







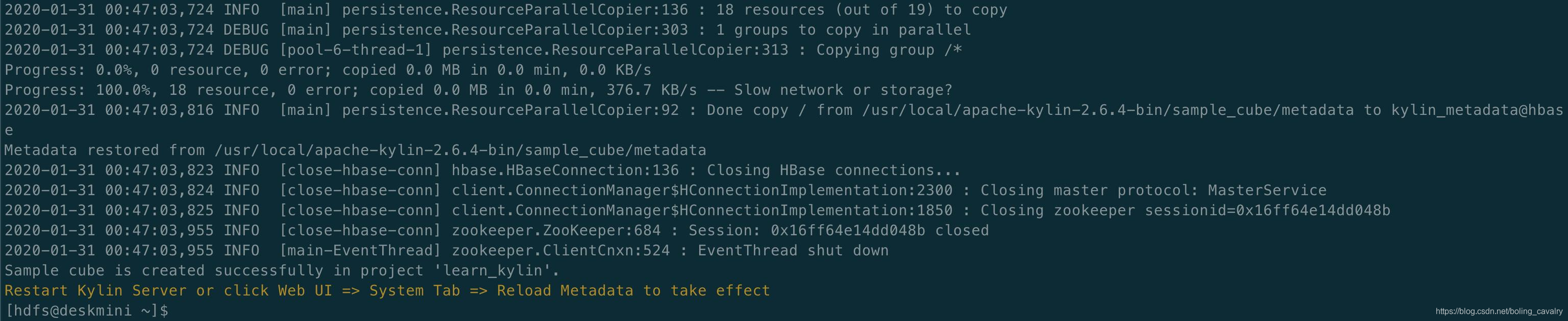
检查数据
- 检查数据,执行beeline进入会话模式(hive官方推荐用beeline取代Hive CLI):

- 在beeline会话模式输入链接URL:!connect jdbc:hive2://localhost:10000,按照提示输入账号hdfs,密码直接回车:
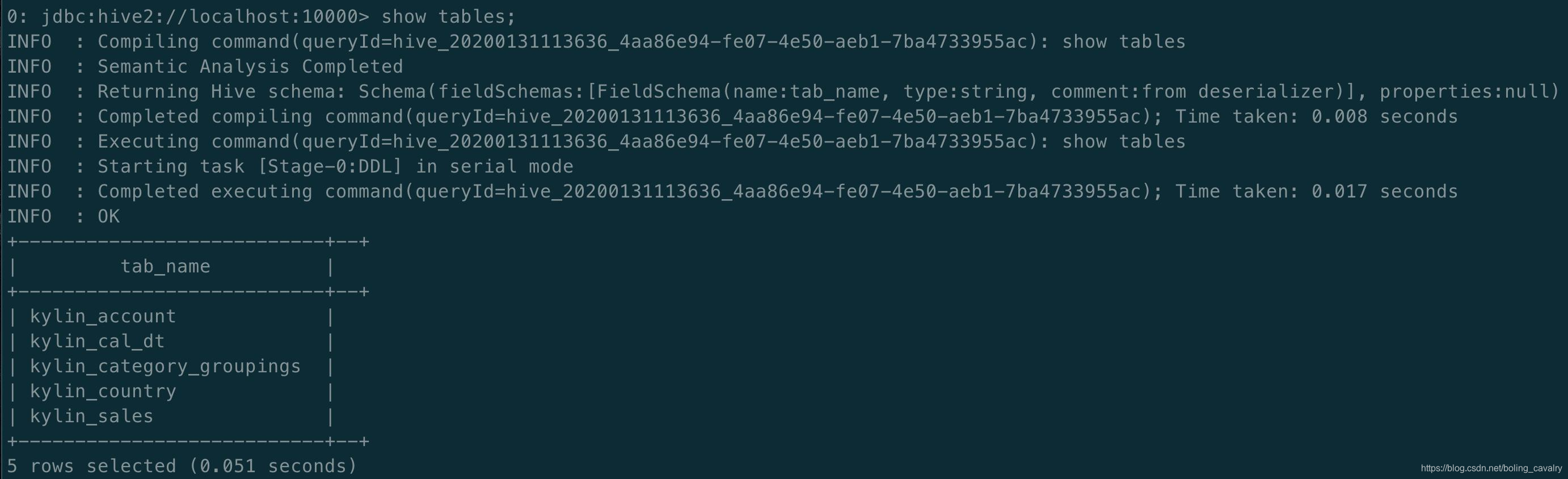
- 用命令show tables查看当前的hive表,已建好:
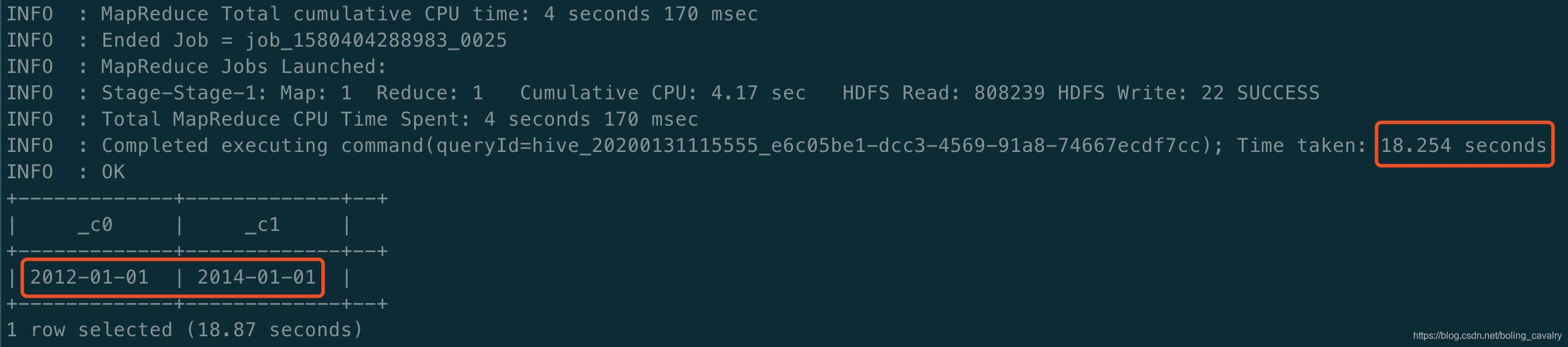
- 查出订单的最早和最晚时间,后面构建Cube的时候会用到,执行SQL:select min(PART_DT), max(PART_DT) from kylin_sales; ,可见最早2012-01-01,最晚2014-01-01,整个查询耗时18.87秒:
构建Cube:
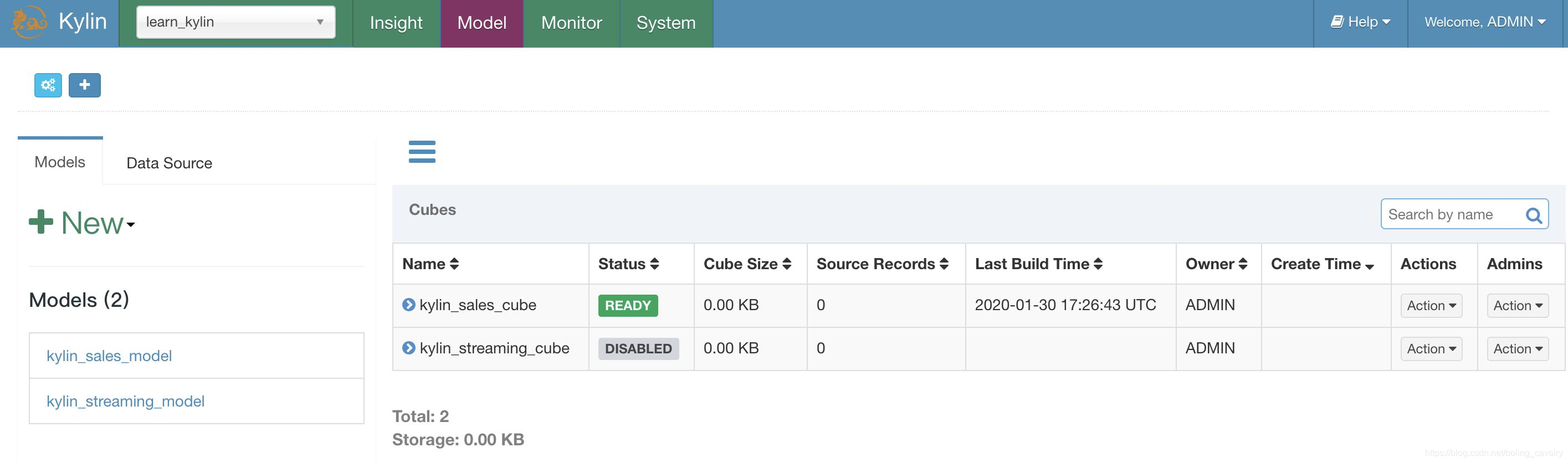
数据准备完成,可以构建Kylin Cube了:
-
登录Kylin网页:http://192.168.50.134:7070/kylin
-
加载Meta数据,如下图:
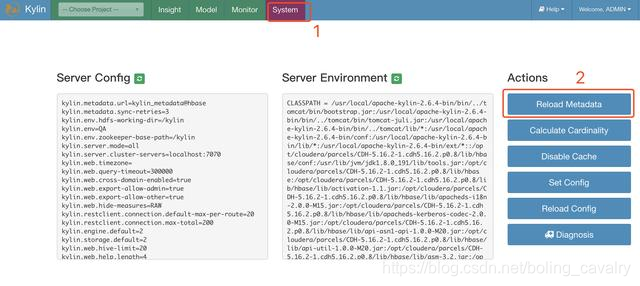
- 如下图红框所示,数据加载成功:
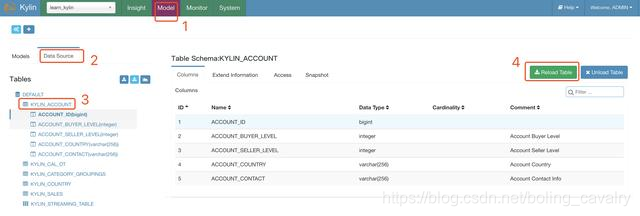
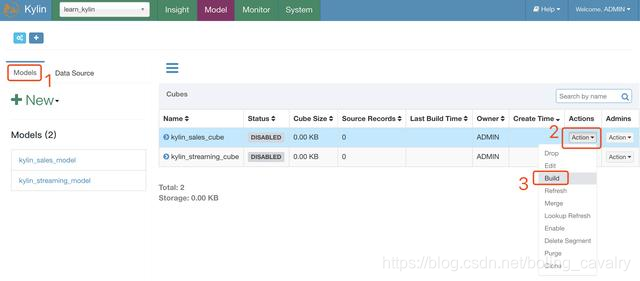
- 在Model页面可以看到事实表和维度表,如下图的操作可以创建一个MapReduce任务,计算维度表KYLIN_ACCOUNT每个列的基数(Cardinality):
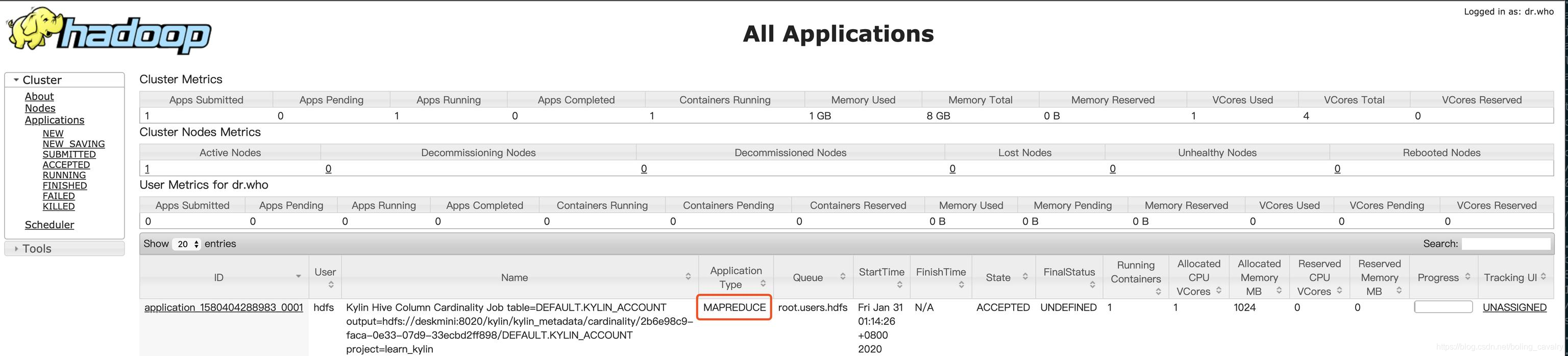
