







文章目录
前言
文件描述符是一个非负整数。
从原理上来说,进程地址空间的内核部分里面会维护一个已经打开的文件的数组,这个数组用来管理所有已经打开的文件。
打开的文件存储在进程地址空间的内核区中,称为文件对象,而文件描述符就是维护数组的索引。因此,文件描述符可以实现进程和打开文件之间的交互。
一、打开、创建和关闭文件
- 使用open函数可以打开或者创建并打开一个文件对象,分配一个文件描述符——选择最小可用的文件描述符(一般为3)。
- 执行成功时,open函数返回一个文件描述符,表示已经打开的文件;执行失败是,open函数返回-1,并设置相应的errno。
- 使用creat函数可以创建一个文件。(不常用)
- 使用close函数关闭文件。
#include <sys/types.h> //头文件
#include <sys/stat.h>
#include <fcntl.h>
int open(const char *pathname, int flags); //文件名 打开方式
int open(const char *pathname, int flags, mode_t mode);//文件名 打开方式 权限
int creat(const char *pathname, mode_t mode); //文件名 权限
//creat现在已经不常用了,它等价于
open(pathname,O_CREAT|O_TRUNC|O_WRONLY,mode);
-
参数:flags表示打开创建的方式。
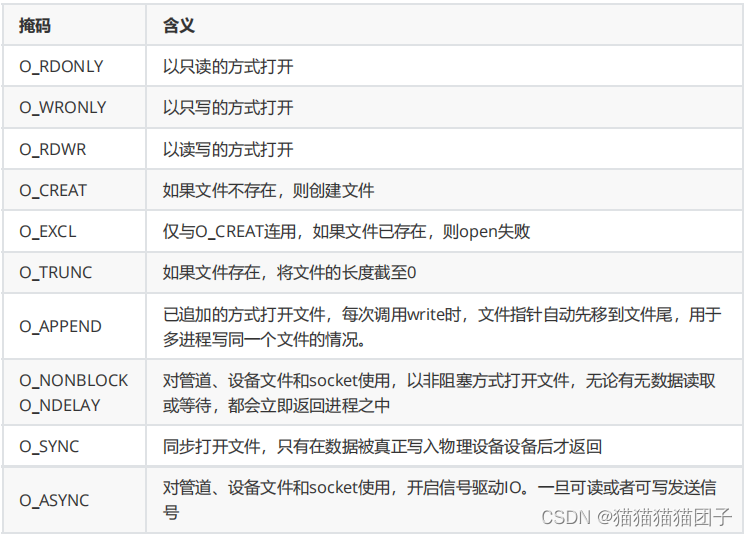
① 也可以使用按位或,拥有两个独立的属性:
O_RDONLY | O_RDWR
② 使用O_CREAT时,使用三参数的版本 -
参数:mode表示文件的访问权限。
mode通常采用直接赋数值的形式。 -
代码展示:
1 #include <47func.h>
2 #include<unistd.h>
3
4 int main(int argc,char*argv[])
5 {
6 // ./open file1
7 ARGS_CHECK(argc,2);
8 int fd = open(argv[1],O_RDONLY|O_CREAT|O_EXCL,0666);
9 //
10 ERROR_CHECK(fd,-1,"open");
11 printf("fd = %d \n",fd);
12 close(fd);
13 return 0;
14 }
15
open倾向于选择最小可用的文件描述符。

二、fopen和open 的关系
- fopen函数实际在运行的过程中也获取了文件的文件描述符。使用fileno函数可以得到文件指针的
文件描述符。
当使用fopen获取文件指针以后,依然是可以使用文件描述符来执行IO。
#include <func.h>
int main(int argc, char *argv[])
{
ARGS_CHECK(argc,2);
FILE* fp = fopen(argv[1],"rb+");
ERROR_CHECK(fp, NULL, "fopen");
int fd = fileno(fp);
printf("fd = %d\n", fd);
char buf[128] = {0};
read(fd, buf, 5);
printf("buf = %s\n", buf);
//使用read接口也是能够正常读取内容的
return 0;
}
-
fopen的原理:fopen函数在执行的时候,会先调用open函数,打开文件并且获取文件对象的信息
(通过文件描述符可以获取文件对象的具体信息),然后fopen函数会在用户态空间申请一片空间
作为缓冲区。 -
fopen的优势:因为read和write是系统调用,需要频繁地切换用户态和内核态,所以比较耗时。借
助用户态缓冲区,可以减少read和write的次数,使用fdopen函数可以根据文件描述符生成用户态
