







redis之集群
现状问题
- redis提供的服务OPS可以达到10万/秒,当前业务OPS已经达到20万/秒
- 内存单机容量达到256G,当前业务需求内存容量1T
- 使用集群的方式可以快速解决上述问题
集群架构
- 集群就是使用网络将诺干台计算机联通起来,并提供统一管理方式,使其对外呈现单机的服务效果
集群的作用
- 分散单台服务器的访问压力,实现负载均衡
- 分散单台服务器的存储压力,实现可扩展性
- 降低单台服务器宕机带来的业务灾难
集群的结构设计
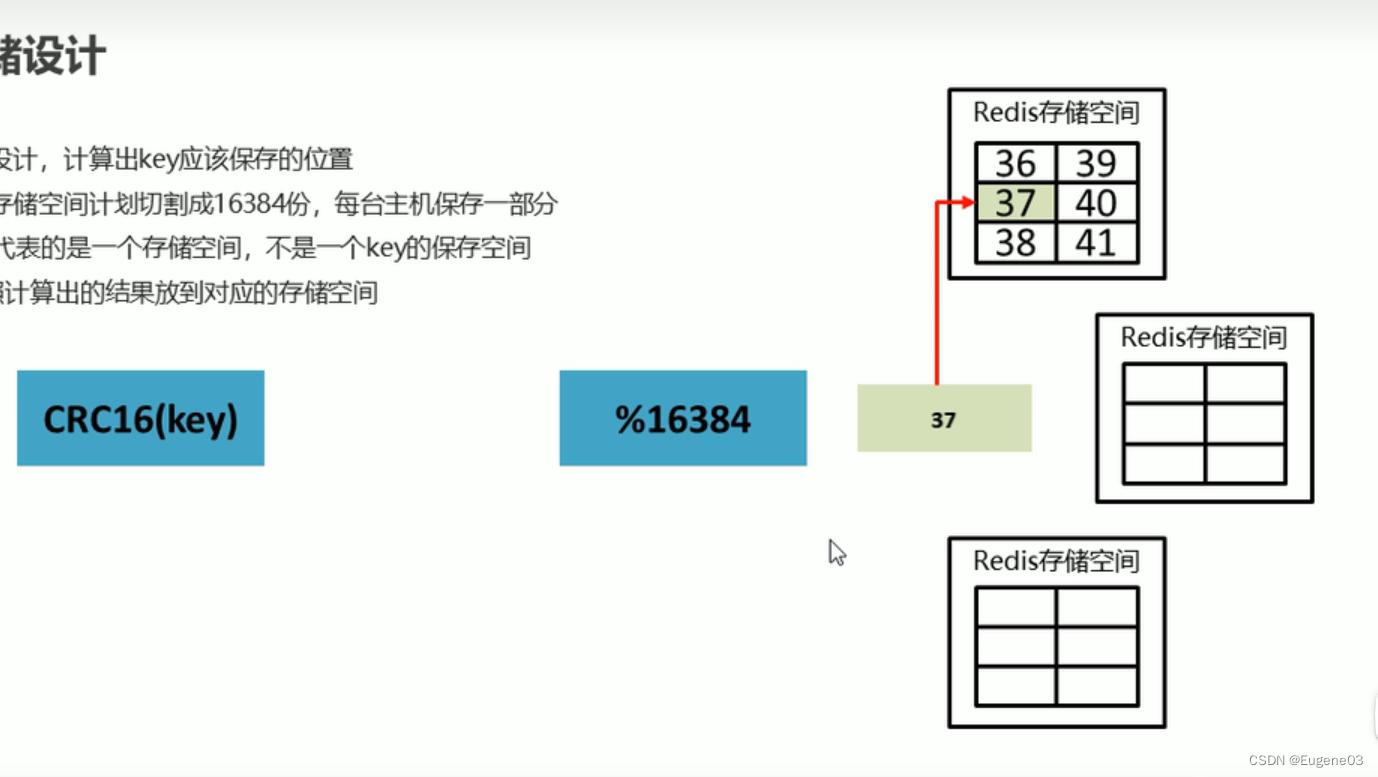
数据存储设计
- 通过算法设计,计算出key应该保存的位置
- 将所有的存储空间计划分割成16238份,每台主机保存一部分
- 每份代表的一个存储空间(槽),不是key的保存空间
- 将key按照计算出的结果放到对应的存储空间
假定我们现在增加一台机器,这些存储的数据以及空间应该如何分配呢?
