








📝个人主页🌹:Eternity._
🌹🌹期待您的关注 🌹🌹


论文讲解
论文题目:High-Resolution Image Synthesis with Latent Diffusion Models(基于潜在扩散模型的高分辨率图像合成)
论文被计算机视觉顶会CVPR 2022收录
Stable diffusion是一个基于Latent Diffusion Models(潜在扩散模型,LDMs)的文图生成(text-to-image)模型。它建立在自注意力机制和扩散过程的基础上。它的设计灵感来自于扩散过程模型(Diffusion Models),这些模型在自然图像建模领域取得了巨大成功。
Stable Diffusion通过一系列的扩散步骤来生成图像。在每一步中,模型逐渐“扩散”图像,从含有较少信息的噪声开始,到包含更多细节的图像。在每个扩散步骤中,模型需要预测图像的条件分布,并根据这个条件分布生成下一个扩散步骤的输入。
本文所涉及的所有资源的获取方式:
https://www.aspiringcode.com/content?id=17143966705089&uid=e3decf79216b48adb0c77754db52e43f
背景介绍
在生成模型的研究中,扩散过程模型和自注意力机制是两个备受关注的领域。扩散过程模型是一种基于随机过程的生成模型,通过模拟随机过程的演化来生成图像,它在自然图像建模领域取得了巨大的成功。而自注意力机制则是一种强大的神经网络组件,能够有效地捕捉输入序列中不同位置之间的依赖关系,被广泛应用于自然语言处理和计算机视觉领域。
近年来,研究人员开始探索如何将扩散过程模型和自注意力机制结合起来,以进一步提高生成模型的性能和生成图像的质量。在这个背景下,Stable Diffusion应运而生,简称SD模型。
