







首先我们先使用传统方法写一个求斐波拉契数列的递归行数
<script>
function fib(n){
return n <=2 ? 1: fib(n - 1) + fib(n - 2);
}
var fib = fib(5);
console.log(fib);
</script>
这样,我们很快就能求出来,表面上看代码上没什么毛病,接下来,我们就来统计一下函数执行的次数
<script>
//用于统计执行函数的个数
var count = 0;
function fib(n){
count ++;
if (n <= 2){
return 1;
}
return fib(n - 1) + fib(n - 2);
}
var fibs = fib(5); //分别使用5、10、20进行测试
console.log(fibs);
console.log("执行次数:" + count);
</script>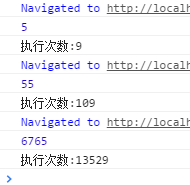
由以上我们可以发现执行次数随着数字增大的数据量是非常大的,那么是什么原因导致了执行次数如此庞大呢?
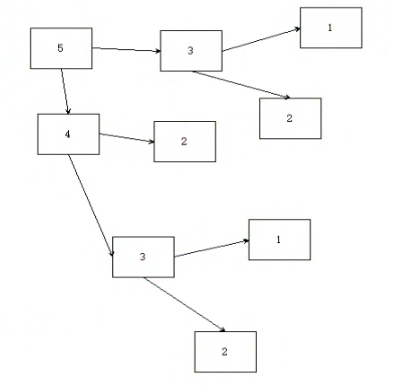
如上图,当我们需要求第五个数的时候,首先我们需要求出第三、四个数;
当计算第三个数时候需要求出之前两个数,即第一个数和第二个数
当计算第四个数时候需要重复求出第三个数还有第二个数,这一步和上面的步骤一样,但还是需要重复计算。
当数据量越来越大时,重复计算的数据量就越来越大,这样一来,调用的次数就越来越多。这就是传统递归所存在的问题。
那么我们该怎么解决呢?
我们这时就需要引入一个概念,缓存,第一次计算的时候先将求得的数存入缓存中,在第2以上执行时,先判断缓存中是否存在这个数,如果没有,继续计算,如果有,直接从缓存中取。
代码实现:
<script>
//定义一个缓存数组,存储已经计算出来的斐波那契数
//计算的步骤
//1.先从cache数组中去取想要获取的数字
//2.如果获取到了,直接使用
//3.如果没有获取到,就去计算,计算完之后,把计算结果存入cache,然后将结果返回
//统计执行次数
var count = 0;
//创建一个闭包,防止外部修改cache数组,提高安全性
function createFib(){
//用于存储数据
var cache = [];
function fib(n){
count++;
//如果缓存中有数据,直接返回
if (cache[n] != undefined){
return cache[n];
}
//如果缓存中没有就计算
if(n <= 2){
//将计算结果存入数组
cache[n] = 1;
return 1;
}
var temp = fib(n - 1) + fib(n - 2);
//将结果存入数据
cache[n] = temp;
return temp;
}
return fib;
}
</script>我们继续用第5、10、20个数进行测试
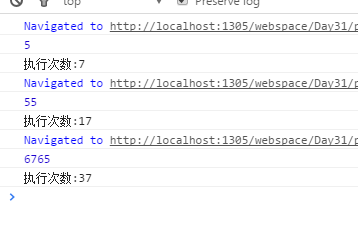
由此我们可以看到,执行次数大大减少,效率提高了不止一个点。















 347
347











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









