






课程打卡凭证

数据集加载与处理
本实验使用了NLPCC2017的数据,主要内容是新闻正文及其摘要,共计50000个样本。
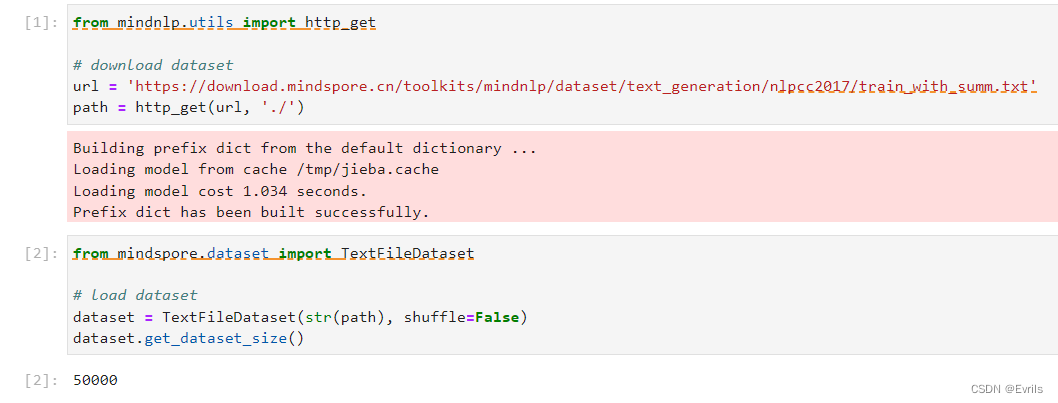
将数据划分为训练集和测试集。

定义数据集处理函数process_dataset,首先从原始数据集中提取文章和摘要字段,然后使用tokenizer对文章和摘要进行标记化、填充和截断,将数据集分成小批次并根据需要打乱数据,最后返回处理后的数据集,准备用于模型训练。
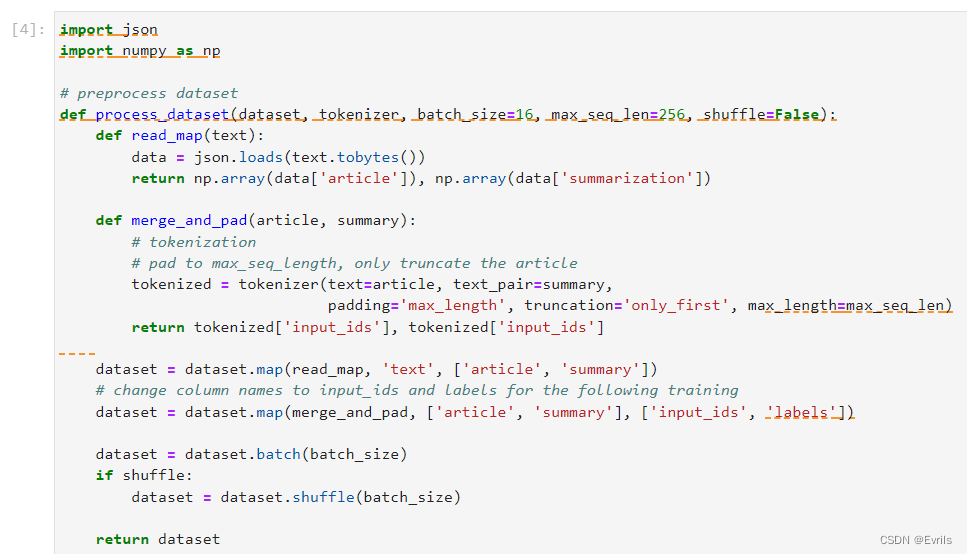
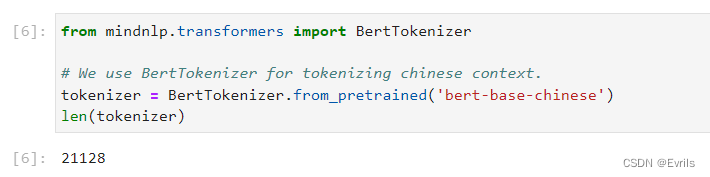
使用BertTokenizer替代GPT2中的Tokenizer。
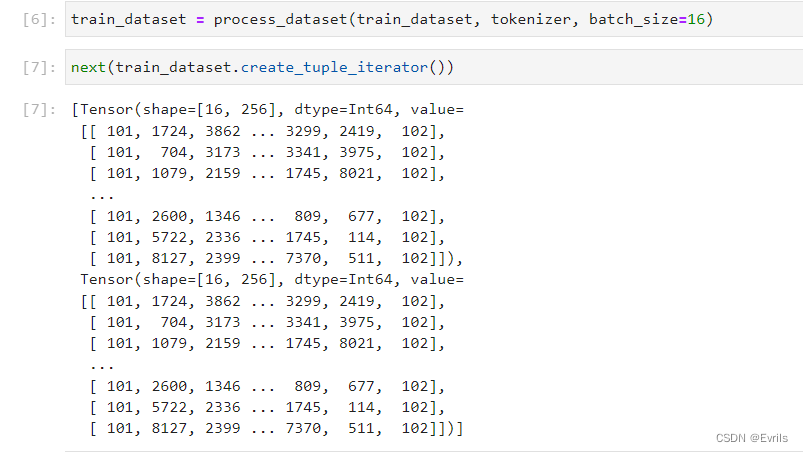
预处理训练数据集。
模型构建
自定义GPT2模型用于摘要生成。

