







一、基本符号
- \b:只匹配一个位置。它的前一个字符和后一个字符不全是\w
- \w:匹配字母或数字或下划线或汉字等
- .:匹配除了换行符以外的任意字符
- *:代表前面的内容可以连续重复任意次。0次或多次
- +:匹配1个或重复多次。1次或多次
- ?:0次或1次
- *?:重复任意次,但尽可能少,最简
- +?:重复1次或多次,尽可能少
- ??:重复0次或1次,尽可能少
- {n,m}:重复n到m次,尽可能少
- .*:代表任意数量的不包含换行的字符
- \d{2,5}:代表前面的数字\d必须连续重复2次至5次
- {n, } :n次或多次
- \s:匹配任意的空白符,包括空格,制表符Tab,换行符,中文全角空格等
- ^和 $:匹配开头和结尾,如^\d{2,5}$,则整个输入必须是2到5个数字,不能有其他字符;若没有^和$,则只要输入的字符里面有2到5位数字即可,其他字符不管
- ^\w+:匹配一行的第一个单词
二、转义符号
- \. 和 \* 和 \\:转义字符,匹配“.”,“*”,“\”字符本身,而非元字符
- [.?!]:匹配“.”或“?”或“!”
三、反义符号
- \W :匹配任意不是字母,数字,下划线,汉字的字符
- \S:匹配任意不是空白符的字符
- \D:匹配任意非数字的字符
- \B:匹配不是单词开头或结束的位置
- [^abcd]:匹配除了abcd这几个字符以外的任意字符,”^”表示非
- <a[^>]+>:匹配用尖括号括起来的以a开头的字符串
四、后向引用
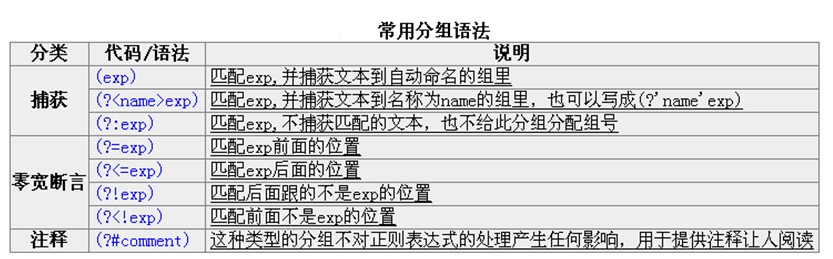
使用小括号指定一个子表达式,匹配这个子表达式的文本可以在表达式或其他程序中进一步处理。每个分组会自动拥有一个组号,从左往右,从1开始。
\b(\w+)\b\s+\1\b:这个表达式首先是一个单词,也就是单词开始处和结束处之间的多于一个的字母或数字(\b(\w+)\b),这个单词会被捕获到编号为1的分组中,然后是1个或几个空白符(\s+),最后是分组1中捕获的内容(也就是前面匹配的那个单词)(\1)。
(?<Word>\w+)(或者把尖括号换成'也行:(?'Word'\w+)):可以自己指定子表达式的组名为“word”。
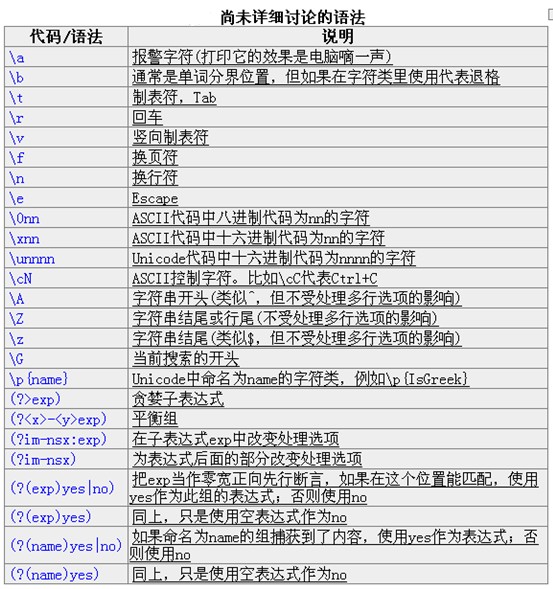
比如\b\w+(?=ing\b),匹配以ing结尾的单词的前面部分(除了ing以外的部分),如查找I'm singing while you're dancing.时,它会匹配sing和danc。
五、示例
- 匹配邮箱(可为空)
(1)用于前台:/^([\w_-]+(?:\.[\w_-]+)*@(?:[\w](?:[\w-]*[\w])?\.)+[\w](?:[\w-]*[\w])?)|$/
(2)用于后台:^([\\w_-]+(?:\\.[\\w_-]+)*@(?:[\\w](?:[\\w-]*[\\w])?\\.)+[\\w](?:[\\w-]*[\\w])?)|$
(3)匹配特殊字符:/^([\\w!#$%&'*+/=?^_`{|}~-]+(?:\\.[\\w!#$%&'*+/=?^_`{|}~-]+)*@(?:[\\w](?:[\\w-]*[\\w])?\\.)+[\\w](?:[\\w-]*[\\w])?)|$/
【解说】
(1)必须指定开头:否则“#aa@qq.com”也可匹配。必须指定结尾,否则“ ”空格或“#”也可匹配(因为前面匹配 | ,为空,又不限制结尾)。
(2)后台使用:(不能加“/",否则不匹配)
(3)Pattern pattern = Pattern.compile("。。。。"); Matcher matcher = pattern.matcher(。。。。); if(!matcher.matches()){ 。。。。。 }
首先[ ]+:字母与一些特殊字符,重复1次或多次
接着(?:expr)*:匹配expr重复0次到多次,expr是“.”加上字母或特殊字符的1次到多次的重复
紧跟一个“@”符号。
接着匹配:字符开头,紧跟至少一个字符的字符串(0到1个),紧跟“.”,这样格式的1次到多次的重复
紧跟一个字符。
最后匹配至少一个字符的字符串(0到1次)。
或者”|"匹配空。
- 匹配4位年份
3. 匹配电话
^([0-9]{2,4}\\-)?([2-9][0-9]{6,7})([-#][0-9]{1,4})?$
【解说】
目前电话一般7~8位,(香港都是8位)
前面区号国内一般4位,台湾是2位
后面分机号,可用“-”或“#”分割。
4. 匹配中文
[\u4e00-\u9fa5]
5. 匹配中文,英文字母和数字及_:^[\u4e00-\u9fa5_a-zA-Z0-9]+$
6. 一个正则表达式,只含有汉字、数字、字母、下划线不能以下划线开头和结尾:
^(?!_)(?!.*?_$)[a-zA-Z0-9_\u4e00-\u9fa5]+$
【解说】
(?!_):不能以_开头
(?!.*?_$):不能以_结尾
7. 最长不得超过7个汉字,或14个字节(数字,字母和下划线)正则表达式
^[\u4e00-\u9fa5]{1,7}$|^[\dA-Za-z_]{1,14}$















 351
351











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









