







牛客网Java面试题集锦
2022.3.3
1.权限修饰符
题目
下列哪个修饰符可以使在一个类中定义的成员变量只能被同一包中的类访问?
private 无修饰符 protected public
知识点
权限修饰符 类内部 本包下(所有类) 子类 任何地方
private √
缺省|无修饰符 √ √
protected √ √ √
public √ √ √ √
进一步解释
「包访问权限:」 没有任何修饰符的权限就是**「包访问权限」,意味着当前包的所有类都可以访问这个成员,如表中所示,对于本包之外的类,这个成员就变成了「private」**,访问不了
「public:」 被public修饰的成员对任意一个类都是可用的,任何一个类都可以访问到,通过操作该类的对象随意访问**「public」**成员
「protected:」 在相同的class内部,同一个包内和其他包的子类中能被访问。要理解**「protected」权限,就需要了解「继承」,因为这个权限处理的就是继承相关的概念,继承而来的子类可以访问「public、protected」**,
2.字符流与字节流
题目
下面的类哪些可以处理Unicode字符?
A.InputStreamReader
B.BufferedReader
C.Writer
D.PipedInputStream
解析
本题主要考察字符流和字节流。字符流是字节流根据字节流所要求的编码集解析获得的,可以理解为字符流=字节流+编码集,字符流处理的单元为2个字节的Unicode字符,分别操作字符、字符数组或字符串,而字节流处理单元为1个字节,操作字节和字节数组。
字符流有关的类都拥有操作编码集(unicode)的能力,以Reader|Writer结尾都是字符流,以Stream结尾都是字节流。如果是单选的话选择A,多选就选ABC。
3.多态与向上转型&类型强转与向下转型
题目
class Base
{
public void method()
{
System.out.println("Base");
}
}
class Son extends Base
{
public void method()
{
System.out.println("Son");
}
public void methodB()
{
System.out.println("SonB");
}
}
public class Test01
{
public static void main(String[] args)
{
Base base = new Son();
base.method();
base.methodB();
}
}
//问打印结果
解析
Base base=new Son(); 是多态的表示形式即父类的引用指向子类的对象,所以要遵循编译看左边运行看右边的原则,base.methodB();编译不通过,因为父类没有methodB()方法,其次base.method()运行时打印的是子类重写的方法。同时也是向上转型的体现,则父类的引用无法访问子类独有的方法。
这时如果必须要调用methodB()可以使用类型强转即先通过SON son=(SON)base;强制转换,然后用son.methodB()调用就可以了
知识点
java多态有两种情况:重载和覆写
在覆写中,运用的是动态单分配,是根据new的类型确定对象,从而确定调用的方法;
在重载中,运用的是静态多分派,即根据静态类型确定对象,因此不是根据new的类型确定调用的方法
具体来说:
1.成员变量:编译和运行都参考左边。
2.成员函数(非静态):编译看左边,运行看右边
3.静态函数:编译和运行都看左边。
总结一句话–只有非静态方法运行才看右边,静态方法,成员变量编译运行都看左,非静态方法编译看左
4.synchronized同步锁
题目
public class Test {
private synchronized void a() {
}
private void b() {
synchronized (this) {
}
}
private synchronized static void c() {
}
private void d() {
synchronized (Test.class) {
}
}
}
//以下描述正确的是
//A同一个对象,分别调用方法a和b,锁住的是同一个对象
//B同一个对象,分别调用方法a和c,锁住的是同一个对象
//C同一个对象,分别调用方法b和c,锁住的不是同一个对象
//D同一个对象,分别调用方法a、b、c,锁住的不是同一个对象
解析
方法a为同步方法,方法b里面的是同步代码块,同步方法使用的锁是固有对象this,同步块使用的锁可以是任意对象,但是方法b里面的同步块使用的锁是对象this,所以方法a和方法b锁住的是同一个对象。
方法 c为静态同步方法,使用的锁是该类的字节码文件,也就是Test.class。方法d里面的也是同步块,只不过使用的锁是Test.class,所以方法c和方法d锁住的是同一个对象。
知识点
Java中Synchronized的用法(简单介绍) - 韦邦杠 - 博客园 (cnblogs.com)
synchronized是Java中的关键字,是一种同步锁。它修饰的对象有以下几种:
1. 修饰一个代码块,被修饰的代码块称为同步语句块,其作用的范围是大括号{}括起来的代码,**同步块使用的锁可以是任意对象**
2. 修饰一个方法,被修饰的方法称为同步方法,其作用的范围是整个方法,**同步方法使用的锁是固有对象this**;
3. 修饰一个静态的方法,其作用的范围是整个静态方法,**使用的锁是该类的字节码文件**;
4. 修饰一个类,其作用的范围是synchronized后面括号括起来的部分,作用主的对象是这个类的所有对象。
用synchronized修饰方法时要注意以下几点:
- synchronized关键字不能继承。如果在父类中的某个方法使用了synchronized关键字,而在子类中覆盖了这个方法,在子类中的这个方法默认情况下并不是同步的,而必须显式地在子类的这个方法中加上synchronized关键字才可以。当然,还可以在子类方法中调用父类中相应的方法,这样虽然子类中的方法不是同步的,但子类调用了父类的同步方法,因此,子类的方法也就相当于同步了。
- 在定义接口方法时不能使用synchronized关键字
- 构造方法不能使用synchronized关键字但可以使用synchronized代码块来进行同步
2022.3.4
1.final关键字与数据类型转换
题目
//以下语句编译错误的是
byte b1=1,b2=2,b3,b6,b8;
final byte b4=4,b5=6,b7;
b3=(b1+b2); /*语句1*/
b6=b4+b5; /*语句2*/
b8=(b1+b4); /*语句3*/
b7=(b2+b5); /*语句4*/
System.out.println(b3+b6);
解析
语句 1 :(b1 + b2) 被转换为int类型 但是 b3仍为 byte ,所以出错 要么将b3转化为int 要么将(b1 + b2) 强制转换为byte类型。所以语句1错误。
语句 2:b4 、b5被声明final 所以类型是不会转换, 计算结果任然是byte ,所以 语句2正确。
语句 3:(b1 + b4) 结果仍然转换成int 所以语句 3 错误。
语句 4 : (b2 + b5) 结果仍然转换为int , 所以语句4错误。
知识点
一、关于final的重要知识点;
1、final关键字可以用于成员变量、本地变量|局部变量、方法以及类。
final关键字修饰的变量类型不会转换
2、 final成员变量必须在声明的时候初始化或者在构造器中初始化,否则就会报编译错误。
3、 你不能够对final变量再次赋值。
4、 final修饰一个类时其本地变量必须在声明时赋值。
5、 在匿名类中所有变量都必须是final变量。
6、 final方法不能被重写,但可以重载
7、 final类不能被继承。
8、 没有在声明时初始化final变量的称为空白final变量(blank final variable),它们必须在构造器中初始化,或者调用this()初始化。不这么做的话,编译器会报错“final变量(变量名)需要进行初始化”。
9、final不能修饰抽象类和接口 ,否则抽象类不能继承,接口方法不能被重写就失去了二者的意义
二、数据类型转换 double->float->long->其它转int
- 算术运算时的数据类型转换
当使用 +、-、*、/、%、运算操作是,遵循如下规则:
只要两个操作数中有一个是double类型的,另一个将会被转换成double类型,并且结果也是double类型;
如果两个操作数中有一个是float类型的,另一个将会被转换为float类型,并且结果也是float类型;
如果两个操作数中有一个是long类型的,另一个将会被转换成long类型,并且结果也是long类型;
否则(操作数为:byte、short、int 、char),两个数都会被转换成int类型,并且结果也是int类型。
此外在进行/算术运算时,进行的操作是取整,如1/4 = 0 而 1/4.0则取小数
+=会自动强转(自动装箱功能),但是+必须要手动强转b=(byte)(a+b)
byte b1 = 2; byte b2 = 4; b1 = b1 + 4;错误 而b1 += b2正确
-
返回值时的数据类型转换
返回基本数据类型时也会有类型转换的需求,当实际返回值比要求的返回值范围小就会自动类型转换,反之需要强转后返回。例如float f1();要求返回float型的数据但我可以返回byte short long int型的数据,可以自动类型转换但是不能直接返回double类型数据需要先强转成float后再返回
三、数据类型转换小结
byte b = 1;
char c = 1;
short s = 1;
int i = 1;
// 三目,一边为byte另一边为char,结果为int
// 其它情况结果为两边中范围大的。适用包装类型
i = true ? b : c; // int
b = true ? b : b; // byte
s = true ? b : s; // short
// 表达式,两边为byte,short,char,结果为int型
// 其它情况结果为两边中范围大的。适用包装类型
i = b + c; // int
i = b + b; // int
i = b + s; // int
// 当 a 为基本数据类型时,a += b,相当于 a = (a的类型) (a + b)
// 当 a 为包装类型时, a += b 就是 a = a + b
b += s; // 没问题
c += i; // 没问题
// 常量任君搞,long以上不能越
b = (char) 1 + (short) 1 + (int) 1; // 没问题
// i = (long) 1 // 错误
2.Java反射机制
解析
普通的java对象是通过new关键字把对应类的字节码文件加载到内存,然后创建该对象的。
反射是通过一个名为Class的特殊类,用Class.forName(“className”);得到类的字节码对象,然后用newInstance()方法在虚拟机内部构造这个对象(针对无参构造函数)。
也就是说反射机制让我们可以先拿到java类对应的字节码对象,然后动态的进行任何可能的操作,
包括
①在运行时判断任意一个对象所属的类
②在运行时构造任意一个类的对象
③在运行时判断任意一个类所具有的成员变量和方法
④在运行时调用任意一个对象的方法这些都是反射的功能。
使用反射的主要作用是方便程序的扩展。
3.包装类与基本类型的==和equals()方法
题目
Integer i = 42;
Long l = 42l;
Double d = 42.0;
//下面为true的是:
i == l;//A
i == d;//B
l == d;//C
i.equals(d);//D
d.equals(l);//E
i.equals(l);//F
l.equals(42L);//G
解析
ABC3 个选项很明显,不同类型引用的 == 比较,会出现编译错误,不能比较。
DEF 调用 equals 方法,因为此方法是先比较类型,类型相同后比较数值,数值一样才返回true否则 false,而 i , d , l 是不同的类型,所以返回假。
选项 G ,会自动装箱,将 42L 装箱成 Long 类型,所以调用 equals 方法时,类型相同,且值也相同,因此返回真。
知识点
1、基本型和基本型封装型进行“==”运算符的比较,基本型封装型将会自动拆箱变为基本型后再进行比较。如:
int a = 220;
Integer b = 220;
System.out.println(a==b);//true
2、两个Integer类型进行“==”比较, 如果其值在-128至127 ,那么返回true,否则返回false, 这跟Integer.valueOf()的缓冲对象有关,缓存是指**-128到127之间的int装箱必定装到同一个integer对象** 所以双等号会为true。如:
Integer c=3;
Integer h=3;
Integer e=321;
Integer f=321;
System.out.println(c==h);//true
System.out.println(e==f);//false
3、两个基本型的封装型进行equals()比较,首先equals()会比较类型,如果类型相同,则继续比较值,如果值也相同,返回true。
Integer a=1;
Integer b=2;
Integer c=3;
System.out.println(c.equals(a+b));//true
4、基本型封装类型调用equals(),但是参数是基本类型,这时候,先会进行自动装箱,基本型转换为其封装类型,再进行3中的比较。
int i=1;
int j = 2;
Integer c=3;
System.out.println(c.equals(i+j));//true
5、包装类的“==”运算在不遇到算术运算的情况下不会自动拆箱(除了基本类型和对应的包装类),包装类的equals()方法不处理数据转型
4.静态代码块的执行次数与static关键字说明
题目
public class StaticTest
{
static
{
System.out.println("Hi there");
}
public void print()
{
System.out.println("Hello");
}
public static void main(String args[])
{
StaticTest st1 = new StaticTest();
st1.print();
StaticTest st2 = new StaticTest();
st2.print();
}
}
//问static代码块语句中打印次数
解析
静态代码块优先于主方法,且只执行一次
知识点
-
被static修饰的语句或者变量有如下特点:
1.随着类的加载而加载,静态方法和静态代码块和静态变量从属于类而不属 对象
2.优先于对象存在
3.被所有对象所共享
4.可以直接被类名所调用
-
使用注意:
1.静态方法只能访问静态成员,当类加载时,static静态方法随着类加载而初始化,此时实例对象还未被创建,但是非静态成员变量需要等到实例对象创建才会被初始化,故无法被引用。
2.静态方法中不可以写this,super关键字。所以main方法中不能使用this
3.主函数是静态的
4.Java中静态变量只能在类主体中定义,不能在方法中定义。 静态变量属于类所有而不属于方法。
2022.3.5
1.字符串.lenth()方法
题目
public class Test {
public static void main(String args[]) {
String s = "祝你考出好成绩!";
System.out.println(s.length());
}
}
//打印结果是 8
解析
字符串中lenth()方法获取到的是字符个数,则每个中英文符号都视为1个字符。
当将字符串转化为字节数组,才会有中英文字符的区别。如果是GBK编码,一个中文字符占2字节,如果是UTF-8编码则是3个字节,且二者的英文字符都占1个字节。
2.JavaSe概念判断题
题目
以下说法正确的是:
A.一个类可以实现多个接口
B.抽象类必须有抽象方法
C.protected成员在子类可见性可以修改
D.通过super可以调用父类构造函数
E.final的成员方法实现中只能读取类的成员变量
F.String是不可修改的,且java运行环境中对string对象有一个对象池保存
G.StringBuilder是 线程不安全的
H.Java类可以同时用 abstract和final声明
I.HashMap中,使用 get(key)==null可以 判断这个Hasmap是否包含这个key
J.volatile关键字不保证对变量操作的原子性
K.Java和C++都是静态类型的面向对象编程语言
解析
A.正确。Java是单继承多实现即只能有一个直接父类,但可以实现多个接口
B.错误。本选项考察抽象类的基本概念。有抽象方法的类一定是抽象类但一个抽象类类不一定必须有抽象方法
1.抽象类有构造方法,但是不可以用来实例化,只能用来初始化
2.抽象类可以有抽象方法也可以没有且抽象类中抽象方法不能是private,因为抽象方法定义为私有则子类不能重写,失去了扩展意义。
3.抽象类中可以包含非抽象的普通方法
4.抽象类中可以包含静态方法
5.抽象类体现的是is-a的关系即继承关系
C.正确。换句话说,意思是父类中的protected方法子类在重写的时候访问权限可以修改。其实考察的就是子类重写父类方法时访问权限可以同级或者放大,不能缩小
D.正确。本选项考察继承中super()的用法,super()表示调用父类中的构造方法,通过this()调用本类的构造函数(不能通过调用普通方法的方式调用构造方法)
1、子类继承父类,子类的构造方法的第一行,系统会默认编写super(),在调用子类的构造方法时,先调用父类的无参数构造方法
2、如果父类中只有有参数构造方法,那么子类继承父类时会报错,因为子类的构造方法在默认调用父类无参数构造方法super()不存在。
3.如果子类的第一行编写了this()、this(实参),因为this()也会占用第一行,所以此时就会将super()挤掉,就不会调用父类构造方法。
E.此题答案是错,但是意义有点不明。类的成员变量应该包含实例变量(非static修饰)和类变量(static修饰),final方法两种变量值都能访问也就是说类的成员变量都能访问到。
F.正确。本项考察String类不可变性的理解。在给String类型变量赋值时会先去堆内存的字符串常量池寻找有没有该值的字符串,如果有就将其引用地址赋给字符串变量,没有就开辟一个该值的字符串并将引用给字符串变量,但是在给该字符串变量重新赋值时,原先值并未销毁仍然在字符串常量池中好好保存着,只是将新值的引用再次给字符串变量。所以,String 类不可修改,只能改引用地址。
G.正确。StringBuffer是线程安全的而StringBuilder是线程不安全的
H.错误。二者矛盾 ,final修饰的方法不能被重写 而abstract抽象方法要求子类必须重写
I. 错误。Hashmap中的value可以置为null,get(key)==null有两种情况,一是key不存在,二是该key中存的是null,所以**应该使用map.containskey(key)**返回的true/false来判断是否存在这个key。
D.正确。volatile关键字有两个作用:
1.并发环境可见性:volatile修饰后的变量能够保证该变量在线程间的可见性,线程进行数据的读写操作时将绕开工作内存(CPU缓存)而直接跟主内存进行数据交互,即线程进行读操作时直接从主内存中读取,写操作时直接将修改后端变量刷新到主内存中,这样就能保证其他线程访问到的数据是最新数据
2.并发环境有序性:通过对volatile变量采取内存屏障(Memory barrier)的方式来防止编译重排序和CPU指令重排序,具体方式是通过在操作volatile变量的指令前后加入内存屏障,来实现happens-before关系,保证在多线程环境下的数据交互不会出现紊乱。
**K.**正确。动态类型语言是指在运行期间才去做数据类型检查的语言,也就是说,在用动态类型的语言编程时,永远也不用给任何变量指定数据类型,该语言会在你第一次赋值给变量时,在内部将数据类型记录下来。静态类型语言与动态类型语言刚好相反,它的数据类型是在编译其间检查的,也就是说在写程序时要声明所有变量的数据类型,C/C++是静态类型语言的典型代表,其他的静态类型语言还有C#、JAVA等。
3.线程安全的集合
线程同步的集合:喂,SHE
喂(Vector)- 对应ArrayList,仅仅多了一个同步化机制(线程安全)但效率低
S(Stack)- 堆栈类 先进后出
H(hashtable)- 对应hashmap 仅多一个线程安全
E(enumeration)- 枚举接口,相当于迭代器,有Object nextElement( )和boolean hasMoreElements( )方法
4.线程的创建方式和启动&其它注意点
题目
public class MyRunnable implements Runnable {
public void run() {
//some code here
}
}
//以下哪个能创建和启动线程
new Runnable(MyRunnable).start()//A
new Thread(MyRunnable).run()//B
new Thread(new MyRunnable()).start()//C
new MyRunnable().start()//D
解析
首先启动线程是使用Thread对象的start()方法。所以B一定错误
其次创建Thread对象有以下三种方式:
①A继承Thread类,并重写run()方法。直接new A().start()就开启线程
②A实现Runnable接口,并覆盖了run()方法。通过new Thread(new A()).start()就开启线程。
③A实现Callable接口并重写call()方法(call()方法有返回值)。通过new Thread(传入FutureTask<call()方法返回值类型> 类型的task),其中task的get()方法可以获取call()方法返回值。
综上所属:
线程创建并开启的方式有两个要素:①创建好Thread对象②调用Thread对象的start()方法开启线程
而Thread对象的创建方式有两种:①直接new一个Thread对象,要求要继承Thread类重写run()方法②通过其它有参构造创建。如通过传入一个Runnable实例或者FutureTask<返回值>实例。
知识点
- CyclicBarrier(栅栏):可以让一组线程等待其他线程。 CountDownLatch(闭锁): 可以让一组线程等待某个事件发生。
5.接口类中变量和方法的特点以及接口类,抽象类和实体类的深层次理解
解析
接口类的特点
①变量都是默认public static fianl修饰,且接口中的变量在声明时要赋值
②方法都是默认public abstract修饰
接口类,抽象类和实体类的深层次理解
首先你要弄清接口的含义.接口就是提供一种统一的’协议’,而接口中的属性也属于’协议’中的成员.它们是公共的,静态的,最终的常量.相当于全局常量.
抽象类是不’完全’的类,相当于是接口和具体类的一个中间层.既满足接口的抽象,也满足具体的实现.