Stable Diffusion的提出
Stable Diffusion是一种基于扩散过程和自注意力机制的生成模型,旨在生成高质量的图像。它采用了一系列扩散步骤来逐渐生成图像,每个步骤中模型需要预测图像的条件分布,并生成下一个扩散步骤的输入。通过结合自注意力机制,Stable Diffusion能够有效地捕捉图像中不同位置之间的关联信息,从而生成更加真实和细节丰富的图像。
Stable Diffusion在图像生成领域的应用
Stable Diffusion不仅可以用于生成高质量的图像,还可以应用于多种图像生成任务,包括图像修复、超分辨率重建、图像合成等。其灵活的生成过程和强大的生成能力使其成为图像生成领域的一项重要研究成果,并在各种实际应用中展现出巨大潜力。
在下文中,我们将更深入地探讨Stable Diffusion的工作原理、实现细节以及相关的实验结果,以帮助读者更好地理解这一新颖的生成模型,并探讨其在未来的发展方向和应用前景。
经过微调后Stable Diffusion模型可以生成各种风格的图像,先来看生成效果:
论文方法
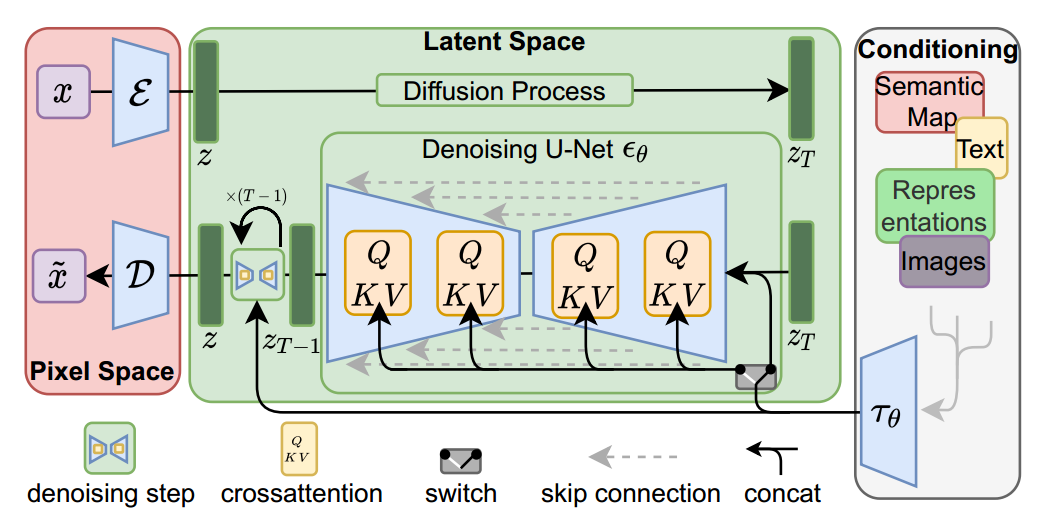
上图是模型的框架图,模型的步骤和讲解如下
1、训练自编码模型(AutoEncoder)
-
首先,通过训练一个自编码模型,包括编码器和解码器部分。编码器负责将输入图像压缩成潜在表示(latent representation),而解码器则负责将潜在表示解码成原始像素空间的图像。
-
这一步骤是为了将图像压缩到低维的潜在表示空间,为后续的diffusion操作做准备。
2、感知压缩(Perceptual Compression) -
利用训练好的自编码模型对图片进行压缩,将其转换到潜在表示空间。
