







x264代码剖析(十七):核心算法之熵编码(Entropy Encoding)
熵编码是无损压缩编码方法,它生产的码流可以经解码无失真地恢复出原始数据。熵编码是建立在随机过程的统计特性基础上的。本文对熵编码中的CAVLC(基于上下文自适应的可变长编码)和CABAC(基于上下文的自适应二进制算术熵编码)进行简单介绍,并给出x264中熵编码对应的代码分析。
在H.264的CAVLC中,通过根据已编码句法元素的情况,动态调整编码中使用的码表,取得了极高的压缩比。CAVLC用于亮度和色度残差数据的编码,CAVLC充分利用残差经过整数变换、量化后数据的特性进行压缩,进一步减少数据中的冗余信息,为H.264的编码效率的提升奠定了基础。
CAVLC的编码过程主要包括以下五个步骤:
(1)对非零系数的数目(TotalCoeffs)以及拖尾系数的数目(TrailingOnes)进行编码;
(2)对每个拖尾系数的符号进行编码;
(3)对除了拖尾系数之外的非零系数的幅值(Levels)进行编码;
(4)对最后一个非零系数前零的数目(TotalZeros)进行编码;
(5)对每个非零系数前零的个数(RunBefore)进行编码。
在最新国际视频编码标准(High Efficiency Video Coding, HEVC)中,熵编码模块摒弃了CAVLC(基于上下文自适应的可变长编码),而仅仅采用了CABAC(基于上下文的自适应二进制算术熵编码),故本文只分析CAVLC在x264中的代码,对于CABAC的原理以及代码分析将在x265相关的代码分析文章中进行介绍。
在x264中,熵编码模块对应的函数关系图如下图所示:
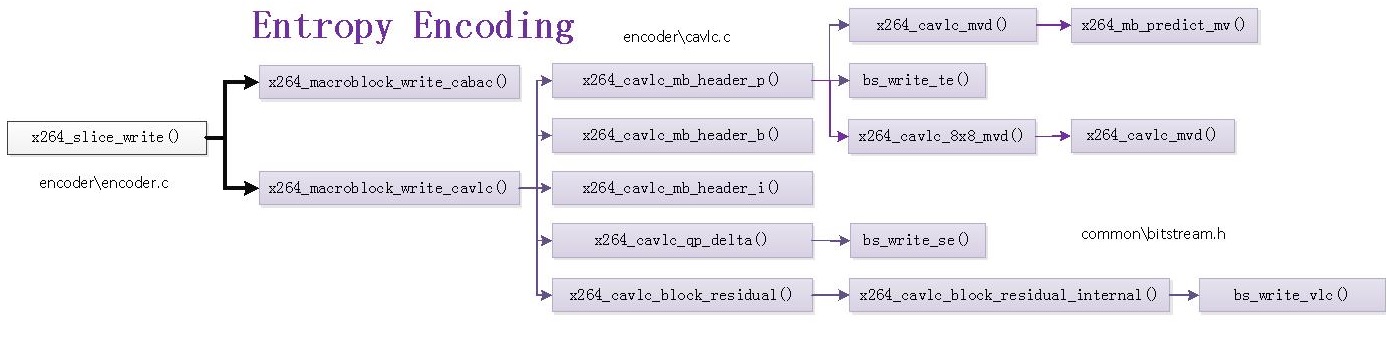
从图中可以看出,熵编码模块包含两个函数x264_macroblock_write_cabac()和x264_macroblock_write_cavlc()。如果输出设置为CABAC编码,则会调用x264_macroblock_write_cabac();如果输出设置为CAVLC编码,则会调用x264_macroblock_write_cavlc()。本文选择CAVLC编码输出函数x264_macroblock_write_cavlc()进行分析。该函数调用了如下函数:
(1)x264_cavlc_mb_header_i():写入I宏块MB Header数据。包含帧内预测模式等。
(2)x264_cavlc_mb_header_p():写入P宏块MB Header数据。包含MVD、参考帧序号等。
(3)x264_cavlc_mb_header_b():写入B宏块MB Header数据。包含MVD、参考帧序号等。
(4)x264_cavlc_qp_delta():写入QP。
(5)x264_cavlc_block_residual():写入残差数据。
1、x264_slice_write()函数
x264_slice_write()是完成编码工作的函数。该函数中包含了去块效应滤波,运动估计,宏块编码,熵编码等模块。x264_slice_write()调用了如下函数:
x264_nal_start():开始写一个NALU。
x264_macroblock_thread_init():初始化宏块重建数据缓存fdec_buf[]和编码数据缓存fenc_buf[]。
x264_slice_header_write():输出 Slice Header。
x264_fdec_filter_row():滤波模块。该模块包含了环路滤波,半像素插值,SSIM/PSNR的计算。
x264_macro
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 231
231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