缓冲区。 -
open是unix系统调用函数(包括Linux),返回的是文件描述符,它是文件描述符表里的索引。
-
fopen是ANSIC标准中的C语言库函数,在不同的系统中应该调不同的内核api,返回的是一个指向文件结构的指针。
-
open属于低级IO,fopen属于高级IO。
-
open返回文件描述符,属于用户态,读写需进行用户态与内核态切换。
-
open是系统函数,不可移植;fopen是标准C函数,可移植。
三、读写文件
1、读函数
- 使用read和write来读写文件,它们统称为无缓冲的IO。
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);//文件描述符 缓冲区 长度
ssize_t write(int fd, const void *buf, size_t count);
-
对于read和write函数,出错返回-1,读取完了之后,返回0, 其他情况返回成功读取的个数。
-
read函数从文件对象拷贝到用户态的buf
-
每读写一次,指针向前移动一次。
-
磁盘文件:
ret < count::剩余长度 < count
ret = 0 :读取到文件末尾
ret = -1 : 报错
ssize_t ret = read(fd,buf,sizeof(buf));
-
设备文件/管道文件 :
= count: 发送的数据大于等于count
< 0 :count 发送的数据小于count
= 0 :ctrl + d
没有发送数据:read会导致进程阻塞 -
count 的选择: 单次读取的上限
如果读取文本文件:可以使用 sizeof(buf) - 1
如果buf只是用来暂存数据,不用于printf:使用sizeof(buf) -
read.c 代码实现
// 读取文件内容 read.c
1 #include <47func.h>
2 #include<unistd.h>
3
4 int main(int argc,char*argv[])
5 {
6 // ./open file1
7 ARGS_CHECK(argc,2);
8 int fd = open(argv[1],O_RDONLY);
9 ERROR_CHECK(fd,-1,"open");
10
11 printf("fd = %d\n",fd);
12
13 char buf[1024]= {0};
14 ssize_t ret = read(fd,buf,sizeof(buf));
15 ERROR_CHECK(ret, -1, "read");
16 printf("ret = %ld , buf = %s \n",ret,buf);
17
18
19 close(fd);
20 return 0;
21 }
结果:

2、文本文件和二进制文件
计算机的存储在物理上是二进制的,所以文本文件与二进制文件的区别并不是物理上的,而是逻辑上的。
这两者只是在编码层次上有差异。
1. 定义不同
- 文本文件是基于字符编码的文件,常见的编码有ASCII编码,UNICODE编码等等,文本文件基本上是定长编码的。
- 二进制文件是基于值编码的文件,你可以根据具体应用,指定某个值(可以看作是自定义编码)。进制文件可看成是变长编码的,多少个比特代表一个值,完全由自己决定。
2. 存取不同
-
文本工具打开一个文件,首先读取文件物理上所对应的二进制比特流,然后按照所选择的解码方式来解释这个流,然后将解释结果显示出来。
-
一般来说,你选取的解码方式会是ASCII码形式(ASCII码的一个字符是8个比特),接下来,它8个比特8个比特地来解释这个文件流。
-
记事本无论打开什么文件都按既定的字符编码工作(如ASCII码),所以当他打开二进制文件时,出现乱码也是很必然的一件事情了,解码和译码不对应。
-
文本文件的存储与其读取基本上是个逆过程。而二进制文件的存取与文本文件的存取差不多,只是编/解码方式不同而已。
3. 使用二进制文件的好处
-