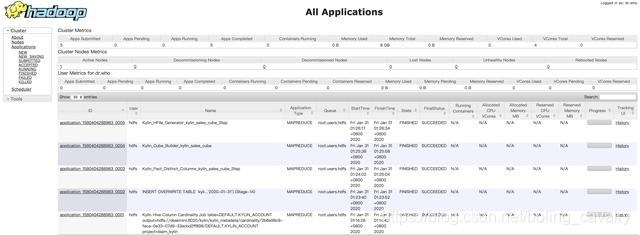
- 去Yarn页面(CDH服务器的8088端口),如下图,可见有个MapReduce类型的任务正在执行中:
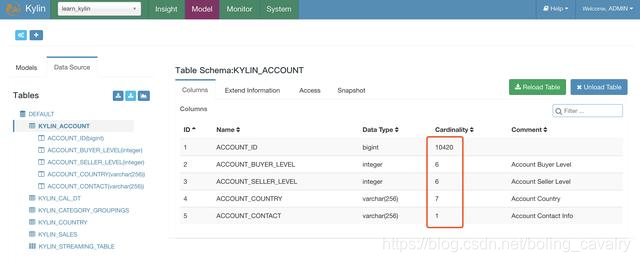
- 上述任务很快就能完成(10多秒),此时刷新Kylin页面,可见KYLIN_ACCOUNT表的Cardinality数据已经计算完成了(hive查询得到ACCOUNT_ID数量是10000,但下图的Cardinality值为10420,Kylin对Cardinality的计算采用的是HyperLogLog的近似算法,与精确值有误差,其他四个字段的Cardinality与Hive查询结果一致):
- 接下来开始构建Cube:
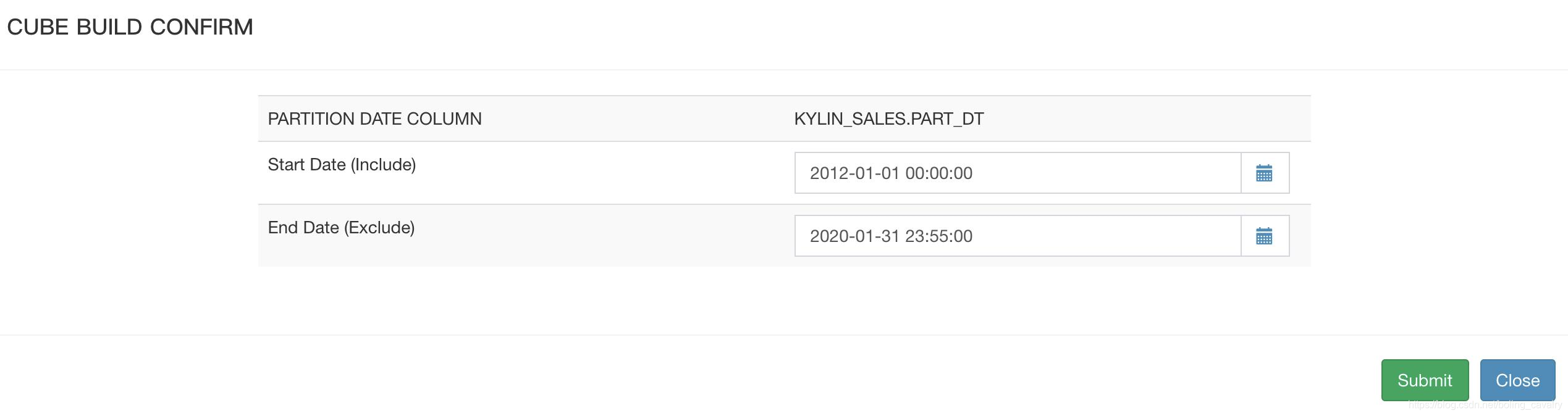
- 日期范围,刚才Hive查询结果是2012-01-01到2014-01-01,注意截止日期要超过2014-01-01:
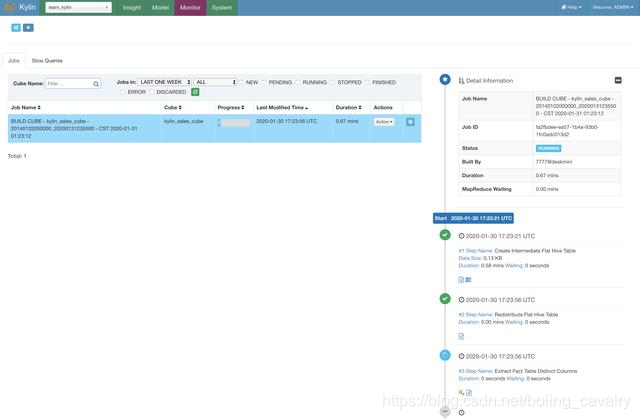
- 在Monitor页面可见进度:
- 去Yarn页面(CDH服务器的8088端口),可以看到对应的任务和资源使用情况:
- build完成后,会出现ready图标:
查询
- 先尝试查询交易的最早和最晚时间,这个查询在Hive上执行的耗时是18.87秒,如下图,结果一致,耗时0.14秒:

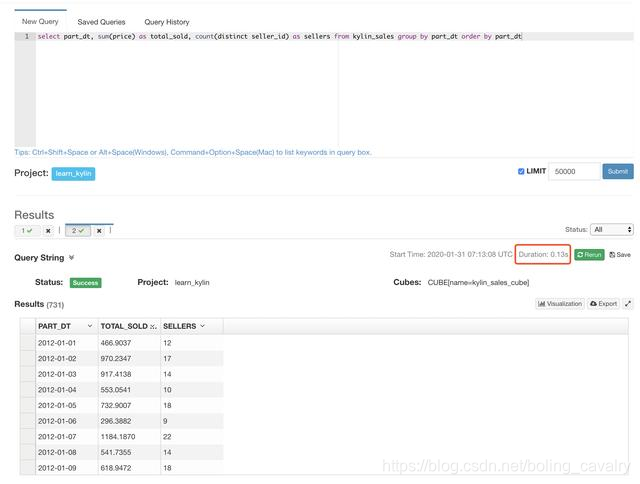
- 下面这个SQL是Kylin官方示例用来对比响应时间的,对订单按日期聚合,再按日期排序,然后接下来分别用Kylin和Hive查询:
select part_dt, sum(price) as total_sold, count(distinct seller_id) as sellers from kylin_sales group by part_dt order by part_dt;
- Kylin查询耗时0.13秒:
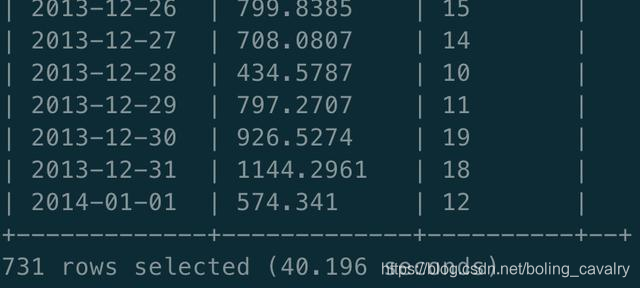
- Hive查询,结果相同,耗时40.196秒:
- 最后来看下资源使用情况,Cube构建过程中,18G内存被使用:
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注:Java)

读者福利

更多笔记分享

《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
1713816070994)]
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!















 299
299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









