







 本文介绍了一位非CS背景的作者如何使用Python的BeautifulSoup库爬取链家网站上的重庆江北区在售二手房房源信息。通过分析网页结构,抓取了包括标题、总价、单价等在内的多项房源数据,并分享了爬取过程中需要注意的反爬策略。最终成功获取3000条房源数据,为初学者提供了实践Python爬虫的实例。
本文介绍了一位非CS背景的作者如何使用Python的BeautifulSoup库爬取链家网站上的重庆江北区在售二手房房源信息。通过分析网页结构,抓取了包括标题、总价、单价等在内的多项房源数据,并分享了爬取过程中需要注意的反爬策略。最终成功获取3000条房源数据,为初学者提供了实践Python爬虫的实例。
bs4爬取重庆链家在售二手房房源信息(总共爬取3000条)
写这篇博客两个目的,第一是总结复习最近一个月工作学习的爬虫内容,第二是给想学习python或者爬虫,但是没有python基础的童鞋们一些建议(不要怕,python是一门工具(或者是手艺),学习手艺最关键的就是做事情(写爬虫入门吧)。我是非CS出身,之前学过半年R语言,因为现在工作需要用到python,所以先学爬虫,大致了解一下python语言。
链家的网站目前是不设防的(没有反爬机制),所以爬起来是非常轻松的,也能够增加大家初学python或爬虫的信心。