二进制文件比较节约空间,这两者储存字符型数据时并没有差别。但是在储存数字,特别是实型数字时,二进制更节省空间。
比如储存 Real*4 的数据:3.1415927,文本文件需要 9 个字节,分别储存:3 . 1 4 1 5 9 2 7 这 9 个 ASCII 值,而二进制文件只需要 4 个字节(DB 0F 49 40) -
内存中参加计算的数据都是用二进制无格式储存起来的,因此,使用二进制储存到文件就更快捷。
如果储存为文本文件,则需要一个转换的过程。在数据量很大的时候,两者就会有明显的速度差别了。 -
就是一些比较精确的数据,使用二进制储存不会造成有效位的丢失。
4. 写函数
- count的选择
真实有多少数据写入多少数据
字符串: strlen(buf)
cp过程中: 上次read的返回值
5. 写函数的差别
fscanf / fprint : “10000” scanf+% --> int i = 1000
fread / fwrite : “10000” fread --> char str[] = “10000”
- 文本文件的处理
//写入文件描述符
1 #include <47func.h>
2
3 int main(int argc, char*argv[])
4 {
5 // ./write file1
6 ARGS_CHECK(argc,2);
7 int fd = open(argv[1],O_RDWR|O_CREAT,0666);
8 ERROR_CHECK(fd,-1,"open");
9 const char *buf = "hello";
10 ssize_t ret = write(fd,buf,strlen(buf));
11 ERROR_CHECK(ret,-1,"write");
12 printf("ret = %ld \n",ret);
13 close(fd);
14 return 0;
15 }
16
如果希望查看文件的2进制信息,在vim中输入命令:%!xxd
//使用od -h 命令也可查看文件的16进制形式
- 二进制数据的处理
1 #include <47func.h>
2
3 int main(int argc, char*argv[])
4 {
5 // ./write file1
6 ARGS_CHECK(argc,2);
7 int fd = open(argv[1],O_RDWR|O_CREAT,0666);
8 ERROR_CHECK(fd,-1,"open");
9 // const char *buf = "hello";
10 // ssize_t ret = write(fd,buf,strlen(buf));
11 int i = 10000000;
12 ssize_t ret = write(fd,&i,sizeof(i));
13 ERROR_CHECK(ret,-1,"write");
14 printf("ret = %ld \n",ret);
15 close(fd);
16 return 0;
17 }
5. read 函数的效率问题和场景
- read的效率问题:
使用不带缓冲IO的时候,CPU需要陷入内核态来处理文件读取。
如果频繁地使用read来读取少量数据,数据的读取效率会比较低。 - 使用read的场景:
① 读取常规文件时,文件内容大于读取长度(即还没有遇到EOF,读取字符数达到count),此时返回值等于count。
② 读取常规文件时,文件内容小于读取长度,此时返回值等于文件内容长度。
③ 读取网络文件的时候,由于数据传输不稳定,可能会导致文件还没有传输完成,read函数就已经返回的情况。此时返回值等于成功读取的字符数。
四、cp函数实现
1. fread/fwrite 和 read/write
- fread就是通过read来实现的,fread是C语言的库,而read是系统调用。
