







文章目录
036 Container With Most Water 盛水最多的容器
给定一个整数数组heights ,其中heights[i]表示第i个棒子的高度。
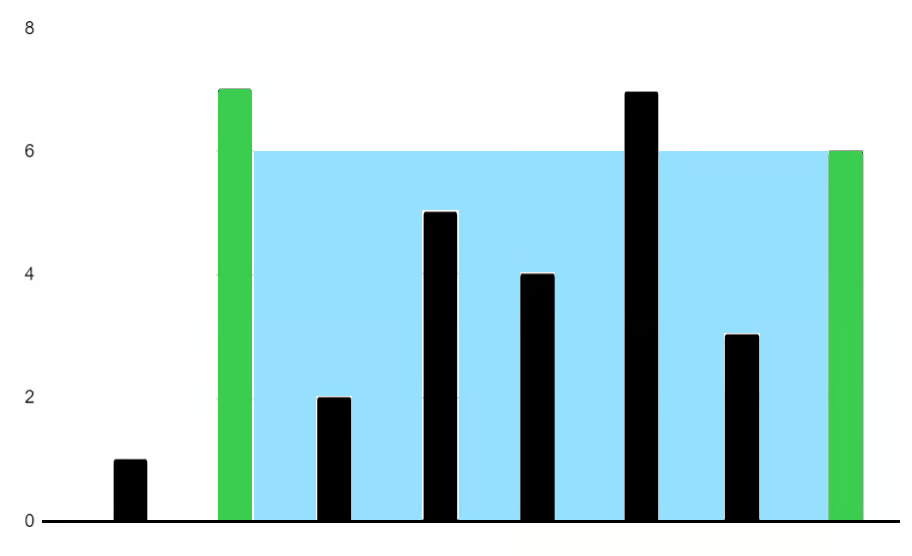
示例1:
Input: height = [1,7,2,5,4,7,3,6]
Output: 36
解题1: 哈希表
遍历每个字符串,并用哈希表存储字符串中每个字母出现的次数
class Solution:
def maxArea(self, heights: List[int]) -> int:
i,j = 0, len(heights)-1
maximum = 0
while i < j:
maximum = max(maximum, (j-i)*min(heights[i],heights[j]))
if heights[i] < heights[j]:
i += 1
else:
j -= 1
return maximum
时间复杂度:
O
(
n
)
O(n)
O(n)
空间复杂度:
O
(
1
)
O(1)
O(1)
037 Best Time to Buy and Sell Stock 买卖股票的最佳时机
给定一个整数数组prices ,其中prices[i]是NeetCoin在ith天的价格。
您可以选择某一天购买一枚 NeetCoin,并选择未来的另一天出售它。
返回您可以获得的最大利润。您可以选择不进行任何交易,在这种情况下利润将为0 。
示例1:
Input: prices = [10,1,5,6,7,1]
Output: 6
解释:买入prices[1]和卖出prices[4] , profit = 7 - 1 = 6
示例2:
Input: prices = [10,8,7,5,2]
Output: 0
解题1: 双指针
class Solution:
def maxArea(self, heights: List[int]) -> int:
i,j = 0, len(heights)-1
maximum = 0
while i < j:
maximum = max(maximum, (j-i)*min(heights[i],heights[j]))
if heights[i] < heights[j]:
i += 1
else:
j -= 1
return maximum
时间复杂度:
O
(
n
)
O(n)
O(n)
空间复杂度:
O
(
1
)
O(1)
O(1)
038 Longest Substring Without Repeating Characters 没有重复字符的最长子串
给定一个字符串s ,找到没有重复字符的最长子字符串的长度。