如果接口可以定义变量,但是接口中的方法又都是抽象的,在接口中无法通过行为来修改属性。有的人会说了,没有关系,可以通过实现接口的对象的行为来修改接口中的属性。这当然没有问题,但是考虑这样的情况。如果接口A中有一个public访问权限的静态变量a。按照java的语义,我们可以不通过实现接口的对象来访问变量a,通过A.a = xxx;就可以改变接口中的变量a的值了。正如抽象类中是可以这样做的,那么实现接口A的所有对象也都会自动拥有这一改变后的a的值了,也就是说一个地方改变了a,所有这些对象中a的值也都跟着变了。这和抽象类有什么区别呢,怎么体现接口更高的抽象级别呢,怎么体现接口提供的统一的协议呢,那还要接口这种抽象来做什么呢?所以接口中不能出现变量,如果有变量,就和接口提供的统一的抽象这种思想是抵触的。所以接口中的属性必然是常量,只能读不能改,这样才能为实现接口的对象提供一个统一的属性。
通俗的讲,你认为是要变化的东西,就放在你自己的实现中,不能放在接口中去,接口只是对一类事物的属性和行为更高层次的抽象。对修改关闭,对扩展(不同的实现implements)开放,接口是对开闭原则的一种体现。
abstract class和interface所反映出的设计理念不同。其实abstract class表示的是"is-a"关系,interface表示的是"has-a"关系。
is-a:继承关系 has-a:从属关系 like-a:组合关系
6.使用迭代器遍历集合
题目
//list是一个ArrayList的对象,哪个选项的代码填到//todo delete处,可以在Iterator遍历的过程中正确并安全的删除一个list中保存的对象()
Iterator it = list.iterator();
int index = 0;
while (it.hasNext())
{
Object obj = it.next();
if (needDelete(obj)) //needDelete返回boolean,决定是否要删除
{
//todo delete
}
index ++;
}
A.it.remove();
B.list.remove(obj);
C.list.remove(index);
D.list.remove(obj,index);
解析
当使用迭代器遍历集合元素时,迭代器已经事先知道集合元素的个数。在迭代途中突然想要增加或删除一个元素,那么就会打乱集合中元素的顺序,迭代器就会无所适从,抛出一个并发修改异常(ConcurrentModificationException)。
解决方案1:使用迭代器进行遍历时可以使用迭代器的添加删除元素的方法
ListIterator listIterator = list.listIterator();
while (listIterator.hasNext()){
Object obj = listIterator.next();
String str = (String)obj;
if (str.equals("world")){
//list.add("JavaEE");//并发修改异常
//listIterator.add("JavaEE");
listIterator.remove();
}
}
解决方案2:使用for循环进行遍历,就可以使用集合自己添加删除元素
注意根据索引移除元素的时候for循环i最后记得-1,为了下次循环再次 检查当前索引的元素
list.clear();
list.add("world");
list.add("world");
list.add("java");
list.add("world");
list.add("java");
list.add("world");
System.out.println("for遍历前:"+list);
for (int i = 0; i < list.size(); i++) {
Object obj = list.get(i);
String str = (String)obj;
System.out.println("索引: "+i+";当前字符串: "+str);
if (str.equals("world")){
//list.add("JavaEE");
System.out.println("removeId:"+i);
list.remove(i);
//i-1 因为移除当前索引的元素后其后面的元素索引-1
// 要从当前索引再次检查 平衡for循环的i自增这里需要设置一下i-1;
i-=1;
}
}
System.out.println("for遍历后:"+list);
7.线程礼让yield()与其它线程方法&线程状态
题目
public class ThreadTest extends Thread {
public void run() {
System.out.println("In run");
yield();
System.out.println("Leaving run");
}
public static void main(String []argv) {
(new ThreadTest()).start();
}
}
//程序打印结果
解析
Thread.yield()方法作用是:暂停当前正在执行的线程对象,并执行其他线程。
yield()应该做的是让当前运行线程回到可运行状态,以允许具有相同优先级的其他线程获得运行机会。因此,使用yield()的目的是让相同优先级的线程之间能适当的轮转执行。但是,实际中无法保证yield()达到让步目的,因为让步的线程还有可能被线程调度程序再次选中。
结论:yield()从未导致线程转到等待/睡眠/阻塞状态。在大多数情况下,yield()将导致线程从运行状态转到可运行状态,但有可能没有效果。
知识点
-
线程的状态:①新建状态:被创建处理②就绪状态③运行状态④阻塞状态⑤死亡状态
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aQQUUeNa-1649296599904)(C:\Users\ck\AppData\Roaming\Typora\typora-user-images\1646478759463.png)]
-
其它线程方法
- void interrupt() 中断当前线程
- void join() 等待该线程死亡
- static void sleep() 休眠
- void setDaemond() 设置守护线程,开启start线程前有效
- void start() 开启当前线程
8. HttpServletRequest的考察
题目
java如何返回request范围内存在的对象?
A.request.getRequestURL()
B.request.getAttribute()
C.request.getParameter()
D.request.getWriter()
解析
略
知识点
参考HttpServletRequest详解:获取HTTP请求消息 (biancheng.net)
-
基本概念
HttpServletRequest 接口继承自 ServletRequest 接口,其主要作用是封装 HTTP 请求消息,代表客户端的请求,当客户端通过HTTP协议访问服务器时,HTTP请求头中的所有信息都封装在这个对象中。由于 HTTP 请求消息分为请求行、请求消息头和请求消息体三部分。因此,在 HttpServletRequest 接口中定义了获取请求行、请求头和请求消息体的相关方法。
-
Http请求报文的组成图解
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NiAOAsba-1649296599906)(C:\Users\ck\AppData\Roaming\Typora\typora-user-images\1646490521873.png)]
-
常用的一些方法
①获取客户机信息
getRequestURL() 返回客户端发出请求时的完整URL。
getRequestURI() 返回请求行中的参数部分。
getQueryString () 方法返回请求行中的参数部分(参数名+值)
getRemoteHost() 返回发出请求的客户机的完整主机名。
getRemoteAddr() 返回发出请求的客户机的IP地址。
getPathInfo() 返回请求URL中的额外路径信息。额外路径信息是请求URL中的位于Servlet的路径之后和查询参数之前的内容,它以"/"开头。
getRemotePort() 返回客户机所使用的网络端口号。
getLocalAddr() 返回WEB服务器的IP地址。
getLocalName() 返回WEB服务器的主机名。②获取客户机请求头
getHeader(string name) 以 String 的形式返回指定请求头的值。如果该请求不包含指定名称的头,则此 方法返回 null。如果有多个具有相同名称的头,则此方法返回请求中的第一 个头。头名称是不区分大小写的。可以将此方法与任何请求头一起使用
getHeaders(String name) 以 String 对象的 Enumeration 的形式返回指定请求头的所有值
getHeaderNames() 返回此请求包含的所有头名称的枚举。如果该请求没有头,则此方法返回一个空枚举
③获取客户机请求参数getParameter(String name) 根据name获取请求参数(常用)
getParameterValues(String name) 根据name获取请求参数列表(常用)
getParameterMap() 返回的是一个Map类型的值,该返回值记录着前端(如jsp页面)所提交请求中的请 求参数和请求参数值的映射关系。(编写框架时常用)
④请求转发-指一个web资源收到客户端请求后,通知服务器去调用另外一个web资源进行处理getRequestDispatche(String path) 返回一个RequestDispatcher对象,调用这个对象的forward方法可以实 现请求转发。
⑤request对象同时也是一个域对象
* setAttribute(String name,Object o)方法,将数据作为request对象的一个属性存放到request对象中,例如:request.setAttribute(“data”, data); * getAttribute(String name)方法,获取request对象的name属性的属性值,例如:request.getAttribute(“data”) * removeAttribute(String name)方法,移除request对象的name属性,例如:request.removeAttribute(“data”) * getAttributeNames方法,获取request对象的所有属性名,返回的是一个,例如:Enumeration attrNames = request.getAttributeNames();
9.基本数据类型的赋值-自动类型提升和字节占据大小
题目
以下表达式正确的是:
A.byte i=128
B.boolean i=null
C.long i=0xfffL
D.double i=0.9239d
E.long test=012
F.float f=-412
G.int other =(int)true
解析
A. byte 1字节 值域在-128-127之间 。如果真想声明为byte类型则需强制转换,byte b1 = (byte) 128;且此时打印b1的话是**-128**
B. 基本数据类型的boolean只能赋值true或者fasle 而null代表没有引用地址,只能赋值给引用类型,所以如果是Boolean则没有错
C.十六进制的long
D. double类型的d可以显式标明也可以省略
E和F. 虽然右边的值没有标明l和f,但由于都是基本数据类型所以会自动类型提升。此外 012是八进制,用十进制表示为10
G.boolean类型的变量不能 和 任何其它基本数据类型转换 。
知识点
-
字节数
byte 1 int 4 short 4 long 8
float 4 double 8
char 2
boolean 4|1 如果boolean用于声明一个基本类型变量时是占四个字节,如果用于声明一个数组类型时,那么数组中的每个元素占一个字节
-
默认值:java中整型默认的是int,浮点默认的是double.
-
具体
默认值 存储需求(字节) 取值范围 示例 byte 0 1 -27—27-1 byte b=10; char ‘ \u0000′ 2 0—2^16-1 char c=’c’ ; short 0 2 -215—215-1 short s=10; int 0 4 -231—231-1 int i=10; long 0 8 -263—263-1 long o=10L; float 0.0f 4 -231—231-1 float f=10.0F double 0.0d 8 -263—263-1 double d=10.0; boolean false 1 true\false boolean flag=true;
10.JVM堆内存设置与堆外内存含义
题目
下面哪种情况会导致持久区jvm堆内存溢出?
A.循环上万次的字符串处理
B.在一段代码内申请上百M甚至上G的内存
C.使用CGLib技术直接操作字节码运行,生成大量的动态类
D.不断创建对象
解析
A B D都会造成年老代溢出,即Heap Space溢出
C会造成持久代溢出,即Permanent Space溢出
知识点
(13条消息) JVM 堆内存设置原理_sivyer123的专栏-CSDN博客_jvm 堆内存设置
JVM堆内存分为2块:Permanent Space(持久区|永久区) 和 Heap Space(堆内存)。
- Permanent 即 持久代(Permanent Generation),主要存放的是Java类定义信息,与垃圾收集器要收集的Java对象关系不大。
- Heap = { Old + NEW = {Eden, from, to} },Old 即 年老代(Old Generation),New 即 年轻代(Young Generation)。年老代和年轻代的划分对垃圾收集影响比较大。
堆中区分的新生代和老年代是为了垃圾回收,新生代中的对象存活期一般不长,而老年代中的对象存活期较长,所以当垃圾回收器回收内存时,新生代中垃圾回收效果较好,会回收大量的内存,而老年代中回收效果较差,内存回收不会太多。
基于以上特性,新生代中一般采用复制算法,因为存活下来的对象是少数,所需要复制的对象少,而老年代对象存活多,不适合采用复制算法,一般是标记整理和标记清除算法。
OOM(“Out of Memory”)异常一般主要有如下2种原因:
- 年老代溢出,表现为:java.lang.OutOfMemoryError:Javaheapspace
这是最常见的情况,产生的原因可能是:设置的内存参数Xmx过小或程序的内存泄露及使用不当问题。
例如循环上万次的字符串处理、创建上千万个对象、在一段代码内申请上百M甚至上G的内存。还有的时候虽然不会报内存溢出,却会使系统不间断的垃圾回收,也无法处理其它请求。这种情况下除了检查程序、打印堆内存等方法排查,还可以借助一些内存分析工具,比如MAT就很不错。
- 持久代溢出,表现为:java.lang.OutOfMemoryError:PermGenspace
通常由于持久代设置过小,动态加载了大量Java类而导致溢出,解决办法唯有将参数 -XX:MaxPermSize 调大(一般256m能满足绝大多数应用程序需求)。将部分Java类放到容器共享区(例如Tomcat share lib)去加载的办法也是一个思路,但前提是容器里部署了多个应用,且这些应用有大量的共享类库。
堆外内存off-heap-指的是JVM进程管理的内存
off-heap叫做堆外内存,将你的对象从堆中脱离出来序列化,然后存储在一大块内存中,这就像它存储到磁盘上一样,但它仍然在RAM中。对象在这种状态下不能直接使用,它们必须首先反序列化,也不受垃圾收集。序列化和反序列化将会影响部分性能(所以可以考虑使用FST-serialization)使用堆外内存能够降低GC导致的暂停。堆外内存不受垃圾收集器管理,也不属于老年代,新生代。
2022.3.6
1.内部类
题目
判断:静态内部类不可以直接访问外围类的非静态数据,而非静态内部类可以直接访问外围类的数据,包括私有数据。
知识点
定义:一个类定义在另一个类的内部,称之为内部类。
分类:
①成员内部类:类中方法外。调用内部类方法格式:Outer.Inner inner = new Outer().new Inner()
//在手动导包Outer.Inner后也可以用内部类接收Inner inner = new Outer().new Inner()
②静态内部类:类中方法外,成员内部类用static修饰就变成了静态内部类。Outer.Inner inner = new Outer.Inner();//省略一个括号
②局部内部类:定义在外部类的局部位置即方法中,作用域只限于本方法。局部内部类的的使用主要是用来解决比较复杂的问题,想创建一个类来辅助我们的解决方案,到那时又不希望这个类是公共可用的,所以就产生了局部内部类。
③匿名内部类:匿名内部类是局部内部类的一种简写方式。匿名内部类本质是一个对象,是实现父接口或继承抽象父类的子类对象
//匿名内部类定义方式
Object o=new Object(){
public boolean equals(Object obj){
return true;
}
};
注意点:
-
匿名内部类没有访问修饰符。
-
匿名内部类没有构造方法。
-
成员内部类可以直接访问外部类的成员,但是外部类不能直接访问非静态内部类成员。
-
成员内部类不能有静态方法、静态属性和静态初始化块。因为实例化要依赖外部类
-
外部类的静态方法、静态代码块不能访问非静态内部类,包括不能使用非静态内部类定义变量、创建实例。
-
静态内部类只能访问外部类的静态成员,包括私有。实例化不依赖外部类
-
局部内部类就像一个局部方法,不能被访问修饰符修饰,也不能被static修饰。
-
局部内部类只能访问所在代码块或者方法中被定义为final的局部变量。
-
匿名内部类是局部内部类的特殊形式,所以局部内部类的所有限制对匿名内部类也有效
-
一个匿名内部类一定是在new后面的,这个匿名类必须继承一个父类或者实现一个接口。
-
匿名内部类是没有类名的内部类,不能使用class,extends和implements,没有构造方法。
-
**外部类只能使用public和default修饰。**因为外部类没有处于任何类的内部,也就没有其所在类的内部、所在类的子类两个范围,因此 private 和 protected 访问控制符对外部类没有意义。


2.String编解码字节数组byte[]
题目
下面哪段程序能够正确的实现了GBK编码字节流到UTF-8编码字节流的转换:byte[] src,dst;
A.dst=String.fromBytes(src,"GBK").getBytes("UTF-8")
B.dst=new String(src,"GBK").getBytes("UTF-8")
C.dst=new String("GBK",src).getBytes()
D.dst=String.encode(String.decode(src,"GBK")),"UTF-8" )
解析
A和D错误:Java中的String类没有fromBytes和encode方法
C中一方面使用String构造方法解码时传参位置有误,另一方面编码时没有指定为UTF-8字符集编码,这时会使用平台默认的字符集去编码
B正确:通过String类的构造方法可以解码byte[]字节数组且可以指定解码用到的字符集,而通过getBytes()方法可以指定字符集给当前字符串去编码。二者联合使用就可以实现字节流的编码转换
3.序列化与反序列化
题目
下列关于系列化和反序列化描述正确的是:
A.序列化是将数据转为n个 byte序列的过程
B.反序列化是将n个 byte转换为数据的过程
C.将类型int转换为4 byte是反序列化过程
D.将8个字节转换为long类型的数据为序列化过程
知识点
- 含义
通俗来讲,把你看得懂的转换为看不懂的,就是序列化;把你看不懂的转换为看得懂的,就是反序列化。
**序列化:把对象转换为字节序列的过程称为对象的序列化。**序列化后的数据方便在网络上传输和在硬盘上存储。反序列化:把字节序列恢复为对象的过程称为对象的反序列化。
本质其实还是一种协议,一种数据格式,方便数据的存储和传输。
- 应用场景
当你想把的内存中的对象状态保存到一个文件中或者数据库中时候;
当你想用套接字socket在网络上传送对象的时候;
当你想通过RMI传输对象的时候;
4.Servlet相关包及体系结构和生命周期
题目
常用的servlet包的名称是?
A.java.servlet
B.javax.servlet
C.servlet.http
D.javax.servlet.http
解析
JEE5.0中的Servlet相关的就下面这几个包:
javax.servlet
javax.servlet.jsp
java.servlet.jsp.el
java.servlet.jsp.tagext
而最用得多的就是
javax.servlet
javax.servlet.http
这两个包了.
javax是Sun公司提供的一个扩展包,算是对原 JAVA 包的一些优化处理,现在已经有很多都是基于JAVAX的程序开发而不是java包
此外javax. servlet只包含这个包下的直接类,不能包含这个包里的其他包的类。换句话说,导包import时引用只能引用父包的儿子 如果想要引用孙子的话需要引进孙子那一层的包
知识点
-
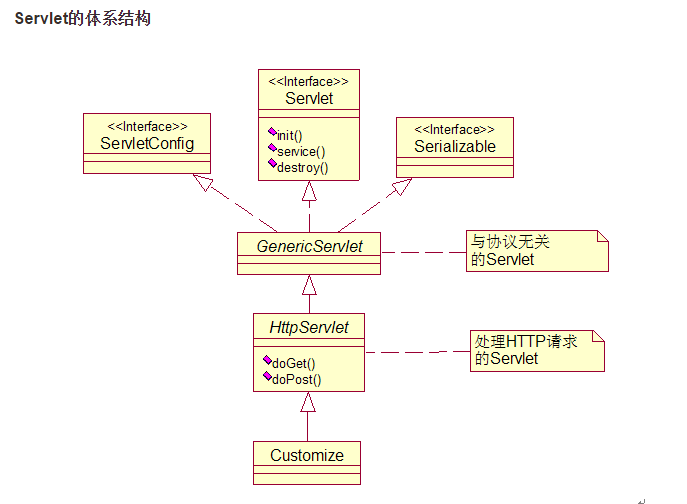
servlet体系结构
-
一些说明
GenericServlet类:抽象类,定义一个通用的、独立于底层协议的Servlet。
大多数Servlet通过从GenericServlet或HttpServlet类进行扩展来实现,一般通过HttpServlet扩展
ServletConfig接口定义了在Servlet初始化的过程中由Servlet容器(Tomcat)传递给Servlet的配置信息对象
HttpServletRequest接口扩展ServletRequest接口,为HTTP Servlet提供HTTP请求信息HttpServlet是GenericServlet的子类。
GenericServlet是个抽象类,必须给出子类才能实例化。它给 出了设计servlet的一些骨架,定义了servlet生命周期,还有一些得到名字、配置、初始化参数的方法,其设计的是和应用层协议无关的,也就是说 你有可能用非http协议实现它。
HttpServlet是子类,当然就具有GenericServlet的一切特性,还添加了doGet, doPost, doDelete, doPut, doTrace等方法对应处理http协议里的命令的请求响应过程。开发者在开发servlet继承HttpServlet时如何处理父类的service方法,一般我们都是不对service方法进行重载(没有特殊需求的话),而只是重载doGet()之类的doXxx()方法,减少了开发工作量。但如果重载了service方法,doXXX()方法也是要重载的。即不论是否重载service方法,doXXX()方法都是需要重载的。
ServletContext是servlet与servlet容器之间的直接通信的接口。Servlet容器在启动一个Webapp时,会为它创建一个ServletContext对象,即servlet上下文环境。每个webapp都有唯一的ServletContext对象。同一个webapp的所有servlet对象共享一个ServeltContext,servlet对象可以通过ServletContext来访问容器中的各种资源。
说明一下参数的获取。访问ServletConfig参数,取得ServletConfig对象后,调用getInitParameter()方法;访问ServletContext对象,只要调用现有的ServletConfig对象的getServletContext()即可,然后同样调用getInitParamter()方法就能获取参数。
-
生命周期
①详细阶段 5阶段
Servlet的生命周期分为5个阶段:加载、创建、初始化、处理客户请求、卸载。
(1)加载:容器(Tomcat)通过类加载器加载servlet文件(class)
(2)创建:通过调用servlet构造函数创建一个servlet对象
(3)初始化:调用init方法初始化
(4)处理客户请求:每当有一个客户请求,容器会创建一个线程来处理客户请求
(5)卸载:调用destroy方法让servlet自己释放其占用的资源
综上:servlet是由Servlet容器负责加载Servlet类,创建Servlet对象并实例化,然后调用Servlet的init方法,进行初始化,之后调用Service方法。实例化和初始化不同。先实例化,再初始化。
②粗略阶段 3阶段
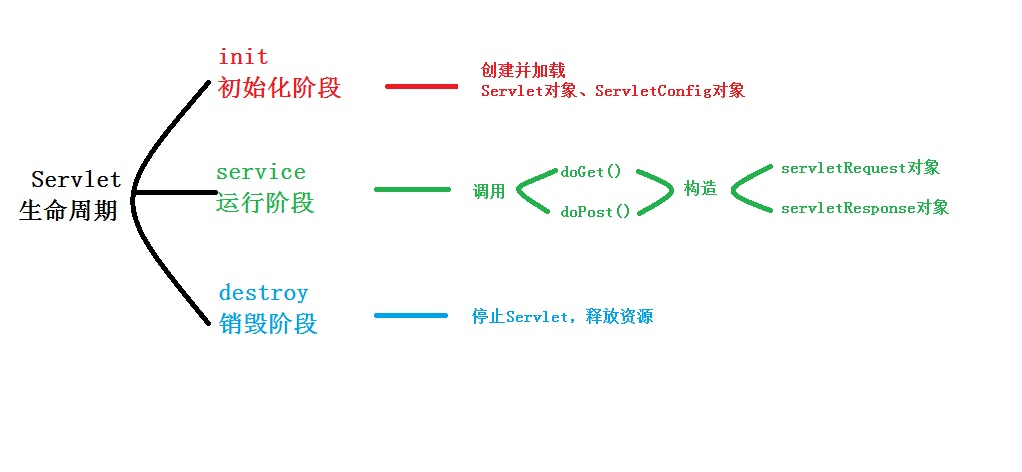
补充:
初始化:Servlet启动,会读取配置文件中的信息,构造指定的Servlet对象,创建ServletConfig对象,将ServletConfig作为参数来调用init()方法。
每一次请求来到容器时,会产生HttpServletRequest与HttpServlceResponse对象,并在调用service()方法时当做参数传入。
在WEB容器启动后,会读取Servlet设置信息,将Servlet类加载并实例化,并为每个Servlet设置信息产生一个ServletConfig对象,而后调用Servlet接口的init()方法,并将产生的ServletConfig对象当作参数传入。
5.方法重写和重载的规则
题目
在java中重写方法应遵循规则的包括()
A.访问修饰符的限制一定要大于被重写方法的访问修饰符
B.可以有不同的访问修饰符
C.参数列表必须完全与被重写的方法相同
D.必须具有不同的参数列表
解析
A.也可以相等
B&C正确
D错误 参数列表和方法名必须相同
知识点
-
重写规则
两同两小一大原则–
-
两同:方法名和参数列表相同
-
两小:返回值或声明异常比父类小(或相同)
-
一大:访问修饰符比父类的大(或相同)
-
-
重载规则
方法名必须相同,参数列表必须不同(参数数目,参数类型,参数顺序),其它无所谓(返回值,访问权限,声明异常等)
6.不可变类概念
题目
Java 中,以下不是修饰符 final 作用的是( )。
A.修饰常量
B.修饰不可被继承的类
C.修饰不可变类
D.修饰不可覆盖的方法
解析
ABD都是final的作用,修饰变量则变量不可变变为常量,修饰类则类不可被继承,修饰方法则方法不能被重写|覆盖(但可以被重载)
虽然答案给C但是有异议,因为java中不可变类如String Integer等包装类都用final修饰过
知识点
- 定义
不可变类(Immutable Class)是一旦被实例化就不会改变自身状态(或值)的类。常见的比如String和基本数据类型的包装类,对于这种不可变类,一旦在进行引用传递的时候,形参一开始就和实际参数指向的不是一个地址,所以在方法中对形参的改变,并不会影响实际参数。
- 特点
不可变类要求 不提供可以改变成员变量的方法,且如果构造方法传入的参数是引用类型,不能直接赋值,应当拷贝,因为该类的成员变量应当是private final的。
不要提供任何可以修改对象属性的方法
不要为属性提供set方法
保证类不会被扩展
用final修饰类
使所有的属性都是final的
初始化之后不能修改属性的值
使所有的属性都是private的
防止别的对象访问不可变类的属性
确保对任何可变组件的互斥访问
如果有指向可变对象的属性,一定要确保,这个可变对象不能被其他类访问和修改。最好不要在不可变类中添加 指向可变类的属性
7.try{}catch{}finally{}语句
题目
//AccessViolationException异常触发后,下列程序的输出结果为( )
static void Main(string[] args)
{
try
{
throw new AccessViolationException();
Console.WriteLine("error1");
}
catch (Exception e)
{
Console.WriteLine("error2");
}
Console.WriteLine("error3");
}
解析
代码中try{}块抛出异常并被catch{}块成功捕获,此后执行catch中的语句打印error2,且catch块中没有抛出异常则执行try{}catch{}块后面的语句,即打印error3;
知识点
- 结构
try {
// 可能会发生异常的语句
} catch(子类异常类 e) {
// 处理异常语句
} //...可以多个捕获块catch
catch(Exception e){
//处理异常处理
} finally {
// 清理代码块
}
-
注意点
-
异常处理语法结构中只有 try 块是必需的,也就是说,如果没有 try 块,则不能有后面的 catch 块和 finally 块;
-
catch 块和 finally 块都是可选的,但 catch 块和 finally 块至少出现其中之一,也可以同时出现;
-
可以有多个 catch 块,捕获父类异常的 catch 块必须位于捕获子类异常的后面;
-
不能只有 try 块,既没有 catch 块,也没有 finally 块;
-
多个 catch 块必须位于 try 块之后,finally 块必须位于所有的 catch 块之后。
-
finally 与 try 语句块匹配的语法格式,此种情况会导致异常丢失,所以不常见。
-
除非在 try 块、catch 块中调用了退出虚拟机的方法
System.exit(int status),否则不管在 try 块或者 catch 块中执行怎样的代码,出现怎样的情况,异常处理的 finally 块总会执行。 -
通常情况下不在 finally 代码块中使用 return 或 throw 等导致方法终止的语句,否则将会导致 try 和 catch 代码块中的 return 和 throw 语句失效。换言之:
如果try语句里有return,返回的是try语句块中变量值。
详细执行过程如下:- 如果有返回值,就把返回值保存到局部变量中;
- 执行jsr指令跳到finally语句里执行;
- 执行完finally语句后,返回之前保存在局部变量表里的值。
如果try,finally语句里均有return,忽略try的return,而使用finally的return.
