




目录
介绍
HashMap是java中常用的一种数据结构。HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。
HashMap在jdk1.2中初始实现,jdk1.7及其之前采用 数组+链表 方式实现,jdk1.8优化为 数组 + 链表 + 红黑树 的实现方式。
原理
注:以下基于jdk1.8
核心结构
HashMap 继承于AbstractMap,实现了Map、Cloneable、java.io.Serializable接口,其定义和核心参数如下:
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
transient Node<K,V>[] table; // node数组
transient Set<Map.Entry<K,V>> entrySet; // 存储具体元素的集合
transient int size; // 记录map的数据个数
transient int modCount; // HashMap扩容和结构改变的次数
int threshold; // 记录要调整大小的临界值
final float loadFactor; // 负载因子
// 默认初始容量 - 必须是2的幂
static final int DEFAULT_INITIAL_CAPACITY = 16;
// 最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
// 默认负载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 链表转红黑树的阈值
static final int TREEIFY_THRESHOLD = 8;
// 红黑树转链表的阈值
static final int UNTREEIFY_THRESHOLD = 6;
// 树化的最小容量
static final int MIN_TREEIFY_CAPACITY = 64;
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
}
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
}
}- 数据结构图:
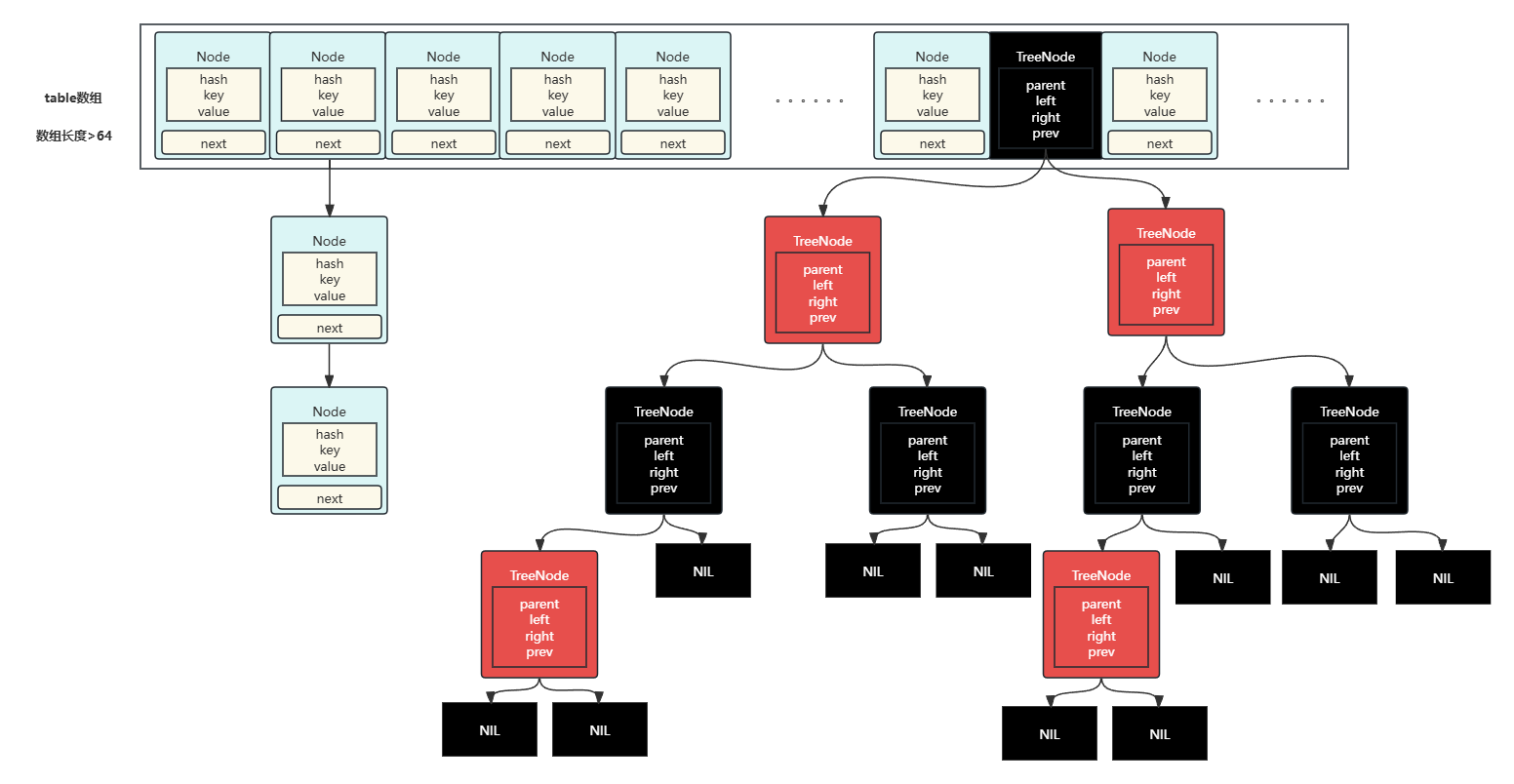
数据存储采用数组+链表+红黑树的方式,当链表长度超过阈值(默认 8)且数组容量 ≥ 64 时,链表会转换为红黑树;若节点数减少到 6 以下,红黑树会退化为链表(避免频繁树结构调整)。
核心方法与流程
插入(put方法)
-
底层代码
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
