







每当需要传输数据时,就必须有一个buffer缓冲区。Java NIO API自带的ByteBuffer操作繁琐,没有自动回收机制。
Netty的ByteBuf等同于JDK的ByteBuffer,在进行channel数据传输时,ByteBuf缓冲区组件相比于ByteBuffer更加快捷更加高效地操作内存缓冲区。
ByteBuf的组成
ByteBuf是一个字节容器,内部是一个字节数组。从逻辑上分,分为四部分:
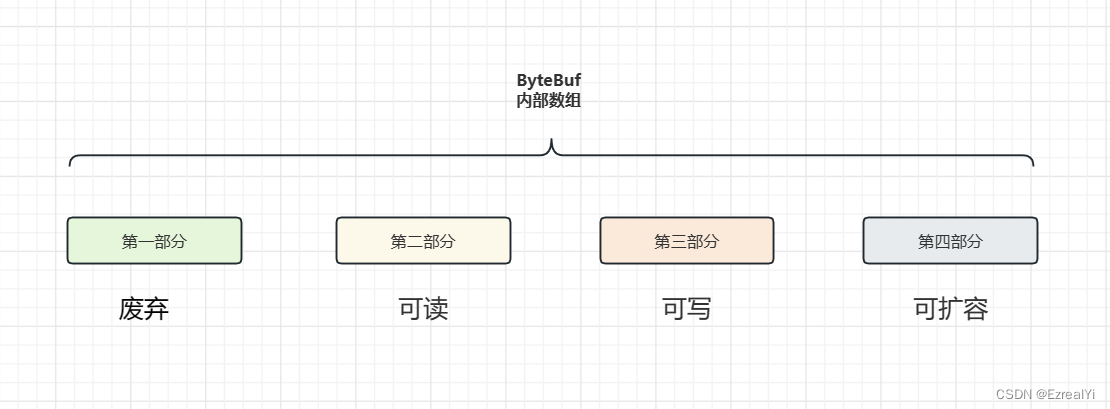
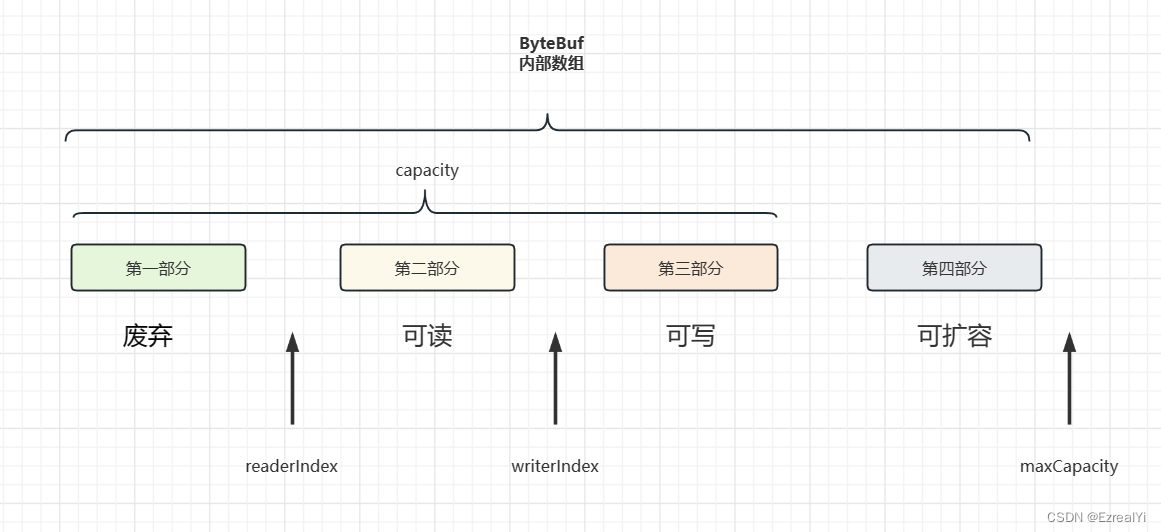
三个重要属性
- readerIndex(读指针):指示读取的起始位置
- writerIndex(写指针):指示写入的起始位置
- maxCapacity(最大容量):表示ByteBuf可以扩容的最大容量
ByteBuf分配器
Netty通过ByteBufAllocator分配器来创建缓冲区对象和分配内存空间。Netty提供了两种形式的分配器实现:PoolByteBufAllocator和UnpooledByteBufAllocator。
- PoolByteBufAllocator(池化的ByteBuf分配器)将ByteBuf实例放入池中,提高了性能,将内存碎片减少到最小;池化分配器采用了jemalloc高效内存分配的策略,该策略被好几种现代操作系统所采用。
- UnpooledByteBufAllocator(普通的未池化ByteBuf分配器)它没有把ByteBuf放入池中,每次被调用时,返回一个新的ByteBuf实例;使用完之后,通过Java的垃圾回收机制回收或者直接释放(对于直接内存而言)。
在Netty中,默认的分配器为ByteBufAllocator.DEFAULT,该默认的分配器可以通过系统参数(System Property)选项io.netty.allocator.type进行配置,配置时使用字符串值:unpooled,pooled。不同的Netty版本,默认分配器是不一样的。在初始化代码在ByteBufUtil类中的静态代码中
public final class ByteBufUtil {
static {
MAX_BYTES_PER_CHAR_UTF8 = (int)CharsetUtil.encoder(CharsetUtil.UTF_8).maxBytesPerChar();
String allocType = SystemPropertyUtil.get("io.netty.allocator.type", PlatformDependent.isAndroid() ? "unpooled" : "pooled");
allocType = allocType.toLowerCase(Locale.US).trim();
Object alloc;
if ("unpooled".equals(allocType)) {
alloc = UnpooledByteBufAllocator.DEFAULT;
logger.debug("-Dio.netty.allocator.type: {}", allocType);
} else if ("pooled".equals(allocType)) {
alloc = PooledByteBufAllocator.DEFAULT;
logger.debug("-Dio.netty.allocator.type: {}", allocType);
} else {
alloc = PooledByteBufAllocator.DEFAULT;
logger.debug("-Dio.netty.allocator.type: pooled (unknown: {})", allocType);
}
......
}
}
现在PooledByteBufAllocator已经广泛使用了一段时间,并且有了增强的缓冲区泄漏追踪机制。因此,也可以在Netty程序中设置引导类Bootstrap装配的时候,将PooledByteBufAllocator设置为默认的分配器。
ServerBootstrap b = new ServerBootstrap()
//4 设置通道的参数,设置长连接
b.option(ChannelOption.SO_KEEPALIVE, true);
//设置父通道的缓冲区分配器
b.option(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT);
//设置子通道的缓冲区分配器