-
在潜在表示空间上进行操作,这个过程被称为感知压缩,因为它通过自编码器模型来实现压缩,同时保留了重要的图像特征。
3、潜在表示空间上的diffusion操作 -
在潜在表示空间上进行diffusion操作,其过程与标准的扩散模型类似。
扩散模型的具体实现为time-conditional UNet,这是一种结合了时间条件信息的UNet结构,用于在- 潜在表示空间上进行图像生成。
图片感知压缩
图片感知压缩(Perceptual Image Compression)是一种通过忽略图像中的高频信息,保留重要和基础特征来实现高效压缩的方法。这种方法在生成模型中起到了关键作用,通过降低模型训练和采样的计算复杂度,使得模型能够在较短的时间内生成高质量的图像,从而降低了模型的落地门槛。
方法原理
- 感知压缩利用预训练的自编码模型(如变分自编码器,VAE)来学习图像的潜在表示空间。这个潜在表示空间是在感知上等同于图像空间的,但维度更低。
- 在这个潜在表示空间中,自编码模型保留了图像的重要特征,同时忽略了一些不太重要的高频信息。这种压缩方式使得模型训练和采样的计算复杂度大幅降低。
方法优势
- 感知压缩只需要训练一个通用的自编码模型,就可以应用于不同的扩散模型训练中,也可以用于不同的图像生成任务。这种通用性使得该方法在多种场景下都十分有效。
- 除了标准的无条件图像生成任务外,感知压缩还可以方便地应用于各种图像到图像(如修复、超分辨率重建)和文本到图像(如文本生成图像)的任务中。
训练过程
- 基于感知压缩的扩散模型的训练通常是一个两阶段的过程。首先,需要训练一个自编码器来学习图像的潜在表示空间。在这一阶段中,为了避免潜在表示空间出现高度的异化,通常会采用KL正则化(KL-reg)和矢量量化正则化(VQ-reg)等方法。