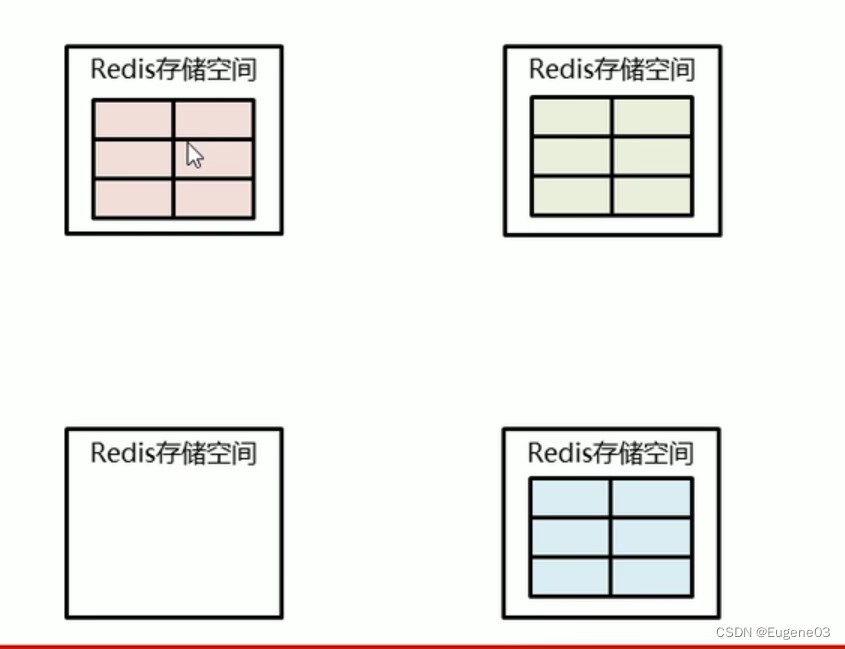
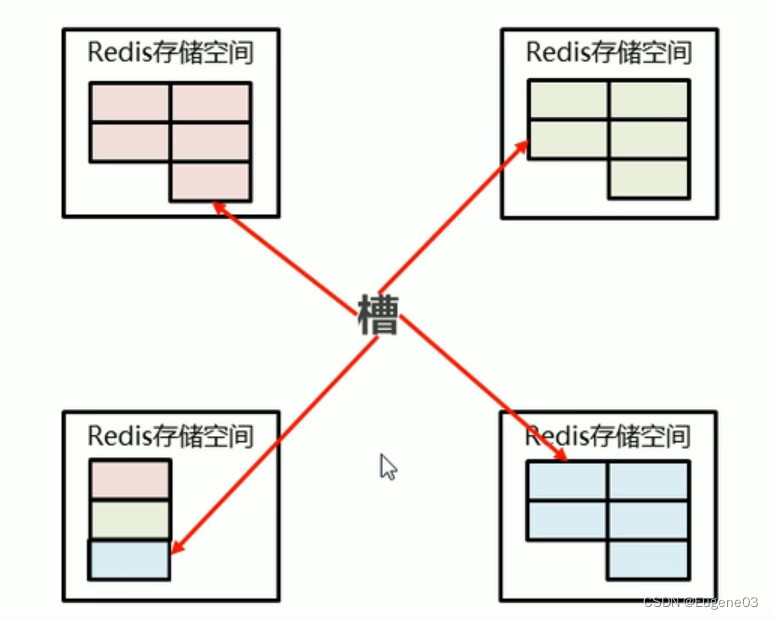
一台机器分一些槽出来给新的机器,所谓的增加机器和删除机器,改变槽所存储的机器即可
增强可扩展性
集群内部通讯设计
- 各个数据库相互通信,保存各个库中槽的编号数据
- 一次命中,直接返回
- 一次为命中,告知具体位置
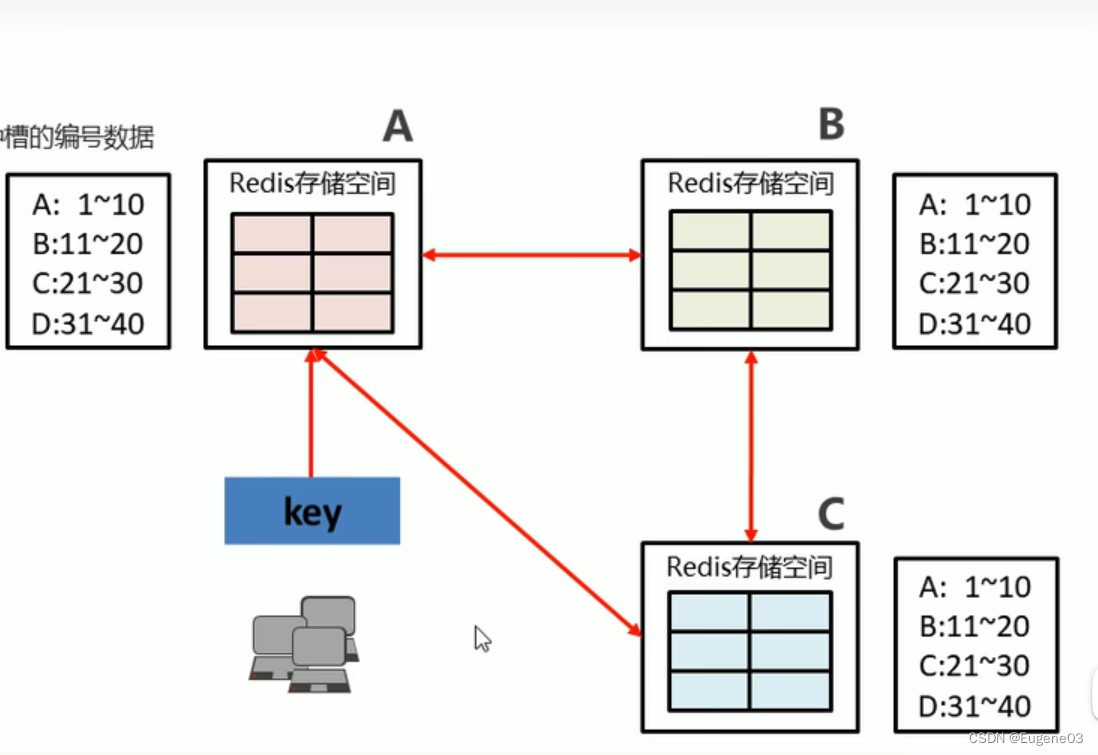
此时有一台客户端查找key,首先会通过hash算法计算出key对应的槽编号,然后在哈希环上找到对应的机器,检查这台机器上是否有对应的槽(由于可能进行了机器的增加、删除,机器上的槽会被添加到不同机器上)