b.childOption(ChannelOption.ALLOCATOR,PooledByteBufAllocator.DEFAULT);
......
// 使用默认分配器分配
ByteBuf buffer = null;
//初始容量为 9,最大容量 100 的缓冲区
buffer = ByteBufAllocator.DEFAULT.buffer(9, 100);
//初始容量为 256,最大容量 Integer.MAX_VALUE 的缓冲区
buffer = ByteBufAllocator.DEFAULT.buffer();
ByteBuf类型
使用Netty时会遇到3种不同类型的ByteBuf,也就是堆缓冲区(Heap ByteBuf)、直接缓冲区(Direct ByteBuf),为了方便缓冲区进行组合,还提供了一种组合缓冲区(CompositeByteBuf)。
| 类型 | 说明 | 优点 | 不足 |
|---|---|---|---|
| Heap ByteBuf | 内部数据为一个Java数组, 存储在JVM的堆空间中,可以通过hasArray方法来判断是不是堆缓冲区 | 内部数据为一个Java数组, 存储在JVM的堆空间中,可以通过hasArray方法来判断是不是堆缓冲区 | 写入底层传输通道之前,都会复制到直接缓冲区 |
| Direct ByteBuf | 内部数据存储在操作系统的物理内存中 | 能获取超过JVM堆限制大小的内存空间;写入传输通道比堆缓冲区更快 | 释放和分配空间昂贵(使用了操作系统的方法);在Java中读取数据时,需要复 制一次到堆上 |
| CompositeByteBuf | 多个缓冲区的组合表示 | 方便一次操作多个缓冲区实例 |
上面三种缓冲区的类型,无论哪一种,都可以通过池化(Pooled)、非池化(Unpooled)两种分配器来创建和分配内存空间。
@Test
public void testHeapBuffer() {
ByteBuf heapBuf = null;
try {
// 分配堆缓冲区
heapBuf = ByteBufAllocator.DEFAULT.heapBuffer();
heapBuf.writeBytes("堆缓冲区".getBytes(CharsetUtil.UTF_8));
if (heapBuf.hasArray()) {
byte[] bytes = heapBuf.array();
int offset = heapBuf.arrayOffset() + heapBuf.readerIndex();
int length = heapBuf.readableBytes();
System.out.println(new String(bytes, offset, length, CharsetUtil.UTF_8)); // 堆缓冲区
}
} finally {
Optional.ofNullable(heapBuf).ifPresent(buf -> buf.release());
}
}
@Test
public void testDirectBuffer() {
ByteBuf directBuf = null;
try {
// 分配直接缓冲区
directBuf = ByteBufAllocator.DEFAULT.directBuffer();
directBuf.writeBytes("直接缓冲区".getBytes(CharsetUtil.UTF_8));
if (!directBuf.hasArray()) {
int length = directBuf.readableBytes();
byte[] bytes = new byte[length];
// 将直接缓冲区数据读到堆内存中
directBuf.getBytes(directBuf.readerIndex(), bytes);
System.out.println(new String(bytes, CharsetUtil.UTF_8)); // 直接缓冲区
}
} finally {
Optional.ofNullable(directBuf).ifPresent(buf -> buf.release());
}
}
@Test
public void testCompositeBuffer() {
CompositeByteBuf compositeBuf = null;
ByteBuf heapBuf1 = null;
ByteBuf heapBuf2 = null;
try {
// 分配两个堆缓冲区
heapBuf1 = ByteBufAllocator.DEFAULT.heapBuffer();
