







目录
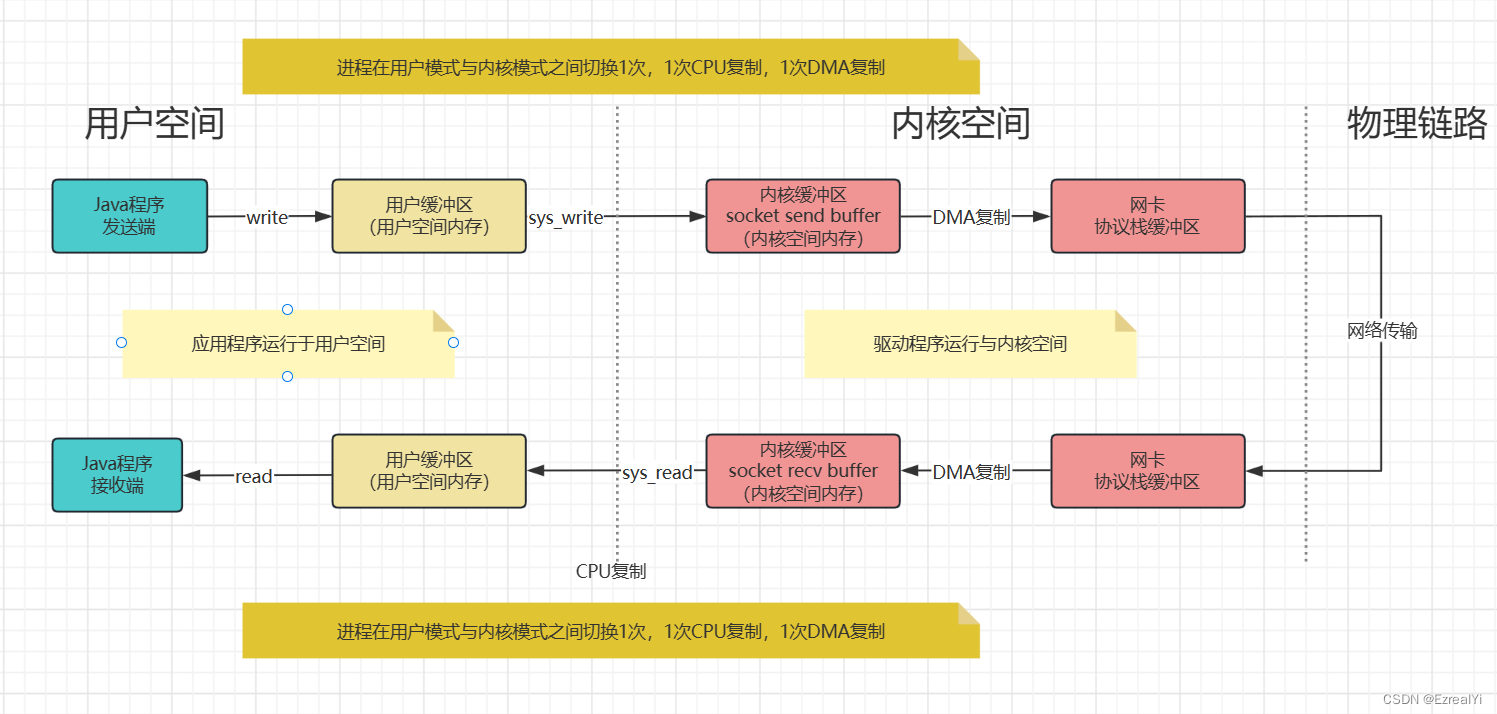
传统C程序IO数据传输过程
-
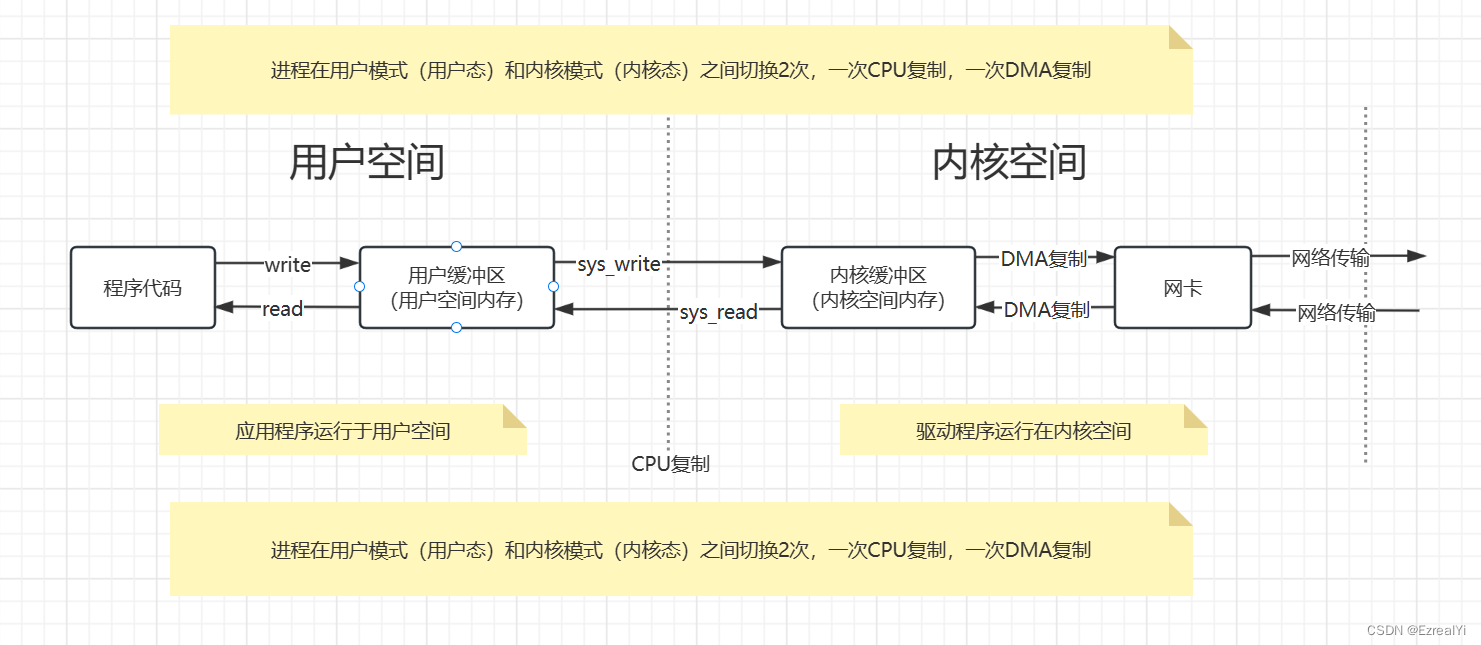
详解典型的IO系统调用流程:写入流程
-
wirte系统调用导致进程从用户模式切换成内核模式。 -
sys_write写内核函数,将用户空间内存地址数据放入内核空间地址缓冲区。这是一次CPU负责的内存复制。该内核地址缓冲区如果与
套接字相关,叫做socket send buffer,如果与文件系统相关,叫做filesystem cache。 -
DMA(非DNA)引擎将数据从内核缓冲区传递到协议栈引擎。
这是一次DMA负责的内存复制,CPU不用参与其中。
-
write系统调用返回,进程从内核模式切换到用户模式。
-
-
详解典型的IO系统调用流程:读取流程
-