如果这台机器有key对应的槽,直接查找返回;如果没有,则查找每台机器槽编号和机器的记录,然后再到对应机器取即可
集群搭建
Cluster配置
设置加入cluster,成为其中的节点
cluster-enabled yes|no
cluster配置文件名,该文件属于自动生成,仅用于快速查找文件并查询文件内容
cluster-config-file <filename>
节点服务响应超时时间,用于判定该节点是否下线或切换为slave
cluster-node-timeout <milliseconds>
master连接的slave最小数量
cluster-migration-barrier <count>

以集群节点
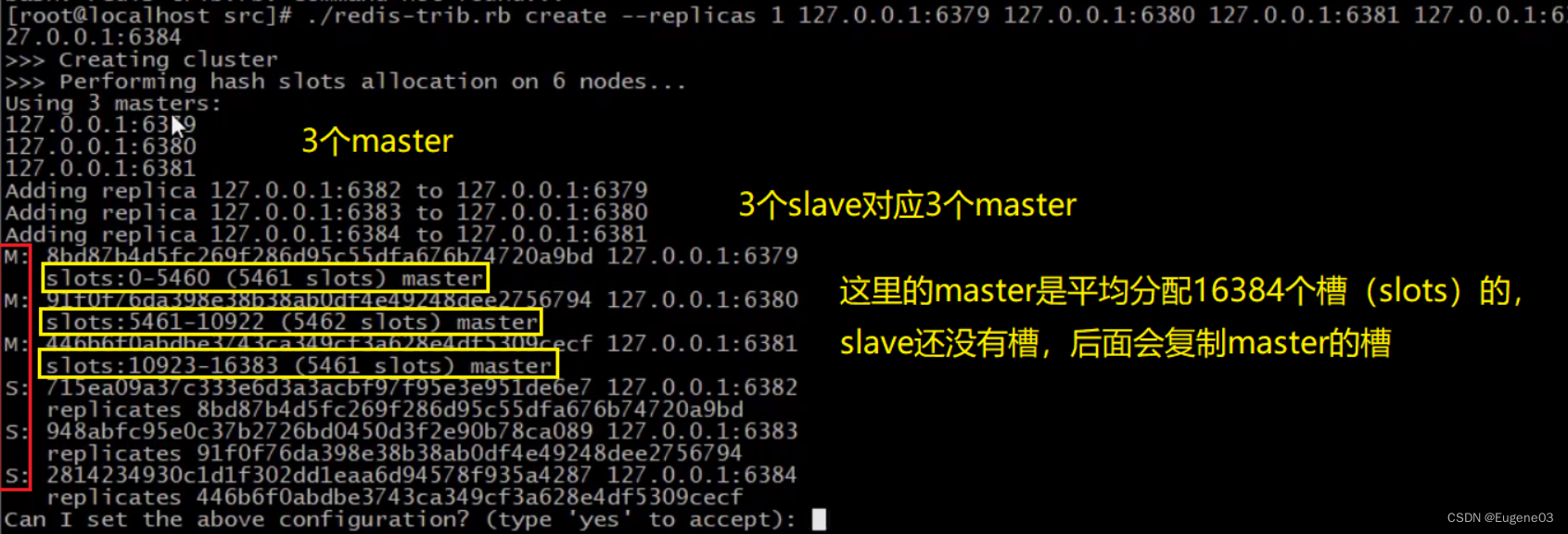
这是一个一个的节点,我们需要把他们连在一起,在src目录下有一个redis-trib.rb的可执行程序(这个文件执行需要安装ruby)
# 这里的n表示1个master对应n个slave
# 后面的ip:port表示master和slave的信息,master和slave的数量需要和前面的n对应
# 假设n=1,写了6组ip:port,则表示前3个为master,后3个为slave,实现1主1从
# 假设n=2,写了9组ip:port,则表示前3个为master,后6个为slave,实现1主2从
./redis-trib.rb create --replicas n ip1:port1 ip2:port2 ....