heapBuf2 = ByteBufAllocator.DEFAULT.heapBuffer();
heapBuf1.writeBytes("堆缓冲区-1".getBytes(CharsetUtil.UTF_8));
heapBuf2.writeBytes("堆缓冲区-2".getBytes(CharsetUtil.UTF_8));
// 分配composite缓冲区
compositeBuf = ByteBufAllocator.DEFAULT.compositeBuffer();
compositeBuf.addComponents(heapBuf1, heapBuf2);
StringBuffer sBuffer = new StringBuffer();
for (ByteBuf buf : compositeBuf) {
byte[] array = buf.array();
int offset = buf.arrayOffset() + buf.readerIndex();
int length = buf.readableBytes();
sBuffer.append(new String(array, offset, length, CharsetUtil.UTF_8));
sBuffer.append("\t");
}
System.out.println(sBuffer.toString()); // 堆缓冲区-1 堆缓冲区-2
} finally {
Optional.ofNullable(compositeBuf).ifPresent(buf -> buf.release());
}
}
ByteBuf引用计数
JVM中使用“计数器”(一种GC算法)来标记对象是否“不可达”进而收回(注:GC是Garbage Collection的缩写,即Java中的垃圾回收机制),Netty也使用了这种手段来对ByteBuf的引用进行计数,Netty的ByteBuf的内存回收工作是通过引用计数的方式管理的。
Netty之所以采用“计数器”来追踪ByteBuf的生命周期,一是能对Pooled ByteBuf的支持,二是能够尽快地“发现”那些可以回收的ByteBuf(非Pooled),以便提升ByteBuf的分配和销毁的效率。
什么是 Pooled(池化)的 ByteBuf 缓冲区呢?从 Netty4 版本开始,新增了 ByteBuf的池化机制。即创建一个缓冲区对象池,将没有被引用的 ByteBuf 对象,放入对象缓存池中;当需要时,则重新从对象缓存池中取出,而不需要重新创建。
在通信程序的数据传输过程中,Buffer缓冲区实例会被频繁创建、使用、释放,而频繁创建对象、内存分配、释放内存,这样导致系统的开销大、性能低,如何提升性能、提高Buffer实例的使用率呢?池化ByteBuf是一种非常有效的方式。
ByteBuf引用计数的大致规则如下:在默认情况下,当创建完一个ByteBuf时,它的引用为1;每次调用retain()方法,它的引用就加1;每次调用release()方法,就是将引用计数减1;如果引用为0,再次访问这个ByteBuf对象,将会抛出异常;如果引用为0,表示这个ByteBuf没有哪个进程引用它,它占用的内存需要回收。
@Test
public void testRef() {
ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer();
System.out.println("after create:" + buffer.refCnt());
buffer.retain(); //增加一次引用计数
System.out.println("after retain:" + buffer.refCnt());
buffer.release(); //减少一次引用计数
System.out.println("after release:" + buffer.refCnt());
buffer.release(); //减少一次引用计数
System.out.println("after release:" + buffer.refCnt());
//错误:refCnt: 0,不能再 retain
buffer.retain(); //增加一次引用计数
System.out.println("after retain:" + buffer.refCnt());
}
输出:
after create:1
after retain:2
after release:1
after release:0
io.netty.util.IllegalReferenceCountException: refCnt: 0, increment: 1
......