-
-
执行情况
- 如果 try 代码块中没有拋出异常,则执行完 try 代码块之后直接执行 finally 代码块,然后执行 try catch finally 语句块之后的语句。
- 如果 try 代码块中拋出异常,并被 catch 子句捕捉,那么在拋出异常的地方终止 try 代码块的执行,转而执行相匹配的 catch 代码块,之后执行 finally 代码块。如果 finally 代码块中没有拋出异常,则继续执行 try catch finally 语句块之后的语句;如果 finally 代码块中拋出异常,则把该异常传递给该方法的调用者。
- 如果 try 代码块中拋出的异常没有被任何 catch 子句捕捉到,那么将直接执行 finally 代码块中的语句,并把该异常传递给该方法的调用者。
-
举例
-
finally中修改返回值
实际过程是这样的:当程序执行到try{}语句中的return方法时,它会干这么一件事,将要返回的结果存储到一个临时栈中,然后程序不会立即返回,而是去执行finally{}中的程序, 在执行
a = 2时,程序仅仅是覆盖了a的值,但不会去更新临时栈中的那个要返回的值 。执行完之后,就会通知主程序“finally的程序执行完毕,可以请求返回了”,这时,就会将临时栈中的值取出来返回。这下应该清楚了,要返回的值是保存至临时栈中的。public abstract class Test { public static void main(String[] args) { System.out.println(beforeFinally()); } public static int beforeFinally(){ int a = 0; try{ a = 1; return a; }finally{ // a=2; // System.out.println( "finally块:"+a); System.out.println( "finally块:"+a); a=2; } } } /**output: finally块:2 1 或 finally块:1 1 */ -
finally中也有返回语句
在这里,finally{}里也有一个return,那么在执行这个return时,就会更新临时栈中的值。同样,在执行完finally之后,就会通知主程序请求返回了,即将临时栈中的值取出来返回。故返回值是2.
public abstract class Test { public static void main(String[] args) { System.out.println(beforeFinally()); } public static int beforeFinally(){ int a = 0; try{ a = 1; return a; }finally{ a = 2; return a; } } } /**output: 2 */
-
8.方法内定义的变量定义时需要初始化赋值
方法内定义的变量没有初始值必须要初始化(用之前赋值),类中定义的成员变量有初始值可以不初始化
9.字符串创建方式及包装类创建的信息补充
题目
以下代码执行的结果显示是多少( )?

解析
首先要明确使用 == 比较引用类型的时候实际比较的是引用类型地址
i1 == i2 为fasle,i5 == i6为true。在定义的时候都是通过自动装箱即调用Integer.valueof()方法创建int型数值对应的Integer包装类。而当使用自动装箱构造包装类时**,JVM从节省内存角度出发提前缓存好-128-127**之间的Integer对象,也就是说通过自动装箱获取到的包装类,相同数值且在-128-127之间对应的包装类地址一致,则i5==i6。而不在那个区间的值则会重新new出Integer对象,则即使值相同创建出来的Integer对象的地址值也不一样。此外,如果手动new出来-128和127之间的数对应的Integer类型对象也是地址随机的即Integer i5 = new Integer(100);Integer i6 = new Integer(100); 则i5和i6地址不同。
额外要说的是 除了Double和Float没有提前缓存对齐外,Short,Long,Integer,Byte都提前缓存了-128-127之间的包装类对象,而Boolean提前缓存了true和false的Boolean对象
Long l1 = 122L;
Long l2 = 122l;
Long l3 = 128l;
Long l4 = 128l;
Byte b1 = 127;
Byte b2 = 127;
Short s1 = 127;
Short s2 = 127;
Short s3 = 128;
Short s4 = 128;
Boolean bo1 = true;
Boolean bo2 = true;
Boolean bo3 = false;
Double d1 = 1.2d;
Double d2 = 1.2d;
Float f1 = 1.3f;
Float f2 = 1.3f;
System.out.println(l1 == l2);//true
System.out.println(l3 == l4);//false
System.out.println(b1 == b2);//true
System.out.println(s1 == s2);//true
System.out.println(s3 == s4);//false
System.out.println(bo1 == bo2);//true
System.out.println(bo1 == bo3);//false
System.out.println(d1 == d2);//false
System.out.println(f1 == f2);//false
String类型的i3和i4 判断见知识点说明
知识点
-
String类的创建方式
①字面值直接赋值 如 String s1 = “test”
这种创建方式会现在字符串池(String Pool)中找是否存在了"test"这个字符串,如果已经存在了那么直接将字符串池"test"的引用直接传给s1。如果没有则先创建该字符串然后将引用传给s1。
具体表现如下:
String s1 = "test"; String s2 = "test"; System.out.println(s1 == s2);//true System.out.println(s1 == "test");//true也就是说只要是通过相同的字面值去创建的String对象其引用地址永远一致。
②new出String对象
只要是通过new的方式创建一个类的实例,那么就会在堆内存中开辟一块内存并将内存地址赋予栈中新new出来的类实例。也就是说每new一次String类都会在堆内存中开辟出一块新的空间,并将对应的字符串池中目标字符串的引用放入开辟的堆空间中然后将堆空间的引用地址赋给栈中新增的String实例。
换句话说,即使new String(“字符串值”)的字符串值相同但每new一次其引用地址(指向堆空间开辟的地址)都不一样。用代码表示如下:
String s3 = "test"; String s4 = new String("test"); String s5 = new String("test"); System.out.println(s3 == s4);//false System.out.println(s4 == s5);//false -
字符串池的优缺点
字符串池的优点就是避免了相同内容的字符串的创建,节省了内存,省去了创建相同字符串的时间,同时提升了性能;
另一方面,字符串池的缺点就是牺牲了JVM在常量池中遍历对象所需要的时间,不过其时间成本相比而言比较低。
10.子类创建时构造方法的调用情况
题目
//运行结果
class Person {
String name = "No name";
public Person(String nm) {
name = nm;
}
}
class Employee extends Person {
String empID = "0000";
public Employee(String id) {
empID = id;
}
}
public class Test {
public static void main(String args[]) {
Employee e = new Employee("123");
System.out.println(e.empID);
}
}
解析
子类的构造方法总是先调用父类的构造方法,如果子类的构造方法没有明显地指明使用父类的哪个构造方法,子类就默认调用父类不带参数的构造方法。
当父类没有无参的构造函数,所以子类需要在自己的构造函数中显示的调用父类的有参构造函数。本题需要在子类构造函数中第一行添加super(“nm”);
11.构造方法
知识点
java中的构造方法review
- 构造方法的特点:
构造方法名与类名相同
构造方法没有返回值 类型,也不写void
构造方法可以重载
- 构造方法的作用:
在创建对象时,给属性赋初值
- 构造方法何时使用
构造方法在创建对象时被调用
- 构造方法的分类:
显示的构造方法和隐式的构造方法
当声明了构造方法时,系统不会提供隐式的默认的无参构造方法
12.Collection集合存入数据必须是引用类型&自动装箱
题目
//打印结果
public static void main(String args[]) {
List Listlist1 = new ArrayList();
Listlist1.add(0);
List Listlist2 = Listlist1;
System.out.println(Listlist1.get(0) instanceof Integer);
System.out.println(Listlist2.get(0) instanceof Integer);
}
解析
- Collection集合中存入的数据必须是引用数据类型而add(0)时0会自动装箱变成对应的Integer类型
- List Listlist2 = Listlist1;是将Listlist1的引用给Listlist2这样两个集合都指向堆中同一个ArrayList()对象
- instanceof:前一个参数通常是一个引用类型变量,后一个操作数通常是一个类(也可以是一个接口, 它用于判断前面的对象是否是后面的类,或者其子类、实现类的实例。
13.Java跨平台性 一次编译到处运行的理解
题目
判断:Java的跨平台特性是指它的源代码可以在多个平台运行。
解析
-
源代码和字节码文件:
源代码->.java结尾的文件
字节码文件->.class结尾的文件
.class文件是由编译器运行完.java源代码后生成的。
-
一次编译到处运行-跨平台性
java源代码经过编译器生成的字节码文件可以通过JVM解析运行,而不同的系统平台JVM不同但对同一个字节码文件解析运行结果一致。
所以Java的跨平台性不是因为其源代码可以在多个 平台运行,而是因为JVM可以解释运行字节码文件
14.File类功能
题目
//下列叙述错误的是
A.File类能够存储文件属性
B.File类能够读写文件
C.File类能够建立文件
D.File类能够获取文件目录信息
解析
File类能操作文件本身,但不能对文件内容进行修改
知识点
File类的一下常用方法和说明
1.访问文件名相关方法:
-
String getName(); 返回此File对象所表示的文件名和路径名(如果是路径,则返回最后一级子路径名)。
-
String getPath(); 返回此File对象所对应的路径名。
-
File getAbsolutePath(); 返回此File对象所对应的绝对路径名。
-
String getParent(); 返回此File对象所对应目录(最后一级子目录)的父路径名。
-
boolean renameTo(File newName); 重命名此File对象所对应的文件或目录,如果重命名成功,则返回true:否则返回false.(A)
2.文件检测相关方法
- boolean exists(); 判断File对象所对应的文件或目录是否存在。
- boolean canWrite(); 判断File对象所对应的目录或文件是否可写。
- boolean canRead(); 判断File对象所对应的目录或文件是否可读。
- boolean isFile(); 判断File对象所对应的是否是文件,而不是目录。
- boolean isDirectory(); 判断File对象所对应的是否是目录,而不是文件。
- boolean isAbsolute(); 判断File对象所对应的文件或目录是否是绝对路径。该方法消除了不同平台的差异,可以直接判断File对象是否为绝对路径。在UNIX/Linux/BSD等系统上,如果路径名开头是一条斜线(/),则表明该File对象对应一个绝对路径;在Windows等系统上,如果路径开头是盘符,则说明它是绝对路径。
3.获取常规文件信息
- long lastModified(); 返回文件最后修改时间。
- long length(); 返回文件内容的长度。
4.文件操作相关的方法
- boolean createNewFile(); 当此File对象所对应的文件不存在时,该方法将新建的一个该File对象所指定的新文件,如果创建成功则返回true;否则返回false.©
- boolean delete(); 删除File对象所对应的文件或路径。
- static File CreateTempFile(String prefix,String suffix);在默认的临时文件目录创建一个临时空文件,使用给定前缀、系统生成的随机数和给定后缀作为文件名。这是一个静态方法,可以直接通过File来调用。preFix参数必须至少是3个字节长。建议前缀使用一个短的、有意义的字符串。建议前缀使用一个短的、有意义的字符串,比如”hjb“ 或”main”. suffix参数可以为null,在这种情况下,将使用默认的后缀”.tmp”.
- static File CreateTempFile(String prefix,String suffix,File directory);在directory所指定的目录中创建一个临时空文件,使用给定前缀、系统生成的随机数和给定后缀作为文件名。这是一个静态方法,可以直接通过File来调用。
- void deleteOnExit(); 注册一个删除钩子,指定当Java虚拟机退出时,删除File对象随对应的文件和目录。
5.目录操作相关方法**(D)**
- boolean mkdir(); 试图创建一个File对象所对应的目录,如果创建成功,则返回true;否则返回false. 调用该方法时File对象必须对应一个路径,而不是一个文件。
- String[] list(); 列出File对象的所有子文件名和路径名,返回String数组。
- File[] listFiles(); 列出File对象的所有子文件和路径,返回File数组。
- static File[] listRoots(); 列出系统所有的根路径。这是一个静态方法,可以直接通过File类来调用。
- http://blog.csdn.net/nightcurtis/article/details/51385934
15.ThreadLocal类
题目
下面有关 Java ThreadLocal 说法正确的有?(ABCDHI)
A.ThreadLocal存放的值是线程封闭,线程间互斥的,主要用于线程内共享一些数据,避免通过参数来传递
B.线程的角度看,每个线程都保持一个对其线程局部变量副本的隐式引用,只要线程是活动的并且 ThreadLocal 实例是可访问的;在线程消失之后,其线程局部实例的所有副本都会被垃圾回收
C.在Thread类中有一个Map,用于存储每一个线程的变量的副本。
D.对于多线程资源共享的问题,同步机制采用了“以时间换空间”的方式,而ThreadLocal采用了“以空间换时间”的方式
E.ThreadLocal继承自Thread
F.ThreadLocal实现了Runnable接口
G.ThreadLocal重要作用在于多线程间的数据共享
H.ThreadLocal是采用哈希表的方式来为每个线程都提供一个变量的副本
I.ThreadLocal保证各个线程间数据安全,每个线程的数据不会被另外线程访问和破坏
知识点
-
作用
ThreadLocal设计的初衷:提供线程内部的局部变量,在本线程内随时随地可取,隔离其他线程。
-
举例
举个例子,我出门需要先坐公交再做地铁,这里的坐公交和坐地铁就好比是同一个线程内的两个函数,我就是一个线程,我要完成这两个函数都需要同一个东西:公交卡(北京公交和地铁都使用公交卡),那么我为了不向这两个函数都传递公交卡这个变量(相当于不是一直带着公交卡上路),我可以这么做:将公交卡事先交给一个机构,当我需要刷卡的时候再向这个机构要公交卡(当然每次拿的都是同一张公交卡)。这样就能达到只要是我(同一个线程)需要公交卡,何时何地都能向这个机构要的目的。 有人要说了:你可以将公交卡设置为全局变量啊,这样不是也能何时何地都能取公交卡吗?但是如果有很多个人(很多个线程)呢?大家可不能都使用同一张公交卡吧(我们假设公交卡是实名认证的),这样不就乱套了嘛。
-
其它
对于多线程资源共享的问题,同步机制采用了“以时间换空间”的方式,而T**hreadLocal采用了“以空间换时间”**的方式。前者仅提供一份变量,让不同的线程排队访问,而后者为每一个线程都提供了一份变量,因此可以同时访问而互不影响。
在Thread中有一个成员变量ThreadLocals,该变量的类型是ThreadLocalMap,也就是一个Map,它的键是threadLocal,值为就是变量的副本。通过ThreadLocal的get()方法可以获取该线程变量的本地副本,在get方法之前要先set,否则就要重写initialValue()方法。
-
注意:
①ThreadLocal并没有继承自Thread,也没有实现Runnable接口。
②ThreadLocal类为每一个线程都维护了自己独有的变量拷贝。每个线程都拥有了自己独立的一个变量。
所以ThreadLocal重要作用并不在于多线程间的数据共享,而是数据的独立
③ThreadLocal中定义了一个哈希表用于为每个线程都提供一个变量的副本
-
线程局部存储TLS(thread local storage)
解决多线程中的对同一变量的访问冲突的一种技术 TLS会为每一个线程维护一个和该线程绑定的变量的副本 Java平台的java.lang.ThreadLocal是TLS技术的一种实现
16.创建一个对象的初始化过程
题目
//输出结果
class C {
C() {
System.out.print("C");
}
}
class A {
C c = new C();
A() {
this("A");
System.out.print("A");
}
A(String s) {
System.out.print(s);
}
}
class Test extends A {
Test() {
super("B");
System.out.print("B");
}
public static void main(String[] args) {
new Test();
}
}
解析
这题最大的坑在于,会不会调用父类(A)的无参构造。
因为Test已经显式调用了super(“B”),所以会直接调用A的有参构造。
如果删除super(“B”),系统才会默认调用父类无参构造,此时答案为:CAAB。
(1)初始化父类的普通成员变量和代码块,执行 C c = new C(); 输出C
(2)super(“B”); 表示调用父类的构造方法,不调用父类的无参构造函数,输出B
(3) System.out.print(“B”);
所以输出CBB
知识点
创建一个对象的初始化过程:
1.首先,初始化父类中的静态成员变量和静态代码块,按照在程序中出现的顺序初始化;
2.然后,初始化子类中的静态成员变量和静态代码块,按照在程序中出现的顺序初始化;
3.其次,初始化父类的普通成员变量和代码块,再执行父类的构造方法;
4.最后,初始化子类的普通成员变量和代码块,再执行子类的构造方法;
17.JVM组成和各模块线程共享情况
题目
java运行时内存分为“线程共享”和“线程私有”两部分,以下哪些属于“线程共享”部分
程序计算器
方法区
java虚拟机栈
java堆
解析
私有:java虚拟机栈(JVM栈),程序计数器(程序寄存器),本地方法栈
共享:java堆,方法区
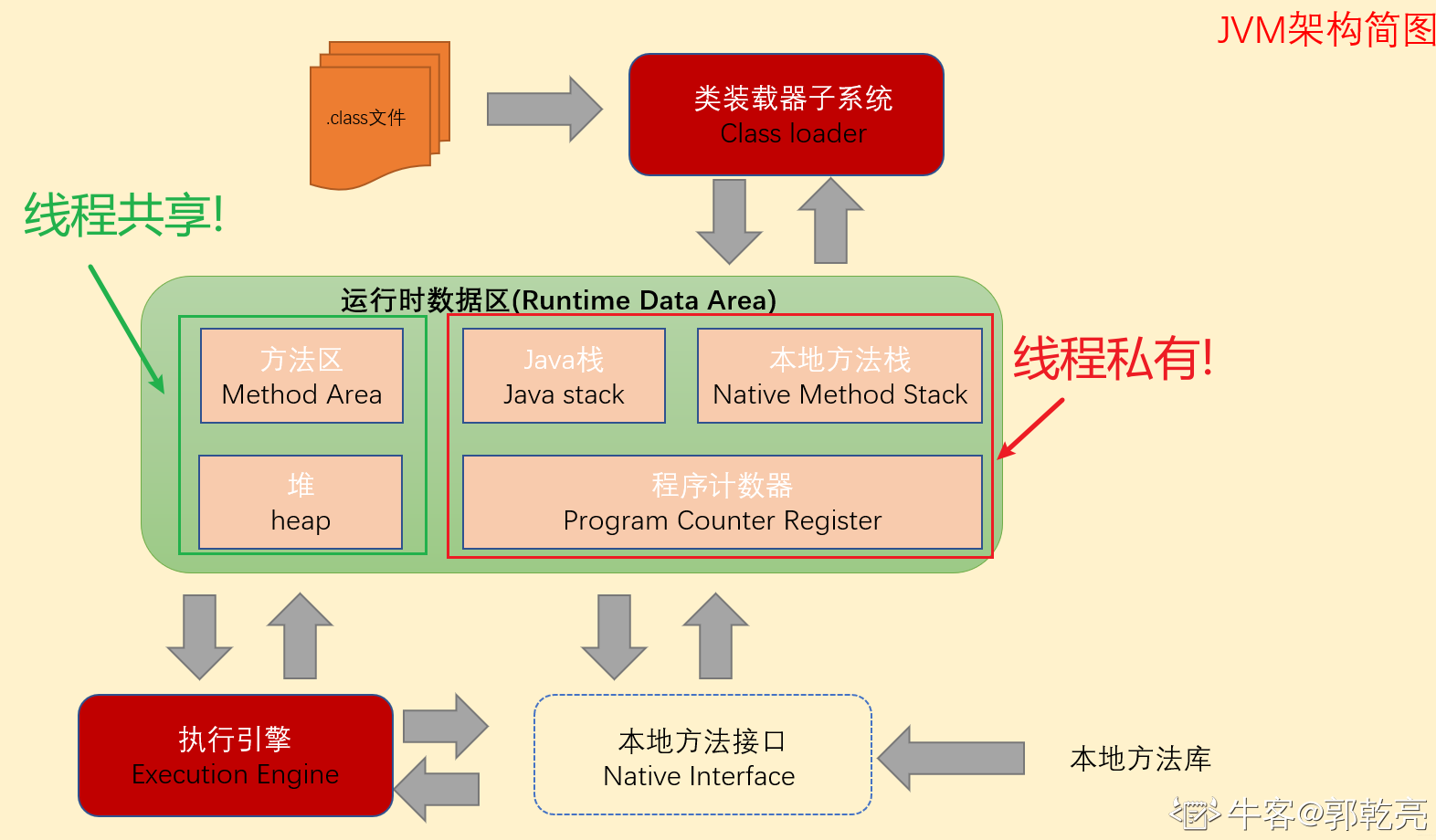
大多数 JVM 将内存区域划分为 Method Area(Non-Heap)(方法区) ,Heap(堆) , Program Counter Register(程序计数器) , VM Stack(虚拟机栈,也有翻译成JAVA 方法栈的),Native Method Stack ( 本地方法栈 ),其中Method Area 和 Heap 是线程共享的 ,VM Stack,Native Method Stack 和Program Counter Register 是非线程共享的。为什么分为 线程共享和非线程共享的呢?请继续往下看。
首先我们熟悉一下一个一般性的 Java 程序的工作过程。一个 Java 源程序文件,会被编译为字节码文件(以 class 为扩展名),每个java程序都需要运行在自己的JVM上,然后告知 JVM 程序的运行入口,再被 JVM 通过字节码解释器加载运行。那么程序开始运行后,都是如何涉及到各内存区域的呢?