- 在Stable Diffusion中,主要采用AutoencoderKL这种实现,这个实现结合了KL正则化的方法,用于训练自编码器。
潜在扩散模型
扩散模型可以被理解为一种时序去噪自编码器,其主要目标是根据输入图像去预测一个对应的去噪后的变体,或者说预测噪音,其中噪音是输入图像的噪音版本。其相应的目标函数可以被表述如下:
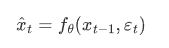
这里, x_t是模型预测的下一个时间步的图像,x_t-1 是当前时间步的输入图像,ε_t 是从均匀分布中采样得到的噪音。
在潜在扩散模型中,引入了预训练的感知压缩模型。这个感知压缩模型包括一个编码器E和一个解码器D。在训练过程中,编码器 负责将输入图像压缩成潜在表示,解码器则负责将潜在表示 解码成图像。这样,模型就能够在潜在表示空间中学习。相应的目标函数可以被表述如下:
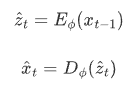
在这里,z_t 是模型预测的下一个时间步的潜在表示,x_t-1 是当前时间步的输入图像,E_ϕ 是编码器,D_ϕ 是解码器,ϕ是编码器和解码器的参数。这样的目标函数结构使得模型能够在潜在表示空间中进行操作,同时通过解码器将潜在表示转换回图像空间。
条件机制
通过引入条件信息来控制图片合成的过程。为了实现这一点,论文提出了拓展的条件时序去噪自编码器(conditional denoising autoencoder)。通过这种方法,我们可以引入条件变量c,并将其作为输入来控制图像的生成过程。
