







作者 | 张彦飞allen
来源 | 开发内功修炼
今天我给大家分享一个内核中常用的提升性能的小技巧。理解了它对你一定大有好处。
在内核中很多地方都充斥着 likely、unlikely 这一对儿函数的使用。随便揪两处,比如在 TCP 连接建立的过程中的这两个函数。
//file: net/ipv4/tcp_ipv4.c
int tcp_v4_conn_request(struct sock *sk, struct sk_buff *skb)
{
if (likely(!do_fastopen))
...
}
//file: net/ipv4/tcp_input.c
int tcp_rcv_established(struct sock *sk, ...)
{
if (unlikely(sk->sk_rx_dst == NULL))
......
}在刚开始看源码的时候,我也没弄懂这一对儿函数的玄机。后来才搞懂它原来对性能提升是有帮助的。今天我就来和大家聊聊 likely、unlikely 是如何帮助性能提升的。
1. likely 和 unlikely
咱们先来挖挖这对儿函数的底层实现。
//file: include/linux/compiler.h
#define likely(x) __builtin_expect(!!(x),1)
#define unlikely(x) __builtin_expect(!!(x),0)可以看到其实它们就是对 __builtin_expect 的一个封装而已。__builtin_expect 这个指令是 gcc 引入的。该函数作用是允许程序员将最有可能执行的分支告诉编译器,来辅助系统进行分支预测。
(参见 https://gcc.gnu.org/onlinedocs/gcc/Other-Builtins.html)
它的用法为:__builtin_expect(EXP, N)。意思是:EXP == N的概率很大。那么上面 likely 和 unlikely 这两句的具体含义就是:
__builtin_expect(!!(x),1) x 为真的可能性更大
__builtin_expect(!!(x),0) x 为假的可能性更大
当正确地使用了__builtin_expect后,编译器在编译过程中会根据程序员的指令,将可能性更大的代码紧跟着前面的代码,从而减少指令跳转带来的性能上的下降。
2. 实际动手验证
那我们实际动手写两个例子,来窥探一下编译器是如何进行优化的。为此我写了一段简单的测试代码,如下:
#include <stdio.h>
#define likely(x) __builtin_expect(!!(x), 1)
#define unlikely(x) __builtin_expect(!!(x), 0)
int main(int argc, char *argv[])
{
int n;
n = atoi(argv[1]);
if (likely(n == 10)){
n = n + 2;
} else {
n = n - 2;
}
printf("%d\n", n);
return 0;
}这段代码非常简单,对用户的输入做一个 if else 判断。在 if 中使用了 likely,也就是假设这个条件为真的概率更大。那么我们来看看它编译后的汇编码来看看。
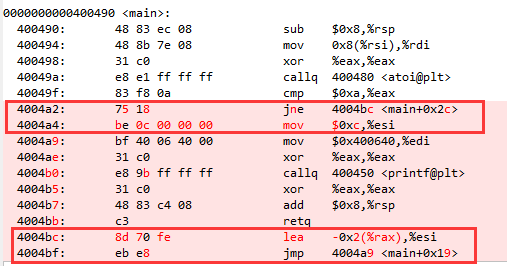
图中上面红框内是对 if 的汇编结果,可见它使用的是 jne 指令。它的作用是看它的上一句比较结果,如果不相等则跳转到 4004bc 处,相等的话则继续执行后面的指令。
在 jne 指令后面紧挨着的是 n = n + 2 对应的汇编代码, 也就是说它把 n = n + 2 这段代码逻辑放在了紧挨着自己身边。而把 n = n - 2 的执行逻辑放在了离当前指令较远的 4004bc 处。