准备阶段
第一步,工具准备
1.安装好python,然后我的编译器是pycharm。
2.选取爬取网站 https://cq.lianjia.com/ershoufang/
第二步,安装好需要的库,我这里是用BeautifulSoup爬取的,所以安装requests、bs4、 re、time(也可以用Xpath爬取,需要安装相应的库,time是设置访问频率的,两秒,太频繁可能禁止访问)
第三步,观察所需要爬取的网页信息

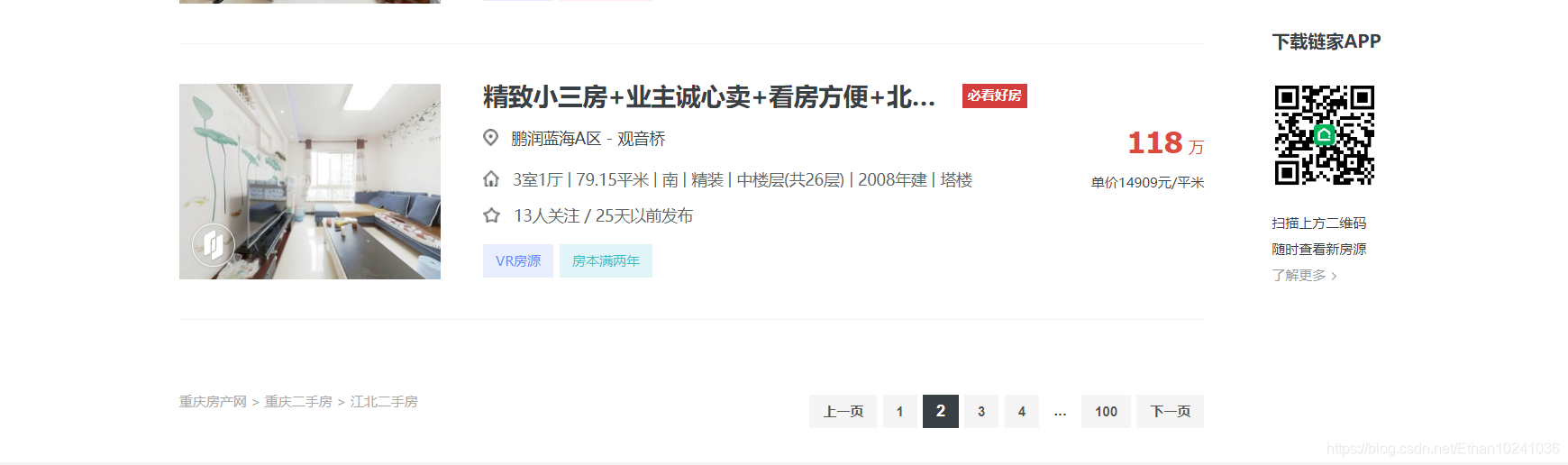
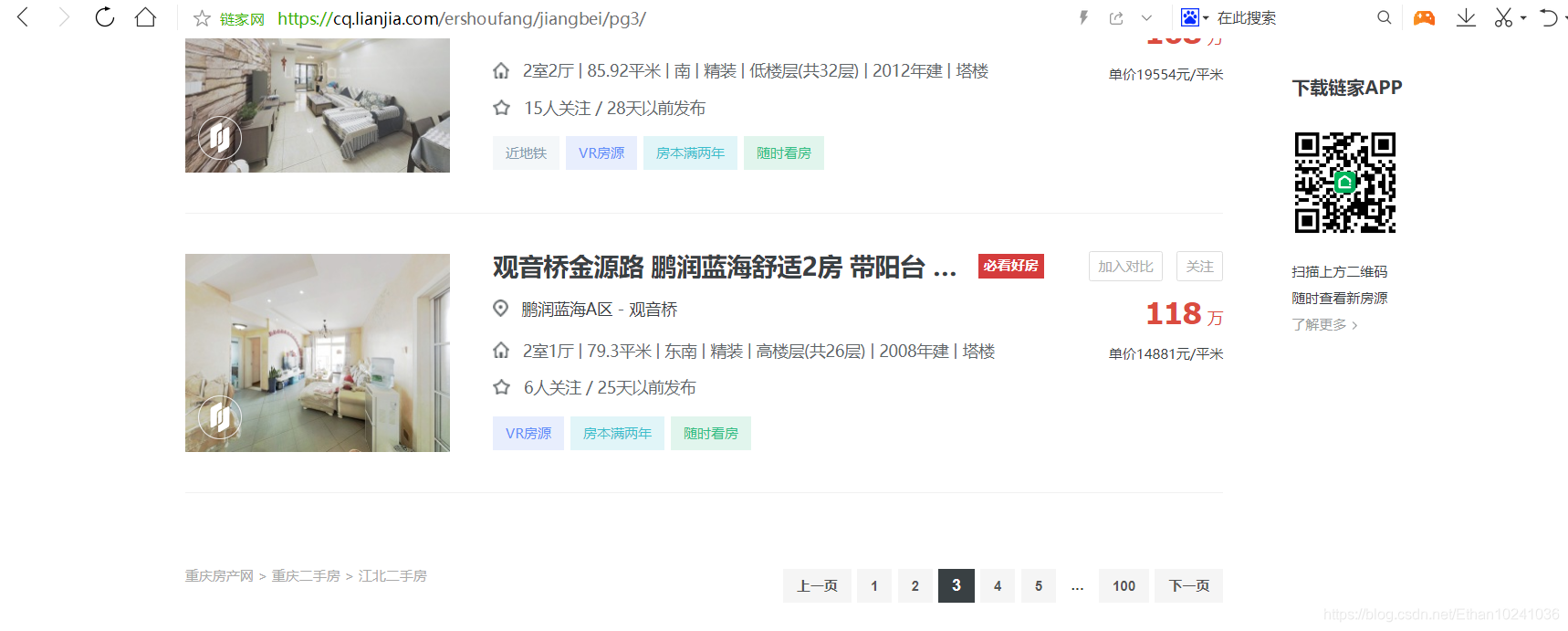
我这里筛选信息是区域:江北,然后选取区域后,最多可以显示100页,每页有房源30条,我现在是处于第二页和第三页,所以网页URL分别是是https://cq.lianjia.com/ershoufang/jiangbei/pg2/
https://cq.lianjia.com/ershoufang/jiangbei/pg3/
网页URL包含了筛选的区域即jiangbei,还有第二页pg2和第三页pg3,这就是网页URL变化的规律(如果要爬取南岸区的在售二手房房源信息,可以把jiangbei改成nanan)。