概括地说来,JVM初始运行的时候都会分配好 Method Area(方法区) 和Heap(堆) ,而JVM 每遇到一个线程,就为其分配一个 Program Counter Register(程序计数器) , VM Stack(虚拟机栈)和Native Method Stack (本地方法栈), 当线程终止时,三者(虚拟机栈,本地方法栈和程序计数器)所占用的内存空间也会被释放掉。这也是为什么我把内存区域分为线程共享和非线程共享的原因,非线程共享的那三个区域的生命周期与所属线程相同,而线程共享的区域与JAVA程序运行的生命周期相同,所以这也是系统垃圾回收的场所只发生在线程共享的区域(实际上对大部分虚拟机来说知发生在Heap上)的原因。
2022.3.7
1.hashCode() Vs equals() 对象判等
题目
下面论述正确的是()?
A.如果两个对象的hashcode相同,那么它们作为同一个HashMap的key时,必然返回同样的值
B.如果a,b的hashcode相同,那么a.equals(b)必须返回true
C.对于一个类,其所有对象的hashcode必须不同
D.如果a.equals(b)返回true,那么a,b两个对象的hashcode必须相同
解析
A.中HashMap的key唯一,在put对象的时候,如果key之前存入过则本次存入值会覆盖之前key存入的值并且返回之前key对应的值。
hashCode()方法和equals()方法都是用来判断两个对象是否相等一致且都在基类Object中定义,其它对象或者自定义对象不重写都是使用默认的Object中继承过来的。
**那么equals()既然已经能实现对比的功能了,为什么还要hashCode()呢?**因为重写的equals()里一般比较的比较全面比较复杂,这样效率就比较低,而利用hashCode()进行对比,则只要生成一个hash值进行比较就可以了,效率很高。
那么hashCode()既然效率这么高为什么还要equals()呢? 因为hashCode()并不是完全可靠,有时候不同的对象他们生成的hashcode也会一样(生成hash值的公式可能存在的问题),所以hashCode()只能说是大部分时候可靠,并不是绝对可靠,
所以我们可以得出:
1.equals()相等的两个对象他们的hashCode()肯定相等,也就是用equals()对比是绝对可靠的。
2.hashCode()相等的两个对象他们的equal()不一定相等,也就是hashCode()不是绝对可靠的。
所有对于需要大量并且快速的对比的话如果都用equals()去做显然效率太低,所以解决方式是,每当需要对比的时候,首先用hashCode()去对比,如果hashCode()不一样,则表示这两个对象肯定不相等(也就是不必再用equal()去再对比了),如果hashCode()相同,此时再对比他们的equals(),如果equals()也相同,则表示这两个对象是真的相同了,这样既能大大提高了效率也保证了对比的绝对正确性
2.关键字和保留字
1)48个关键字:abstract、assert、boolean、break、byte、case、catch、char、class、continue、default、do、double、else、enum、extends、final、finally、float、for、if、implements、import、int、interface、instanceof、long、native、new、package、private、protected、public、return、short、static、strictfp、super、switch、synchronized、this、throw、throws、transient、try、void、volatile、while。
2)const和goto既是保留字又是关键字
3)3个特殊直接量:true、false、null。是不是关键字有争议,因为其它关键字都没有值。
不是关键字的常见选项–then sizeof true false null
3.JVM内存配置参数及内存结构
题目
对于JVM内存配置参数:
-Xmx10240m -Xms10240m -Xmn5120m -XXSurvivorRatio=3
,其最小内存值和Survivor区总大小分别是()
解析
-
内存配置参数
-Xmn5120m:代表新生代 -XXSurvivorRatio=3:代表Eden:Survivor = 3 (默认8:1)
-Xmx10240m:代表最大堆
-Xms10240m:代表最小堆
-Xmn5120m:代表新生代
-XXSurvivorRatio=3:代表Eden:Survivor = 3 根据Generation-Collection算法(目前大部分JVM采用的算法),一般根据对象的生存周期将堆内存分为若干不同的区域,一般情况将新生代分为Eden ,两块Survivor; 计算Survivor大小, Eden:Survivor = 3,总大小为5120,3x+x+x=5120 x=1024
新生代大部分要回收,采用Copying算法,快!
老年代 大部分不需要回收,采用Mark-Compact算法
-
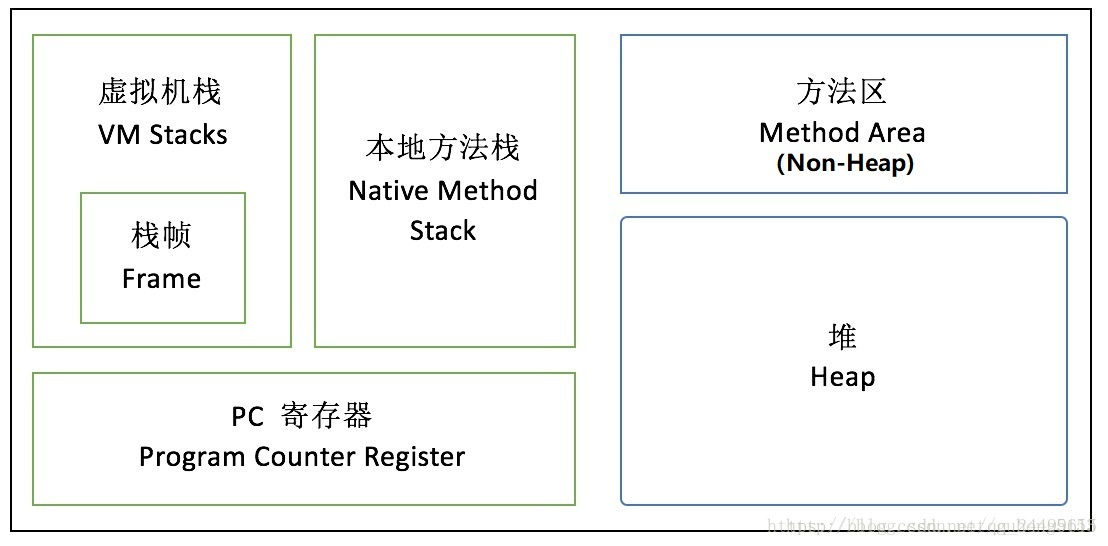
内存结构–没有堆帧
栈(虚拟机栈+本地方法栈),栈帧,PC寄存器/程序计数器,方法区,堆
-
内存结构说明
https://blog.csdn.net/qq_41701956/article/details/81664921
题目
关于Java内存区域下列说法不正确的有哪些 BC
程序计数器是一块较小的内存空间,它的作用可以看做是当前线程所执行的字节码的信号指示器,每个线程都需要一个独立的程序计数器. Java虚拟机栈描述的是java方法执行的内存模型,每个方法被执行的时候都会创建一个栈帧,用于存储局部变量表、类信息、动态链接等信息 Java堆是java虚拟机所管理的内存中最大的一块,每个线程都拥有一块内存区域,所有的对象实例以及数组都在这里分配内存。 方法区是各个线程共享的内存区域,它用于存储已经被虚拟机加载的常量、即时编译器编译后的代码、静态变量等数据。解析
B.类信息不是存储在java虚拟机栈中,而是存储在方法区中;
C.java堆是被所有线程共享的一块内存区域,而不是每个线程都拥有一块内存区域。
4.各排序方法的算法复杂度
题目
在各自最优条件下,对N个数进行排序,哪个算法复杂度最低的是? ()
A.插入排序
B.快速排序
C.堆排序
D.归并排序
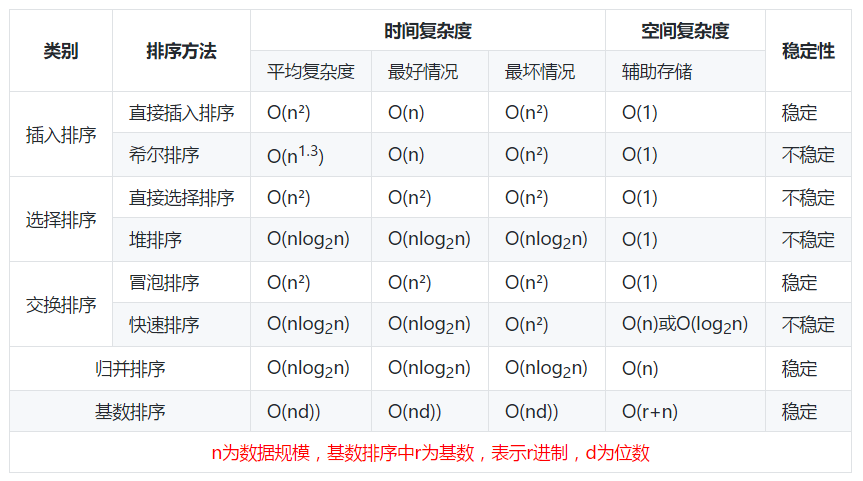
解析
对于插入排序,最优条件就是本身有序,所以循环一遍就好了。
知识点
-
各排序算法的时间复杂度图示
5.Class类
知识点
- Class类继承于Object类
- Class.forName(“类或接口的全类名”)可以返回相关的Class对象即可以装载其它类
6.ClassLoader类加载器
题目
下面有关java classloader说法错误的是?
A.Java默认提供的三个ClassLoader是BootStrap ClassLoader,Extension ClassLoader,
AppClassLoader
B.ClassLoader使用的是双亲委托模型来搜索类的
C.JVM在判定两个class是否相同时,只用判断类名相同即可,和类加载器无关
D.ClassLoader就是用来动态加载class文件到内存当中用的
解析
C.JVM判断类是否相同是除了要判断类名是否一致外,还要判断是否由同一个类加载器实例加载出来的。
知识点
比较两个类是否相等,只有这两个类是由同一个类加载器加载才有意义。否则,即使这两个类是来源于同一个Class文件,只要加载它们的类加载器不同,那么这两个类必定不相等。
补充:
1. 什么是类加载器?
把类加载的过程放到Java虚拟机外部去实现,让应用程序决定如何去获取所需要的类。实现这个动作的代码模块称为“类加载器”。
2. 有哪些类加载器,分别加载哪些类
类加载器按照层次,从顶层到底层,分为以下三种:
(1)启动类加载器BootStrap ClassLoader : 它用来加载 Java 的核心库,比如String、System这些类
(2)扩展类加载器Extension ClassLoader : 它用来加载 Java 的扩展库。
(3) 应用程序类加载器AppClassLoader : 负责加载用户类路径上所指定的类库,一般来说,Java 应用的类都是由它来完成加载的。
3. 双亲委派模型
我们应用程序都是由以上三种类加载器互相配合进行加载的,还可以加入自己定义的类加载器。称为 类加载器的双亲委派模型 ,这里类加载器之间的父子关系一般不会以继承的关系来实现,而是都使用 组合关系 来复用父加载器的。
4. 双亲委托模型的工作原理
是当一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,每一个层次的类加载都是如此,因此所有的加载请求最终都应该传送到顶层的启动类加载器中,只有当父加载器反馈自己无法加载这个加载请求的时候,子加载器才会尝试自己去加载。
5. 使用双亲委派模型好处?(原因)
第一:可以避免重复加载,当父亲已经加载了该类的时候,子类不需要再次加载。
第二:考虑到安全因素,如果不使用这种委托模式,那我们就可以随时使用自定义的String来动态替代java核心api中定义类型,这样会存在非常大的安全隐患,而双亲委托的方式,就可以避免这种情况,因为String已经在启动时被加载,所以用户自定义类是无法加载一个自定义的类装载器。
7.创建子类调用父类构造时父类构造调用子类重写后的方法打印子类成员变量时的情况
题目
//打印结果
public class Base
{
private String baseName = "base";
public Base()
{
callName();
}
public void callName()
{
System. out. println(baseName);
}
static class Sub extends Base
{
private String baseName = "sub";
public void callName()
{
System. out. println (baseName) ;
}
}
public static void main(String[] args)
{
Base b = new Sub();
}
}
解析
创建Sub对象时是通过Sub的无参构造创建,这里没声明默认存在一个无参构造且第一行代码调用父类构造super();父类在构造时调用了callName()方法而callName方法被Sub子类重写了所以执行子类的callName()方法,要求打印成员变量baseName,这里由于子类Sub构造未完成成员变量还没初始化所以此时打印的null
8.垃圾收集
题目
下面关于垃圾收集的说法正确的是 D
A.一旦一个对象成为垃圾,就立刻被收集掉。
B.对象空间被收集掉之后,会执行该对象的finalize方法
C.finalize方法和C++的析构函数是完全一回事情
D.一个对象成为垃圾是因为不再有引用指着它,但是线程并非如此
解析
1、在java中,对象的内存在哪个时刻回收,取决于垃圾回收器何时运行。
2、一旦垃圾回收器准备好释放对象占用的存储空间,将首先调用其finalize()方法, 并且在下一次垃圾回收动作发生时,才会真正的回收对象占用的内存(《java 编程思想》)
3、线程的释放是在run()方法结束以后,此时线程的引用可能并未释放。
4、方法调用时,会创建栈帧在栈中,调用完是程序自动出栈释放,而不是gc(垃圾回收器)释放,gc释放的是堆区的内容(所有对象)
9.算术运算符
知识点
- 右移 左移 无符号右移
1.>>和>>>
运算符“>>”执行算术右移,它使用最高位填充移位后左侧的空位。
右移的结果为:每移一位,第一个操作数被2除一次,移动的次数由第二个操作数确定。
>>为带符号右移,右移后左边的空位被填充为符号位
逻辑右移或叫无符号右移运算符“>>>“只对位进行操作,没有算术含义,它用0填充左侧的空位。
算术右移不改变原数的符号,而逻辑右移不能保证这点。
>>>为不带符号右移,右移后左边的空位被填充为0
-
取余%和取模mod运算
%是取余,余数和被除数符号一致
mod是取模,和除数符号一致
10.标识符规范
题目
下列可作为java语言标识符的是()
a1
$1
_1
11
知识点
- 标识符的组成元素是字母(a-z,A-Z),数字(0~9),下划线(_)和美元符号($)。
- 标识符不能以数字开头。
- java的标识符是严格区分大小写的。
- 标识符的长度可以是任意的。
- 关键字,保留字以及null、true、false不能用于自定义的标识符。
- 注意关键字都是小写 如 null是关键字而NULL不是关键字 即NULL可以作为标识符存在
11.枚举类
题目
//下面代码输出是?
enum AccountType
{
SAVING, FIXED, CURRENT;
private AccountType()
{
System.out.println("It is a account type");
}
}
class EnumOne
{
public static void main(String[]args)
{
System.out.println(AccountType.FIXED);
}
}
知识点
枚举类在后台实现时,实际上是转化为一个继承了java.lang.Enum类的实体类,原先的枚举类型变成对应的实体类型,而每个枚举项都是该实体类的一个对象。上例中AccountType变成了个class AccountType,并且会生成一个新的构造函数,若原来有构造函数,则在此基础上添加两个参数,生成新的构造函数,如上例子中:
`private` `AccountType(){ System.out.println(“It is a account type”); }`
会变成:
`private` `AccountType(String s, ``int` `i){`` ``super``(s,i); System.out.println(“It is a account type”); }`
而在这个类中,会添加若干字段来代表具体的枚举类型:
`public` `static` `final` `AccountType SAVING;``public` `static` `final` `AccountType FIXED;``public` `static` `final` `AccountType CURRENT;`
而且还会添加一段static代码段:
`static``{`` ``SAVING = ``new` `AccountType(``"SAVING"``, ``0``);`` ``... CURRENT = ``new` `AccountType(``"CURRENT"``, ``0``);`` ``$VALUES = ``new` `AccountType[]{`` ``SAVING, FIXED, CURRENT`` ``} }`
静态代码块随类的加载而加载且只执行一次,以此来初始化枚举中的每个具体类型。(并将所有具体类型放到一个$VALUE数组中,以便用序号访问具体类型)
在初始化过程中new AccountType构造函数被调用了三次,所以Enum中定义的构造函数中的打印代码被执行了3遍。
12.进程与线程&线程锁(监视器)机制
题目
关于多线程和多进程,下面描述正确的是():
A.多进程里,子进程可获得父进程的所有堆和栈的数据;而线程会与同进程的其他线程共享数据,拥有自己的栈空间。
B.线程因为有自己的独立栈空间且共享数据,所有执行的开销相对较大,同时不利于资源管理和保护。
C.线程的通信速度更快,切换更快,因为他们在同一地址空间内。
D.一个线程可以属于多个进程。
//AC
解析
A.子进程得到的是除了代码段是与父进程共享以外,其他所有的都是得到父进程的一个副本,子进程的所有资源都继承父进程,得到父进程资源的副本,子进程可获得父进程的所有堆和栈的数据,但二者并不共享地址空间。两个是单独的进程,继承了以后二者就没有什么关联了,子进程单独运行;进程的线程之间共享由进程获得的资源,但线程拥有属于自己的一小部分资源,就是栈空间,保存其运行状态和局部自动变量的。
B.线程之间共享进程获得的数据资源,所以开销小,但不利于资源的管理和保护;而进程执行开销大,但是能够很好的进行资源管理和保护。
**C.**线程的通信速度更快,切换更快,因为他们共享同一进程的地址空间。
**D.**一个进程可以有多个线程,线程是进程的一个实体,是CPU调度的基本单位。
知识点
-
线程调度机制
一般线程调度模式分为两种——抢占式调度和协同式调度。抢占式调度指的是每条线程执行的时间、线程的切换都由系统控制,系统控制指的是在系统某种运行机制下,可能每条线程都分同样的执行时间片,也可能是某些线程执行的时间片较长,甚至某些线程得不到执行的时间片。在这种机制下,一个线程的堵塞不会导致整个进程堵塞。协同式调度指某一线程执行完后主动通知系统切换到另一线程上执行,这种模式就像接力赛一样,一个人跑完自己的路程就把接力棒交接给下一个人,下个人继续往下跑。线程的执行时间由线程本身控制,线程切换可以预知,不存在多线程同步问题,但它有一个致命弱点:如果一个线程编写有问题,运行到一半就一直堵塞,那么可能导致整个系统崩溃。
java采用的是抢占式调度方式。 -
线程锁机制 - 监视器
java中使用互斥锁有synchronized和ReentrantLock两种方式,第二种方式是jdk1.5之后出现,属于util.concurrent.locks.ReentrantLock
2022.3.8
1.位运算符
知识点
直接对补码(负数注意转换)进行运算,效率高
&与,|或,^异或,~按位取反,<<左移 >>右移 >>>无符号右移
与逻辑运算符的区别,若&,|,^两端都是数值,则进行位运算
-
& 将两边数值换成二进制(正数三码合一,负数先求出反码),然后按位与,有零则零,全1则1
-
| 将两边数值换成二进制(正数三码合一,负数先求出反码),然后按位或,有1则1,全0则0
-
^将两边数值换成二进制(正数三码合一,负数先求出反码),然后按位异或,不同为1,相同为0
-
<<左移 正数左移,丢弃左边bit位,被移除位补0.