通过在 UNet 主干网络上增加 cross-attention 机制来实现条件图片生成。这个过程可以理解为,在生成图像的过程中,模型会重点关注与条件变量相关的信息,从而在图像生成过程中加入条件的影响。为了能够处理来自多个不同模态的条件变量,论文引入了一个领域专用编码器(domain specific encoder),用来将不同模态的条件变量 ?c 映射为一个统一的中间表示。这样一来,我们可以很方便地引入各种形态的条件,比如文本、类别、布局等等。
总之,条件图片生成任务的目标函数可以根据模型的具体设计而有所不同,但通常会涉及到最小化生成图像与目标图像之间的差异,同时考虑到条件变量对图像生成过程的影响。
实验结果

模型生成效果如上图,展示了来自不同数据集(CelebAHQ、FFHQ、LSUN-Churches、LSUN-Bedrooms和类别条件的ImageNet)上训练的LDMs(Latent Diffusion Models)生成的样本。这些样本的分辨率均为256×256像素。
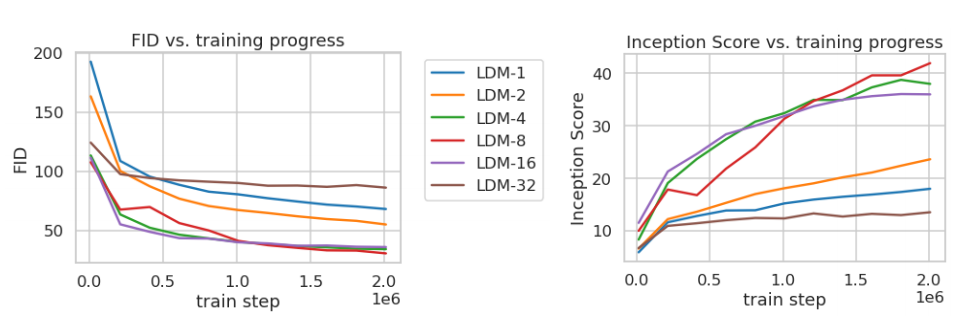
这个图表展示了在ImageNet数据集上,通过观察类别条件下的不同下采样因子 f,对类别条件下的扩散模型(LDM,Latent Diffusion Models)进行训练的情况。图中显示了在进行了200万个训练步骤后的结果。这些模型使用了不同的下采样因子(如LDM-1、LDM-4、LDM-16等),这直接影响了模型的感知压缩程度。
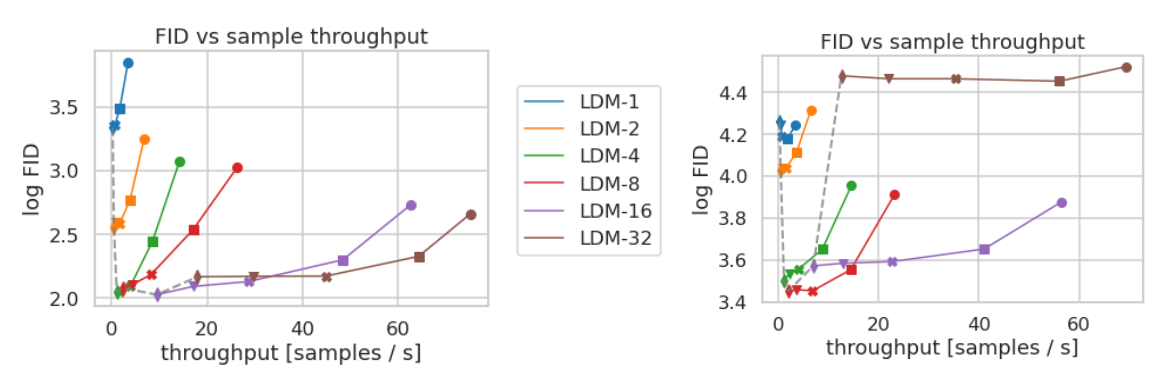
展示了在CelebA-HQ和ImageNet数据集上,不同压缩程度的LDMs(Latent Diffusion Models)在推断速度和样本质量之间的比较。图中的左侧部分是CelebA-HQ数据集的结果,右侧部分是ImageNet数据集的结果。不同的标记代表使用DDIM采样器进行的{10、20、50、100、200}个采样步骤,沿着每条线从右到左进行计数。