子字符串是字符串中连续的字符序列。
示例1:
Input: s = "zxyzxyz"
Output: 3
解题1: 滑动窗口
设置一个集合,遍历字符串,但遍历到的字符不在集合中的时候,就往集合中添加这个元素,如果在集合中,就移除集合中该字符及左侧的部分。
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
charSet = set()
l = 0
maxlen = 0
for r in range(len(s)):
while s[r] in charSet:
charSet.remove(s[l])
l += 1
charSet.add(s[r])
maxlen = max(maxlen, r-l+1)
return maxlen
时间复杂度:
O
(
n
)
O(n)
O(n)
空间复杂度:
O
(
m
)
O(m)
O(m)
n 是字符串的长度, m 是字符串中唯一字符的总数。
039 Longest Repeating Character Replacement 最长重复字符替换
给定一个仅由大写英文字符组成的字符串s和一个整数k 。您最多可以选择字符串中的k字符并将其替换为任何其他大写英文字符。
执行最多k次替换后,返回仅包含一个不同字符的最长子字符串的长度。
示例1:
Input: s = "XYYX", k = 2
Output: 4
解释:将“X”替换为“Y”,或者将“Y”替换为“X”。
解题1: 滑动窗口
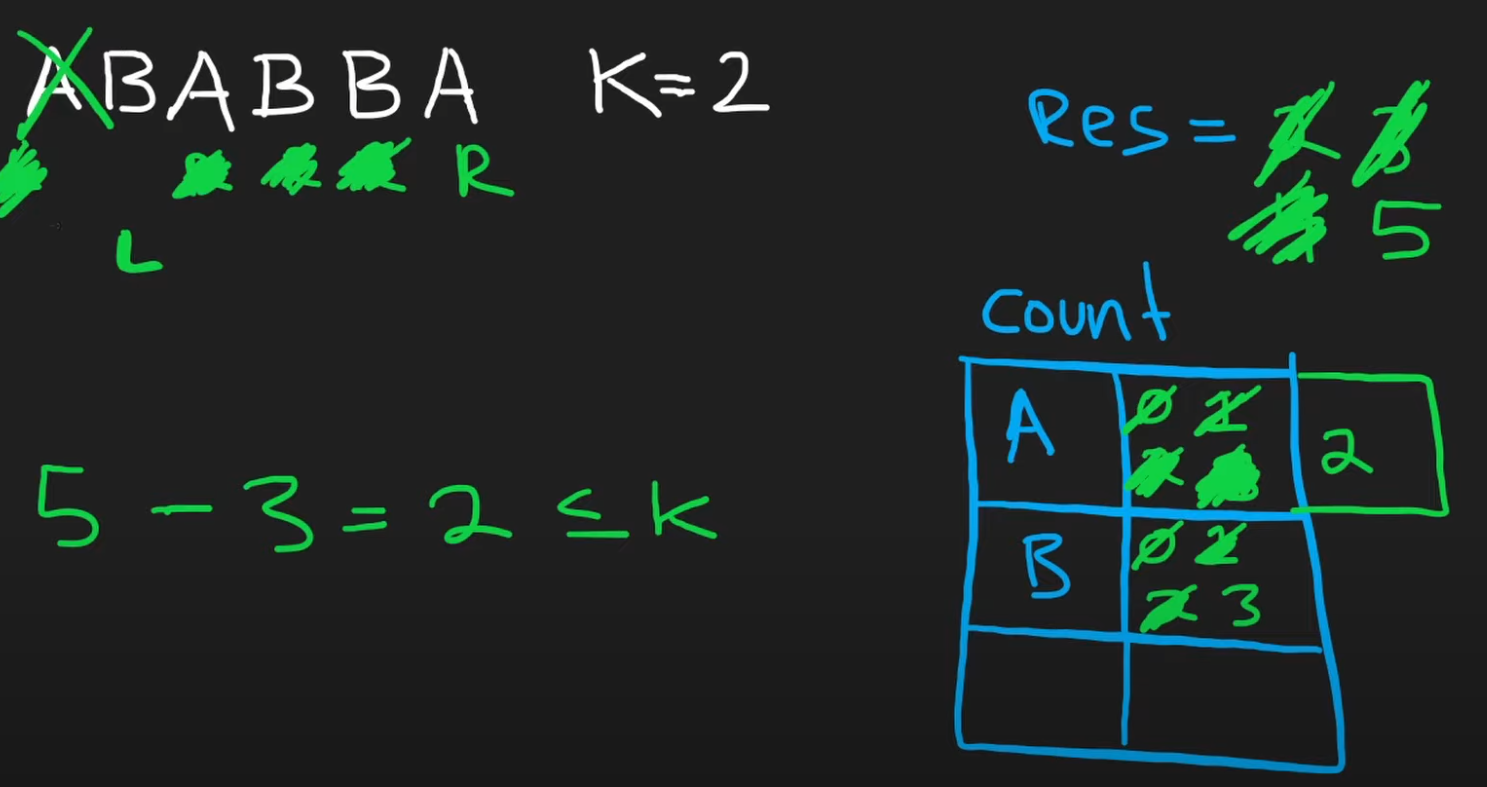
设置一个哈希表,来记录子字符串中每个字母出现的次数。只要我们每次子字符串的长度减去频率最大的字符个数的值小于k,那就说明这个子字符串是成立的
class Solution:
def characterReplacement(self, s: str, k: int) -> int:
count = {}
res = 0
l = 0
for r in range(len(s)):
count[s[r]] = 1 + count.get(s[r], 0)
# 如果条件不成立,就要从最左边的字符开始移除
while (r-l+1) - max(count.values()) > k:
count[s[l]] -= 1
l += 1
res = max(res, r-l+1)
return res
时间复杂度:
O
(
m
∗
n
)
O(m∗n)
O(m∗n)
空间复杂度:
O
(
m
)
O(m)
O(m)
n 是字符串的长度, m 是字符串中唯一字符的总数。
解题2: 滑动窗口,稍微难理解,但是效率更高
class Solution:
def characterReplacement(self, s: str, k: int) -> int:
count = {}
res = 0
l = 0
# 这里用maxf这个变量来统计哈希表中频率最高字母出现的次数
maxf = 0
for r in range(len(s)):
count[s[r]] = 1 + count.get(s[r], 0)
maxf = max(maxf, count[s[r]])
# 如果条件不成立,就要从最左边的字符开始移除
while (r-l+1) - maxf > k:
count[s[l]] -= 1
l += 1
res = max(res, r-l+1)
return res
时间复杂度:
O
(
n
)
O(n)
O(n)
空间复杂度:
O
(
m
)
O(m)
O(m)
040 Permutation in String 字符串中的排列
给你两个字符串s1和s2。
如果s2包含s1的排列,则返回true ,否则返回false 。这意味着如果s1的排列作为s2的子字符串存在,则返回true 。
两个字符串都只包含小写字母。
示例1:
Input: s1 = "abc", s2 = "lecabee"
Output: true
解释:子字符串"cab"是"abc"的排列,出现在"lecabee"中。
示例2:
Input: s1 = "abc", s2 = "lecaabee"
Output: false
解题1: 滑动窗口,哈希集(自己想的)
class Solution:
def checkInclusion(self, s1: str, s2: str) -> bool:
# 首先需要判断s1的长度是否小于s2
if len(s1) > len(s2):
return False
count1 = {}
count2 = {}
for i in range(len(s1)):
count1[s1[i]] = 1 + count1.get(s1[i], 0)
count2[s2[i]] = 1 + count2.get(s2[i], 0)
if count1 == count2:
return True
l = 0
for r in range(len(s1), len(s2)):
count2[s2[l]] -= 1
# 这里要特别注意,因为一旦键值对创建后,当某个键的值为0,
# 该键值对也会在字典中,那么可能无法与子串字典保持一致
if count2[s2[l]] == 0: # 如果值为 0,删除键
del count2[s2[l]]
count2[s2[r]] = 1 + count2.get(s2[r], 0)
if count1 == count2:
return True
l += 1
return False
时间复杂度:
O
(
n
)
O(n)
O(n)
空间复杂度:
O
(
m
)
O(m)
O(m)
解题1: 滑动窗口,哈希集(更加高效的)
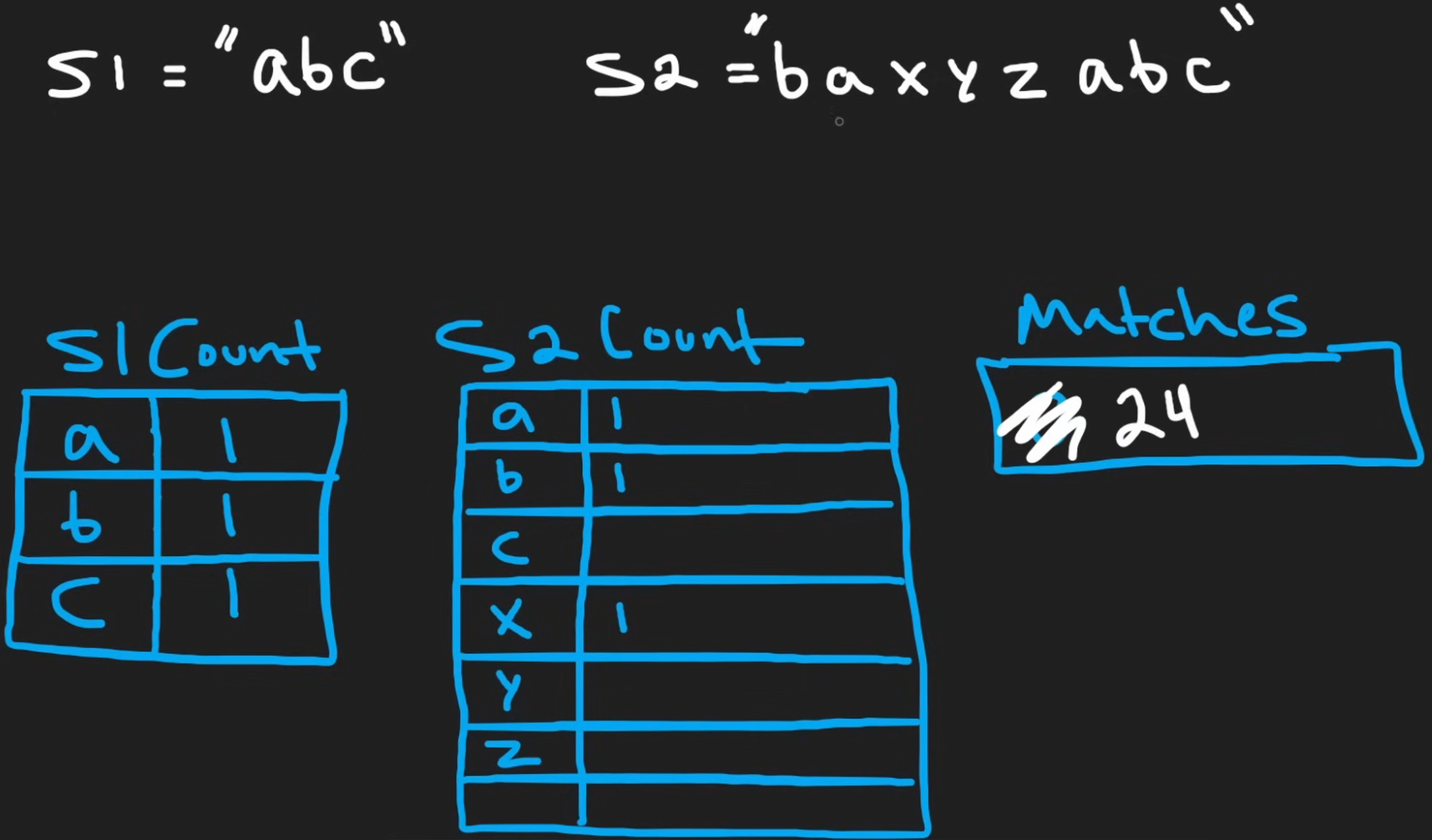
因为这里的字母只从a到z,一共只有26个, 所以我们用matches来表示现在一共有多少个字母是匹配的。如上图所示,此时除了c和x是不匹配,其他都是匹配的,所以matches=24。
class Solution:
def checkInclusion(self, s1: str, s2: str) -> bool:
# 首先需要判断s1的长度是否小于s2
if len(s1) > len(s2):
return False
s1Count, s2Count = [0] * 26, [0] *26
for i in range(len(s1)):
s1Count[ord(s1[i])-ord('a')] += 1
s2Count[ord(s2[i])-ord('a')] += 1
# 先统计一次匹配的字符个数
matches = 0
for i in range(26):
matches += (1 if s1Count[i] == s2Count[i] else 0)
# 开始用滑动窗口进行遍历
l = 0
for r in range(len(s1), len(s2)):
if matches == 26:
return True
# 往右移动,增加右侧一个字符
index = ord(s2[r])-ord('a')
s2Count[index] += 1
if s1Count[index] == s2Count[index]:
matches += 1
# 这里是用来判断刚刚是否匹配的,如果刚刚是匹配的,+1会导致不匹配,matches-1
elif s1Count[index] + 1 == s2Count[index]:
matches -= 1
index = ord(s2[l])-ord('a')
s2Count[index] -= 1
if s1Count[index] == s2Count[index]:
matches += 1
elif s1Count[index] - 1 == s2Count[index]:
matches -= 1
l += 1
# 当遍历到最后一次时,没有判断是否满足条件,所以不是直接返回false,需要对最后一个子串再进行一次判断
return matches == 26
时间复杂度:
O
(
n
)
O(n)
O(n)
空间复杂度:
O
(
1
)
O(1)
O(1)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









