






实现思路
1、首先要找到你想要抓取信息的网站地址,通过浏览器F12观察接口,如果只是抓取文本信息,只需要找到对应返回json数据的接口。
2、通过java代码发送http请求获取对应的数据进行保存即可,如果是抓取网页上的信息,就需要观察html页面元素,根据dom节点进行解析再进行保存。
其实python实现思路也是一样,只不过python代码实现起来更简洁,在这里就不做演示了,感兴趣的朋友可以自己使用python实现一个爬虫程序。
应用场景
当需要在网页上获取大量的数据时,如果通过人工进行点击保存下载操作太费劲了,,比如获取图片素材、小说等,都可以利用代码实现。
java爬虫示例
今天就教大家利用java代码实现一段爬虫程序,获取网站上的图片。
目标网站:高清图片,堆糖,美图壁纸兴趣社区
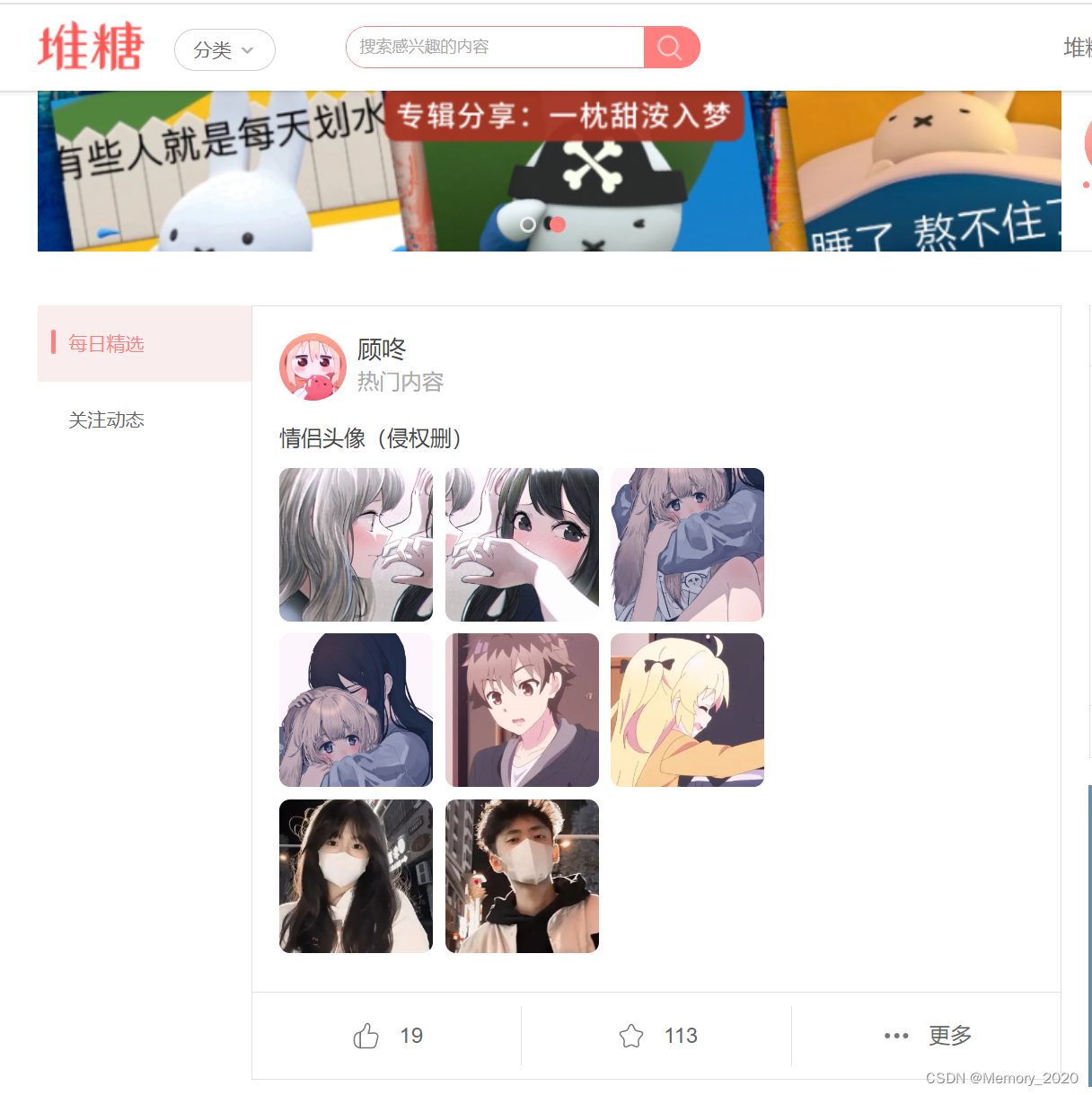
主程序类
package com.memory.flink;
import org.apache.flink.table.expressions.E;
import java.io.*;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.Set;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import java.util.stream.Collectors;
public class MainDownLoad {
// 地址
private static final String URL = "http://www.tooopen.com/view/1439719.html";
// 获取img标签正则
private static final String IMGURL_REG = "<img.*src=(.*?)[^>]*?>";
// 获取src路径的正则
private static final String IMGSRC_REG = "[a-zA-z]+://[^\\s]*";
// TODO 数据集ID
final static long dataSetId = 85597077;
public static void download(Long dataSetId,String resourceName,String filePath) {
filePath = filePath +resourceName+"//"+ dataSetId + "/";
try {
MainDownLoad cm=new MainDownLoad();
Set<String> imageUrls = DownloadImageFormDuiTang.getImageUrls(dataSetId);
List<String> imageList = new ArrayList(imageUrls);
//下载图片
cm.Download(imageList,filePath);
}catch (Exception e){
e.printStackTrace();
}
}
public static void main(String[] args) {
try {
MainDownLoad cm=new MainDownLoad();
Set<String> imageUrls = DownloadImage.getImageUrls(dataSetId);
List<String> imageList = new ArrayList();
for (String imageUrl : imageUrls) {
//获得html文本内容
String HTML = cm.getHtml(imageUrl);
//获取图片标签
List<String> imgUrl = cm.getImageUrl(HTML);
// 筛选blog图片
List<String> mainImageUrl = imgUrl.stream().filter(url -> url.indexOf("blog")!=-1).collect(Collectors.toList());
//获取图片src地址
List<String> imgSrc = cm.getImageSrc(mainImageUrl);
for (String s : imgSrc) {
System.out.println(s);
imageList.add(s);
}
// break;
}
//下载图片
// cm.Download(imageList,filePath);
}catch (Exception e){
e.printStackTrace();
}
}
//获取HTML内容
private String getHtml(String url)throws Exception{
URL url1=new URL(url);
URLConnection connection=url1.openConnection();
InputStream in = null;
InputStreamReader isr = null;
BufferedReader br = null;
try {
in=connection.getInputStream();
isr=new InputStreamReader(in);
br=new BufferedReader(isr);
}catch (Exception e){
System.err.println("获取资源出错。" + e.getMessage());
}
String line;
StringBuffer sb=new StringBuffer();
while((line=br.readLine())!=null){
sb.append(line,0,line.length());
sb.append('\n');
}
br.close();
isr.close();
in.close();
return sb.toString();
}
//获取ImageUrl地址
private List<String> getImageUrl(String html){
Matcher matcher=Pattern.compile(IMGURL_REG).matcher(html);
List<String>listimgurl=new ArrayList<String>();
while (matcher.find()){
listimgurl.add(matcher.group());
}
return listimgurl;
}
//获取ImageSrc地址