代码复现
环境配置
基本的环境配置要点如下
- 最好使用显卡的电脑,没有显卡SD模型生成图像较慢。(本人使用1660 Ti 显卡 6G显存可跑SD模型,速度比较快了,大家可以参考此配置)
- 电脑能够访问github,并安装git工具,方便下载代码。(如果不能访问,附件中有我整理的代码包(已经配置好且安装了汉化插件),即开即用。)
- 安装好编程语言工具python,可以直接安装,也可以使用Conda环境
1、在Windows下需要配置有Python环境,建议使用Conda环境
# 创建一个sd环境,方便后续安装包
conda create –n sd python=3.10.9
# 激活sd环境
activate sd
2、拉取官方的代码,如果不能拉取代码,可我整理好的附件使用。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
3、安装代码运行所需要的包(已成功下载官方代码或者下载了我整理好的代码包)
成功下载代码包后,打开"stable-diffusion-webui"文件夹,点击webui-user.bat文件,一定注意点击webui-user.bat,后缀是bat的文件(Windows安装文件),而不是sh的(sh是Linux的安装文件)。
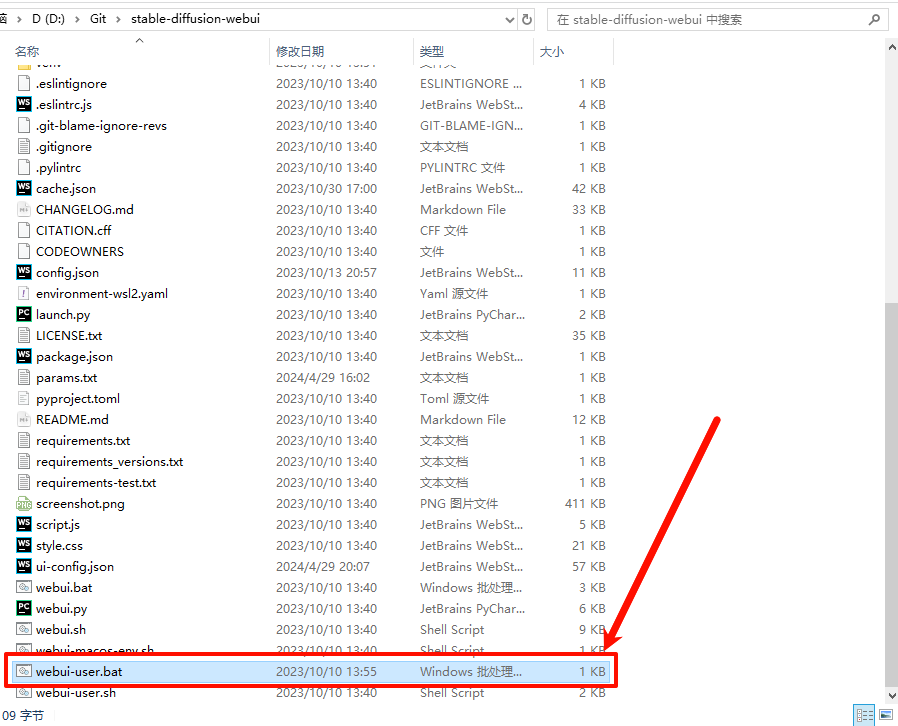
安装一般需要等待1个半小时左右,耐心等待安装结束。
安装结束,一般浏览器会自动打开网页,如果没有打开,请在浏览器输入http://127.0.0.1:7860,正常运行,命令行页面提示的地址。
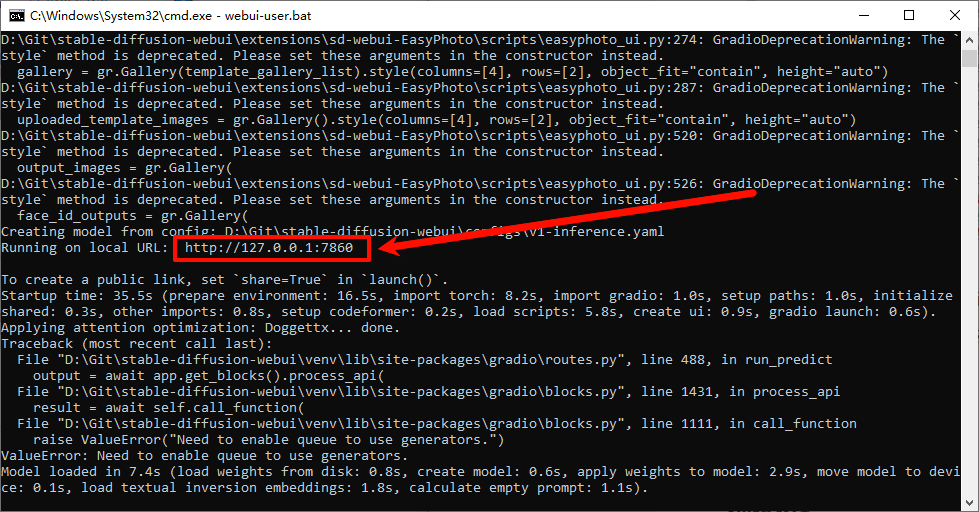