ByteBuf的自动创建与自动释放
首先来一个问题:在pipeline入站处理时,Netty是何时自动创建入站的ByteBuf缓冲区呢?
-
ByteBuf的自动创建
查看Netty源代码,我们可以看到,Netty的Reactor反应器线程会通过底层的Java NIO通道读数据,发生NIO读取的方法为AbstractNioByteChannel.NioByteUnsafe.read()方法

分配缓冲区的时候,为啥要进行大小的计算呢?从通道里读取时,是不知道具体的接收数据大小的,那么申请的缓冲区具体要多大呢?首先不能太大,太大了浪费,其次也不能太小你,太小了又不够,可能要涉及扩容,性能不好,所以申请的缓冲区大小需要推测,Netty设计了一个
RecvByteBufAllocator大小推测接口和一系列的大小推测实现类,帮助进行缓冲区大小的计算和推测。默认的缓冲区大小推测实现类为AdaptiveRecvByteBufAllocator,其特点是能够根据上一次接收数据的大小,来自动调整下一次缓冲区建立时分配的空间大小,从而帮助避免内存的浪费。
再来一个问题:在入站处理完成时,入站的ByteBuf是如何自动释放的呢?
-
自动释放方式一:TailContext自动释放
Netty默认会在ChannelPipline通道流水线的最后添加一个TailContext尾部上下文(也是一个入站处理器),它实现了默认的入站处理方法,在这些方法中会帮助完成ByteBuf内存释放的工作,具体如下图所示:
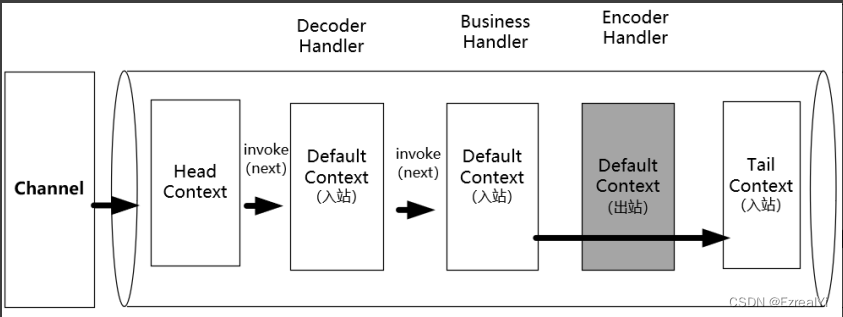
-
自动释放方式二:SimpleChannelInboundHandler自动释放
以入站读数据为例,Handler业务处理器可以继承自SimpleChannelInboundHandler基类,此时必须将业务处理代码,移动到重写的channelRead0(ctx, msg)方法中。SimpleChannelInboundHandle类的入站处理方法(如channelRead等),会在调用完实际的channelRead0(…) 方法后,帮忙释放ByteBuf实例。

高级使用:ByteBuf的浅层复制
首先说明一下,浅层复制是一种非常重要的操作。可以很大程度地避免内存复制。这一点对于大规模消息通信来说是非常重要的。ByteBuf的浅层复制分为两种,有切片(slice)浅层复制和整体(duplicate)浅层复制。
-
slice切片浅层复制
ByteBuf的slice方法可以获取到一个ByteBuf的一个切片。一个ByteBuf可以进行多次的切片浅层复制;多次切片后的ByteBuf对象可以共享一个存储区域。
slice方法有两个重载版本:
- public ByteBuf slice()
- public ByteBuf slice(int index, int length)
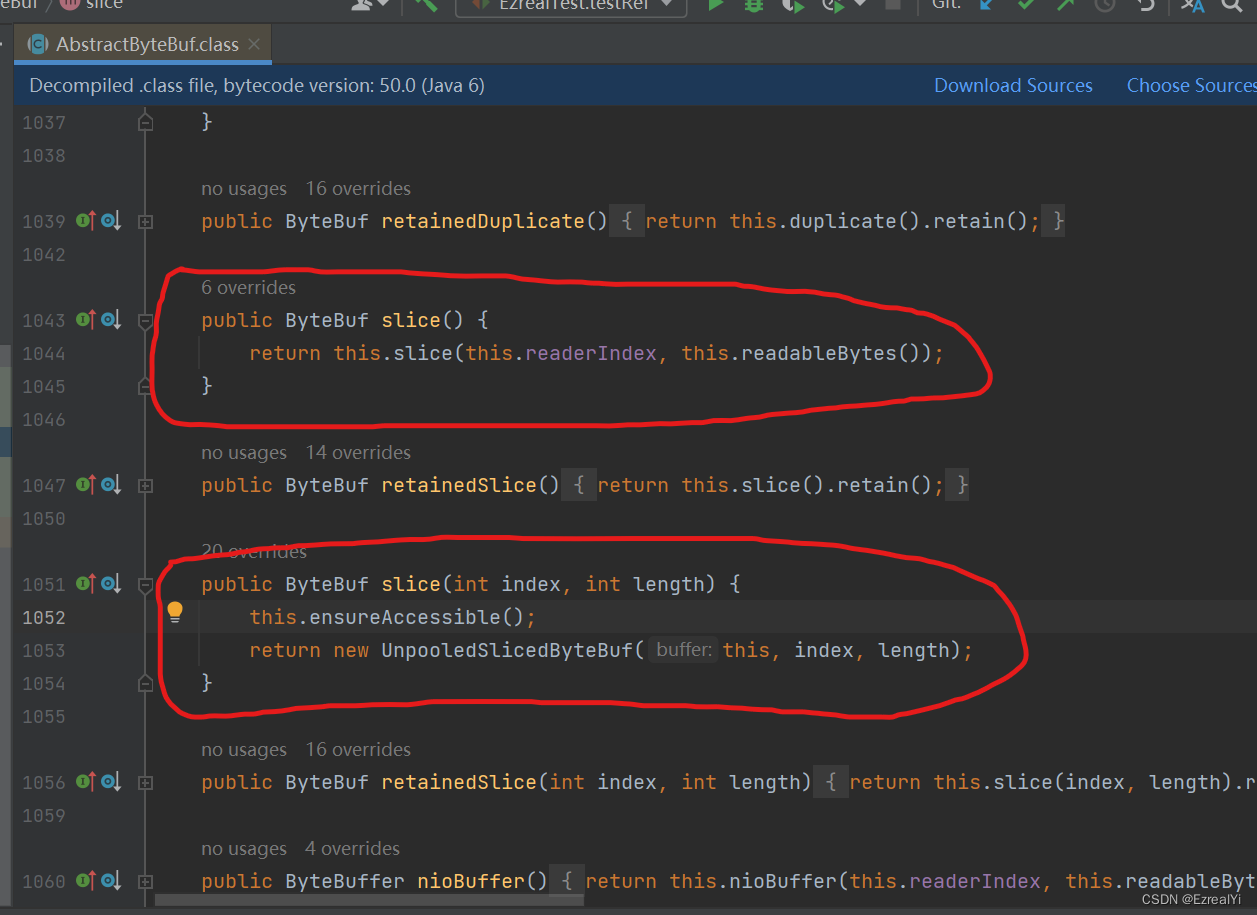
也就是说,第一个无参数slice方法的返回值是ByteBuf实例中可读部分的切片。而带参数的
