







数据独立性包括两个方面:物理独立性和逻辑独立性。
一、物理独立性理解
要理解数据独立性的含义,我们得搞清什么是非数据独立的。在旧的系统中(关系系统之前的和数据库系统之前的系统)实现的应用程序常常是数据依赖的。这也意味着,在二级存储中,数据的物理表示方式和有关的存取技术都是应用设计中要考虑的,而且,有关物理表示的知识和访问技术直接体现在应用程序的代码中。
例子:
假定有一个应用程序使用了一个学生信息文件,还假定文件在学号字段进行索引。在旧的系统中,该应用程序肯定知道存在索引,也知道记录顺序是根据索引定的,应用程序的内部结构是基于这些知识而设计的。特别地,各种数据访问的准确形式和应用程序的异常检验程序都很大程度上依赖于数据管理软件提供给应用程序的接口细节。
我们称这个例子中的应用程序是数据依赖的,因为一旦改变数据的物理表示会对应用程序产生非常强的影响。例如,用哈希算法来对例子重建索引后,对应用程序不做大的修改是不可能的。而且,这种情况下应用程序修改的部分恰恰是与数据管理软件密切联系的部分。这其中的困难与应用程序最初所要解决的问题毫不相关,而是由数据管理接口的特点所引起的。数据库系统中,应尽可能避免应用程序依赖于数据的情况。
这至少有以下两条原因:
- 不同的应用程序对相同的数据会从不同角度来看。例如,假定在企业建立统一的数据库之前有两个应用程序A和B。每一个都拥有包括客户余额的专有文件。假定A是以十进制存储的,而B是以二进制存储的。这时有可能要消除冗余,并把两文件统一起来。条件是DBMS可以而且能够执行以下必要的转换,即存储格式(可能是十进制或二进制或者其他的)和每个应用程序所采用的格式之间的转换。例如,如果决定以十进制存储数据,每次对B的访问都要转换成二进制。这是个非常细小的例子,数据库系统中应用程序所看到的数据和物理存储的数据之间可能是不同类型的。
- DBA必须有权改变物理表示和访问技术以适应变化的需要,而不必改变现有的应用程序。例如,新类型的数据可能加入到数据库中;有可能采纳新的标准;应用程序的优先级(因此相关的执行需求)可能改变;系统要添加新的存储设备,等等。如果应用程序是数据依赖的,这些改变会要求程序做相应的改变,这种维护的代价无异于创建一个新的应用。类似的情况甚至在都并不少见,如典型的Y2K问题,这对充分利用稀缺宝贵的资源是极其不利的。
二、逻辑独立性理解
数据的逻辑独立性是指数据与程序的逻辑独立性。
当数据的逻辑结构改变时,用户程序也可以不变。
总之,数据独立性的提出主要是数据库系统的客观要求。数据独立性可以定义成应用程序不会因物理表示和访问技术的改变而改变。当然,这意味着应用程序不应依赖于任何特定的物理表示和访问技术。
三、怎么实现
那么为什么会有三级模式?
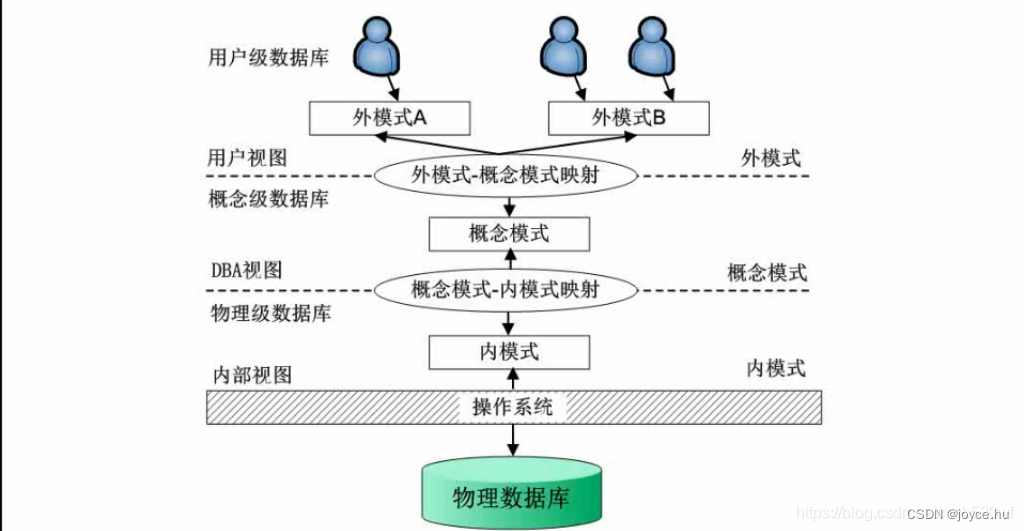
ANSI为了规范我们对数据库的使用,ANSI的数据库管理系统研究小组于1978年提出了标准化的建议,将数据库结构分为3级:面向用户或应用程序员的用户级、面向建立和维护数据库人员的概念级、面向系统程序员的物理级
外模式体现了数据库的用户观(视图级)
外模式又称子模式或用户模式,对应于用户级。它是某个或某几个用户所看到的数据库的数据视图,是与某一应用有关的数据的逻辑表示。外模式是从模式导出的一个子集,包含模式中允许特定用户使用的那部分数据。用户可以通过外模式描述语言来描述、定义对应于用户的数据记录(外模式),也可以使用DML对这些数据记录进行操作。
概念模式体现了数据库的整体观(表级)
概念模式又称模式或者是概念模式,对应于概念级,它是数据库设计者综合所有用户的数据,按照一个统一的观点构造的全局逻辑结构,对数据库的全部的数据的逻辑结构和特征的总体描述,是所有用户的公共数据视图(全局视图)。它是由数据库管理系统提供的数据模式描述语言(Data Description Language,DDL)来描述、定义的。
内模式体现了数据库的存储观(物理文件级)
内模式又称存储模式,对应于物理级。它是数据库中全体数据的内部表示或底层描述,是数据库最低一级的逻辑描述,它描述了数据在存储介质上的存储方式和物理结构(例如,记录的存储方式是顺序存储、按照B树结构存储还是按hash方法存储;索引按照什么方式组织;数据是否压缩存储,是否加密;数据的存储记录结构有何规定),对应着实际存储在外存储介质上的数据库。内模式由内模式描述语言来描述、定义的。
工作方式
数据按照外模式描述提供给我们的用户;按内模式存储到磁盘上;而概念模式提供了连接这两级模式一个相对稳定的中间层级,而就是有了这个中间级使得两级模式中任意一级的改变不受第三级的限制。
二层映射
外模式-模式映射保证了逻辑独立性
模式-内模式映射保证了物理独立性
参考链接:https://blog.csdn.net/qq_46086223/article/details/120228601
参考链接:https://www.yisu.com/zixun/365760.html

















 2286
2286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