即可见到启动页面
下面是官方代码的启动页面,我整理的代码是已经安装好汉化插件,汉化过的,方便使用
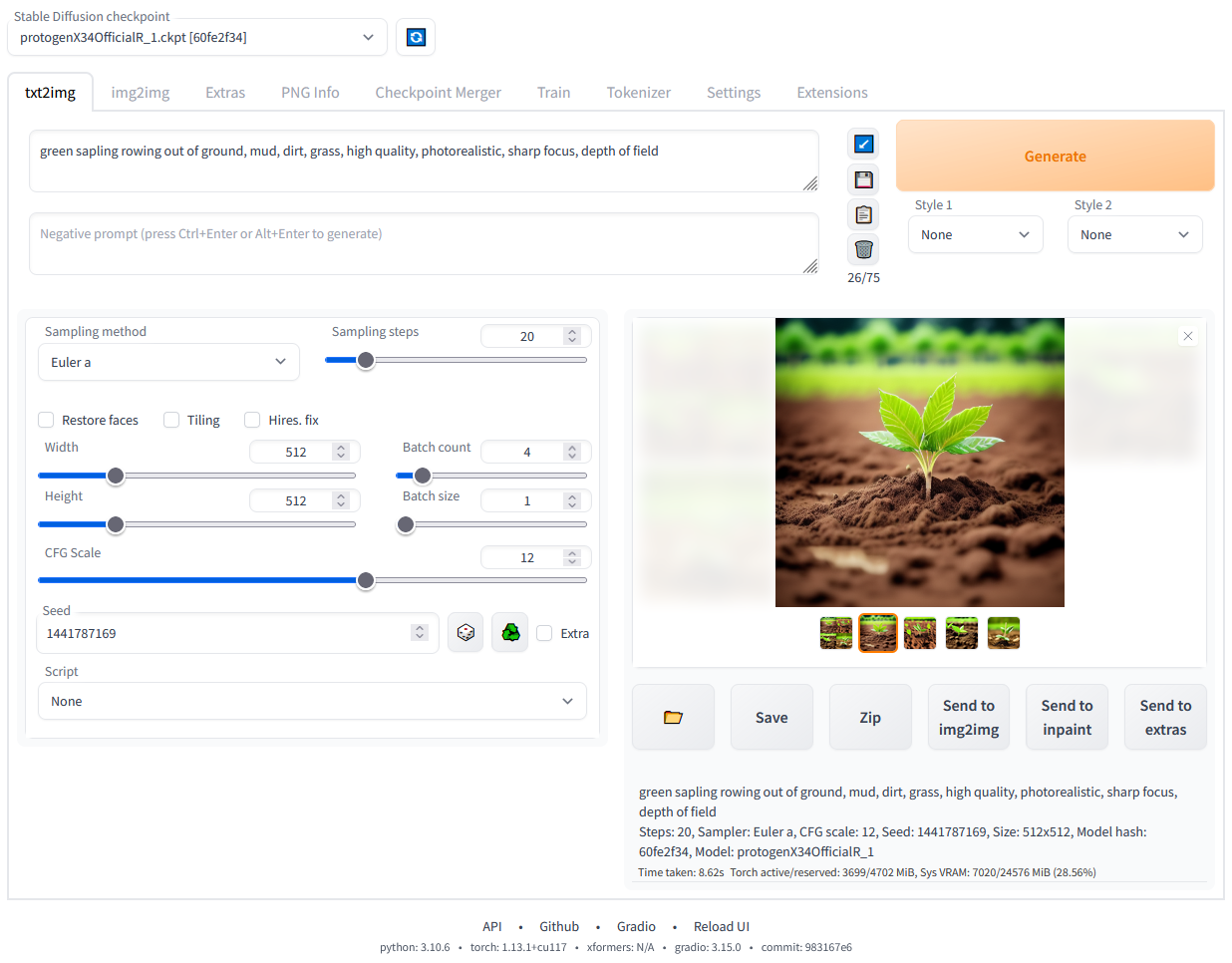
下面是使用整理好的附件的代码启动的页面,已经集成了中英文双语汉化插件,方便使用。
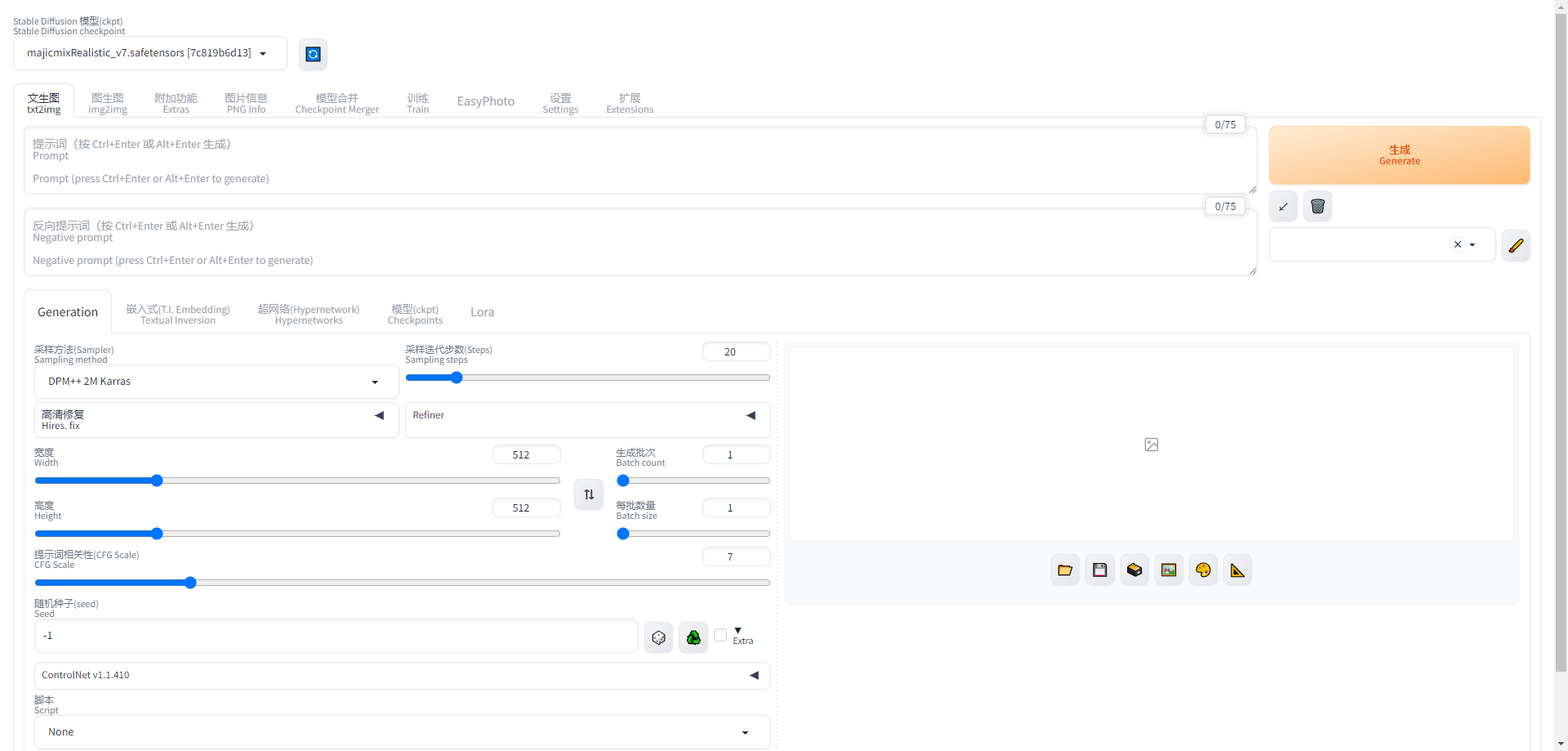
提示词准备
提示词可以根据用户自己的喜好设定,比如设置生成猫狗的图像、动漫图像。不过提示词的设定是一门技术,好的提示词,能够引导模型生成符合要求的图像。提示词要是英文的。
这里推荐一个提示词和模型下载网站 https://civitai.com/,在这个网站上可以下载自己喜欢风格的模型,也可以方便获取提示词,可以基于别人写好的提示词修改。
下面就是一个“majicMIX realistic 麦橘写实”的模型,可以生成写实风格的图像。
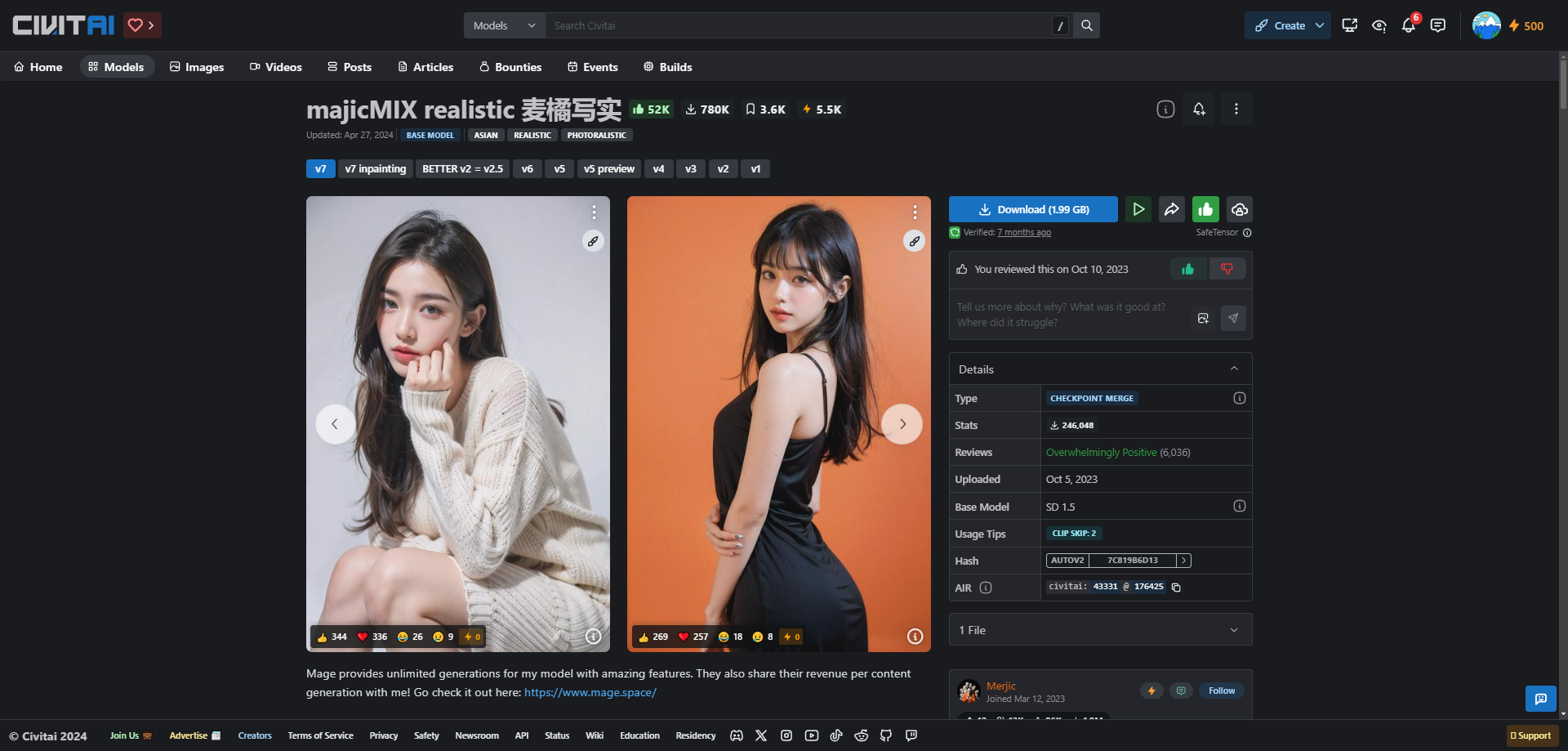
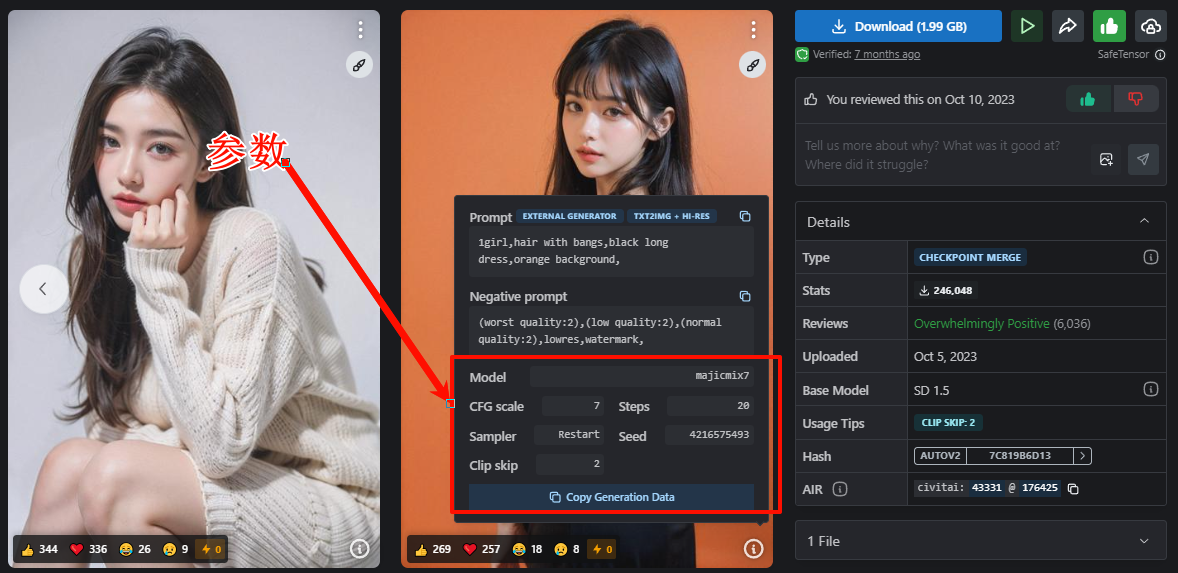
提示词一般要准备正面提示词和负面提示词
正面提示词(我们想要的内容)例如:
1girl,hair with bangs,black long dress,orange background,
负面提示词(我们不要的内容)例如:
(worst quality:2),(low quality:2),(normal quality:2),lowres,watermark,
准备好提示词,我们就可以设置模型生成的参数

生成的参数控制模型的应该怎样生成
针对不同风格图像要有不同的参数,例如
模型下载
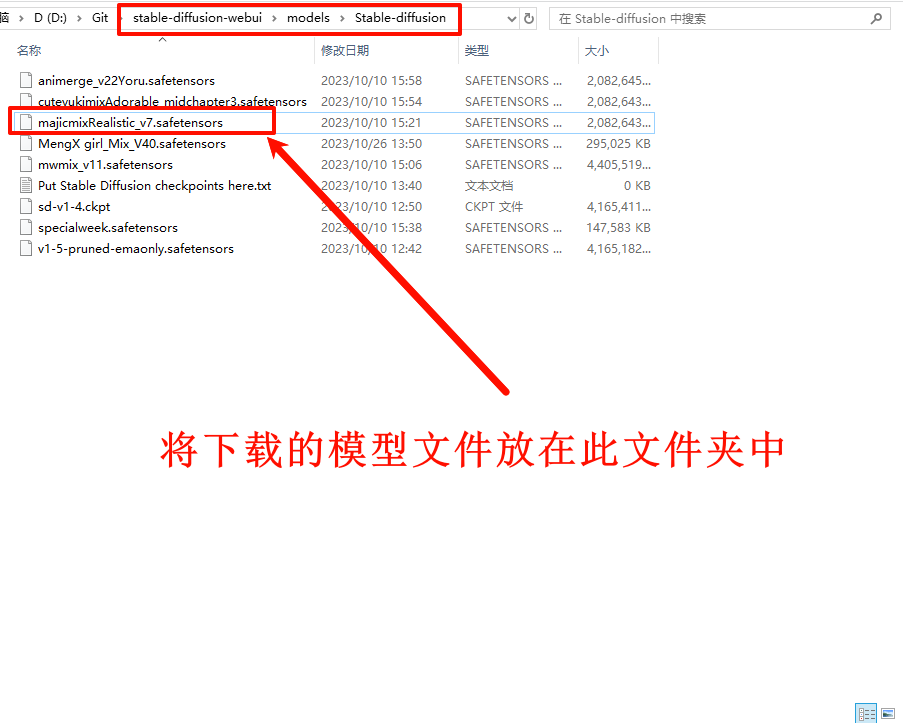