slice(int index, int length)方法,可以通过灵活地设置不同起始位置和长度,来获取到ByteBuf不同区域的切片。@Test public void sliceTest() { ByteBuf byteBuf = null; ByteBuf slice = null; try { byteBuf = Unpooled.buffer(9, 100); byteBuf.writeBytes(new byte[]{1, 2, 3, 4}); System.out.println("init: " + byteBuf); byteBuf.retain(); slice = byteBuf.slice(); System.out.println("slice: " + slice); // 读取byte,会改变slice的readerIndex + 1 byte readByte = slice.readByte(); System.out.println("byteBuf after read: " + byteBuf); System.out.println("slice after read: " + slice); } finally { Optional.ofNullable(byteBuf).ifPresent(buf -> buf.release()); Optional.ofNullable(slice).ifPresent(buf -> buf.release()); } } 输出: init: UnpooledByteBufAllocator$InstrumentedUnpooledUnsafeHeapByteBuf(ridx: 0, widx: 4, cap: 9/100) slice: UnpooledSlicedByteBuf(ridx: 0, widx: 4, cap: 4/4, unwrapped: UnpooledByteBufAllocator$InstrumentedUnpooledUnsafeHeapByteBuf(ridx: 0, widx: 4, cap: 9/100)) byteBuf after read: UnpooledByteBufAllocator$InstrumentedUnpooledUnsafeHeapByteBuf(ridx: 0, widx: 4, cap: 9/100) slice after read: UnpooledSlicedByteBuf(ridx: 1, widx: 4, cap: 4/4, unwrapped: UnpooledByteBufAllocator$InstrumentedUnpooledUnsafeHeapByteBuf(ridx: 0, widx: 4, cap: 9/100))单元测试第二条输出结果可知,切片slice相当于一个独立的只可读(ridx: 0)不可写( widx: 4, cap: 4/4)的副本,副本的读操作导致readerIndex的改变不会影响源ByteBuf,所以对于源ByteBuf多次读,可以创建多个slice浅层复制。但是源ByteBuf引用计数为零,将导致slice不可用,后面介绍。另外,切片不会复制源ByteBuf的底层数据,底层数组和源ByteBuf的底层数组是同一个。
-
duplicate整体浅层复制
和slice切片不同,duplicate() 返回的是源ByteBuf的整个对象的一个浅层复制。duplicate() 和slice() 方法都是浅层复制。不同的是,slice()方法是切取一段的浅层复制,而duplicate( )是整体的浅层复制。
-
浅层复制的问题
浅层复制方法不会实际去复制数据,也不会改变ByteBuf的引用计数,这就会导致一个问题:在源ByteBuf调用release() 之后,一旦引用计数为零,就变得不能访问了;在这种场景下,源ByteBuf的所有浅层复制实例也不能进行读写了;如果强行对浅层复制实例进行读写,则会报错。
