







1、什么是跳跃表
跳跃表是基于链表扩展实现的一种特殊链表,类似于树的实现,跳跃表不仅实现了横向链表,还实现了垂直方向的分层索引。
一个跳跃表由若干层链表组成,每一层都实现了一个有序链表索引,只有最底层包含了所有数据,每一层由下往上依次通过一个指针指向上层相同值的元素,每层数据依次减少,等到了最顶层就只会保留部分数据了。
跳跃表的这种结构,是利用了空间换时间的方法来提高了查询效率。程序总是从最顶层开始查询访问,通过判断元素值来缩小查询范围。如图
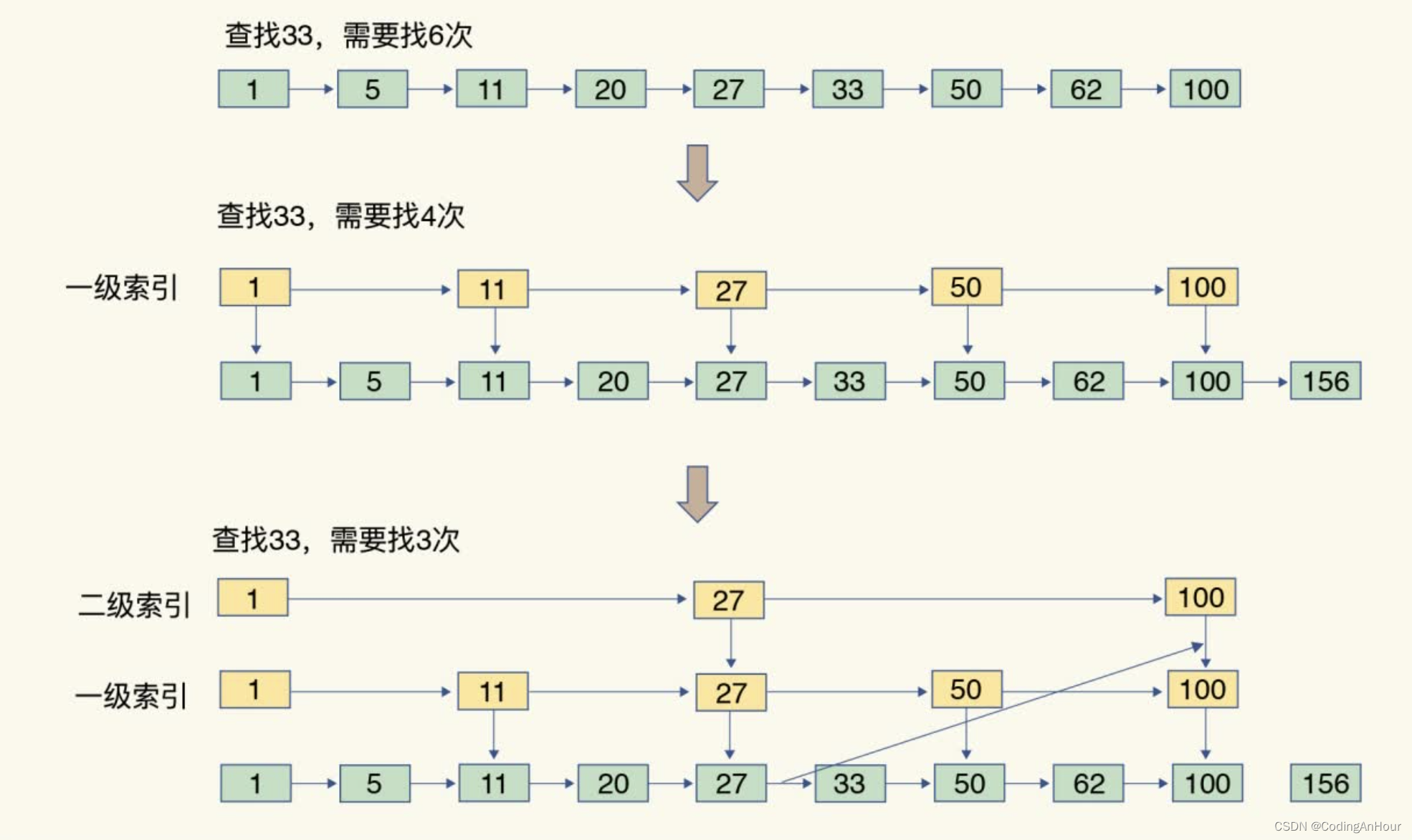
如果我们要在链表中查找 33 这个元素,只能从头开始遍历链表,查找 6 次,直到找到 33
为止。此时,复杂度是 O(N),查找效率很低。
为了提高查找速度,我们来增加一级索引:从第一个元素开始,每两个元素选一个出来作为索引。这些索引再通过指针指向原始的链表。
例如,从前两个元素中抽取元素 1 作为一级索引,从第三、四个元素中抽取元素 11 作为一级索引。此时,我们只需要 4 次查找就能定位到元素 33 了。
如果我们还想再快,可以再增加二级索引:从一级索引中,再抽取部分元素作为二级索引。
例如,从一级索引中抽取 1、27、100 作为二级索引,二级索引指向一级索引。这样,我们只需要 3 次查找,就能定位到元素 33 了。
可以看到,这个查找过程就是在多级索引上跳来跳去,最后定位到元素。这也正好符合“跳”表的叫法。当数据量很大时,跳表的查找复杂度就是 O(logN)。
2、ConcurrentSkipListMap跳表结构
真正存储数据的节点
static final class Node<K,V> {
final K key; // 键
V val; // 值
Node<K,V> next; // 指向下一个节点的指针
Node(K key, V value, Node<K,V> next) {
this.key = key;
this.val = value;
this.next = next;
}
}
跳表的索引
static final class Index<K,V> {
final Node<K,V> node; // 当前节点
final Index<K,V> down; // 下一层
Index<K,V> right; // 当前层的下一个节点
Index(Node<K,V> node, Index<K,V> down, Index<K,V> right) {
this.node = node;
this.down = down;
this.right = right;
}
}
跳跃表ConcurrentSkipListMap源码解析这篇文章介绍的非常详细,没就有继续写。。。















 3447
3447











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