private List<String> getImageSrc(List<String> listimageurl){
List<String> listImageSrc=new ArrayList<String>();
for (String image:listimageurl){
Matcher matcher=Pattern.compile(IMGSRC_REG).matcher(image);
while (matcher.find()){
listImageSrc.add(matcher.group().substring(0, matcher.group().length()-1));
}
}
return listImageSrc;
}
//下载图片
private void Download(List<String> listImgSrc, String filePath) {
try {
File file = new File(filePath);
if (!file.exists()) {
file.mkdirs();
}
//开始时间
Date begindate = new Date();
for (String url : listImgSrc) {
if (url.indexOf(".gif_jpeg") != -1){
url = url.replace(".gif_jpeg",".gif");
}
//开始时间
Date begindate2 = new Date();
String imageName = url.substring(url.lastIndexOf("/") + 1, url.length());
URL uri = new URL(url);
InputStream in = uri.openStream();
FileOutputStream fo = new FileOutputStream(new File(filePath+imageName));
byte[] buf = new byte[1024];
int length = 0;
System.out.println("开始下载:" + url);
while ((length = in.read(buf, 0, buf.length)) != -1) {
fo.write(buf, 0, length);
}
in.close();
fo.close();
System.out.println(imageName + "下载完成");
//结束时间
Date overdate2 = new Date();
double time = overdate2.getTime() - begindate2.getTime();
System.out.println("耗时:" + time / 1000 + "s");
}
Date overdate = new Date();
double time = overdate.getTime() - begindate.getTime();
System.out.println("总耗时:" + time / 1000 + "s");
} catch (Exception e) {
e.printStackTrace();
}
}
}获取每个章节的图片接口信息
package com.memory.flink;
import cn.hutool.http.HttpUtil;
import cn.hutool.json.JSONArray;
import cn.hutool.json.JSONObject;
import cn.hutool.json.JSONUtil;
import java.util.*;
public class DownloadImage {
static Set<Integer> imageIds = new HashSet<>();
// static List<Integer> imageIds = new ArrayList<>();
public static void main(String[] args) {
// String url = "https://www.duitang.com/napi/blog/list/by_album/?album_id=108374401&limit=24&include_fields=top_comments%2Cis_root%2Csource_link%2Cbuyable%2Croot_id%2Cstatus%2Clike_count%2Clike_id%2Csender%2Creply_count&start=1&_=1648521141702";
long dataSetId = 85597077;
Set<Integer> imageIds = getImageIds(dataSetId);
String baseUrl = "https://www.duitang.com/blog/?id=";
for (Integer id : imageIds) {
String imageUrl = baseUrl + id;
System.out.println(imageUrl);
// String result2 = HttpUtil.get(url, paramMap);
}
}
/**
* 根据数据集ID 获取集合
* @param dataSetId
* @return
*/
public static Set<String> getImageUrls (long dataSetId) {
Set<Integer> imageIds = getImageIds(dataSetId);
Set<String> result = new HashSet();
String baseUrl = "https://www.duitang.com/blog/?id=";
for (Integer id : imageIds) {
String imageUrl = baseUrl + id;
// TODO 关闭打印
// System.out.println(imageUrl);
// String result2 = HttpUtil.get(url, paramMap);
result.add(imageUrl);
}
return result;
}
public static Set<Integer> getImageIds (long album_id) {
String url = "https://www.duitang.com/napi/blog/list/by_album/";