因此,在调用浅层复制实例时,可以通过调用一次retain() 方法来增加一次引用,表示它们对应的底层内存多了一次引用,此后引用计数为2。在浅层复制实例用完后,需要调用一次release()方法,将引用计数减1,这样就不影响Netty内部的ByteBuf的内存释放。
Netty的零拷贝
大部分的场景下,Netty的接收和发送ByteBuffer的过程中,一般来说会使用直接内存进行Socket通道读写,使用JVM的堆内存进行业务处理,会涉及到直接内存、堆内存之间的数据复制。但是,内存的数据复制,其实是效率非常低的,Netty提供了多种方法,帮助应用程序减少内存的复制。
Netty的零拷贝主要体现在五个方面:
- Netty提供CompositeByteBuf组合缓冲区类, 可以将多个ByteBuf合并为一个逻辑上的ByteBuf, 避免了各个ByteBuf之间的拷贝。
- Netty提供了ByteBuf的浅层复制操作(slice、duplicate),可以将ByteBuf分解为多个共享同一个存储区域的ByteBuf, 避免内存的拷贝。
- 在使用Netty进行文件传输时,可以调用FileRegion包装的transferTo方法,直接将文件缓冲区的数据发送到目标Channel,避免普通的循环读取文件数据和写入通道所导致的内存拷贝问题。
- 在将一个byte数组转换为一个ByteBuf对象的场景,Netty提供了一系列的包装类,避免了转换过程中的内存拷贝。
- 如果Channel接收和发送ByteBuf都使用direct直接内存进行Socket读写,不需要进
- 行缓冲区的二次拷贝。但是,如果使用JVM的堆内存进行Socket读写,JVM会将堆内存Buffer拷贝一份到直接内存中,然后才写入Socket中,相比于使用直接内存,这种情况在发送过程中会多出一次缓冲区的内存拷贝。所以,在发送ByteBuffer到Socket时,尽量使用直接内存而不是JVM堆内存。
Netty 中的零拷贝和操作系统层面上的零拷贝是有区别的,不能混淆,我们所说的Netty 零拷贝完全是基于(Java 层面)或者说用户空间的,它的更多的是偏向于应用中的数据操作优化,而不是系统层面的操作优化。
-
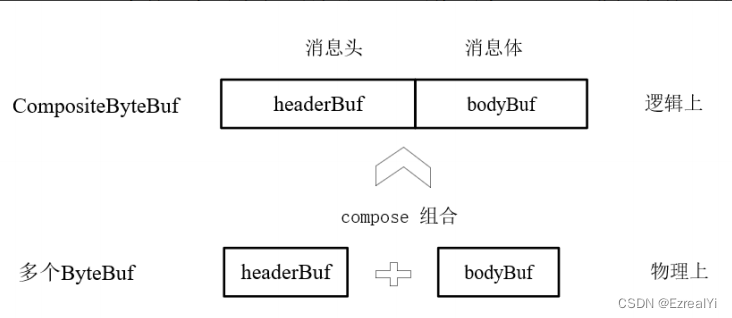
通过CompositeByteBuf实现零拷贝
CompositeByteBuf可以把需要合并的多个ByteBuf组合起来,对外提供统一的readIndex和writerIndex。CompositeByteBuf 只是逻辑上是一个整体,在CompositeByteBuf内部, 合并的多个ByteBuf都是单独存在的。CompositeByteBuf里面有个Component数组,聚合的ByteBuf都放在Component数组里面,最小容量为16。
在很多通信编程场景下,需要多个ByteBuf组成一个完整的消息:例如HTTP协议传输时消息总是由Header(消息头)和Body(消息体)组成的。如果传输的内容很长,就会分成多个消息包进行发送,消息中的Header就需要重用,而不是每次发送都创建新的Header缓冲区。这时候可以使用CompositeByteBuf缓冲区进行ByteBuf组合,避免内存拷贝。
假设有一份协议数据,它由头部和消息体组成,而头部和消息体是分别存放在两个ByteBuf中的, 为了方便后续处理,要将两个ByteBuf进行合并
-
通过wrap操作实现零拷贝
Unpooled了提供了一系列的wrap包装方法,帮助大家方便快速包装出CompositeByteBuf实例或者ByteBuf实例,而不用进行内存的拷贝。