- 差别在read每次读的数据是调用者要求的大小,比如调用者要求读取10个字节数据,read就会从内核缓冲区(操作系统开辟的一段空间用来存储磁盘上的数据)读10个字节数据到数组中,所以每次调用read会涉及到用户态与內核态之间的切换从而损耗一定的性能。
- fread为了加快读的速度,fread每次都会从内核缓冲区读比要求更多的数据,然后放到应用进程缓冲区(首地址存在FILE结构体中),这样下次再读数据只需要到应用进程缓冲区中去取而无需过多的系统调用。
2. 代码实现
// read和write
1 #include <47func.h>
2
3 int main(int argc, char*argv[])
4 {
5 // ./mycp src dest
6 ARGS_CHECK(argc,3);
7 int fdr = open(argv[1],O_RDONLY);
8 ERROR_CHECK(fdr,-1,"open src");
9 int fdw = open(argv[2],O_RDWR|O_CREAT,0666);
10 ERROR_CHECK(fdr,-1,"open dest");
11 char buf[1];
12 time_t begTime = time(NULL);
13 while(1){
14 memset(buf,0,sizeof(buf));
15 ssize_t ret = read(fdr,buf,sizeof(buf));
16 ERROR_CHECK(ret,-1,"read");
17 if(ret == 0){
18 break;
19 }
20 write(fdw,buf,ret);
21
22 }
23 time_t endTime = time(NULL);
24 printf("total time = %ld s\n", endTime - begTime);
25 close(fdw);
26 close(fdr);
27
28 return 0;
29 }
30
五、改变文件大小
使用ftruncate函数可以文件大小
#include<unistd.h>
intftruncate(intfd,off_tlength);
- 函数ftruncate会将参数fd指定的文件大小改为参数length指定的大小。参数fd为已打开的文件描述词,而且必须是以写入模式打开的文件。
- 如果原来的文件大小比参数length大,则超过的部分会被删去(实际上修改了文件的inode信息)。执行成功则返回0,失败返回-1。
- 如果原来的文件大小比参数length小,则从小到大 补0——可能导致文件空洞
- 代码实现
ftruncate.c buffers
1 #include <47func.h>
2
3 int main(int argc,char *argv[])
4 {
5 // ./ftruncate file1
6 ARGS_CHECK(argc,2);
7 int fd = open(argv[1],O_RDWR);
8
9 ERROR_CHECK(fd,-1,"open");
10
11 printf("fd = %d\n",fd);
12 int ret = ftruncate(fd,10);
13 ERROR_CHECK(ret,-1,"fturncate");
14 close(fd);
15
16 return 0;
17 }
18
~
- 文件空洞:
空洞文件特点就是offset大于实际大小,也就是说一个文件的两头有数据而中间为空,以‘\0‘填充。
那文件系统会不会不做任何处理的将其存放在硬盘上呢?答案是否定的,文件系统没有傻到这种程度,因为这实际是中浪费,也是一种威胁,因为一旦黑客利用这个漏洞不断侵蚀磁盘资源,计算机就崩溃了。
使用mmap函数经常配合函数ftruncate来扩大文件大小
六、文件映射
- 使用mmap函数配合函数ftruncate来扩大文件大小。
- 原理:把一片内存区域与磁盘文件建立映射
- *访问内存 等价于 读写文件
- 为什么mmap需要和ftruncate联合使用?