Map<String, Object> paramMap = new HashMap<>();
paramMap.put("album_id", album_id);
paramMap.put("include_fields", "top_comments,is_root,source_link,buyable,root_id,status,like_count,like_id,sender,reply_count");
paramMap.put("limit", 100);
paramMap.put("start", 0);
paramMap.put("_", System.currentTimeMillis());
// 无参GET请求
//String result = HttpUtil.get(url);
// 带参GET请求
String result2 = HttpUtil.get(url, paramMap);
Map map = JSONUtil.toBean(result2, Map.class);
JSONObject data = (JSONObject)map.get("data");
JSONArray jsonArray = (JSONArray)data.get("object_list");
for (Object o : jsonArray) {
JSONObject image = (JSONObject)o;
Integer id = (Integer)image.get("id");
imageIds.add(id);
}
// 第二页
paramMap.put("start", 100);
result2 = HttpUtil.get(url, paramMap);
map = JSONUtil.toBean(result2, Map.class);
data = (JSONObject)map.get("data");
jsonArray = (JSONArray)data.get("object_list");
for (Object o : jsonArray) {
JSONObject image = (JSONObject)o;
Integer id = (Integer)image.get("id");
imageIds.add(id);
}
paramMap.put("start", 200);
result2 = HttpUtil.get(url, paramMap);
map = JSONUtil.toBean(result2, Map.class);
data = (JSONObject)map.get("data");
jsonArray = (JSONArray)data.get("object_list");
for (Object o : jsonArray) {
JSONObject image = (JSONObject)o;
Integer id = (Integer)image.get("id");
imageIds.add(id);
}
paramMap.put("start", 300);
result2 = HttpUtil.get(url, paramMap);
map = JSONUtil.toBean(result2, Map.class);
data = (JSONObject)map.get("data");
jsonArray = (JSONArray)data.get("object_list");
for (Object o : jsonArray) {
JSONObject image = (JSONObject)o;
Integer id = (Integer)image.get("id");
imageIds.add(id);
}
System.out.println(jsonArray.size());
System.out.println(imageIds);
return imageIds;
}
}
获取图片url
package com.memory.flink;
import cn.hutool.http.HttpUtil;
import cn.hutool.json.JSONArray;
import cn.hutool.json.JSONObject;
import cn.hutool.json.JSONUtil;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import java.util.Set;
public class DownloadImageFormDuiTang {
final static String baseUrl = "https://www.duitang.com/napi/album/list/by_search/";
static Set<Long> dataSetIds = new HashSet<>();
static Set<String> imageUrls = new HashSet<>();
final static String resourceName = "动漫场景";
final static String filePath = "C://material//";
public static void main(String[] args) {
long start = System.currentTimeMillis();
Map<String, Object> paramMap = new HashMap<>();
paramMap.put("kw", resourceName);
paramMap.put("include_fields", "top_comments,is_root,source_link,item,buyable,root_id,status,like_count,like_id,sender,album,reply_count,favorite_blog_id");
paramMap.put("after_id",0);
paramMap.put("limit",10);
paramMap.put("type", "feed");
paramMap.put("_type", "");
paramMap.put("_", System.currentTimeMillis());
// 无参GET请求
//String result = HttpUtil.get(url);
// 带参GET请求
String result2 = HttpUtil.get(baseUrl, paramMap);