Unpooled包装CompositeByteBuf的操作,使用起来更加方便。例如,上一小节的header与body的组合,可以使用 Unpooled.wrappedBuffer方法。
Unpooled类提供了很多重载的wrappedBuffer方法,将多个ByteBuf包装为CompositeByteBuf实例,从而实现零拷贝,这些重载方法大致如下:
public static ByteBuf wrappedBuffer(ByteBuffer buffer) public static ByteBuf wrappedBuffer(ByteBuf buffer) public static ByteBuf wrappedBuffer(ByteBuf... buffers) public static ByteBuf wrappedBuffer(ByteBuffer... buffers)除了通过Unpooled包装CompositeByteBuf之外,还可以将byte数组包装成ByteBuf。如果将一个byte数组转换为一个ByteBuf对象,大致的代码如下
byte[] bytes = ... ByteBuf byteBuf = Unpooled.wrappedBuffer(bytes);通过Unpooled.wrappedBuffer方法将bytes包装为一个UnpooledHeapByteBuf对象, 而在包装的过程中, 不会有拷贝操作的,所得到的ByteBuf对象是和bytes数组共用了同一个存储空间,对bytes的修改也就是对ByteBuf对象的修改。
@Test public void wrappedByteBufTest() { byte[] bytes = new byte[]{1, 2, 3, 4, 5, 6, 7, 8, 9}; // 将数组包装成ByteBuf ByteBuf byteBuf = Unpooled.wrappedBuffer(bytes); System.out.println(byteBuf); byte[] copy = new byte[9]; byteBuf.getBytes(0, copy); for (byte b : copy) { System.out.print(b); } System.out.println(); // 修改数组,ByteBuf内容跟着变 bytes[1] = 5; System.out.println(byteBuf); byteBuf.getBytes(0, copy); for (byte b : copy) { System.out.print(b); } System.out.println(); // 修改ByteBuf,数组跟着变。。。所以包装的ByteBuf底层只是拷贝了数组地址(浅拷贝),而不是拷贝内容 byteBuf.setByte(0, 9); for (byte b : bytes) { System.out.print(b); } System.out.println(); byteBuf.release(); } 输出: UnpooledHeapByteBuf(ridx: 0, widx: 9, cap: 9/9) 123456789 UnpooledHeapByteBuf(ridx: 0, widx: 9, cap: 9/9) 153456789 953456789
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