开始爬取
爬虫就是抓取网页解析的数据,然后提取自己想要的信息
1.解析网页,这里是用的是BeautifulSoup解析网页
URL = "https://cq.lianjia.com/ershoufang/jiangbei/pg2"
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3766.400 QQBrowser/10.6.4163.400"}
res = requests.get(URL, headers=header)
soup = BeautifulSoup(res.text, "lxml")
2.我们先爬取江北第二页30条房源的标题信息(鼠标悬在所选信息上,单击右键,点检查就可以看到网页代码)
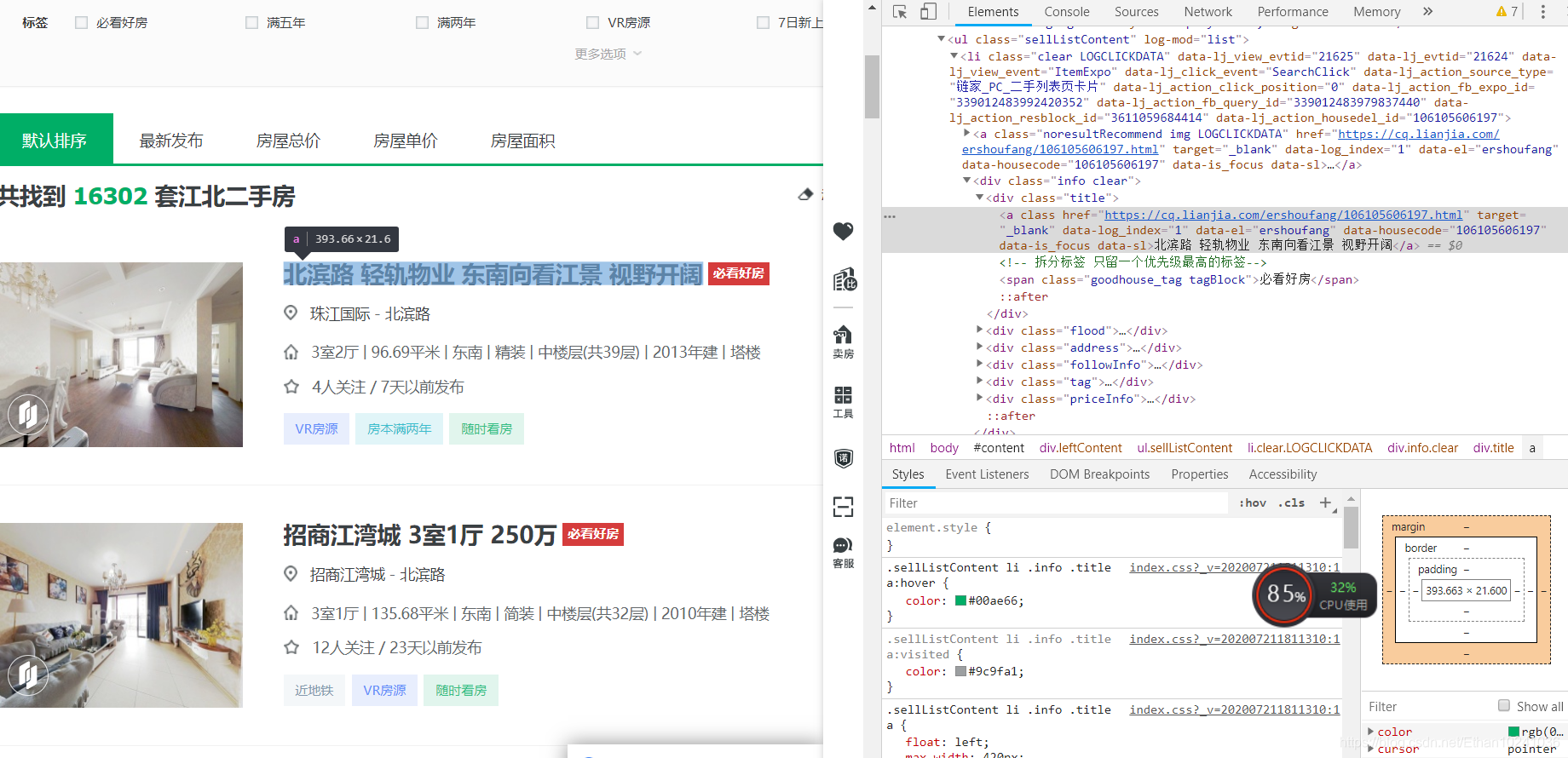
可以看到,标题信息是在div class="title"下面的,抓取第一个房源标题信息
title = soup.select(".title")[1].text
抓取第二个房源标题信息
title = soup.select(".ti 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