-
》》右移,正数右移丢弃右边bit位,高位补零,负数则注意最高位补1
-
》》》不管正负,高位补0
-
左右移结论: 右移n位,即/2n,左移n位,即*2n;(2 << 3和2 * 8)
-
异或结论:一个数被另一个数异或两次,则该数不变。(交换数值) a ^ b ^ a = b; a ^ b ^ b = a;
自己异或自己为0。
2.集合&HashMapVsHashTable
知识点
-
集合的分类:单列集合Collection和双列集合Map
-
继承体系
简单的参考 这里HashTable的继承体系有问题 HashTable是直接继承于Dictionary抽象类从而实现的Map接口
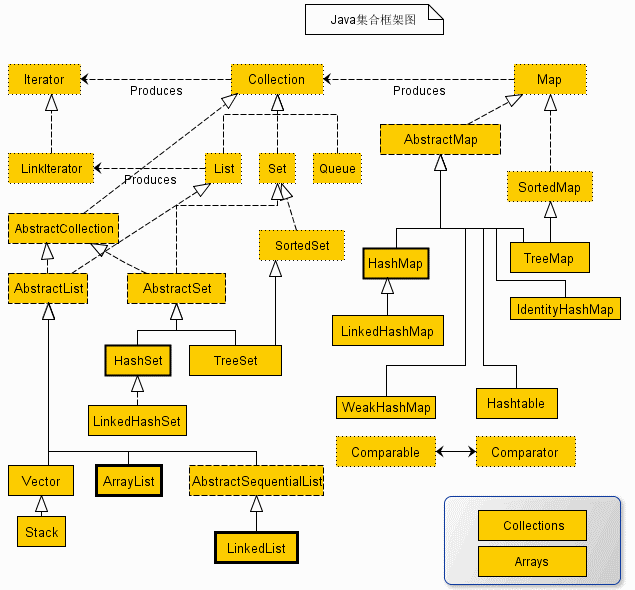
-
各集合特点
-
单列集合
1.1 List集合 - 元素有序(存取元素顺序一致),允许重复元素
①ArrayList:底层数据结构是数组,查询快,增删慢,线程不安全,效率高
②Vector:底层数据结构是数组,查询快,增删慢,线程安全,效率低
③LinkedList:底层数据结构是链表,查询慢,增删快,线程不安全,效率高
1.2 Set集合 - 元素唯一
①HashSet:底层数据结构是哈希表 ,线程不安全效率高。元素无序(存取顺序不一致)且唯一 唯一性,是靠重写equals()方法来保证
注: HashSet子类依靠hashCode()和equal()方法来区分重复元素。 HashSet内部使用Map保存数据,即将HashSet的数据作为Map的key值保存,这也是HashSet中元素不能重复的原因。而Map中保存key值的,会去判断当前Map中是否含有该Key对象,内部是先通过key的hashCode,确定有相同的hashCode之后,再通过equals方法判断是否相同。
②LinkedHashSet:底层数据结构是链表和哈希表,线程不安全效率高。链表保证有序,哈希表保证唯一。元素唯一且有序
③TreeSet:底层数据结构是二叉树。元素唯一,且可以对元素进行排序
-
双列集合
①HashMap: 数组+链表组成,存储的键无序且唯一,线程不安全,效率高。可以存null值或空字符串作为K且只能存一个也可以存null值
②Hashtable:底层是散列表,存储的键无序且唯一,线程安全,效率低。不可以存null值null键
③LinkedHashMap:键存储的数据结构-链表 + 哈希表 链表保证键有序,哈希保证键唯一
存储的键有序且唯一
④TreeMap: 键存储的数据结构:二叉树。键唯一且可以对键进行排序。键不允许null值可以为Null
-
-
HashMap Vs HashTable
Hashtable:
(1)Hashtable 是一个散列表,它存储的内容是键值对(key-value)映射。
(2)Hashtable 的函数都是同步的,这意味着它是线程安全的。它的key、value都不可以为null。
(3)HashTable直接使用对象的hashCode。
(4) HashTable继承自Dictionary类,实现了Map接口。且Properties 类 继承了 Hashtable 类
(5) 内部实现方式的数组的初始大小和扩容的方式不同。HashTable中hash数组默认大小是11,增加的方式是old*2+1
HashMap:
(1)由数组+链表组成的,基于哈希表的Map实现,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的。
(2)线程非安全,HashMap可以接受为null的键(key)和值(value)。且null键唯一,null值多个
(3)HashMap重新计算hash值
(4) HashMap继承自AbstractMap,实现Map接口
(5) 内部实现方式的数组的初始大小和扩容的方式不同。HashMap中hash数组的默认大小是16,而且一定是2的指数。
1. 关于HashMap的一些说法:
a.HashMap的实例有俩个参数影响其性能: “初始容量” 和 装填因子。
b.HashMap中的key-value都是存储在Entry中的。
c.不保证元素的顺序恒久不变,它的底层使用的是数组和链表,通过hashCode()方法和equals方法保证键的唯一性
d.解决冲突主要有三种方法:定址法,拉链法,再散列法。HashMap是采用拉链法解决哈希冲突的。 注: 链表法是将相同hash值的对象组成一个链表放在hash值对应的槽位;
用开放定址法解决冲突的做法是:当冲突发生时,使用某种探查(亦称探测)技术在散列表中形成一个探查(测)序列。 沿此序列逐个单元地查找,直到找到给定 的关键字,或者碰到一个开放的地址(即该地址单元为空)为止(若要插入,在探查到开放的地址,则可将待插入的新结点存人该地址单元)。
拉链法解决冲突的做法是: 将所有关键字为同义词的结点链接在同一个单链表中 。若选定的散列表长度为m,则可将散列表定义为一个由m个头指针组成的指针数 组T[0..m-1]。凡是散列地址为i的结点,均插入到以T[i]为头指针的单链表中。T中各分量的初值均应为空指针。在拉链法中,装填因子α可以大于1,但一般均取α≤1。拉链法适合未规定元素的大小。
3.接口和抽象类比较
题目
jdk1.8中,下面有关java 抽象类和接口的区别,说法错误的是?
BD
A.抽象类可以有构造方法,接口中不能有构造方法
B.抽象类中可以包含非抽象的普通方法,接口中的方法必须是抽象的,不能有非抽象的普通方法
C.一个类可以实现多个接口,但只能继承一个抽象类
D.接口中可以有普通成员变量,抽象类中没有普通成员变量
知识点
抽象类
1.抽象类中可以构造方法
2.抽象类中可以存在普通属性(成员变量修饰符不限定),方法,静态属性和方法。
3.抽象类中可以存在抽象方法。
4.如果一个类中有一个抽象方法,那么当前类一定是抽象类;抽象类中不一定有抽象方法。
5.抽象类中的抽象方法,需要有子类实现,如果子类不实现,则子类也需要定义为抽象的。
接口
1.(1.8之前在接口中只有方法的声明,没有方法体)。1.8后允许有静态方法存在
2.在接口中只有常量,因为定义的变量,在编译的时候都会默认加上
public static final
3.在接口中的方法,永远都被public来修饰。
4.接口中没有构造方法,也不能实例化接口的对象。
5.接口可以多继承其它接口
6.接口中定义的方法都需要有实现类来实现,如果实现类不能实现接口中的所有方法
则实现类定义为抽象类。
7.接口默认被abstract修饰
4.PreparedStatement和Statement执行Sql方式及ps好处及继承体系
题目
以下描述正确的是 B
CallableStatement是PreparedStatement的父接口
PreparedStatement是CallableStatement的父接口
CallableStatement是Statement的父接口
PreparedStatement是Statement的父接口
知识点
-
PreparedStatement好处
PreparedStatement是预编译的,使用PreparedStatement有几个好处
a. 在执行可变参数的一条SQL时,PreparedStatement比Statement的效率高,因为DBMS预编译一条SQL当然会比多次编译一条SQL的效率要高。
b. 安全性好,有效防止Sql注入等问题。
c. 对于多次重复执行的语句,使用PreparedStament效率会更高一点,并且在这种情况下也比较适合使用batch;
d. 代码的可读性和可维护性。
-
继承体系
CallableStatement 继承自 PreparedStatement 而PreparedStatement继承自Statement
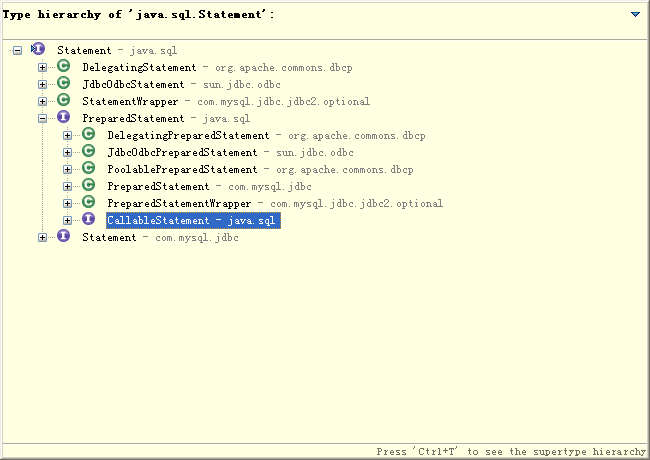
-
jdbc中创建ps和s的方式
①ps创建
创建PreparedStatement是需要传入sql语句
作为 Statement 的子类,PreparedStatement 继承了 Statement 的所有功能。三种方法 execute、 executeQuery 和 executeUpdate 已被更改以使之不再需要参数
PreparedStatement pst=con.prepareStatement(“select * from book”); ResultSet rst=pst.executeQuery();②s的创建
创建Statement是不传参的,调用方法需要传参
Statement sta=con.createStatement(); ResultSet rst=sta.executeQuery(“select * from book”);
5.类初始化的条件以及过程
题目
- 初始化条件
//运行代码,输出的结果是()
public class P {
public static int abc = 123;
static{
System.out.println("P is init");
}
}
public class S extends P {
static{
System.out.println("S is init");
}
}
public class Test {
public static void main(String[] args) {
System.out.println(S.abc);
}
}
//P is init<br />123
-
初始化过程
//打印结果 YXYZ class X{ Y y=new Y(); public X(){ System.out.print("X"); } } class Y{ public Y(){ System.out.print("Y"); } } public class Z extends X{ Y y=new Y(); public Z(){ System.out.print("Z"); } public static void main(String[] args) { new Z(); } }
知识点
类初始化条件
虚拟机规范严格规定了有且只有五种情况必须立即对类进行“初始化”:
-
使用new关键字实例化对象的时候、读取或设置一个类的静态字段的时候,已经调用一个类的静态方法的时候。
-
使用java.lang.reflect包的方法对类进行反射调用的时候,如果类没有初始化,则需要先触发其初始化。
-
当初始化一个类的时候,如果发现其父类没有被初始化就会先初始化它的父类。
-
当虚拟机启动的时候,用户需要指定一个要执行的主类(就是包含main()方法的那个类),虚拟机会先初始化这个类;
-
使用Jdk1.7动态语言支持的时候的一些情况。
除了这五种之外,其他的所有引用类的方式都不会触发初始化,称为被动引用。下面是被动引用的三个例子:
-
通过子类引用父类的的静态字段,不会导致子类初始化。
-
通过数组定义来引用类,不会触发此类的初始化。
public class NotInitialization {
public static void main(String[] args) {
SuperClass[] sca = new SuperClass[10];
}
}
- 常量在编译阶段会存入调用类的常量池中,本质上没有直接引用到定义常量的类,因此不会触发定义常量的类的初始化。
public class ConstClass {
static {
System.out.println("ConstClass init!");
}
public static final int value = 123;
}
public class NotInitialization{
public static void main(String[] args) {
int x = ConstClass.value;
}
}
上述代码运行之后,也没有输出“ConstClass init!”,这是因为虽然在Java源码中引用了ConstClass类中的常量value,但其实在编译阶段通过常量传播优化,已经将此常量的值“123”存储到了NotInitialization类的常量池中,以后NotInitialization对常量ConstClass.value的引用实际都被转化为NotInitialization类对自身常量池的引用了。也就是说,实际上NotInitialization的Class文件之中并没有ConstClass类的符号引用入口,这两个类在编译成Class之后就不存在任何联系了。
参考资料:https://blog.csdn.net/qq_22771739/article/details/86348962
初始化过程
-
初始化父类中的静态成员变量和静态代码块 ;
-
初始化子类中的静态成员变量和静态代码块 ;
-
初始化父类的普通成员变量和代码块,再执行父类的构造方法;
-
初始化子类的普通成员变量和代码块,再执行子类的构造方法;
解析:
(1)初始化父类的普通成员变量和代码块,执行 Y y=new Y(); 输出Y
(2)再执行父类的构造方法;输出X
(3) 初始化子类的普通成员变量和代码块,执行 Y y=new Y(); 输出Y
(4)再执行子类的构造方法;输出Z
所以输出YXYZ
6.依赖注入和控制反转
题目
关于依赖注入,下列选项中说法错误的是(B)
依赖注入能够独立开发各组件,然后根据组件间关系进行组装
依赖注入使组件之间相互依赖,相互制约
依赖注入提供使用接口编程
依赖注入指对象在使用时动态注入
解析
B.依赖注入就是减少了耦合,减少了依赖。
知识点
依赖注入有效的分离了对象和它所需要的外部资源,使得它们松散耦合,有利于功能复用,更重要的是使得程序的整个体系结构变得非常灵活。
依赖注入和控制反转是对同一件事情的不同描述,从某个方面讲,就是它们描述的角度不同。依赖注入是从应用程序的角度在描述,可以把依赖注入描述完整点:应用程序依赖容器创建并注入它所需要的外部资源。换言之,依赖注入的引入体现了主从换位的思想,应用程序从主动创建获取外部资源变成了被动等待容器创建注入外部资源;而控制反转是从容器的角度在描述,描述完整点:容器控制应用程序,由容器反向的向应用程序注入应用程序所需要的外部资源。
7.重载静态多分派
题目
//以下代码执行的结果是多少()? Super:collection<br>Super:collection<br >Super:collection
public class Demo {
public static void main(String[] args) {
Collection<?>[] collections =
{new HashSet<String>(), new ArrayList<String>(), new HashMap<String, String>().values()};
Super subToSuper = new Sub();
for(Collection<?> collection: collections) {
System.out.println(subToSuper.getType(collection));
}
}
abstract static class Super {
public static String getType(Collection<?> collection) {
return “Super:collection”;
}
public static String getType(List<?> list) {
return “Super:list”;
}
public String getType(ArrayList<?> list) {
return “Super:arrayList”;
}
public static String getType(Set<?> set) {
return “Super:set”;
}
public String getType(HashSet<?> set) {
return “Super:hashSet”;
}
}
static class Sub extends Super {
public static String getType(Collection<?> collection) {
return "Sub"; }
}
}
解析
-
考察点1-子类不能重写父类static方法
这里Sub子类也定义了和父类完全相同的静态方法。所以在调用时该方法都是各自独有的,这里题目用Super接收的对象,所以调用的是父类的静态方法getType()
-
考察点2-重载方法的调用遵循静态多分配原则
在Demo中遍历到的每个集合元素的静态类型应为Collection col,在调用重载方法时不考虑运行时的实际类型如HashSet,ArrayList等。则返回的都是Super:collection。总结来说:重载实际上是使用静态分派的,重载时是通过参数的静态类型而不是实际类型作为判定依据的
-
考察点3:假如所有方法都不用static修饰
则考察点变为多态,调用非静态方法时编译看左运行看右,即都会调用子类重写过的getType方法返回三次Sub
2022.3.9
1.Java中类的编译与运行
题目
关于java编译和运行命令叙述不正确的是? ( )
A.运行“java Scut.class”
B.运行“java Scut”
C.编译 Scut.java文件,使用“javac Scut.java”命令的输出文件是Scut.class
D.java这个命令的运行对象是Scut.class
解析
编译命令,javac后跟 你的 Java 程序名字加后缀,也就是 YourClassName.java 。输出的是类名.class文件
运行命令是 java + 你的 Java 程序的名字但是不加后缀
2.Servlet与CGI
题目
下面有关servlet和cgi的描述,说法错误的是?(D)
A.servlet处于服务器进程中,它通过多线程方式运行其service方法
B.CGI对每个请求都产生新的进程,服务完成后就销毁
C.servlet在易用性上强于cgi,它提供了大量的实用工具例程,例如自动地解析和解码HTML表单数据、读取和设置 HTTP头、处理Cookie、跟踪会话状态等
D.cgi在移植性上高于servlet,几乎所有的主流服务器都直接或通过插件支持cgi
解析
Servlet处于服务器进程中,它通过多线程方式运行其service方法,一个实例可以服务于多个请求,并且其实例一般不会销毁。
而CGI对每个请求都产生新的进程,服务完成后就销毁,所以效率上低于Servlet 。
知识点
- CGI(Common Gateway Interface),通用网关接口
通用网关接口,简称CGI,是一种根据请求信息动态产生回应内容的技术。通过CGI,Web 服务器可以将根据请求不同启动不同的外部程序,并将请求内容转发给该程序,在程序执行结束后,将执行结果作为回应返回给客户端。也就是说,对于每个请求,都要产生一个新的进程进行处理,且服务完成后就销毁该进程。因为每个进程都会占有很多服务器的资源和时间,这就导致服务器无法同时处理很多的并发请求。另外CGI程序都是与操作系统平台相关的,虽然在互联网爆发的初期,CGI为开发互联网应用做出了很大的贡献,但是随着技术的发展,开始逐渐衰落。
- Servlet
Servlet最初是在1995年由James Gosling 提出的,因为使用该技术需要复杂的Web服务器支持,所以当时并没有得到重视,也就放弃了。后来随着Web应用复杂度的提升,并要求提供更高的并发处理能力,Servlet被重新捡起,并在Java平台上得到实现,现在提起Servlet,指的都是Java Servlet。Java Servlet要求必须运行在Web服务器当中,与Web服务器之间属于分工和互补关系。确切的说,在实际运行的时候Java Servlet与Web服务器会融为一体,如同一个程序一样运行在同一个Java虚拟机(JVM)当中。与CGI不同的是,Servlet对每个请求都是单独启动一个线程,而不是进程。这种处理方式大幅度地降低了系统里的进程数量,提高了系统的并发处理能力。另外因为Java Servlet是运行在虚拟机之上的,也就解决了跨平台问题。如果没有Servlet的出现,也就没有互联网的今天。
在Servlet出现之后,随着使用范围的扩大,人们发现了它的一个很大的一个弊端。那就是 为了能够输出HTML格式内容,需要编写大量重复代码,造成不必要的重复劳动。为了解决这个问题,基于Servlet技术产生了JavaServet Pages技术,也就是JSP。Servlet和JSP两者分工协作,Servlet侧重于解决运算和业务逻辑问题,JSP则侧重于解决展示问题。 Servlet与JSP一起为Web应用开发带来了巨大的贡献,后来出现的众多Java Web应用开发框架都是基于这两种技术的,更确切的说,都是基于Servlet技术的。
3.IO流继承体系&处理流(包装流)和节点流分类
题目
BufferedReader的父类是以下哪个?
FilterReader
InputStreamReader
PipedReader
Reader
知识点
- 继承体系
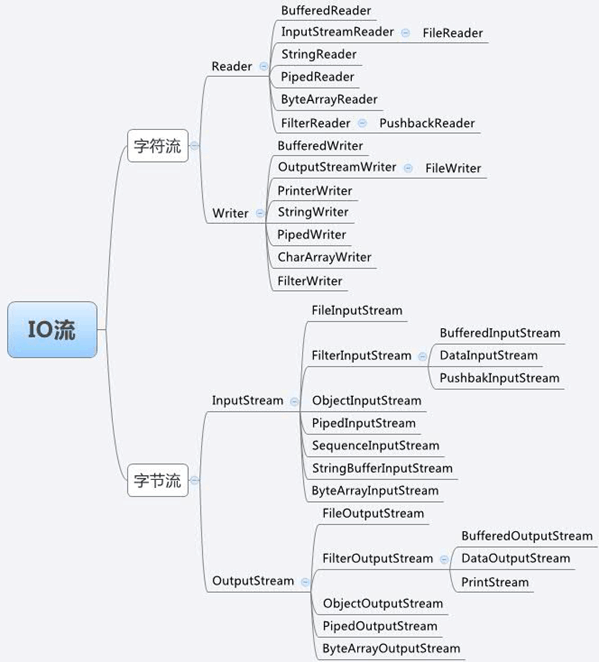
注意:
①字符流中FileReader继承自InputStreamReader,PushbackReader继承自FilterReader,FileWriter继承自OutputStreamWriter。换言之,除了文件字符输入流和文件字符输出流以及推回字符输入流外其它字符流都直接继承自Writer或Reader
②字节流中除了缓冲字节输入|出流,数据字节输入|出流和推回字节输入|出流外其它字节流都是直接继承自InputStream流和OutputStream流
③字符流和字节流每次读入的字节数是不确定的,可能相同也可能不相同
④字符流和字节流都有缓冲流
-
按是否直接与特定地方(如磁盘、内存、设备等)相连分为处理流和节点流
- 节点流:可以从或向一个特定的地方(节点)读写数据。如FileReader.
- 处理流:是对一个已存在的流的连接和封装,通过所封装的流的功能调用实现数据读写。如BufferedReader.处理流的构造方法总是要带一个其他的流对象做参数。一个流对象经过其他流的多次包装,称为流的链接。
JAVA常用的节点流:
- 文 件 FileInputStream FileOutputStrean FileReader FileWriter 文件进行处理的节点流。
- 字符串 StringReader StringWriter 对字符串进行处理的节点流。
- 数 组 ByteArrayInputStream ByteArrayOutputStreamCharArrayReader CharArrayWriter 对数组进行处理的节点流(对应的不再是文件,而是内存中的一个数组)。
- 管 道 PipedInputStream PipedOutputStream PipedReaderPipedWriter对管道进行处理的节点流。
常用处理流(关闭处理流使用关闭里面的节点流)
-
缓冲流:BufferedInputStrean BufferedOutputStream BufferedReader BufferedWriter 增加缓冲功能,避免频繁读写硬盘。
-
转换流:InputStreamReader OutputStreamReader 实现字节流和字符流之间的转换。
-
数据流 DataInputStream DataOutputStream 等-提供将基础数据类型写入到文件中,或者读取出来.