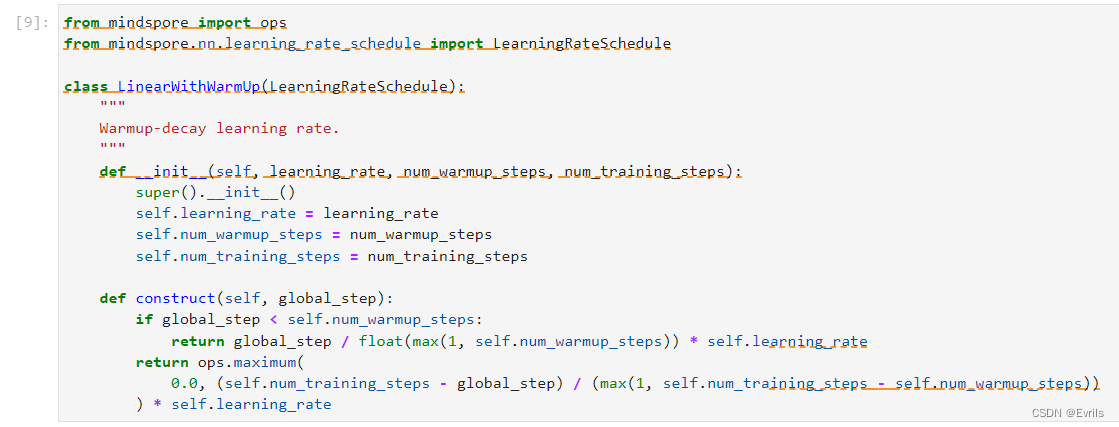
自定义学习率调度器。
模型训练
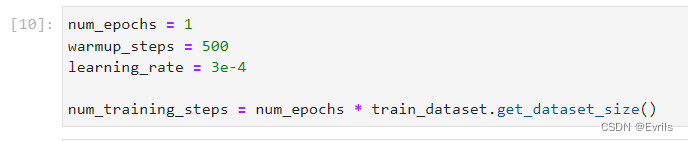
设置训练批次、预热步骤、学习率、训练步数等。
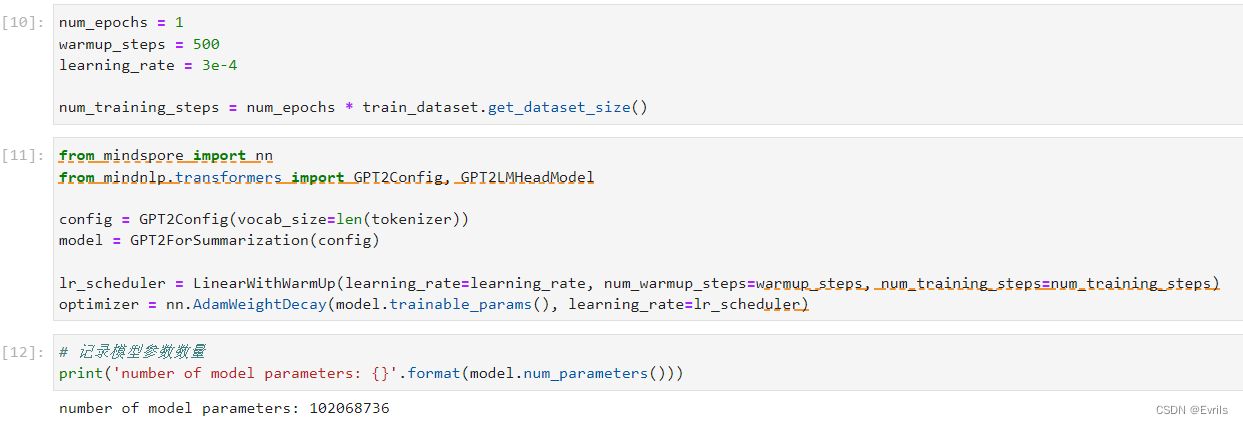
配置模型和优化器,记录模型参数数量。
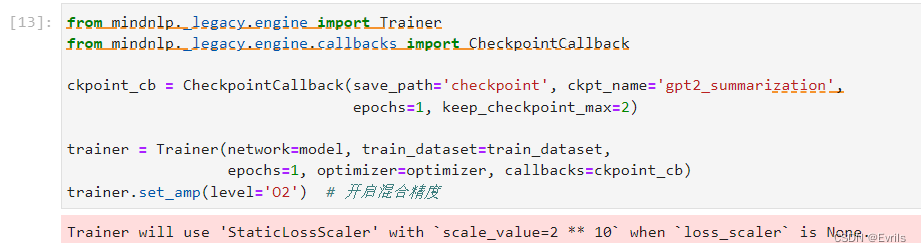
配置训练器。
开始训练模型。

为了追求快速收敛,loss反而越来越大。因此,这里将调整部分参数,重新训练模型,如下图所示。

















 415
415

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