下载模型文件majicmixRealistic_v7.safetensors到stable-diffusion-webui\models\Stable-diffusion文件夹下
放在stable-diffusion-webui\models\Stable-diffusion文件夹下,一定要注意,放在该文件夹,才能检测到。
生成图像
以上都设置完毕后,即可点击生成按钮,开始绘画
点击生成按钮生成效果如下所示:
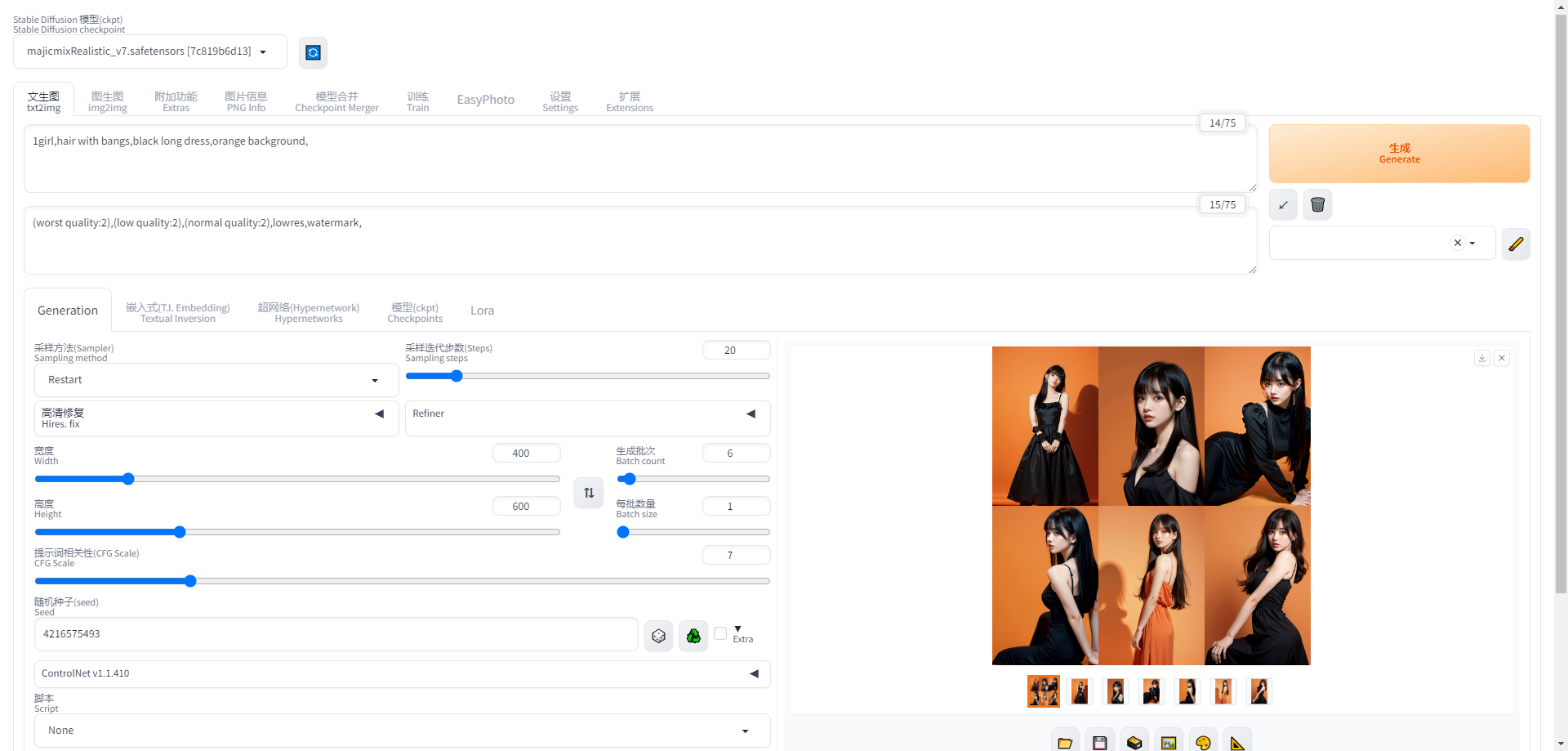
绘画效果
下面是生成图像的高清图:
本次绘画过程中,共进行6次生成,除第一次生成效果不太好外,其余效果都很好,可以生成根据提示不同风格的图像

总结
以上就是Stable diffusion模型的论文和代码复现的讲解。
这篇论文和代码,都是很好玩的,可以帮助我们绘制想要的图画,满足我们一键成为画家的愿望。
整理的代码在附件中,可以直接安装上面的教程使用。
参考链接
Stable Diffusion论文
https://openaccess.thecvf.com/content/CVPR2022/papers/Rombach_High-Resolution_Image_Synthesis_With_Latent_Diffusion_Models_CVPR_2022_paper.pdf
编程未来,从这里启航!解锁无限创意,让每一行代码都成为你通往成功的阶梯,帮助更多人欣赏与学习!
更多内容详见:
https://www.aspiringcode.com/login?tid=17301108783140


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