4.一维数组和二维数组的定义方式
题目
下面哪几个语句正确的声明一个整型的二维数组() CD
int a[][]=new int[][]
int b[10][10]=new int[][]
int c[][]=new int[10][10]
int []d[]=new int[10][10]
知识点
/**
* 一维数组的三种定义方法
* 动态初始化
* 1.数组类型[] 数组名=new 数组类型[数组长度];
* 静态初始化省略写法
* 2.数组类型[] 数组名={数组0,数组1,数组2,数组3,....};
* 静态初始化
* 3.数组类型[] 数组名=new 数组类型[]{数组0,数组1,数组2,...};
*/
//动态初始化
int[] arr1 = new int[3];
//静态初始化省略写法
int[] arr2 = {1,2,3};
//静态初始化
int[] arr3 = new int[]{1,2,3};
/**
* N维数组的定义方式同上 但是左边的数组名可以在多个[]位置
*/
//int[][] arr4 = new int[3][];//只有一维数组的长度必须声明
int[][] arr4 = new int[3][4];
int arr5[][] = {{1,2,3},{4,5,6}};
int []arr6[] = new int[][]{
{1,2,3},{4,5,6},{7,8,9,10}
};
5.Socket套接字通信编程
题目
关于 Socket 通信编程,以下描述正确的是:(C )
客户端通过new ServerSocket()创建TCP连接对象
客户端通过TCP连接对象调用accept()方法创建通信的Socket对象
客户端通过new Socket()方法创建通信的Socket对象
服务器端通过new ServerSocket()创建通信的Socket对象
解析
客户端通过new Socket()方法创建通信的Socket对象
服务器端通过new ServerSocket()创建TCP连接对象 accept接纳客户端请求,换言之,
Server端通过new ServerSocket()创建ServerSocket对象,ServerSocket对象的accept()方法产生阻塞,阻塞直到捕捉到一个来自Client端的请求。当Server端捕捉到一个来自Client端的请求时,会创建一个Socket对象,使用此Socket对象与Client端进行通信。
知识点
-
使用Socket套接字编程的基本流程
ServerSocket类
创建一个ServerSocket类,同时在运行该语句的计算机的指定端口处建立一个监听服务,如:
ServerSocket serverSocket =new ServerSocket(600);
这里指定提供监听服务的端口是600,一台计算机可以同时提供多个服务,这些不同的服务之间通过端口号来区别,不同的端口号上提供不同的服务。为了随时监听可能的Client端请求,执行如下的语句:
Socket socket = serverSocket.accept();
该语句调用了ServerSocket对象的accept()方法,这个方法的执行将使Server端的程序处于阻塞状态,程序将一直阻塞直到捕捉到一个来自Client端的请求,并返回一个用于与该Client端通信的Socket对象。此后Server程序只需要向这个Socket对象读写数据,就可以向远端的Client端读写数据。结束监听时,关闭ServerSocket
serverSocket.close();
Socket类
当Client端需要从Server端获取信息及其他服务时,应创建一个Socket对象:
`Socket socket = ``new` `Socket(“IP”,``600``);`Socket类的构造方法有两个参数,第一个参数是欲连接到的Server端所在计算机的IP地址(请注意,是IP,不是域名),第二个参数是该Server机上提供服务的端口号。
如果需要使用域名表示Server端所在计算机的地址:
`// 用此句代替IP地址,url为你的域名``InetAddress.getByName(``"url"``);`Socket对象建立成功之后,就可以在Client端和Server端之间建立一个连接,通过这个连接在两个端之间传递数据。利用Socket类的方法getInputStream()和getOutputStream()分别获得用于向Socket读写数据的输入/输出流。
当Server端和Client端的通信结束时,可以调用Socket类的close()方法关闭连接。
6.String类replace()&replaceAll()
题目
//打印结果
public static void main (String[] args) {
String classFile = "com.jd.". replaceAll(".", "/") + "MyClass.class";
System.out.println(classFile);
}
解析
String类中replace(待替换字符串,替换后的字符串),replaceAll(“匹配此字符串的正则表达式”,用来替换每个匹配项的字符串)
public static void main (String[] args) {
String classFile1 = "com.jd".replace(".", "/") + "/MyClass.class";
String classFile2 = "com.jd.". replaceAll(".", "/") + "MyClass.class";
System.out.println(classFile1);// com/jd/MyClass.class
System.out.println(classFile2);// ///MyClass.class
}
replaceAll()的应用
public class Test {
public static void main(String args[]) {
String Str = new String("www.google.com");
System.out.print("匹配成功返回值 :" );
System.out.println(Str.replaceAll("(.*)google(.*)", "runoob" ));
System.out.print("匹配失败返回值 :" );
System.out.println(Str.replaceAll("(.*)taobao(.*)", "runoob" ));
}
}
匹配成功返回值 :runoob
匹配失败返回值 :www.google.com
7.并发编程同步器
题目
JDK提供的用于并发编程的同步器有哪些?ABC
Semaphore
CyclicBarrier
CountDownLatch
Counter
解析
A,Java 并发库 的Semaphore 可以很轻松完成信号量控制,Semaphore可以控制某个资源可被同时访问的个数,通过 acquire() 获取一个许可,如果没有就等待,而 release() 释放一个许可。
B,CyclicBarrier 主要的方法就是一个:await()。await() 方法每被调用一次,计数便会减少1,并阻塞住当前线程。当计数减至0时,阻塞解除,所有在此 CyclicBarrier 上面阻塞的线程开始运行。
C,直译过来就是倒计数(CountDown)门闩(Latch)。倒计数不用说,门闩的意思顾名思义就是阻止前进。在这里就是指 CountDownLatch.await() 方法在倒计数为0之前会阻塞当前线程。
D,Counter不是并发编程的同步器,Counter计数器
同步器是一些使线程能够等待另一个线程的对象,允许它们协调动作。最常用的同步器是CountDownLatch和Semaphore,不常用的是Barrier 和Exchanger
8.HttpServletResponse方法
题目
下面HttpServletResponse方法调用,那些给客户端回应了一个定制的HTTP回应头:(AB )
response.setHeader("X-MyHeader", "34");
response.addHeader("X-MyHeader", "34");
response.setHeader(new HttpHeader("X-MyHeader", "34"));
response.addHeader(new HttpHeader("X-MyHeader", "34"));
response.addHeader(new ServletHeader("X-MyHeader", "34"));
response.setHeader(new ServletHeader("X-MyHeader", "34"));
解析
-
HttpServletResponse设置响应头的方法
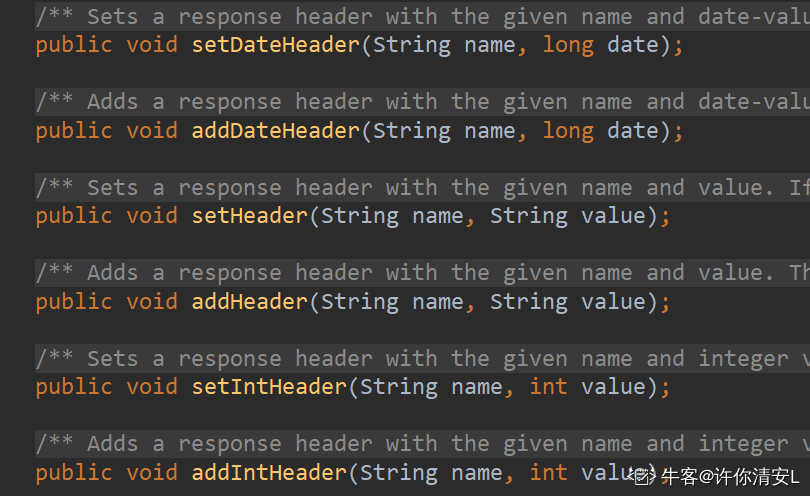
其中addHeader,如果同名header已存在,则追加至原同名header后面。
setHeader,如果同名header已存在,则覆盖一个同名header。
-
HttpServletResponse的作用
HttpServletResponse完成:设置http头标,设置cookie,设置返回数据类型,输出返回数据;
读取路径信息是HttpServletRequest做的
9.泛型通配符
题目
class A {}
class B extends A {}
class C extends A {}
class D extends B {}
下面的哪4个语句是正确的?(ACDG)
A.The type List<A>is assignable to List.
B.The type List<B>is assignable to List<A>.
C.The type List<Object>is assignable to List<?>.
D.The type List<D>is assignable to List<?extends B>.
E.The type List<?extends A>is assignable to List<A>.
F.The type List<Object>is assignable to any List reference.
G.The type List<?extends B>is assignable to List<?extends A>.
解析
public static void main(String[] args) {
List<A> a;
List list;
list = a; //A对,因为List就是List<?>,代表最大的范围,A只是其中的一个点,肯定被包含在内
List<B> b;
a = b; //B错,点之间不能相互赋值
List<?> qm;
List<Object> o;
qm = o; //C对,List<?>代表最大的范围,List<Object>只是一个点,肯定被包含在内
List<D> d;
List<? extends B> downB;
downB = d; //D对,List<? extends B>代表小于等于B的范围,List<D>是一个点,在其中
List<?extends A> downA;
a = downA; //E错,范围不能赋值给点
a = o; //F错,List<Object>只是一个点
downA = downB; //G对,小于等于A的范围包含小于等于B的范围,因为B本来就比A小,B时A的子类嘛
}
知识点
-
理解泛型通配符的使用必要性
java数组具有协变性,而java集合不是协变的;
什么意思呢?我举几个例子:
-
假设有一个函数 fun(Animal animal),如果我们传入一个Dog d 对象进去,编译器是不会报错的,这是多态的概念;
-
假设有一个函数 fun(Animal[] animals),如果我们传如一个Dog[] dogs数组进去,编译器也不会报错,这就是数组的协变性;
-
假设有一个函数 fun(List animal), 如果我们传如一个List dog 集合进去,编译器就会报错了,这就是集合泛型的不变性;
那么该怎么办呢?我们可以将泛型改成这样 fun (List <? extends Animal> ),这样之后,当我们再 传入一个List dog 集合进去,编译器就就不会报错了。也就是说可以传入包含Animal的子类的List了。
所以,存的时候需要上界通配符<? extends E>,取的时候需要下界通配符 <? super E>
上界通配符<= E 下界通配符>= E
-
10.编译期优化之字符串拼接
题目
//有如下一段代码,请选择其运行结果( true false)
public class StringDemo{
private static final String MESSAGE="taobao";
public static void main(String [] args) {
String a ="tao"+"bao";
String b="tao";
String c="bao";
System.out.println(a==MESSAGE);
System.out.println((b+c)==MESSAGE);
}
}
解析
这题是在考编译器的优化,Java虚拟机hotspot中 编译时"tao"+“bao"将直接变成"taobao”,b+c则不会优化,因为不知道在之前的步骤中bc会不会发生改变,而针对b+c则是用语法糖,新建一个StringBuilder来处理
总结:字符串拼接时只有当两个字面值的字符串(“tao” + “bao”)拼接后会被优化,其余但凡有一个字符串变量参与拼接(b + c/ b+”bao")都不会触发编译期优化
2022.3.10
1.Math类中取整方法
题目
Math.round(11.5) 等于多少 (). Math.round(-11.5) 等于多少 (-12 11 ).
解析
Math类中提供了三个与取整有关的方法:ceil,floor,round,这些方法的作用于它们的英文名称的含义相对应,例如:ceil的英文意义是天花板,该方法就表示向上取整,Math.ceil(11.3)的结果为12,Math.ceil(-11.6)的结果为-11;floor的英文是地板,该方法就表示向下取整,Math.floor(11.6)的结果是11,Math.floor(-11.4)的结果-12;最难掌握的是round方法,他表示“四舍五入”,算法为**Math.floor(x+0.5),**即将原来的数字加上0.5后再向下取整,所以,Math.round(11.5)的结果是12,Math.round(-11.5)的结果为-11.
2.坑点1:boolean/Boolean类型标记作为判断条件
题目
运行代码,结果正确的是:
Boolean flag = false;
if(flag = true){
System.out.println("true");
}else{
System.out.println("false");
}
解析
这里使用flag = true相当于是一个赋值语句,如果需要使用flag起到判断的作用需要使用双等号==
3.volatile关键字和锁的理解以及volatile和synchronized区别
题目
关于volatile关键字,下列描述不正确的是? BD
用volatile修饰的变量,每次更新对其他线程都是立即可见的。
对volatile变量的操作是原子性的。
对volatile变量的操作不会造成阻塞。
不依赖其他锁机制,多线程环境下的计数器可用volatile实现。
知识点
http://www.ibm.com/developerworks/cn/Java/j-jtp06197.html
-
锁的认知
锁提供了两种主要特性:互斥(mutual exclusion) 和可见性(visibility)。互斥即一次只允许一个线程持有某个特定的锁,因此可使用该特性实现对共享数据的协调访问协议,这样,一次就只有一个线程能够使用该共享数据。可见性要更加复杂一些,它必须确保释放锁之前对共享数据做出的更改对于随后获得该锁的另一个线程是可见的** —— 如果没有同步机制提供的这种可见性保证,线程看到的共享变量可能是修改前的值或不一致的值,这将引发许多严重问题。
-
volatile变量
Volatile 变量具有 synchronized 的可见性特性,但是不具备原子特性。这就是说线程能够自动发现 volatile 变量的最新值。Volatile 变量可用于提供线程安全,但是只能应用于非常有限的一组用例:多个变量之间或者某个变量的当前值与修改后值之间没有约束。因此,单独使用 volatile 还不足以实现计数器、互斥锁或任何具有与多个变量相关的不变式(Invariants)的类(例如 “start <=end”)。
出于简易性或可伸缩性的考虑,您可能倾向于使用 volatile 变量而不是锁。当使用 volatile 变量而非锁时,某些习惯用法(idiom)更加易于编码和阅读。此外,volatile 变量不会像锁那样造成线程阻塞,因此也很少造成可伸缩性问题。在某些情况下,如果读操作远远大于写操作,volatile 变量还可以提供优于锁的性能优势。
-
使用volatile提供线程安全的条件
- 对变量的写操作不依赖于当前值。(这个条件限制了volatile 变量不能用作线程安全计数器。虽然增量操作(x++)看上去类似一个单独操作,实际上它是一个由读取-修改-写入操作序列组成的组合操作,必须以原子方式执行,而 volatile 不能提供必须的原子特性。)
- 该变量没有包含在具有其他变量的不变式中。
-
volatile可见性和有序性的释义
volatile用与修饰实例变量和类变量,是一种维护线程安全的手段,作用是实现共享资源的可见性
可见性的意思:
进程中的内存分为工作内存(线程内存)和主内存,普通变量的读写依赖于当前工作内存,直到线程结束,才会把值更新到主内存,
当有多线程存在时,就无法保证数据的真实性(可见性),其他线程读到的数据可能旧的.
volatile修饰的变量每次获取的值都是从主内存中直接读的,写完之后也会直接更新到主内存,实现方式以**机器指令(硬编码)**的方式实现
jkd之后的版本在设计线程安全上都是基于volition和显示锁的方式,很少有用同步块和同步方法的方式,因为同步块方法的来讲,线程以串行的方式经过,效率太低.容易阻塞,而且保持原子性,只要线程进去就无法被打断,而volatile不会阻塞.不保证原子性.
有序性的意思:
jvm和处理器在编译Java代码的时候,出于性能考虑,会对原有的代码进行重排序,(也就是指令重排)我们写好的代码都有顺序,在我们执行的时候由JVM内存模型里的程序计数器标记的,保证线程安全的时候,一般都会禁止指令重排即保证有序性.说是并发环境下指令重排会有很多问题.
但是volatile和synchronized的有序是不同的:
volatile关键字禁止JVM编译器以及处理器对其进行重排序,
synchronized保证顺序性是串行化的结果,但同步块里的语句是会发生指令从排。
-
volatile vs sychnized
①使用上区别:
volatile关键字只能用来修饰实例变量或者类变量,不能修饰方法已及方法参数和局部变量和常量。
synchronized关键字不能用来修饰变量,只能用于修饰方法和语句块。
volatile修饰的变量可以为空,同步块的monitor不能为空。
②对原子性的保证
volatile无法保证原子性
synchronizde能够保证。因为无法被中途打断。
③对可见性的保证
都可以实现共享资源的可见性,但是实现的机制不同,synchronized借助于JVM指令monitor enter 和monitor exit ,通过排他的机制使线程串行通过同步块,在monitor退出后所共享的内存会被刷新到主内存中。volatile使用机器指令(硬编码)的方式,“lock”迫使其他线程工作内存中的数据失效,不得不主内存继续加载。④对有序性的保证
volatile关键字禁止JVM编译器已及处理器对其进行重排序,能够保证有序性。
synchronized保证顺序性是串行化的结果,但同步块里的语句是会发生指令从排。
⑤其他-线程阻塞:
volatile不会使线程陷入阻塞
synchronized会会使线程进入阻塞。
4.正则表达式
题目
正则表达式中,表示匹配非数字字符的字符是(D)
\b
\d
\B
\D
解析
A-匹配一个单词边界,也就是指单词和空格间的位置(即正则表达式的“匹配”有两种概念,一种是匹配字符,一种是匹配位置,这里的\b就是匹配位置的)。例如,“er\b”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”。
B-匹配数字字符
C-匹配非单词边界。“er\B”能匹配“verb”中的“er”,但不能匹配“never”中的“er”。
D-匹配非数字字符
知识点
- 正则表达式定义规则
| 元字符 | 描述 |
|---|---|
| \ | 将下一个字符标记符、或一个向后引用、或一个八进制转义符。例如,“\n”匹配\n。“\n”匹配换行符。序列“\”匹配“\”而“(”则匹配“(”。即相当于多种编程语言中都有的“转义字符”的概念。 |
| ^ | 匹配输入字符串的开始位置。如果设置了RegExp对象的Multiline属性,^也匹配“\n”或“\r”之后的位置。 |
| $ | 匹配输入字符串的结束位置。如果设置了RegExp对象的Multiline属性,$也匹配“\n”或“\r”之前的位置。 |
| * | 匹配前面的子表达式任意次。例如,zo*能匹配“z”,也能匹配“zo”以及“zoo”。*等价于o{0,} |
| + | 匹配前面的子表达式一次或多次(大于等于1次)。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,“do(es)?”可以匹配“do”或“does”中的“do”。?等价于{0,1}。 |
| {n} | n是一个非负整数。匹配确定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个o。 |
| {n,} | n是一个非负整数。至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o。“o{1,}”等价于“o+”。“o{0,}”则等价于“o*”。 |
| {n,m} | m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。例如,“o{1,3}”将匹配“fooooood”中的前三个o为一组,后三个o为一组。“o{0,1}”等价于“o?”。请注意在逗号和两个数之间不能有空格。 |
| ? | 当该字符紧跟在任何一个其他限制符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串“oooo”,“o+”将尽可能多的匹配“o”,得到结果[“oooo”],而“o+?”将尽可能少的匹配“o”,得到结果 [‘o’, ‘o’, ‘o’, ‘o’] |
| .点 | 匹配除“\r\n”之外的任何单个字符。要匹配包括“\r\n”在内的任何字符,请使用像“[\s\S]”的模式。 |
| (pattern) | 匹配pattern并获取这一匹配。所获取的匹配可以从产生的Matches集合得到,在VBScript中使用SubMatches集合,在JScript中则使用$0…$9属性。要匹配圆括号字符,请使用“(”或“)”。 |
| (?:pattern) | 非获取匹配,匹配pattern但不获取匹配结果,不进行存储供以后使用。这在使用或字符“(|)”来组合一个模式的各个部分时很有用。例如“industr(?:y|ies)”就是一个比“industry|industries”更简略的表达式。 |
| (?=pattern) | 非获取匹配,正向肯定预查,在任何匹配pattern的字符串开始处匹配查找字符串,该匹配不需要获取供以后使用。例如,“Windows(?=95|98|NT|2000)”能匹配“Windows2000”中的“Windows”,但不能匹配“Windows3.1”中的“Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
| (?!pattern) | 非获取匹配,正向否定预查,在任何不匹配pattern的字符串开始处匹配查找字符串,该匹配不需要获取供以后使用。例如“Windows(?!95|98|NT|2000)”能匹配“Windows3.1”中的“Windows”,但不能匹配“Windows2000”中的“Windows”。 |
| (?<=pattern) | 非获取匹配,反向肯定预查,与正向肯定预查类似,只是方向相反。例如,“(?<=95|98|NT|2000)Windows”能匹配“2000Windows”中的“Windows”,但不能匹配“3.1Windows”中的“Windows”。 |
| (?<!pattern) | 非获取匹配,反向否定预查,与正向否定预查类似,只是方向相反。例如“(?<!95|98|NT|2000)Windows”能匹配“3.1Windows”中的“Windows”,但不能匹配“2000Windows”中的“Windows”。这个地方不正确,有问题此处用或任意一项都不能超过2位,如“(?<!95|98|NT|20)Windows正确,“(?<!95|980|NT|20)Windows 报错,若是单独使用则无限制,如(?<!2000)Windows 正确匹配 |
| x|y | 匹配x或y。例如,“z|food”能匹配“z”或“food”(此处请谨慎)。“[zf]ood”则匹配“zood”或“food”。 |
| [xyz] | 字符集合。匹配所包含的任意一个字符。例如,“[abc]”可以匹配“plain”中的“a”。 |
| [^xyz] | 负值字符集合。匹配未包含的任意字符。例如,“[^abc]”可以匹配“plain”中的“plin”。 |
| [a-z] | 字符范围。匹配指定范围内的任意字符。例如,“[a-z]”可以匹配“a”到“z”范围内的任意小写字母字符。注意:只有连字符在字符组内部时,并且出现在两个字符之间时,才能表示字符的范围; 如果出字符组的开头,则只能表示连字符本身. |
| [^a-z] | 负值字符范围。匹配任何不在指定范围内的任意字符。例如,“[^a-z]”可以匹配任何不在“a”到“z”范围内的任意字符。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置(即正则表达式的“匹配”有两种概念,一种是匹配字符,一种是匹配位置,这里的\b就是匹配位置的)。例如,“er\b”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”。 |
| \B | 匹配非单词边界。“er\B”能匹配“verb”中的“er”,但不能匹配“never”中的“er”。 |
| \cx | 匹配由x指明的控制字符。例如,\cM匹配一个Control-M或回车符。x的值必须为A-Z或a-z之一。否则,将c视为一个原义的“c”字符。 |
| \d | 匹配一个数字字符。等价于[0-9]。grep 要加上-P,perl正则支持 |
| \D | 匹配一个非数字字符。等价于[^0-9]。grep要加上-P,perl正则支持 |
| \f | 匹配一个换页符。等价于\x0c和\cL。 |
| \n | 匹配一个换行符。等价于\x0a和\cJ。 |
| \r | 匹配一个回车符。等价于\x0d和\cM。 |
| \s | 匹配任何不可见字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。 |
| \S | 匹配任何可见字符。等价于[^ \f\n\r\t\v]。 |
| \t | 匹配一个制表符。等价于\x09和\cI。 |
| \v | 匹配一个垂直制表符。等价于\x0b和\cK。 |
| \w | 匹配包括下划线的任何单词字符。类似但不等价于“[A-Za-z0-9_]”,这里的"单词"字符使用Unicode字符集。 |
| \W | 匹配任何非单词字符。等价于“[^A-Za-z0-9_]”。 |
-
样例
-
身份证正则
A选项:isIDCard=/^[1-9]\d{7}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{3}$/ C选项:isIDCard=/^[1-9]\d{5}[1-9]\d{3}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{4}$/ 有以Y结尾的18位可以使用如下正则 isIDCard=/^[1-9]\d{5}[1-9]\d{3}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{3}(\d|X)$/; ^:起始符号,^x表示以x开头 $:结束符号,x$表示以x结尾 [n-m]:表示从n到m的数字 \d:表示数字,等同于[0-9] X{m}:表示由m个X字符构成,\d{4}表示4位数字 15位身份证的构成:六位出生地区码+六位出身日期码+三位顺序码 18位身份证的构成:六位出生地区码+八位出生日期码+三位顺序码+一位校验码 C选项的构成: [1-9]\d{5}:六位出生地区码,出生地区码没有以0开头,因此第一位为[1-9]。 [1-9]\d{3}:八位出生日期码的四位年份,同样年份没有以0开头。 ((0\d)|(1[0-2])):八位出生日期码的两位月份,| 表示或者,月份的形式为0\d或者是10、11、12。 (([0|1|2]\d)|3[0-1]):八位出生日期码的两位日期,日期由01至31。 \d{4}:三位顺序码+一位校验码,共四位。 A选项的构成: [1-9]\d{7}:六位出生地区码+两位出生日期码的年份,这里的年份指后两位,因此没有第一位不能为0的限制,所以合并了。
-
5.数据库MySQL索引之组合索引
题目
mysql数据库,game_order表表结构如下,下面哪些sql能使用到索引(BCDE)?