read系统调用,首先导致进程从用户模式切换到内核模式。在阻塞的IO模式下,用户进程等待系统调用返回。线程或进程会等待内核缓存中的数据。
-
数据的最初副本,在DMA引擎的工作下,数据复制到内核缓冲区(网卡:复制到
socket send buffer中。文件:复制到filesystem cache中)。这是一次DMA负责的复制,CPU不参与其中。
-
sys_read内核函数,将数据从内核缓冲区复制到用户缓冲区,然后调用read返回。这是一次CPU负责的内存复制。
-
read调用返回,进程从内核模式切换回用户模式。数据存储在用户缓冲区。
-
用户空间的内存可能并不指向物理内存,直接访问时可能产生缺页异常。而Linux内核禁止在中断时产生缺页异常,这就要求用户缓冲区的数据必须在内存中,实际上很难控制,所以把数据复制到内核缓冲区中,这就是内核缓冲区存在的意义(避免文件或网卡直接访问用户内存)。
//缺页异常处理函数
asmlinkage void do_page_fault(unsigned long address, unsigned long mmcsr,
long cause, struct pt_regs *regs)
{
//省略一堆。。
//这里注释已经说的很清楚了,不允许在内核中执行缺页中断
/* If we're in an interrupt context, or have no user context,
we must not take the fault. */
if (!mm || faulthandler_disabled())
goto no_context;
}
//打印oops
no_context:
/* Oops. The kernel tried to access some bad page. We'll have to