因为分配的缓冲区的大小和偏移量的大小是有限制的,它必须是虚拟内存页大小的整数倍。如果文件大小较小,那么超过文件大小返回的缓冲区操作将不会修改文件;如果文件大小为0,还会出现Bus error。
#include <sys/mman.h>
void *mmap(void *adr, size_t len, int prot, int flag, int fd, off_t off);
adr: 参数用于指定映射存储区的起始地址。这里设置为NULL,这样就由系统自动分配;
len : 文件长度 (提前ftruncate)
prot:表示权限,PROT_READ,PROT_WRITE表示可读可写;
flags:多进程共享
fd : 文件描述符
offset :0
void* 映射区的首地址
建立
- 使用munmap释放内存
① open文件
② ftruncate函数
③ mmap函数:
mmap(NULL,5,PROT_READ|PROT_WRITE,MAP_SHARED,fd,0);
成功后返回内存空间首地址
④ *访问
⑤ munmap(※
int munmap(void*addr,size_t length);
//示例
#include <func.h>
int main(int argc, char *argv[])
{
ARGS_CHECK(argc,2);
int fd = open(argv[1],O_RDWR);
ERROR_CHECK(fd,-1,"open");
printf("fd = %d\n",fd);
//先固定文件的大小
ftruncate(fd,5)
char *p;
p = (char *)mmap(NULL,5,PROT_READ|PROT_WRITE,MAP_SHARED,fd,0);
ERROR_CHECK(p,(char *)-1,"mmap");
p[5] = 0;
printf("%s\n",p);
p[0] = 'H';
munmap(p,5);
close(fd);
return 0;
}
使用mmap接口可以实现直接将一个磁盘文件映射到存储空间的一个缓冲区上面,无需使用read和write进行IO,修改内存和修改磁盘文件等价。
七、文件定位
- 函数lseek将文件指针设定到相对于whence,偏移值为offset的位置。它的返回值是读写点距离文件开始的距离。
#include <sys/types.h>
#include <unistd.h>
off_t lseek(int fd, off_t offset, int whence);//fd文件描述词
//whence 可以是下面三个常量的一个
//SEEK_SET 从文件头开始计算
//SEEK_CUR 从当前指针开始计算
//SEEK_END 从文件尾开始计算
- 利用该函数可以实现文件空洞:对一个新建的空文件,可以定位到偏移文件开头1024个字节的地
方,在写入一个字符,则相当于给该文件分配了1025个字节的空间,形成文件空洞。
1 #include <47func.h>
2
3 int main(int argc, char *argv[])
4 {
5 ARGS_CHECK(argc,2);
6 int fd = open(argv[1],O_RDWR);
7 ERROR_CHECK(fd,-1,"open");
8 int ret = lseek(fd,5,SEEK_SET);
9 printf("pos = %d \n",ret);
10 char buf[128]={0};
11 read(fd,buf,sizeof(buf));
12
13 printf("buf = %s\n",buf);
14 close(fd);
15 return 0;
16 }
17
结果:

- 通常用于多进程间通信的时候的共享内存。(在某些文件系统的实现中,这些空洞甚至不会占用磁盘空间)
#include <func.h>
int main(int argc, char *argv[])
{
ARGS_CHECK(argc,2);
int fd = open(argv[1],O_RDWR);
ERROR_CHECK(fd,-1,"open");
int ret = lseek(fd, 1024, SEEK_SET);
write(fd, "a", 1);
close(fd);
return 0;
}
八、获取文件信息
- 可以通过fstat和stat函数获取文件信息,调用完毕后,文件信息被填充到结构体struct stat变量中,函数原型为:
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
int stat(const char *file_name, struct stat *buf); //文件名 stat结构体指针
int fstat(int fd, struct stat *buf); //文件描述词 stat结构体指针
- 对于结构体的成员st_mode,有一组宏可以进行文件类型的判断:
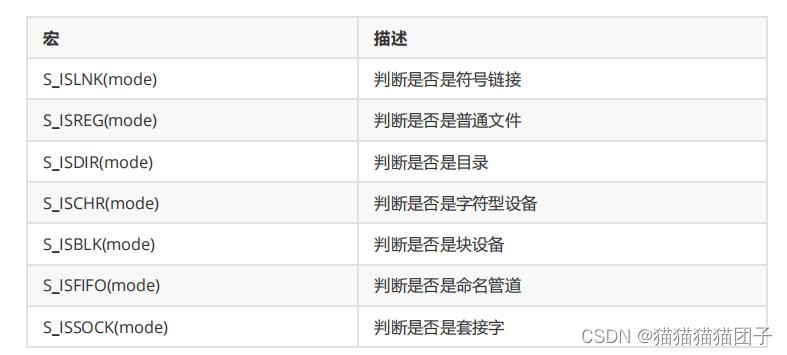
- 代码实现:
//获得文件的大小
#include<sys/stat.h>