select * from game_order where plat_game_id=5 and plat_id=134
select * from game_order where plat_id=134 and
plat_game_id=5 and plat_order_id=’100’
select * from game_order where plat_order_id=’100’
select * from game_order where plat_game_id=5 and
plat_order_id=’100’ and plat_id=134
select * from game_order where plat_game_id=5 and plat_order_id=’100’
解析
这道题目想考察的知识点是MySQL组合索引(复合索引)的最左优先原则。最左优先就是说组合索引的第一个字段必须出现在查询组句中,这个索引才会被用到。只要组合索引最左边第一个字段出现在Where中,那么不管后面的字段出现与否或者出现顺序如何,MySQL引擎都会自动调用索引来优化查询效率。
根据最左匹配原则可以知道B-Tree建立索引的过程,比如假设有一个3列索引(col1,col2,col3),那么MySQL只会会建立三个索引(col1),(col1,col2),(col1,col2,col3)。
所以题目会创建三个索引(plat_order_id)、(plat_order_id与plat_game_id的组合索引)、(plat_order_id、plat_game_id与plat_id的组合索引)。根据最左匹配原则,where语句必须要有plat_order_id才能调用索引(如果没有plat_order_id字段那么一个索引也调用不到),如果同时出现plat_order_id与plat_game_id则会调用两者的组合索引,如果同时出现三者则调用三者的组合索引。
题目问有哪些sql能使用到索引,个人认为只要Where后出现了plat_order_id字段的SQL语句都会调用到索引,只不过是所调用的索引不同而已,所以选BCDE。如果题目说清楚是调用到三个字段的复合索引,那答案才是BD。
通俗来讲组合索引的使用必须满足:带头大哥不能死,中间兄弟不能断。解释: 不能断的意思是:一个3列索引(col1,col2,col3),那么MySQL只会会建立三个索引(col1),(col1,col2),(col1,col2,col3)。但是不可以是(col1,col3)这样子断开的 。带头大哥不能死就是说col1不能少
知识点
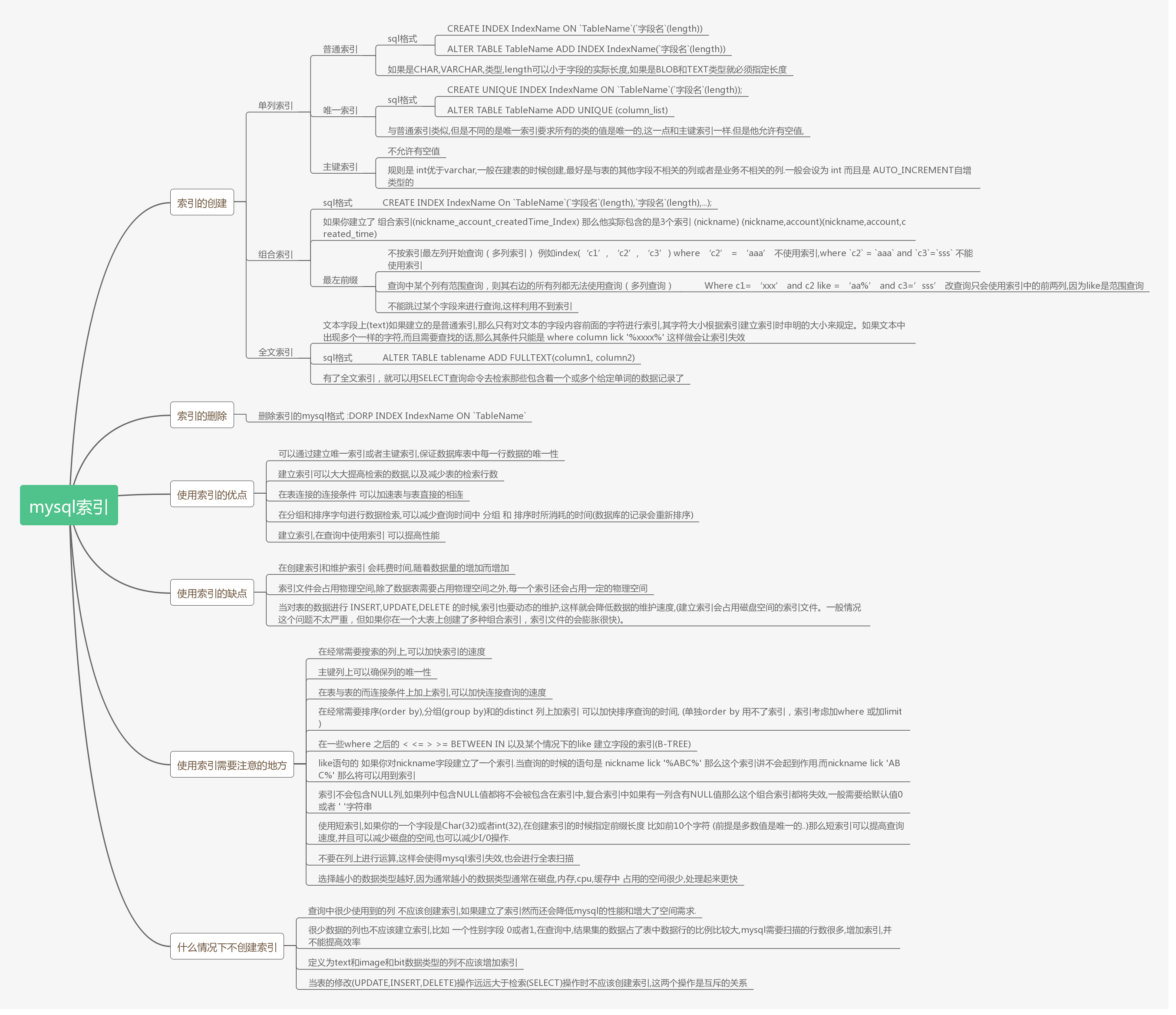
- mysql中索引相关的思维导图
2022.3.11
1.并发包java.util.concurrent的类-线程
题目
当我们需要所有线程都执行到某一处,才进行后面的的代码执行我们可以使用? B
CountDownLatch
CyclicBarrier
Semaphore
Future
解析
CountDownLatch: A synchronization aid that allows one or more threads to wait until a set of operations being performed in other threads completes.
CyclicBarrier : A synchronization aid that allows a set of threads to all wait for each other to reach a common barrier point.
从javadoc的描述可以得出: CountDownLatch:一个或者多个线程,等待其他多个线程完成某件事情之后才能执行; CyclicBarrier(栅栏):多个线程互相等待,直到到达同一个同步点,再继续一起执行。 对于CountDownLatch来说,重点是“一个线程(多个线程)等待”,而其他的N个线程在完成“某件事情”之后,可以终止,也可以等待。 而对于CyclicBarrier,重点是多个线程,在任意一个线程没有完成,所有的线程都必须互相等待,然后继续一起执行。 CountDownLatch是计数器,线程完成一个记录一个,只不过计数不是递增而是递减,而CyclicBarrier更像是一个阀门,需要所有线程都到达,阀门才能打开,然后继续执行。 按照这个题目的描述等所有线程都到达了这一个阀门处,再一起执行,此题强调的是,一起继续执行,B 比较合理!
A.CountDownLatch 是等待一组线程执行完,才执行后面的代码。此时这组线程已经执行完。
B.CyclicBarrier 是等待一组线程至某个状态后再同时全部继续执行线程。此时这组线程还未执行完。C.Semaphore 通常我们叫它信号量, 可以用来控制同时访问特定资源的线程数量,通过协调各个线程,以保证合理的使用资源。
D.future表示一个可能还没有完成的异步任务的结果,针对这个结果可以添加Callback以便在任务执行成功或失败后作出相应的操作。创建Tread类如果有返回值需求的话可以创造一个Future使用Thread的有参构造创建一个Tread实例
2.Switch表达式支持的类型
题目
下面的switch语句中,x可以是哪些类型的数据:()
switch(x)
{
default:
System.out.println("Hello");
}
long
char
float
byte
double
Object
知识点
jdk 1.7之前,switch只能支持 byte、short、char、int或者其对应的封装类以及Enum类型。
jdk 1.7及之后,也支持了String类型
深入理解支持类型的本质
实际只支持int类型– Java实际只能支持int类型的switch语句,那其他的类型时如何支持的
a、基本类型byte char short 原因:这些基本数字类型可自动向上转为int, 实际还是用的int。
b、基本类型包装类Byte,Short,Character,Integer 原因:java的自动拆箱机制 可看这些对象自动转为基本类型
c、String 类型 原因:实际switch比较的string.hashCode值,它是一个int类型 如何实现的,网上例子很多。此处不表。
d、enum类型 原因 :实际比较的是enum的ordinal值(表示枚举值的顺序),它也是一个int类型 所以也可以说 switch语句只支持int类型
3.集合Collection接口常用方法
题目
Java的集合框架中重要的接口java.util.Collection定义了许多方法。选项中哪个方法是Collection接口所定义的( ABD )
int size()
boolean containsAll(Collection c)
compareTo(Object obj)
boolean remove(Object obj)
解析
compareTo(Object obj)–C选项,compareTo是String类的方法,按字典顺序比较两个字符串大小,返回值是int,时常出现在一些类构造器中,如TreeMap
知识点
Collection 接口常用的方法
-
size():返回集合中元素的个数
-
add(Object obj):向集合中添加一个元素
-
addAll(Colletion coll):将形参coll包含的所有元素添加到当前集合中
-
isEmpty():判断这个集合是否为空
-
clear():清空集合元素
-
contains(Object obj):判断集合中是否包含指定的obj元素
① 判断的依据:根据元素所在类的equals()方法进行判断
②明确:如果存入集合中的元素是自定义的类对象,要去:自定义类要重写equals()方法 -
constainsAll(Collection coll):判断当前集合中是否包含coll的所有元素
-
rentainAll(Collection coll):求当前集合与coll的共有集合,返回给当前集合
-
remove(Object obj):删除集合中obj元素,若删除成功,返回ture否则
-
removeAll(Collection coll):从当前集合中删除包含coll的元素
-
equals(Object obj):判断集合中的所有元素 是否相同
-
hashCode():返回集合的哈希值
-
toArray(T[] a):将集合转化为数组
①如有参数,返回数组的运行时类型与指定数组的运行时类型相同。 -
iterator():返回一个Iterator接口实现类的对象,进而实现集合的遍历。
此外,数组转换为集合:Arrays.asList(数组)
4.Servlet过滤器的使用配置
题目
在J2EE中,使用Servlet过滤器,需要在web.xml中配置(AB)元素
<filter>
<filter-mapping>
<servlet-filter>
<filter-config>
解析
Servlet过滤器的配置包括两部分:
第一部分是过滤器在Web应用中的定义,由元素表示,包括**和两个必需的子元素**
第二部分是过滤器映射的定义,由元素表示,可以将一个过滤器映射到一个或者多个Servlet或JSP文件,也可以采用url-pattern将过滤器映射到任意特征的URL。

2022.3.12
1.存根类Stub
题目
存根(Stub)与以下哪种技术有关(B)
交换
动态链接
动态加载
磁盘调度
知识点
-
存根类
-
存根类是一个类,它实现了一个接口,它的作用是:如果一个接口有很多方法,如果要实现这个接口,就要实现所有的方法。但是一个类从业务来说,可能只需要其中一两个方法。如果直接去实现这个接口,除了实现所需的方法,还要实现其他所有的无关方法。而如果通过继承存根类实现接口,就免去了这种麻烦。
-
RMI 采用stubs 和 skeletons 来进行远程对象(remote object)的通讯。stub 充当远程对象的客户端代理,有着和远程对象相同的远程接口,远程对象的调用实际是通过调用该对象的客户端代理对象stub来完成的。
-
每个远程对象都包含一个代理对象stub,当运行在本地Java虚拟机上的程序调用运行在远程Java虚拟机上的对象方法时,它首先在本地创建该对象的代理对象stub, 然后调用代理对象上匹配的方法。每一个远程对象同时也包含一个skeleton对象,skeleton运行在远程对象所在的虚拟机上,接受来自stub对象的调用。这种方式符合等到程序要运行时将目标文件动态链接的思想。
-
-
必要性
为屏蔽客户调用远程主机上的对象,必须提供某种方式来模拟本地对象,这种本地对象称为存根(stub),存根负责接收本地方法调用,并将它们委派给各自的具体实现对象
而本题答案为第二个:动态链接
动态连接使得大部分的连接过程延迟,直到程序开始运行。这种做法做提供了许多其它方法难以实现的优点:
● 动态连接库比静态连接库更容易创建。
● 动态连接库比静态连接库更容易更新。
● 动态连接库的和非共享库的语义非常的接近。(这里语义指什么)
● 动态连接库容许程序在运行时装载和卸载例程,这是其它方式很难提供的一个功能。
2.拉姆达表达式
题目
下面哪些写法能在 java8 中编译执行(AD)
dir.listFiles((File f)->f.getName().endsWith(“.Java”));
dir.listFiles((File f)=>f.getName().endsWith(“.Java”));
dir.listFiles((_.getName().endsWith(“.Java”)));
dir.listFiles( f->f.getName().endsWith(“.Java”));
知识点
-
作用与使用规范
Lanbda表达式的主要作用就是代替匿名内部类的繁琐语法, 它由三部分组成:
(1) 形参列表。形参列表允许省略形参类型。如果形参列表中只有一个参数,甚至连形参列表的圆括号也可以省略。
(2) 箭头(->)。必须通过英文中画线和大于符号组成。
(3)**代码块。如果代码块只包含一条语句,Lambda表达式允许省略代码块的花括号,那么那条语句就不要用花括号表示语句结束。**Lambda代码块只有一条return语句,甚至可以省略return关键字。Lambda表达式需要返回值,而它的代码块中仅有一套省略了return的语句。Lambda表达式会自动返回这条语句的值。
3.会话跟踪
题目
下面哪项技术可以用在WEB开发中实现会话跟踪实现?(全部)
session
Cookie
地址重写
隐藏域
知识点
会话跟踪是一种灵活、轻便的机制,它使Web上的状态编程变为可能。
HTTP是一种无状态协议,每当用户发出请求时,服务器就会做出响应,客户端与服务器之间的联系是离散的、非连续的。当用户在同一网站的多个页面之间转换时,根本无法确定是否是同一个客户,会话跟踪技术就可以解决这个问题。当一个客户在多个页面间切换时,服务器会保存该用户的信息。
有四种方法可以实现会话跟踪技术:URL重写、隐藏表单域、Cookie、Session。
1).隐藏表单域:,非常适合步需要大量数据存储的会话应用。
2).URL 重写:URL 可以在后面附加参数,和服务器的请求一起发送,这些参数为名字/值对。
3).Cookie:一个 Cookie 是一个小的,已命名数据元素。服务器使用 SET-Cookie 头标将它作为 HTTP
响应的一部分传送到客户端,客户端被请求保存 Cookie 值,在对同一服务器的后续请求使用一个
Cookie 头标将之返回到服务器。与其它技术比较,Cookie 的一个优点是在浏览器会话结束后,甚至
在客户端计算机重启后它仍可以保留其值
4).Session:使用 setAttribute(String str,Object obj)方法将对象捆绑到一个会话
4.运行时常量池 Vs 字符串常量池
题目
关于运行时常量池,下列哪个说法是正确的 BCD
运行时常量池大小受栈区大小的影响
运行时常量池大小受方法区大小的影响
存放了编译时期生成的各种字面量
存放编译时期生成的符号引用
解析
为了避免歧义,以下提及的JVM,是Hotspot
方法区是什么?
方法区是广义上的概念,是一个定义、标准,可以理解为Java中的接口,在Jdk6、7方法区的实现叫永久代;Jdk8之后方法区的实现叫元空间,并从JVM内存中移除,放到了直接内存中;
方法区是被所有方法线程共享的一块内存区域.
运行时常量池是什么?
运行时常量池是每一个类或接口的常量池的运行时表示形式.
具体体现就是在Java编译后生成的.class文件中,会有class常量池,也就是静态的运行时常量池;
运行时常量池存放的位置?
运行时常量池一直是方法区的一部分,在不同版本的JDK中,由于方法区位置的变化,运行时常量池所处的位置也不一样.JDK1.7及之前方法区位于永久代.由于一些原因在JDK1.8之后彻底祛除了永久代,用元空间代替。
运行时常量池存放什么?
存放编译期生成的各种字面量和符号引用(以一组符号来描述所引用的目标。符号引用可以是任何形式的字面量,只要使用时能无歧义地定位到目标即可。);
运行时常量池中包含多种不同的常量,包括编译期就已经明确的数值字面量,也包括到运行期解析后才能够获得的方法或者字段引用。 此时不再是常量池中的符号地址了,这里换为真实地址。
运行时常量池与字符串常量池?(可能有同学把他俩搞混)
字符串常量池:在JVM中,为了减少相同的字符串的重复创建,为了达到节省内存的目的。会单独开辟一块内存,用于保存字符串常量,这个内存区域被叫做字符串常量池.
字符串常量池位置?