terminate things with extreme prejudice. */
printk(KERN_ALERT "Unable to handle kernel paging request at "
"virtual address %016lx\n", address);
die_if_kernel("Oops", regs, cause, (unsigned long*)regs - 16);
do_exit(SIGKILL);
-
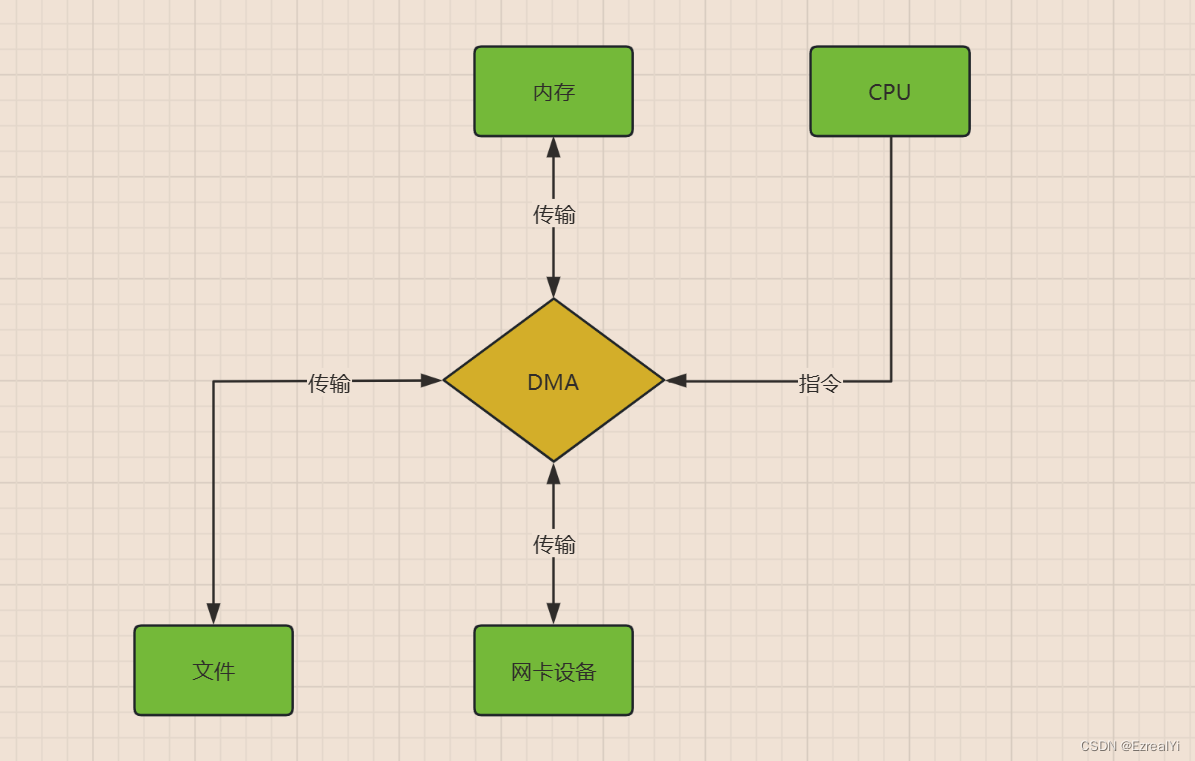
DMA简介:
为了减少CPU对快速设备读写的操作,可以通过把这批数据的传输过程交由一块专用的接口卡(DMA接口)来控制,让DMA卡代替CPU控制在快速设备与主存储器之间直接传输数据。
在DMA模式下,CPU只须向DMA控制器下达指令,让DMA控制器来处理数据的传送,数据传送完毕再把信息反馈给CPU,这样就很大程度上减轻了 CPU资源占有率。