我们再把 likey 换成 unlikey 看一下,发现结果是正好相反,这次把 n = n - 2 的执行逻辑放在前面了,如图。
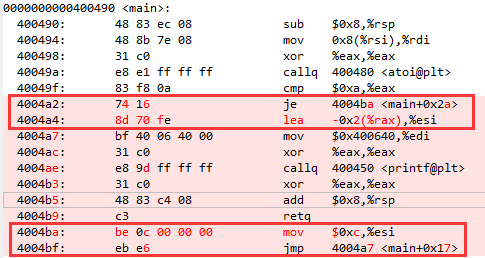
注意,编译时需要加 -O2 选项,使用 objdump -S 来查看汇编指令。为了方便大家使用,我把它写到 makefile 里了,和测试代码一起放到了咱们的 Github 上了。
大家想动手的可以玩玩,地址:
https://github.com/yanfeizhang/coder-kung-fu/tree/main/tests/cpu/test01
3. 性能提升原理
那这么做为什么就能够提升程序运行性能呢?原因有两个。
首先第一个原因就是 CPU 高速缓存。现代的 CPU 一般都有三级的缓存,用来解决内存访问过慢的问题。访问数据时优先从 L1 读取,读取不到再读 L2、还读不到就读 L3,最后用内存兜底。
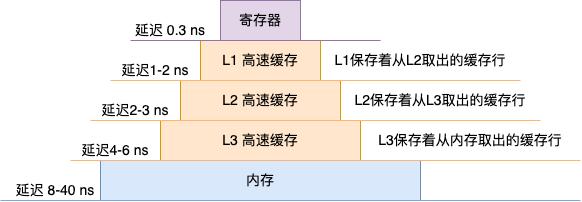
这里要注意的是,每一次缓存数据的单位都是以一个 CacheLine 64 字节为单位进行存储的。假如说要查询的数据在 L1 中不存在,那么 CPU 的做法是一次性从 L2 中把要访问的数据及其后面的 64 个字节全部缓存进来。
假如下一次再执行的时候要访问的指令在上一次已经在 L1 中存在了,那么就直接访问 L1,就不必再从 L2 来读取了。回到上面的例子,假如说我们执行完了 cmp 对比指令以后,判断确实是要进加法分支,那紧接着就会执行 jne 后面的 mov xor 等指令大概率就可以从 L1 中取到了。
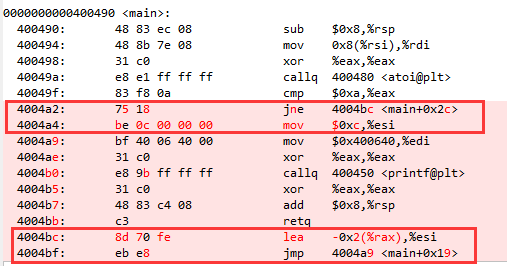
假如说 cmp 对比执行后,发现是要跳到 4004bc 处的指令执行。那大概率该位置处的指令还没有被加载到缓存中(实践中一个分支下可能会包含很多代码,而不是像我这个例子中简单的两三行),就避免不了从 L2 L3 甚至是速度更慢的 L3 去读取指令。
除了高速缓存这个原因以外,还有一个更底层的原理。那就是 CPU 的流水线技术。CPU 在执行程序指令的时候,并不是先执行一个,执行完了再运行下一个这样的。而是把每个指令都分成了多个阶段,并让不同指令的各步操作重叠,从而实现几条指令并行处理。
还拿上面编译出来的汇编码来举例,程序中 cmp、jne、mov 几个指令是挨着的,那么 CPU 在执行的时候实际是大概这样的。
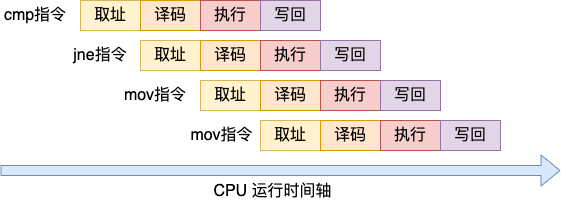
当 jne 指令正在执行的时候,后面的两个 mov 指令都已经分别进入到译码和取址阶段了都。假如说分支预测失败,那么这工作就白干了。
4. 小结
总结一下,今天分享的 likely 和 unlikely 其实是属于是辅助 CPU 分支预测的性能优化方法。这就是 likely 和 unlikely 背后的这点小秘密。它是为了让 CPU 的高速缓存命中率更高,同时也为了让 CPU 的流水线更好地工作。
Linux 作为一个基础程序,在性能上真的是考虑到了极致。内核的作者们内功都是非常的深厚,都深谙计算机的底层工作原理。为了极致的性能追求精心打磨每一个细节,非常值得我们学习和借鉴。
不过这里要说的一点是,likely 和 unlikely 的概率判断务必准确。如果写反了,反而会起到反作用。

往期推荐
JavaScript 数组你都掰扯不明白,还敢说精通 JavaScript ?

点分享

点收藏

点点赞

点在看














 2071
2071











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