HashMap.Node<K,V>[] tab; HashMap.Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
HashMap.Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof HashMap.TreeNode)
e = ((HashMap.TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
final void treeifyBin(HashMap.Node<K,V>[] tab, int hash) {
int n, index; HashMap.Node<K,V> e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
HashMap.TreeNode<K,V> hd = null, tl = null;
do {
HashMap.TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}- 流程解析
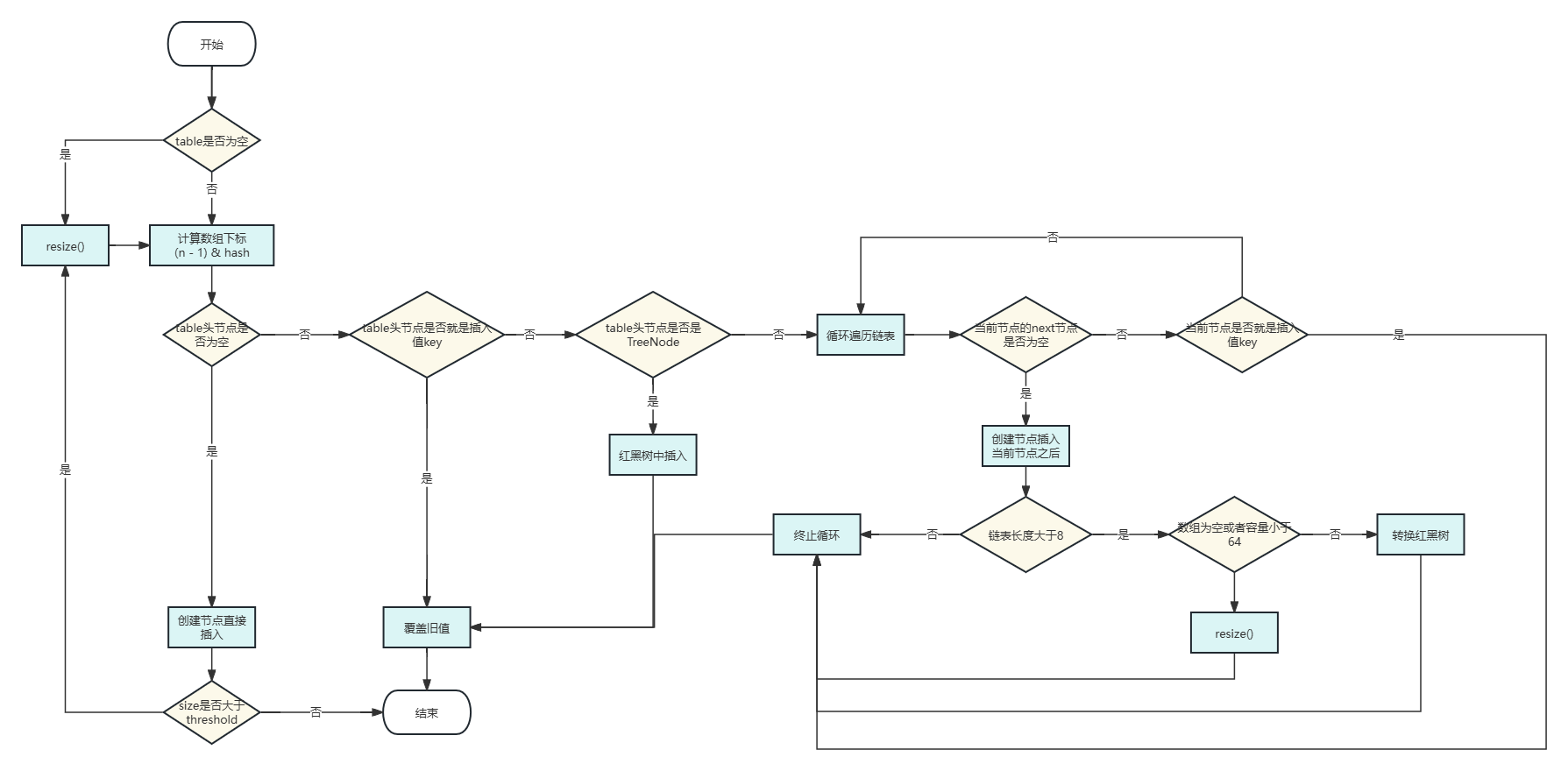
扩容 (resize 方法)
- 底层代码
final HashMap.Node<K,V>[] resize() {
HashMap.Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
HashMap.Node<K,V>[] newTab = (HashMap.Node<K,V>[])new HashMap.Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
HashMap.Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof HashMap.TreeNode)
((HashMap.TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
HashMap.Node<K,V> loHead = null, loTail = null;
HashMap.Node<K,V> hiHead = null, hiTail = null;
HashMap.Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}- 流程解析
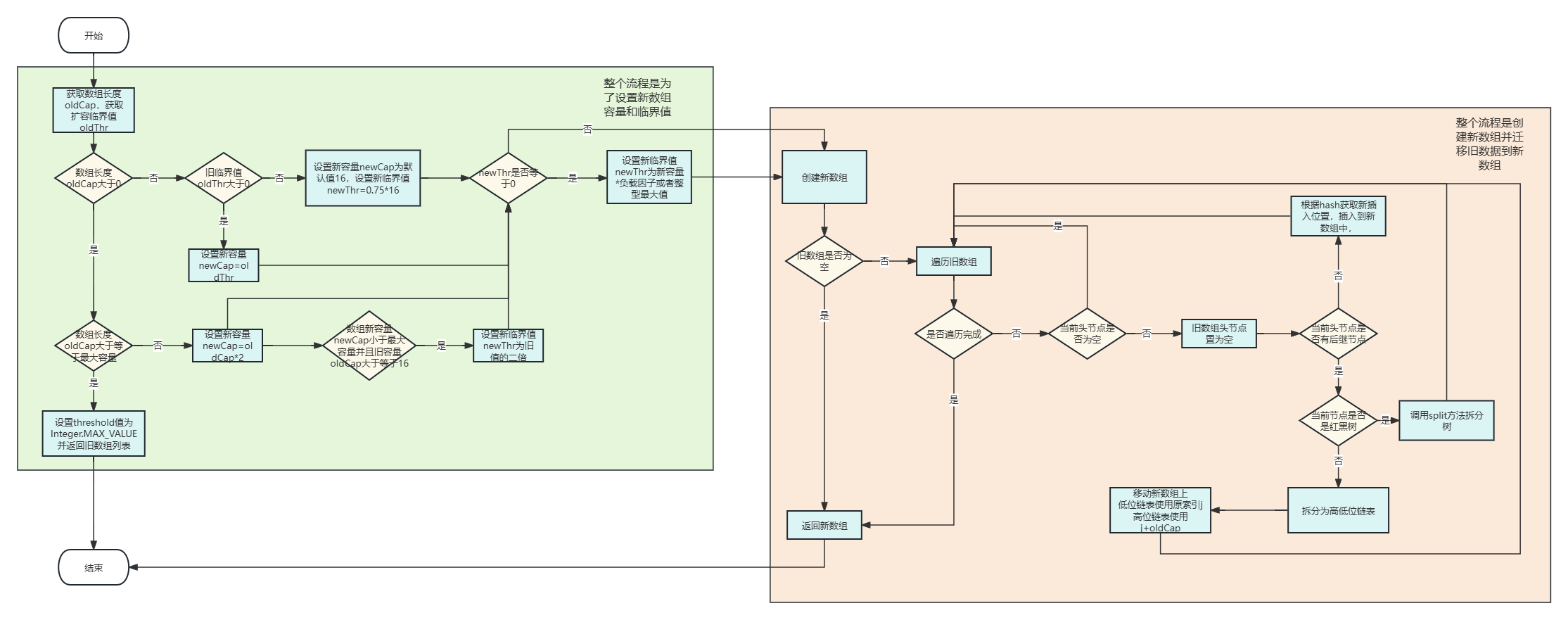
-
注:设置高低位链表,采用 j 和 j + oldcap 定位新位置可以避免重新哈希,提高性能,其值与重新哈希计算位置是相同的,以下是一个简单举例:
假设:
旧容量 = 16(掩码
1111)Key的哈希值:
... 0001 1010(二进制)旧位置计算:
hash : ???? ???? ???1 1010 oldCap-1: 0000 0000 0000 1111 index : 0000 0000 0000 1010 → 十进制10 (j=10)新位置计算:
newCap-1: 0000 0000 0001 1111 hash : ???? ???? ???1 1010 index : 0000 0000 0001 1010 → 十进制26通过
j + oldCap验证:10 (j) + 16 (oldCap) = 26
查询 (get 方法)
- 底层代码
public V get(Object key) {
HashMap.Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final HashMap.Node<K,V> getNode(int hash, Object key) {
HashMap.Node<K,V>[] tab; HashMap.Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof HashMap.TreeNode)
return ((HashMap.TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}删除 (remove 方法)
- 底层代码
public V remove(Object key) {
HashMap.Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
final HashMap.Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
HashMap.Node<K,V>[] tab; HashMap.Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
HashMap.Node<K,V> node = null, e; K k; V v;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
if (p instanceof HashMap.TreeNode)
node = ((HashMap.TreeNode<K,V>)p).getTreeNode(hash, key);
else {
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof HashMap.TreeNode)
((HashMap.TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}常见问题
线程安全问题
结论
HashMap是非线程安全的。
原因
-
环形链表:在JDK 1.7版本中,HashMap在扩容时使用头插法迁移链表,这可能导致链表成环,进而在遍历链表时引发死循环,最终导致
StackOverflowError;而JDK 1.8版本采用尾插法可以避免该问题。 -
数据覆盖:在多线程环境下,如果多个线程同时调用
put()方法插入数据,当两个线程同时计算哈希值并定位到同一个桶(bucket)时,如果该位置为空,新插入的数据可能会覆盖之前的数据。 -
size计算不准:多线程环境下同时调用
put()或remove()方法时,由于size变量的非原子性操作,可能会导致最终的大小值不准确。 -
数据丢失:在扩容过程中,如果其他线程尝试插入新元素而resize操作尚未完成,可能会导致新插入的数据被遗漏。
解决方法
-
使用Hashtable(已废弃):
Hashtable是过时的线程安全集合,在所有方法上都使用synchronized关键字。然而,由于每个操作都被同步,效率较低,不适合高并发场景。 -
使用ConcurrentHashMap:通过分段锁机制允许多个线程并发访问不同的段,减少锁的竞争。
-
使用Collections.synchronizedMap:可以通过
Collections.synchronizedMap(new HashMap<>())方法将HashMap包装成一个线程安全的Map。这种方式在每次访问Map的操作上都加了同步锁,但会降低性能。 -
手动加锁:使用 ReadWriteLock、synchronized等工具加锁保证线程安全。但需要开发者手动管理锁,会稍显复杂。
null键和null值
结论
允许 null 键值,null 键在 HashMap 中仅有一个(唯一性),存储于数组起始位置(index 0),null 值则可多个。
重写 equals 方法和 hashcode 方法
结论
HashMap通过hash值和 equals 判断key是否相等,判断逻辑如下:
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))负载因子的选择
结论
HashMap的默认负载因子(Load Factor)设为0.75,是基于空间利用率与时间效率的平衡,通过数学统计(泊松分布)和工程实践验证得出的最优值。同时,HashMap容量始终为2的幂,0.75可保证扩容阈值为整数。
采用(哈希码 & 数组长度减一)计算方式
结论
HashMap使用(哈希码 & 数组长度减一)这种方式是一种优化技术,它利用了位运算来快速地将大范围的哈希码映射到较小范围的数组索引上,比模运算要快很多;HashMap 的容量设置为 2 的倍数,主要是为了通过位运算优化索引计算效率、减少扩容时的迁移成本,并提升哈希分布的均匀性。

















 43万+
43万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