传统的Java程序IO数据传输过程
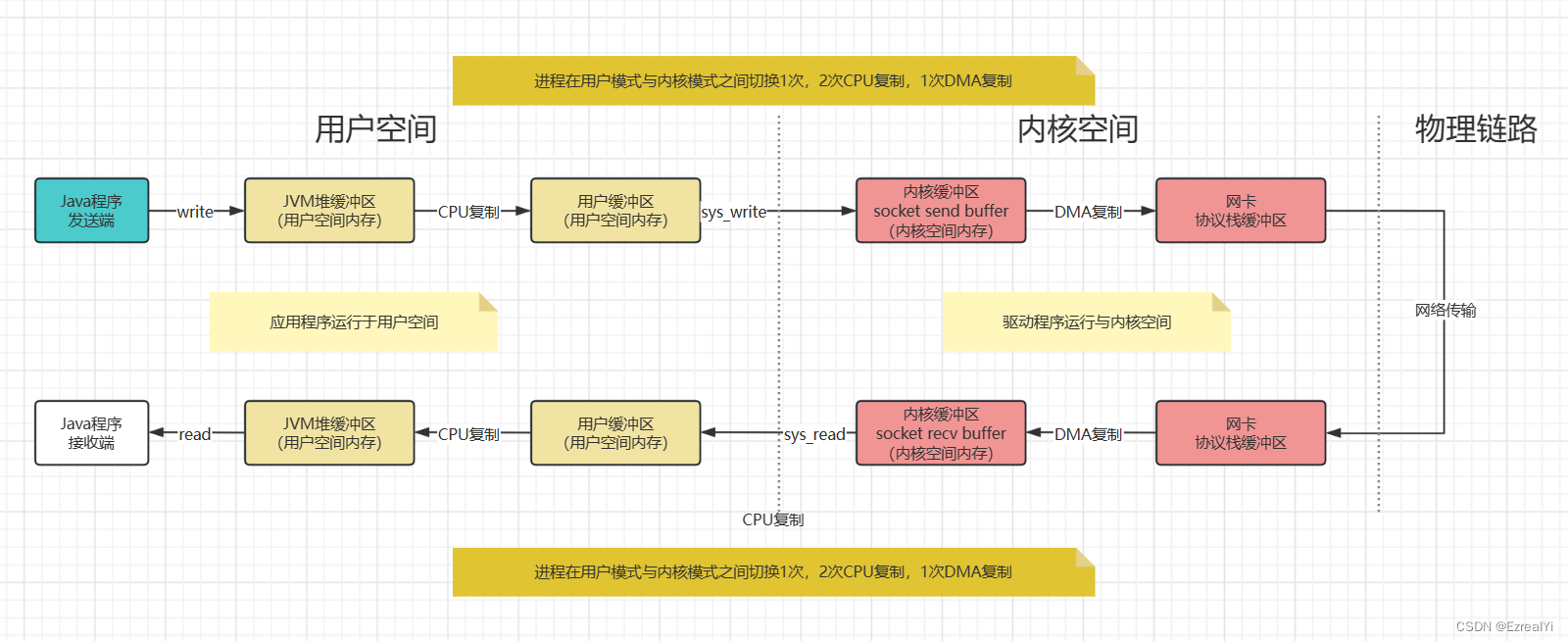
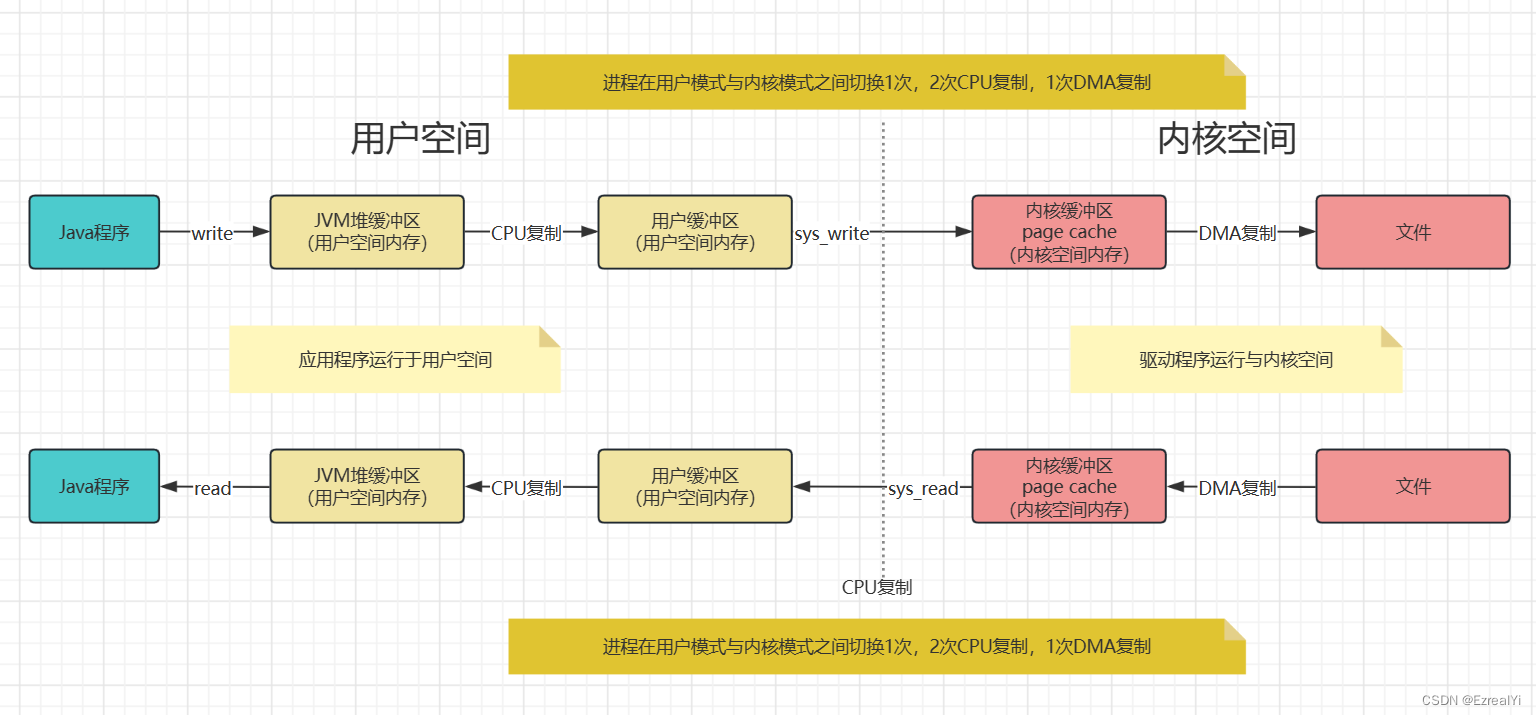
与传统C程序IO数据传输过程相比,传统的Java程序IO数据传输过程多了JVM堆缓冲区内存,实际上也是用户空间内存,但这意外这write和read调用各自多了一次CPU复制,而CPU复制实际上是非常消耗CPU时间的。
三种零复制模式
第一种:DirectBuffer零复制

与传统的Java程序IO数据传输过程相比,DirectBuffer零复制减少了2次CPU复制,write和read各减少1次。
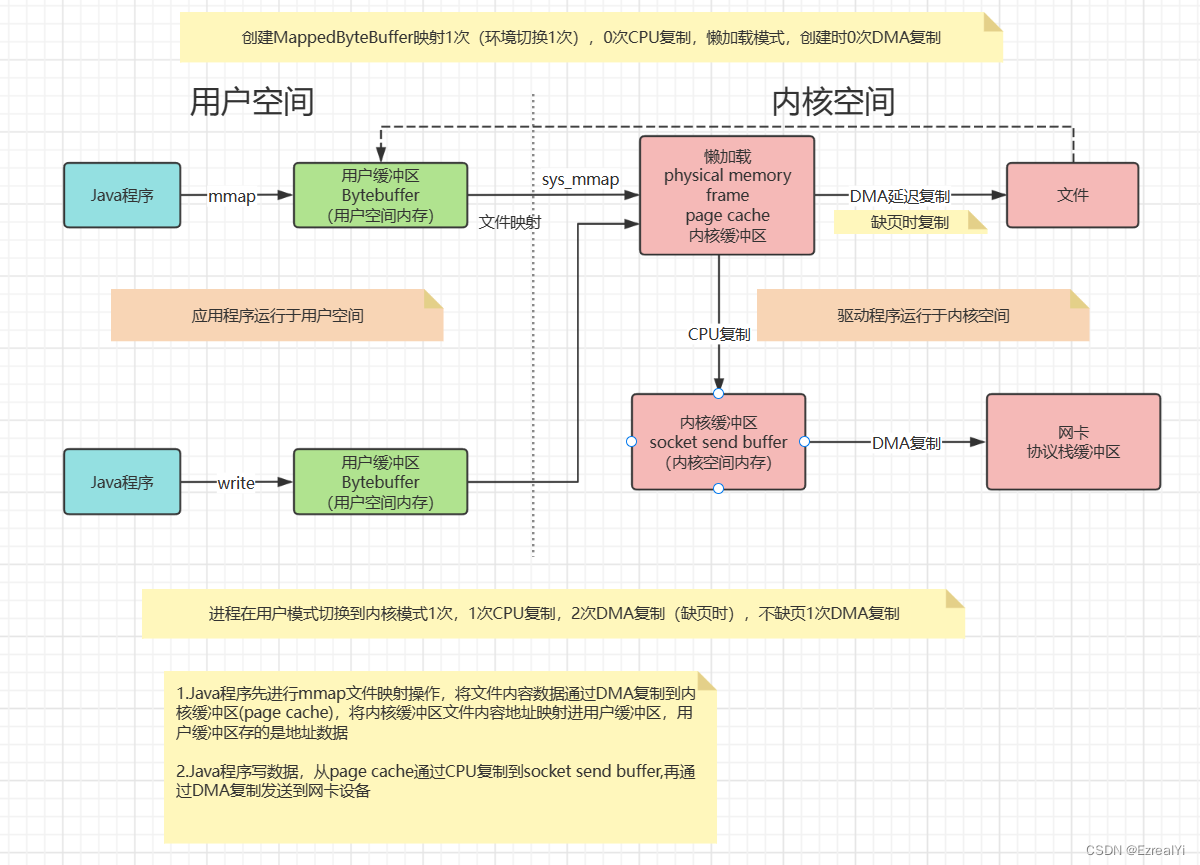
第二种:mmap + write 零复制
-
初识MMAP