#include<unistd.h>
int main(int argc, char *argv[])
{
struct stat buf;
stat (argv[1],&buf);
printf(“file size = %d\n”,buf.st_size);//st_size可以得到文件大小
}
//如果用fstat函数实现,如下:
//int fd = open (“/etc/passwd”,O_RDONLY); //先获得文件描述词
//fstat(fd, &buf);
#include <func.h>
int main(int argc, char *argv[])
{
ARGS_CHECK(argc,2);
int fd = open(argv[1],O_RDWR|__O_PATH);
ERROR_CHECK(fd,-1,"open");
struct stat buf;
int ret = fstat(fd, &buf);
ERROR_CHECK(ret, -1, "fstat");
if(S_ISDIR(buf.st_mode))
{
printf("directory\n");
}
else if(S_ISREG(buf.st_mode))
{
printf("regular file\n");
}
else if(S_ISLNK(buf.st_mode))
{
printf("link file\n");
}
printf("the size of file is: %ld\n",buf.st_size);
close(fd);
return 0;
}
八. 文件描述符复制
1. printf的本质
- pirnt的本质 先把数据拷贝到stdout 通过1号文件描述符拷贝到输出设备的文件对象:
1 #include <47func.h>
2
3 int main()
4 {
5 printf("stdin fileno = %d \n", fileno(stdin));
6 printf("stdout fileno = %d \n", fileno(stdout));
7 printf("stderr fileno = %d \n", fileno(stderr));
8
9 return 0;
10 }
11
2. 文件描述符的复制–dup
- 系统调用函数dup和dup2可以实现文件描述符的复制
- dup返回一个新的文件描述符(是自动分配的,数值是没有使用的文件描述符的最小编号)。
这个新的描述符是旧文件描述符的拷贝,这意味着两个描述符共享同一个数据结构。
#include <unistd.h>
int dup(int oldfd);
int dup2(int oldfd, int newfd);
- 文件描述符的复制是指用另外一个文件描述符指向同一个打开的文件,它完全不同于直接给文件描述符变量赋值,下面是文件描述符赋值的例子:
#include <func.h>
int main(int argc, char *argv[])
{
ARGS_CHECK(argc,2);
int fd = open(argv[1],O_RDWR);
ERROR_CHECK(fd,-1,"open");
printf("fd = %d\n",fd);
int fd1 = fd;
close(fd);
char buf[128] = {0};
int ret = read(fd1, buf, sizeof(buf));
ERROR_CHECK(ret, -1, "read");
return 0;
}
在此情况下,两个文件描述符变量的值相同,指向同一个打开的文件,但是内核的文件打开引用计数还是为1,所以close(fd)或者close(fd1)都会导致文件立即关闭。
- 如果使用文件描述符的复制,则情况有所区别
1 #include <47func.h>
2
3 int main(int argc,char*argv[])
4 {
5 ARGS_CHECK(argc,2);
6 int oldfd = open(argv[1],O_RDWR);
7 ERROR_CHECK(oldfd,-1,"open");
8 write(oldfd,"hello",5);
9 printf("oldfd = %d\n",oldfd);
10 int newfd = dup(oldfd);
11 printf("newfd = %d\n",newfd);
12 write(newfd,"world",5);
13 close(newfd);
14 close(oldfd);
15 return 0;
16 }
17
3. dup原理
- dup的原理:当使用文件的时候,为了和硬件(比如磁盘)建立联系,进程地址空间中应当分配一片空间存放各个已经打开文件的inode信息(此时的文件信息已经放在内存,和实际磁盘内容无关了),Linux当中是采用链表的方式将它们组织起来,称为inode表。
- 除此以外,系统为了高效管理文件,需要一个额外的数据结构来管理文件,称为文件表。文件表里面存放了文件的状态标志(典型的比如引用计数)、偏移量以及inode表的指针。文件表和inode表是在进程地址空间里面,是存放内核区中的,并且这些内容是所有进程共享的(所以多进程同时写入会有问题)