Map map = JSONUtil.toBean(result2, Map.class);
JSONObject data = (JSONObject)map.get("data");
JSONArray jsonArray = (JSONArray)data.get("object_list");
for (Object o : jsonArray) {
JSONObject image = (JSONObject)o;
Long id = Long.valueOf(image.get("id").toString());
dataSetIds.add(id);
}
// 1.获取数据集ID
// 2.根据数据集ID获取图片
for (Long datasetId : dataSetIds) {
MainDownLoad.download(datasetId,resourceName,filePath);
}
long end = System.currentTimeMillis();
System.out.println("下载资源完成,总耗时:" + (end-start) / 1000 + "s");
}
/**
* 根据数据集ID 获取集合
* @param dataSetId
* @return
*/
public static Set<String> getImageUrls (long dataSetId) {
Set<String> imageUrls = getImageIds(dataSetId);
return imageUrls;
}
public static Set<String> getImageIds (long album_id) {
Set<String> result = new HashSet<>();
String url = "https://www.duitang.com/napi/blog/list/by_album/";
Map<String, Object> paramMap = new HashMap<>();
paramMap.put("album_id", album_id);
paramMap.put("include_fields", "top_comments,is_root,source_link,buyable,root_id,status,like_count,like_id,sender,reply_count");
paramMap.put("limit", 100);
paramMap.put("start", 0);
paramMap.put("_", System.currentTimeMillis());
// 无参GET请求
//String result = HttpUtil.get(url);
// 带参GET请求
String result2 = HttpUtil.get(url, paramMap);
Map map = JSONUtil.toBean(result2, Map.class);
JSONObject data = (JSONObject)map.get("data");
JSONArray jsonArray = (JSONArray)data.get("object_list");
for (Object o : jsonArray) {
JSONObject image = (JSONObject)o;
JSONObject photo = (JSONObject)image.get("photo");
String imgUrl = (String)photo.get("path");
result.add(imgUrl);
}
// 第二页
paramMap.put("start", 100);
result2 = HttpUtil.get(url, paramMap);
map = JSONUtil.toBean(result2, Map.class);
data = (JSONObject)map.get("data");
jsonArray = (JSONArray)data.get("object_list");
for (Object o : jsonArray) {
JSONObject image = (JSONObject)o;
JSONObject photo = (JSONObject)image.get("photo");
String imgUrl = (String)photo.get("path");
result.add(imgUrl);
}
paramMap.put("start", 200);
result2 = HttpUtil.get(url, paramMap);
map = JSONUtil.toBean(result2, Map.class);
data = (JSONObject)map.get("data");
jsonArray = (JSONArray)data.get("object_list");
for (Object o : jsonArray) {
JSONObject image = (JSONObject)o;
JSONObject photo = (JSONObject)image.get("photo");
String imgUrl = (String)photo.get("path");
result.add(imgUrl);
}
paramMap.put("start", 300);
result2 = HttpUtil.get(url, paramMap);
map = JSONUtil.toBean(result2, Map.class);
data = (JSONObject)map.get("data");
jsonArray = (JSONArray)data.get("object_list");
for (Object o : jsonArray) {
JSONObject image = (JSONObject)o;
JSONObject photo = (JSONObject)image.get("photo");
String imgUrl = (String)photo.get("path");
result.add(imgUrl);
}
System.out.println(jsonArray.size());
System.out.println(result);
return result;
}
}
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