mmap将一个文件或者其他对象映射进内存。它本身提供了不同于一般对普通文件的访问方式,进程可以像读写内存一样对普通文件的操作。
-
mmap零复制的使用是分使用场景的,也就是说并不是所有场景都可以使用mmap+write
-
mmap进行文件IO读写(文件)

-
mmap+write进行文件读+Socket写(文件读,socket写)
-
rocketmq使用的是这种方式
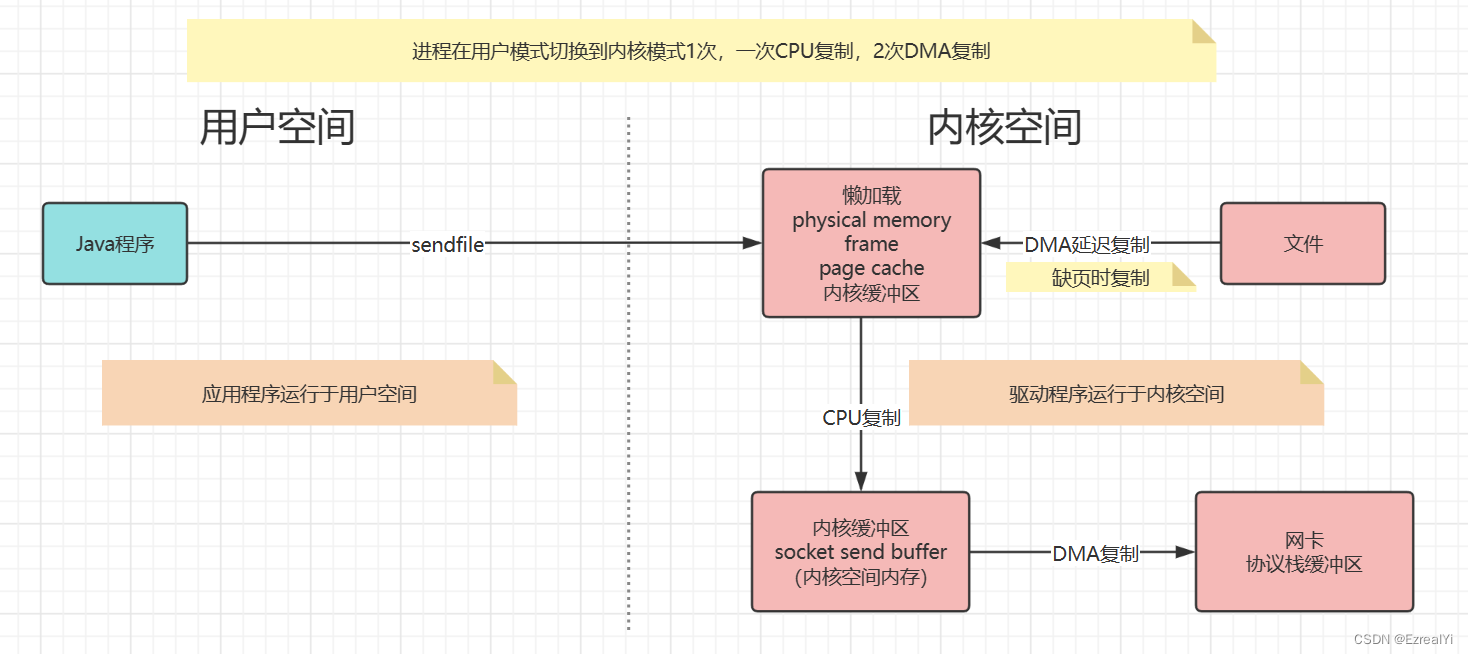
第三种:sendfile零复制
Linux Kernel 2.1引进了sendfile(),只需要一个系统调用就可以实现文件发送
sendfile()
替代
mmap();
write();
sendfile()减少了1次模式切换,但还有1次CPU复制和2次DMA复制。
Linux Kernel 2.4版本进行了优化,提供了gather操作,把最后一次CPU复制去除。