- 而我们所使用的文件描述符与内核区中的另一个数据结构文件指针表有关,文件指针表的索引就是描述符,而数组的内容就是文件表项的指针。
- 当执行dup函数以后,在文件指针表当中,会有两个不同的描述符来描述同一个文件,而在文件表当中,该文件的引用计数会自增1。当关闭文件时,文件指针表会移除该文件相关的项,并且文件表中该文件的引用计数会自减1,当引用计数为0的时候,文件表以及inode表的表项会被释放。
九. 文件重定向
1. dup函数
- 使用dup函数可以实现输出重定向:
- 该程序首先打开了一个文件,返回一个文件描述符,因为默认的就打开了0,1,2表示标准输入,标准输出,标准错误输出。
- 而用close(STDOUT_FILENO);则表示关闭标准输出,此时文件描述符1就空着然后dup(fd);则会复制一个文件描述符到当前未打开的最小描述符,此时这个描述符为1。
- 后面关闭fd自身,然后在用标准输出的时候,发现标准输出重定向到你指定的文件了。
- 那么printf所输出的内容也就直接输出到文件(因为printf的原理就是将内容输入到描述符为1的文件里面)。
1 #include <47func.h>
2
3 int main(int argc,char*argv[])
4 {
5 ARGS_CHECK(argc,2);
6 int oldfd = open(argv[1],O_RDWR);
7 ERROR_CHECK(oldfd,-1,"open");
8 printf("you can see me@!\n");
9 close(STDOUT_FILENO);
10 int newfd = dup(oldfd);
11 printf("newfd = %d\n",newfd);
12 printf("you can't see me@!\n");
13 close(newfd);
14 close(oldfd);
15 return 0;
16 }
17
结果:

2. dup2函数
- dup2(int fdold,int fdnew)也是进行描述符的复制,只不过采用此种复制,新的描述符由用户用参
数fdnew显式指定。 - 对于dup2,如果fdnew已经指向一个已经打开的文件,内核会首先关闭掉fdnew所指向的原来的文件。此时再针对于fdnew文件描述符操作的文件,则采用的是fdold的文件描述符。如果成功dup2的返回值于fdnew相同,否则为-1。
//使用输出重定向
#include <func.h>
int main(int argc, char *argv[])
{
ARGS_CHECK(argc,2);
int fd = open(argv[1],O_RDWR);
ERROR_CHECK(fd,-1,"open");
printf("\n");
int fd1 = dup2(fd,STDOUT_FILENO);
printf("fd1 = %d\n", fd1);
close(fd);
printf("the out of stdout\n");
return 0;
}
总结
1. 写一百万个1
缓冲数组
char buf[1000];
memset(buf,'1',1000);
//填充
2. 学生结构体读写
- 这题主要要摆脱原本的文本读写的思考方式,从内存的角度来读写。
- write和read,都是读取一片内存的方式,结合结构体的内存的分布来理解,这样就不用考虑结构体里面每个属性是什么类型。
#include <47func.h>
typedef struct student{
char* name;
char* number;
double grade;
}Student;
int main(int argc, char*argv[])
{
Student s[3]={
{"1001","Andy",86.5},
{"1002","Ino",96.2},
{"1003","Susan",92.6}
};
ARGS_CHECK(argc,2);
int fd = open(argv[1],O_RDWR|O_CREAT|O_TRUNC,0666);
ERROR_CHECK(fd,-1,"open");
write(fd,s,sizeof(s));
lseek(fd,0,SEEK_SET);
while(1){
char buf[4096]={0};
ssize_t ret = read(fd,buf,sizeof(buf));
if(ret == 0)break;
printf("%s\n",buf);
}
Student res[3];
read(fd,res,sizeof(res));
for(int i=0;i<3;i++){
printf("num = %d, name = %s, score = %5.2f\n",res[i].number,res[i].name,res[i].grade);
}
close(fd);
return 0;
}















 170
170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









