccc';
var res = str.replace(/[a-z]+/g,function(x){
return x.substr(0,1).toUpperCase()+x.substr(1);
});
console.log(res);
</script>
输出结果:

8. 案例
(1)匹配手机号格式是否正确
/* 验证手机格式 */
/**
*要求:
*1,1开头
*2,厂商代号
*3,11位数全数字
*/
/* 正则表达式 */
/^1(56|59|50|57|36|89|58)\d{8}$/g
(2)匹配邮箱格式是否正确
/* 验证邮箱格式 */
/**
*要求:
*1,@ 前6-14位数字与字母的组合,允许有符号比如 . - 等合法符号至多2个,@前一位不能是符号
*2,@ 后直接跟.com,也可以163.com,也可以163.com.cn
*/
/* 正则表达式 */
/^[A-z0-9][\w\.\-]{2}[A-z0-9]{3-11}@[a-z0-9]+(\.[A-z]+)+/g
(3)解决结巴程序
<script>
var str = '今今今今今今今今天晚晚晚晚晚晚晚上吃吃吃鸡鸡鸡鸡鸡'
var r = /([\u4e00-\u9fa5])\1*/g; //表示先捕获中文,再引用,利用量词*匹配相同中文
var result = str.replace(r,'$1');
console.log(result);
</script>
结果:

(4)用户名验证
/* 用户名的验证 */
/* *
* 要求:
* 1,不能纯字母
* 2,开头不能是数字
* 3,长度范围5-9
* 4,没有符号
*/
/* 正则表达式 */
/(?!^[A-z]+$)^[A-z][A-z0-9]{4,8}$/g
9. PHP中的正则表达式
php中没有修饰符。
(1)正则函数
1. preg_match()
相当于非全局匹配。
preg_match()返回匹配的次数,它的返回值是0或者是1。
- 0表示不匹配。
- 1表示匹配一次,因为preg_match在匹配一次之后就停止向后检索了。
<?php
$str = 'hello world';
$rex = '/[a-z]/';
/**
* preg_match
* 返回值是0或1
* $str 要执行正在匹配的字符串
* $rex 正则表达式
* $out 匹配内容,以一个数组的形式输出
*/
echo preg_match($rex,$str,$out);
echo '<pre>'; //预输出
print_r($out);
输出结果:
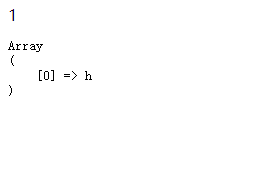
带子表达式的例子
/* 带有子表达式匹配的例子 */
$str = '1122 3455 6677 8989';
$rex = '/(\d)\1(\d)\2/';
echo preg_match($rex,$str,$out);
echo '<pre>';
print_r($out);
输出结果:

2. preg_match_all()
相当于全局匹配。
<?php
$str = 'hello world';
$rex = '/[a-z]/';
echo preg_match_all($rex,$str,$out);
echo '<pre>';
print_r($out);
输出结果:

带子表达式的例子
/* 带有子表达式匹配的例子 */
$str = '1122 3455 6677 8989';
$rex = '/(\d)\1(\d)\2/';
echo preg_match_all($rex,$str,$out);
echo '<pre>';
print_r($out);
输出结果:

3. preg_replace()
执行正则替换,替换字符串:
注意: 在php中preg_replace默认全部替换
<?php
$str = 'hello world';
$r = '/l/';
echo preg_replace($r,'L',$str);
输出结果:
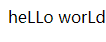
带子表达式:
<?php
$str = 'abcd123';
$r = '/([a-z])/';
echo preg_replace($r,'$1$1',$str);
输出结果:
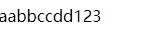
替换数组:
<?php
$arr = array('javascript','php7','es6','html5');
$res = preg_replace('/(\d)/','$1$1',$arr);
echo '<pre>';
print_r($res);
输出结果:

4. php中匹配中文
<?php
$res=array();
$str="你好aaaaa啊";
preg_match_all('/[\x{4e00}-\x{9fa5}]+/u',$str,$res);
echo '<pre>';
print_r($res);
//输出
//Array ( [0] => Array ( [0] => 你好 [1] => 啊 ) )
输出结果:

5. PHP中使用正则注意点
- PHP中的使用正则的使用除了//以外,外面还要加引号,这个引号要用单引号。
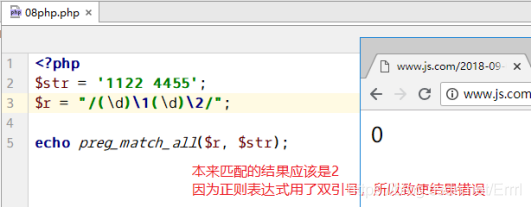
- 无论是JS中,还是PHP中,正则表达式的匹配模式默认都是贪婪模式。
6. 解决贪婪模式
贪婪模式:

上述代码,查询至少一个字母。但是在实际匹配的过程中,匹配到一个a之后,并没有停止,而是继续向后匹配,得到一个连续的字符串。这就是贪婪模式。
下面在正则表达式后面加入?,表示非贪婪模式:

默认是贪婪模式,必须使用非贪婪模式的例子:

PHP中,强制非贪婪模式:
加入大写的修饰符U即可。















 1307
1307











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