就是在内核空间page cache和socket send buffer不做数据复制了,而是将page cache的内存地址、偏移量记录到相应的socket send buffer中,这样就不需要复制了(其实本质就是和虚拟内存的解决方法思路一样,就是内存地址的记录)
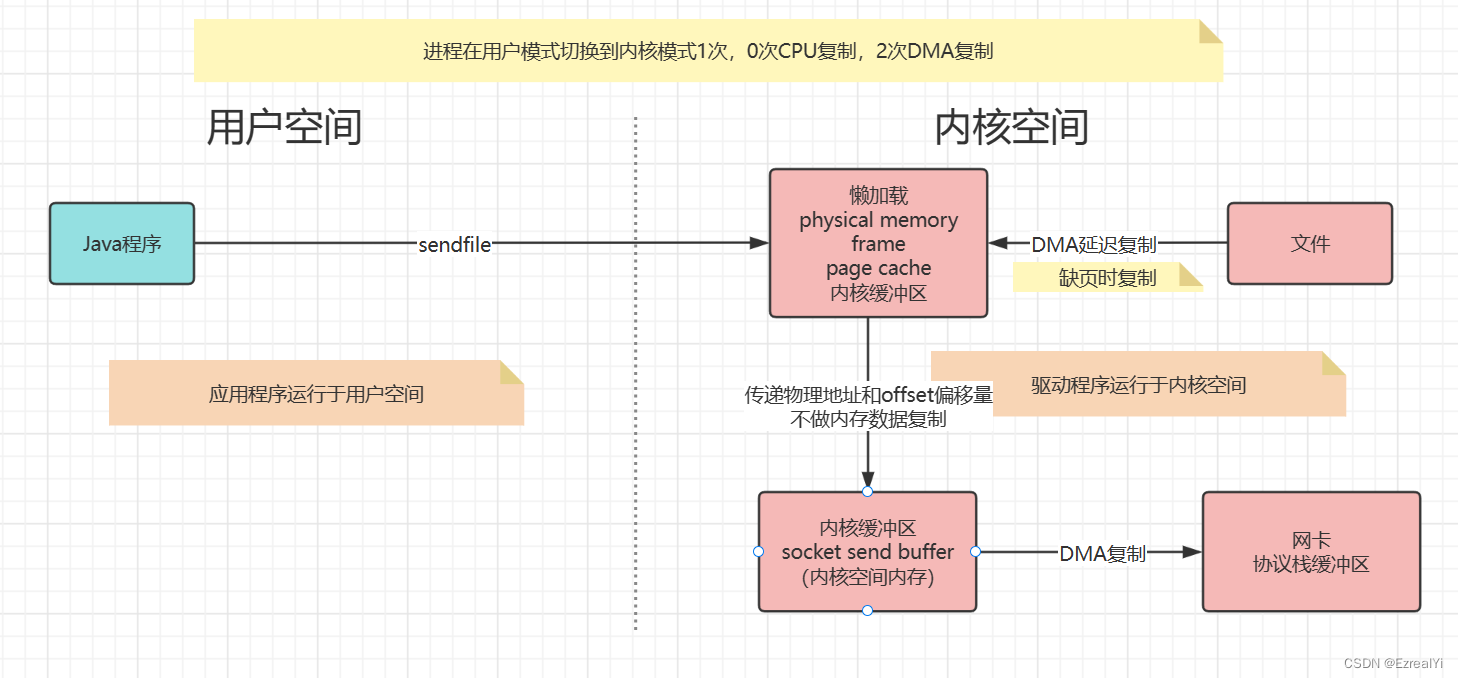
这种方法不仅只有1次用户模式到内核模式的切换,只有2次DMA复制,0次CPU复制,消除了许多数据重复。在许多http server中,都引入了sendfile的机制,如nginx、lighttpd等,它们正是利用sendfile()这个特性来实现高性能的文件发送的。kafka也是使用sendfile()发送文件。后面有精力会系统性详细写写kafka和rocketmq,rocketmq使用的是mmap+write机制。
零复制的优势
- 尽可能避免不必要的CPU拷贝,让CPU解脱出来去执行其他的任务;
- 减少内存带宽的占用;
- 减少用户空间和操作系统内核空间之间的上下文切换;
说在最后
三种零复制机制的原理都是需要非常大的系统底层知识支撑,以开发者的视角出发,系统三大硬件组成:CPU处理器、内存、磁盘对应系统都有相应的管理驱动和算法进行分配、使用的管理,基于这些底层知识,Java程序通过c程序调用访管指令完成特权指令的执行进而完成处理器、内存和磁盘的高效使用,是零复制要求的目的。所以系统性的学习Linux系统底层知识是高级程序员的必备条件,也是使用零复制的必要条件。路漫漫其修远兮,吾将上下而求索… …
















 281
281











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