在src里面操作(linux下)
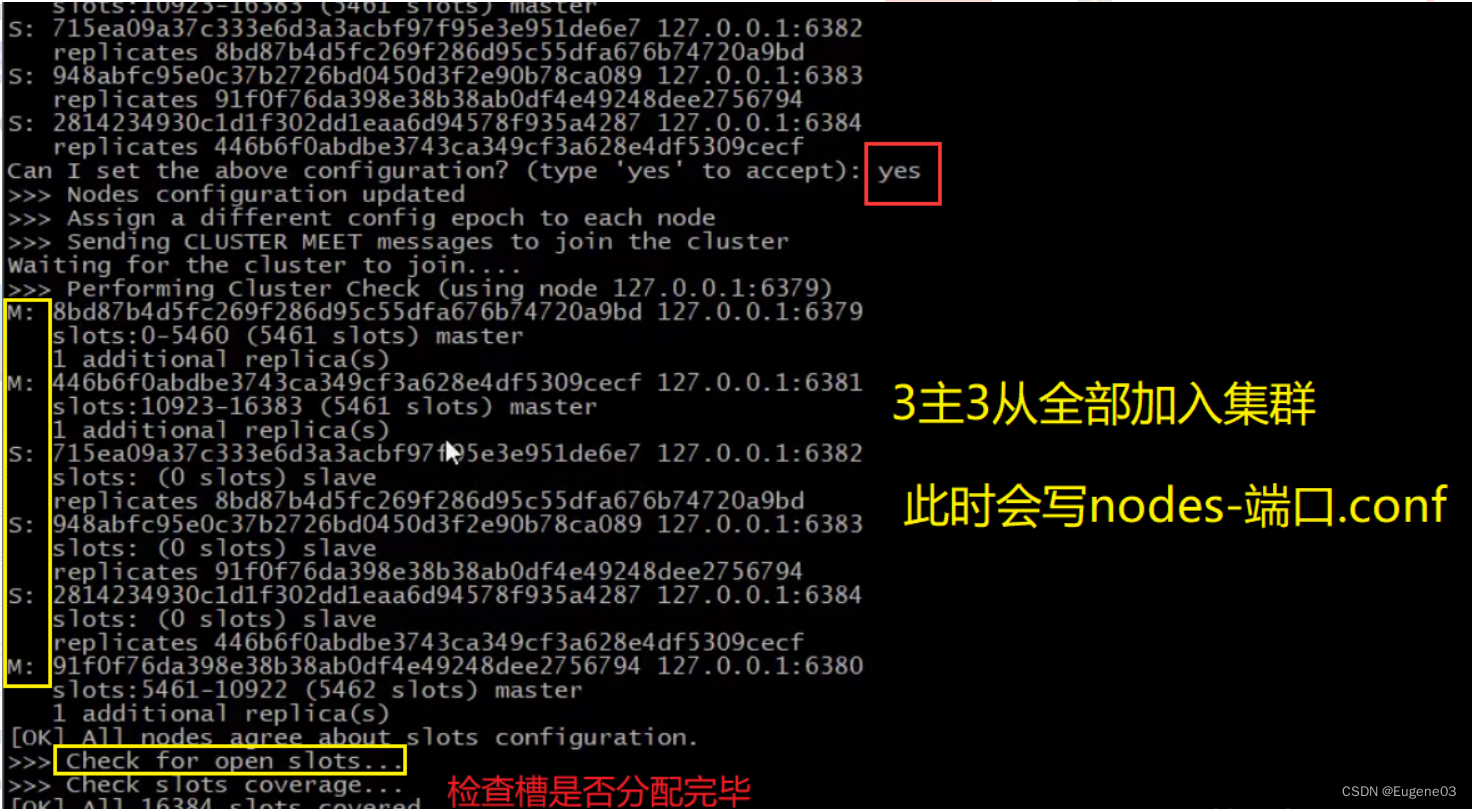
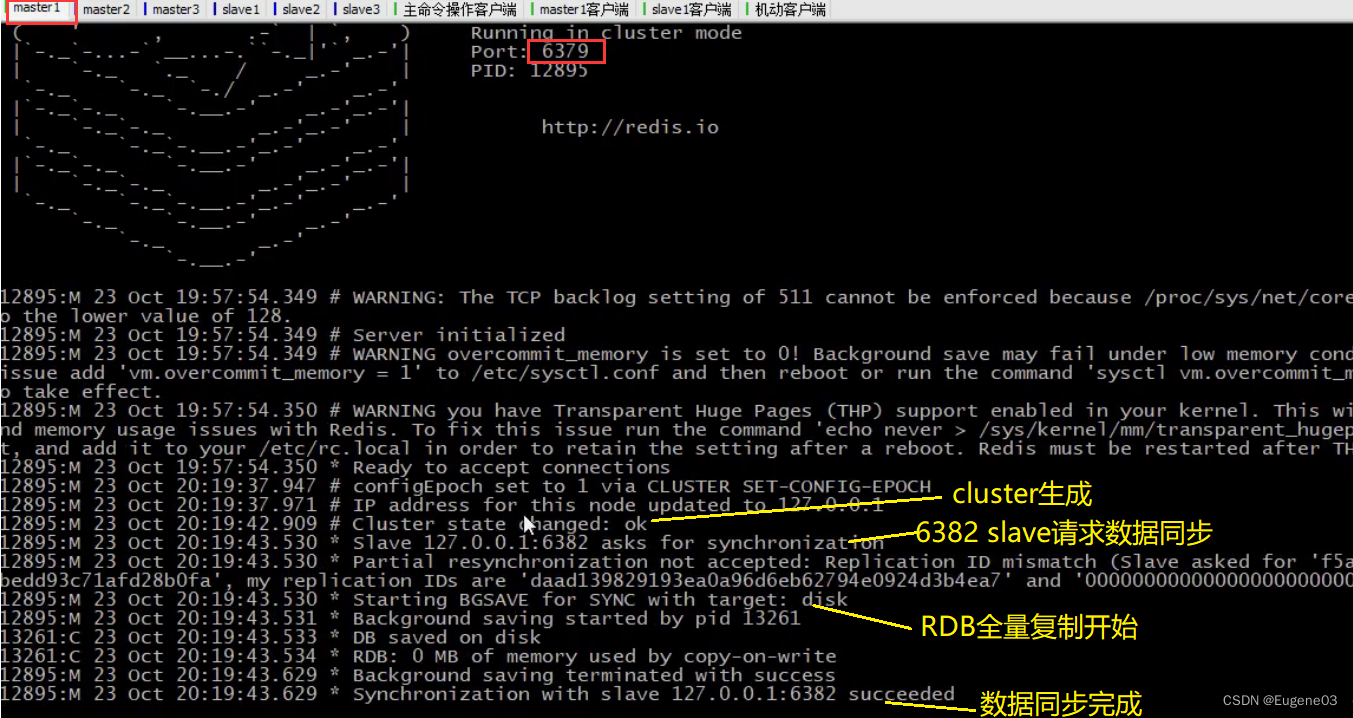
cluster连接在一起后,集群就配置好了,此时nodes-端口.conf就发生了改变。我们看一下master 6379对应的节点配置文件
集群存取数据
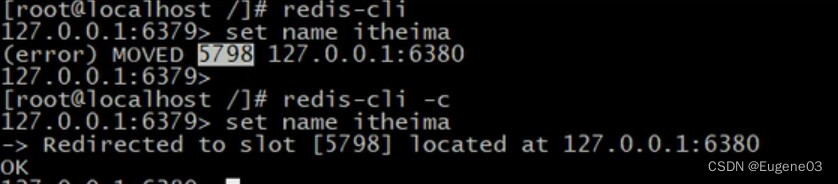
我们连接上6379端口的redis服务器后,想要在6379服务器上放数据,可通过CRC算法和模16384计算出itheima这个数据应该放在5798号槽,而这个槽在6380机器上,不允许我们放在6379机器上
解决办法 使用 -c参数,专门操作集群的
如果我们使用的机器上与槽存放的机器相同,就不会发生重定向,而是直接取出来
集群最大的优势并不是能在多台机器存放数据,而是集群能够很好的解决宕机带来的业务灾难
- slave下线后,与其对应的master会将其标记为下线状态,同时通知集群中其他机器该slave下线;待其上线后,再与其进行数据同步,然后通知集群中其他的机器该slave的上线信息
- 当master1下线后,对应的slave1会尝试连接,超时后自己成为新的master,然后通知集群中其他的机器,master1下线以及自己成为master的消息,master1的状态被标记为master fail;6379重新上线时,会成为slave,并和自己的master进行数据同步
Cluster节点操作命令
查看集群节点信息
cluster nodes
进入一个从节点redis,切换其主节点
cluster replication <master-id>
发现一个新节点,新增主节点
cluster meet ip:port
忽略一个没有slot的节点
cluster forget
手动故障转移
cluster failover
















 90
90











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