JDK1.6时字符串常量池,被存放在方法区中(永久代),而到了JDK1.7,因为永久代垃圾回收频率低;而字符串使用频率比较高,不能及时回收字符串,会导致导致永久代内存不足,就被移动到了堆内存中。
5.异常的继承体系
知识点
-
继承体系
-
说明
都是Throwable的子类:
**1.Exception(异常):**是程序本身可以处理的异常。
2.Error(错误): 是程序无法处理的错误。这些错误表示故障发生于虚拟机自身、或者发生在虚拟机试图执行应用时,一般不需要程序处理。
3.检查异常(编译器要求必须处置的异常) : 除了Error,RuntimeException及其子类以外,其他的Exception类及其子类都属于可查异常。这种异常的特点是Java编译器会检查它,也就是说,当程序中可能出现这类异常,要么用try-catch语句捕获它,要么用throws子句声明抛出它,否则编译不会通过。
4.非检查异常(编译器不要求处置的异常): 包括运行时异常(RuntimeException与其子类)和错误(Error)。
6.同一个java文件public的类唯一且私有化的成员属性外部不能直接访问
题目
以下代码运行输出的是 编译出错
public class Person{
private String name = "Person";
int age=0;
}
public class Child extends Person{
public String grade;
public static void main(String[] args){
Person p = new Child();
System.out.println(p.name);
}
}
解析
①首先一个java文件中只能有一个public修饰的类
②其次私有化的成员变量,外部不能直接.获取,而只能通过public的get方法获取
7.throws和throw的区别
知识点
①使用的位置:throws用在方法声明后面,跟的是异常类名;throw用在方法体内,跟的是异常对象名
②throws后面可以跟多个异常类名,之间用逗号隔开,throw只能抛出一个异常对象名
③含义|处理对象:throws表示抛出异常,由该方法的调用者来处理;throw表示抛出异常,由方法体内的语句处理
④可能性:throws表示异常出现的一种可能性,并不一定会发生这种异常;throw则是抛出异常,执行throw一定是抛出了某种异常
8.final、finally和finalize区别
- 关键字final 修饰类,不能被继承;修饰方法,方法不能被重写;修饰变量,变为常量
- 关键字finally 用于异常处理语句中,一般用来做善后工作,不管是否捕获到异常都会被执行。
- 方法finalize() 是Object类中的方法,回收垃圾用
2022.3.14
1.设计模式
题目
Java数据库连接库JDBC用到哪种设计模式?(桥接模式)
生成器
桥接模式
抽象工厂
单例模式
知识点
-
桥接模式:
定义 :将抽象部分与它的实现部分分离,使它们都可以独立地变化。
意图 :将抽象与实现解耦。
桥接模式所涉及的角色
1. Abstraction :定义抽象接口,拥有一个Implementor类型的对象引用
2. RefinedAbstraction :扩展Abstraction中的接口定义
3. Implementor :是具体实现的接口,Implementor和RefinedAbstraction接口并不一定完全一致,实际上这两个接口可以完全不一样Implementor提供具体操作方法,而Abstraction提供更高层次的调用
4. ConcreteImplementor :实现Implementor接口,给出具体实现Jdk中的桥接模式:JDBC
JDBC连接 数据库的时候,在各个数据库之间进行切换,基本不需要动太多的代码,甚至丝毫不动,原因就是JDBC提供了统一接口,每个数据库提供各自的实现,用一个叫做数据库驱动的程序来桥接就行了总结-JDBC提供两套接口,一个面向数据库厂商,一个面向JDBC使用者。
2022.3.15
1.类加载过程
题目
以下哪项不属于java类加载过程?B
生成java.lang.Class对象
int类型对象成员变量赋予默认值
执行static块代码
类方法解析
解析
类的加载包括:加载,验证,准备,解析,初始化。
选项A:生成java.lang.Class对象是在加载时进行的。生成Class对象作为方法区这个类的各种数据的访问入口。
选项B:既然是对象成员,那么肯定在实例化对象后才有。在类加载的时候会赋予初值的是类变量,而非对象成员。
选项C:这个会调用。可以用反射试验。
选项D:类方法解析发生在解析过程。
2.数组复制方法效率对比
题目
java语言的下面几种数组复制方法中,哪个效率最高?
for 循环逐一复制
System.arraycopy
Array.copyOf
使用clone方法
解析
- System.arraycopy():native方法+JVM手写函数,在JVM里预写好速度最快
- clone():native方法,但并未手写,需要JNI转换,速度其次
- Arrays.copyof():本质是调用1的方法
- for():全是深复制,并且不是封装方法,最慢情有可原
https://blog.csdn.net/qq_34834846/article/details/97174521
3.JavaWeb中关联类
题目
JavaWEB中有一个类,当会话种绑定了属性或者删除了属性时,他会得到通知,这个类是:( A )
HttpSessionAttributeListener
HttpSessionBindingListener
HttpSessionObjectListener
HttpSessionListener;
HttpSession
HttpSessionActivationListener
解析
HttpSessionAttributeListener:可以实现此侦听器接口获取此web应用程序中会话属性列表更改的通知;
HttpSessionBindingListener:当该对象从一个会话中被绑定或者解绑时通知该对象,这个对象由HttpSessionBindingEvent对象通知。这可能是servlet程序显式地从会话中解绑定属性的结果,可能是由于会话无效,也可能是由于会话超时;
HttpSessionObjectListener:没有该接口API;
HttpSessionListener:当web应用程序中的活动会话列表发生更改时通知该接口的实现类,为了接收该通知事件,必须在web应用程序的部署描述符中配置实现类;
HttpSessionActivationListener:绑定到会话的对象可以侦听容器事件,通知它们会话将被钝化,会话将被激活。需要一个在虚拟机之间迁移会话或持久会话的容器来通知所有绑定到实现该接口会话的属性。
4.ArrayList扩容机制
题目
ArrayList list = new ArrayList(20);中的list扩充几次 0次
解析
Arraylist默认数组大小是10,扩容后的大小是扩容前的1.5倍,最大值小于Integer 的最大值减8,如果新创建的集合有带初始值,默认就是传入的大小,在添加元素数超限后会触发扩容
知识点
- ArrayList vs LinkedList扩容时间比较
ArrayList内部是动态数组实现,在增加空间时会复制全部数据到新的容量大一些的数组中。而LinkedList内部为双向链表,可以按需分配空间,扩展容量简单,因此LinkedList用时少。
5.类常见关系
题目
类之间存在以下几种常见的关系: ABC
“USES-A”关系
“HAS-A”关系
“IS-A”关系
“INHERIT-A”关系
解析
USES-A:依赖关系,A类会用到B类,这种关系具有偶然性,临时性。但B类的变化会影响A类。这种在代码中的体现为:A类方法中的参数包含了B类。
关联关系:A类会用到B类,这是一种强依赖关系,是长期的并非偶然。在代码中的表现为:A类的成员变量中含有B类。
HAS-A:聚合关系,拥有关系,是关联关系的一种特例,是整体和部分的关系。比如鸟群和鸟的关系是聚合关系,鸟群中每个部分都是鸟。
**IS-A:**表示继承。父类与子类,这个就不解释了。
要注意:还有一种关系:组合关系也是关联关系的一种特例,它体现一种contains-a的关系,这种关系比聚合更强,也称为强聚合。它同样体现整体与部分的关系,但这种整体和部分是不可分割的。
总结:常见关系-是(is)有(has)用(uses)的 以及contains-a
6.请求转发与重定向forward&redirect
题目
下面有关forward和redirect的描述,正确的是(BCD) ?
forward是服务器将控制权转交给另外一个内部服务器对象,由新的对象来全权负责响应用户的请求
执行forward时,浏览器不知道服务器发送的内容是从何处来,浏览器地址栏中还是原来的地址
执行redirect时,服务器端告诉浏览器重新去请求地址
forward是内部重定向,redirect是外部重定向
redirect默认将产生301 Permanently moved的HTTP响应
解析
A中 服务器会直接访问目标地址的URL,不会把控制权转交
E中web服务器接受后发送302状态码响应及对应新的location给客户浏览器
知识点
-
区别
1.从地址栏显示来说
forward是服务器请求资源,服务器直接访问目标地址的URL,把那个URL的响应内容读取过来,然后把这些内容再发给浏览器.浏览器根本不知道服务器发送的内容从哪里来的,所以它的地址栏还是原来的地址.
redirect是服务端根据逻辑,发送一个状态码,告诉浏览器重新去请求那个地址.所以地址栏显示的是新的URL.
2.从数据共享来说
forward:转发页面和转发到的页面可以共享request里面的数据(请求转发是服务器行为,是request对象的行为).
redirect:不能共享数据(重定向重定向是客户端行为,是需要response将信息返回给浏览器).
3.从运用地方来说
forward:一般用于用户登陆的时候,根据角色转发到相应的模块.
redirect:一般用于用户注销登陆时返回主页面和跳转到其它的网站等.
4.从效率来说
forward:高.
redirect:低.
-
过程
转发过程:客户浏览器发送http请求----》web服务器接受此请求--》调用内部的一个方法在容器内部完成请求处理和转发动作----》将目标资源 发送给客户;在这里,转发的路径必须是同一个web容器下的url,其不能转向到其他的web路径上去,中间传递的是自己的容器内的request。在客户浏览器路径栏显示的仍然是其第一次访问的路径,也就是说客户是感觉不到服务器做了转发的。转发行为是浏览器只做了一次访问请求。 重定向过程:客户浏览器发送http请求----》web服务器接受后发送302状态码响应及对应新的location给客户浏览器--》客户浏览器发现 是302响应,则自动再发送一个新的http请求,请求url是新的location地址----》服务器根据此请求寻找资源并发送给客户。在这里 location可以重定向到任意URL,既然是浏览器重新发出了请求,则就没有什么request传递的概念了。在客户浏览器路径栏显示的是其重定向的 路径,客户可以观察到地址的变化的。重定向行为是浏览器做了至少两次的访问请求的。
7.ASCII码与ANSI码
题目
关于ASCII码和ANSI码,以下说法不正确的是(D)
标准ASCII只使用7个bit
在简体中文的Windows系统中,ANSI就是GB2312
ASCII码是ANSI码的子集
ASCII码都是可打印字符
解析
A、标准ASCII只使用7个bit,扩展的ASCII使用8个bit。
B、ANSI通常使用 0x00~0x7f 范围的1 个字节来表示 1 个英文字符。超出此范围的使用0x80~0xFFFF来编码,即扩展的ASCII编码。不同 ANSI 编码之间互不兼容。在简体中文Windows操作系统中,ANSI 编码代表 GB2312;在繁体中文Windows操作系统中,ANSI编码代表Big5;在日文Windows操作系统中,ANSI 编码代表 Shift_JIS 编码,英文Windows系统,那么ANSI码就是指ascii码
C、ANSI通常使用 0x00~0x7f 范围的1 个字节来表示 1 个英文字符,即ASCII码
D、ASCII码包含一些特殊空字符
2022.3.16
1.Spring中事务属性之传播特性
题目
下面有关SPRING的事务传播特性,说法错误的是?B
PROPAGATION_SUPPORTS:支持当前事务,如果当前没有事务,就以非事务方式执行
PROPAGATION_REQUIRED:支持当前事务,如果当前没有事务,就抛出异常
PROPAGATION_REQUIRES_NEW:新建事务,如果当前存在事务,把当前事务挂起
PROPAGATION_NESTED:支持当前事务,新增Savepoint点,与当前事务同步提交或回滚
知识点
事务属性的种类: 传播行为、隔离级别、只读和事务超时
a) 传播行为定义了被调用方法的事务边界。
| 传播行为 | 意义 |
|---|---|
| PROPERGATION_MANDATORY | 表示方法必须运行在一个事务中,如果当前事务不存在,就抛出异常 |
| PROPAGATION_NESTED | 表示如果当前事务存在,则方法应该运行在一个嵌套事务中。否则,它看起来和 PROPAGATION_REQUIRED 看起来没什么俩样 |
| PROPAGATION_NEVER | 表示方法不能运行在一个事务中,否则抛出异常 |
| PROPAGATION_NOT_SUPPORTED | 表示方法不能运行在一个事务中,如果当前存在一个事务,则该方法将被挂起 |
| PROPAGATION_REQUIRED | 表示当前方法必须运行在一个事务中,如果当前存在一个事务,那么该方法运行在这个事务中,否则,将创建一个新的事务 |
| PROPAGATION_REQUIRES_NEW | 表示当前方法必须运行在自己的事务中,如果当前存在一个事务,那么这个事务将在该方法运行期间被挂起 |
| PROPAGATION_SUPPORTS | 表示当前方法不需要运行在一个是事务中,但如果有一个事务已经存在,该方法也可以运行在这个事务中 |
b) 隔离级别
在操作数据时可能带来 3 个副作用,分别是脏读、不可重复读、幻读。为了避免这 3 中副作用的发生,在**标准的 SQL 语句中定义了 4 种隔离级别,分别是未提交读、已提交读、可重复读、可序列化。**而在 spring 事务中提供了 5 种隔离级别来对应在 SQL 中定义的 4 种隔离级别,如下:
| 隔离级别 | 意义 |
|---|---|
| ISOLATION_DEFAULT | 使用后端数据库默认的隔离级别 |
| ISOLATION_READ_UNCOMMITTED | 允许读取未提交的数据(对应未提交读),可能导致脏读、不可重复读、幻读 |
| ISOLATION_READ_COMMITTED | 允许在一个事务中读取另一个已经提交的事务中的数据(对应已提交读)。可以避免脏读,但是无法避免不可重复读和幻读 |
| ISOLATION_REPEATABLE_READ | 一个事务不可能更新由另一个事务修改但尚未提交(回滚)的数据(对应可重复读)。可以避免脏读和不可重复读,但无法避免幻读 |
| ISOLATION_SERIALIZABLE | 这种隔离级别是所有的事务都在一个执行队列中,依次顺序执行,而不是并行(对应可序列化)。可以避免脏读、不可重复读、幻读。但是这种隔离级别效率很低,因此,除非必须,否则不建议使用。 |
c) 只读
如果在一个事务中所有关于数据库的操作都是只读的,也就是说,这些操作只读取数据库中的数据,而并不更新数据,那么应将事务设为只读模式( READ_ONLY_MARKER ) , 这样更有利于数据库进行优化 。
因为只读的优化措施是事务启动后由数据库实施的,因此,只有将那些具有可能启动新事务的传播行为 (PROPAGATION_NESTED 、 PROPAGATION_REQUIRED 、 PROPAGATION_REQUIRED_NEW) 的方法的事务标记成只读才有意义。
如果使用 Hibernate 作为持久化机制,那么将事务标记为只读后,会将 Hibernate 的 flush 模式设置为 FULSH_NEVER, 以告诉 Hibernate 避免和数据库之间进行不必要的同步,并将所有更新延迟到事务结束。
d) 事务超时
如果一个事务长时间运行,这时为了尽量避免浪费系统资源,应为这个事务设置一个有效时间,使其等待数秒后自动回滚。与设置“只读”属性一样,事务有效属性也需要给那些具有可能启动新事物的传播行为的方法的事务标记成只读才有意义。
2.位运算符
题目
以下JAVA程序代码的输出是 13
public static void main(String args[]) {
System.out.println(14^3);
}
解析
考察位运算符 具体见知识点
知识点
//位运算符
/**
* 按位或|
* 按位且&
* 按位取反~
* 按位异或^
* ----------------------------------
* 逻辑与&&
* 逻辑或||
* 非!
* ----------------------------------
* 左移<<:低位补0,相当于乘以2
* 右移>>:补符号位,负整数高位补1,正整数高位补0,相当于除以2
* 无符号右移>>>:补0
*/
//14 -- 1110 3 -- 0011
System.out.println(14|3);//15 1111 按位或
System.out.println(14&3);//2 0010 按位与
System.out.println(~14);//-15 0001 按位取反
//补充 正数三码合一 底层以补码保存
// 负数的补码: 原码-(符号位1不变,其余位取反)>反码-(符号位不变最后一位+1)>补码
//举例: 这里 -1 原码 1000 0001 -> 1111 1110反码 -> 1111 1111补码 即-15是-1的补码
//这里 14的补码 01110 按位取反后得到补码 10001 转成反码 10000 转成原码 11111即-15
//System.out.println(~(-15));//1000 1111 - 1111 0000 - 1111 0001 按位取反 0000 1110即14
System.out.println(14^3);//13 1101 按位异或
System.out.println(8<<1);//0 1000 -> 1 0000 16
System.out.println(8>>1);//0 1000 -> 0 0100 4
System.out.println(-8<<1);//1000 1000 -> 1111 0111 ->1111 1000补码 ->
// 左移 1111 0000 -> 1110 1111 -> 1001 0000 -16
System.out.println(-8>>1);// -8补码 1111 1000 ->右移1111 1100 ->1111 1101 ->
//1000 0010 -4
3.垃圾回收(GC)
题目
以下哪项陈述是正确的? E (D不正确?)
垃圾回收线程的优先级很高,以保证不再使用的内存将被及时回收
垃圾收集允许程序开发者明确指定释放哪一个对象
垃圾回收机制保证了JAVA程序不会出现内存溢出
进入”Dead”状态的线程将被垃圾回收器回收
以上都不对
解析
A: 垃圾回收在jvm中优先级相当相当低。
B:垃圾收集器(GC)程序开发者只能推荐JVM进行回收,但何时回收,回收哪些,程序员不能控制。
C:垃圾回收机制只是回收不再使用的JVM内存,如果程序有严重BUG,照样内存溢出。
D:不正确???
知识点
- 真正宣布一个对象死亡,至少需要经历2次标记过程。当第一次标记时会同时进行一次筛选(判断此对象是否有必要执行finalize方法)。如果对象没有覆盖该方法,就面临死亡,所以说这个方法是对象逃脱死亡命运的最后一次机会。
- 当程序运行时,至少会有两个线程开启启动,一个是我们的主线程,一个是垃圾回收线程,垃圾回收线程的priority(优先级)较低
- 垃圾回收器会对我们使用的对象进行监视,当一个对象长时间不使用时,垃圾回收器会在空闲的时候(不定时)对对象进行回收,释放内存空间,程序员是不可以显示的调用垃圾回收器回收内存的,但是可以使用System.gc()方法建议垃圾回收器进行回收,但是垃圾回收器不一定会执行。
- Java的垃圾回收机制可以有效的防止内存溢出问题,但是它并不能完全保证不会出现内存溢出。例如当程序出现严重的问题时,也可能出现内存溢出问题。
4.类修饰符
知识点
- 普通类**(外部类):只能用public、default(不写)、abstract、final修饰**。
- (成员)内部类:可理解为外部类的成员,所以修饰类成员的public、protected、default、private、static等关键字都能使用。
- 局部内部类:出现在方法里的类,不能用上述关键词来修饰。
- 匿名内部类:给的是直接实现,类名都没有,没有修饰符。
2022.3.17
1.遍历集合时增删元素遇到的问题-并发修改异常or遍历不完全
题目
假设num已经被创建为一个ArrayList对象,并且最初包含以下整数值:[0,0,4,2,5,0,3,0]。 执行下面的方法numQuest(),最终的输出结果是什么?
private List<Integer> nums;
//precondition: nums.size() > 0
//nums contains Integer objects
public void numQuest() {
int k = 0;
Integer zero = new Integer(0);
while (k < nums.size()) {
if (nums.get(k).equals(zero))
nums.remove(k);
k++;
}
}
解析
答案是[0, 4, 2, 5, 3],而非[4,2,5,3]。举例如下
public static void main(String[] args) {
List<Integer> nums = new ArrayList<>();
nums.add(0);
nums.add(0);
nums.add(4);
nums.add(2);
nums.add(5);
nums.add(0);
nums.add(3);
nums.add(0);
int k = 0;
Integer zero = new Integer(0);
//以下方式中移除第一个0后 k++ 长度减一 剩余元素的索引都减小一位
//会出现不能清除紧跟着第一个0之后的0元素
// while (k < nums.size()) {
// if (nums.get(k).equals(zero))
// nums.remove(k);
// k++;
// }
//解法办法
//法一:普通for循环或while循环移除元素后给循环遍量--
// for (int i = 0; i < nums.size(); i++) {
// if (nums.get(i).equals(zero)){
// nums.remove(i);
// i--;
// }
// }
//或
// while (k < nums.size()) {
// if (nums.get(k).equals(zero)){
// nums.remove(k);
// k--;
// }
// k++;
// }
//使用迭代器及迭代器自带的移除方法
Iterator<Integer> iterator = nums.iterator();
ListIterator<Integer> listIterator = nums.listIterator();
while (listIterator.hasNext()){
Integer next = listIterator.next();
if (next.equals(zero)){
//移除元素可以使用单列集合Collection共有的普通的iterator迭代器
//的remove()方法移除当前遍历元素
listIterator.remove();
//但如果有添加元素的需求则不能使用普通的iterator迭代器,而需要使用
//List集合特有的listIterator迭代器的add()方法
//listIterator.add(100);
}
}
//不能在增强for循环中移除元素或新增元素,理由同迭代器时用集合自带的增删方法
//修改集合
//并发修改异常
// for (Integer num : nums) {
// if (num.equals(0)){
// nums.remove(num);
// }
// }
System.out.println(nums);
}
总的来说:
**①注意通过迭代器和增强for循环遍历集合时如果使用集合自己的增删元素方法修改集合会报并发修改异常的错误 **
**②使用普通for循环和while循环遍历集合时修改集合元素虽然不会报错,但需要注意修改前后集合长度和其余元素的索引变换情况,否则会出现遍历不完全的问题,即在操作集合后对当前遍历索引作修改 **
③通过迭代器遍历集合时删除元素可以使用Collention集合都带的iterator迭代器的remove方法,而增加元素只能使用List集合特有的listIterator迭代器的add方法。
2.JSP内置对象
题目
下面有关JSP内置对象的描述,说法错误的是?C
session对象:session对象指的是客户端与服务器的一次会话,从客户连到服务器的一个WebApplication开始,直到客户端与服务器断开连接为止
request对象:客户端的请求信息被封装在request对象中,通过它才能了解到客户的需求,然后做出响应
application对象:多个application对象实现了用户间数据的共享,可存放全局变量
response对象:response对象包含了响应客户请求的有关信息
解析
application对象保存了一个应用系统中的公有数据,一旦创建了application对象,除非服务器关闭,否则application对象就会一直存在,而且只有一个。
知识点
-
JSP内置对象
1.request对象
客户端的请求信息被封装在request对象中,通过它才能了解到客户的需求,然后做出响应。它是HttpServletRequest类的实例。
2.response对象
response对象包含了响应客户请求的有关信息,但在JSP中很少直接用到它。它是HttpServletResponse类的实例。
3.session对象
session对象指的是客户端与服务器的一次会话,从客户连到服务器的一个WebApplication开始,直到客户端与服务器断开连接为止。它是HttpSession类的实例.
4.out对象
out对象是JspWriter类的实例,是向客户端输出内容常用的对象
5.page对象
page对象就是指向当前JSP页面本身,有点象类中的this指针,它是java.lang.Object类的实例
6.application对象
application对象实现了用户间数据的共享,可存放全局变量。它开始于服务器的启动,直到服务器的关闭,在此期间,此对象将一直存在;这样在用户的前后连接或不同用户之间的连接中,可以对此对象的同一属性进行操作;在任何地方对此对象属性的操作,都将影响到其他用户对此的访问。服务器的启动和关闭决定了application对象的生命。它是ServletContext类的实例。
7.exception对象
exception对象是一个例外对象,当一个页面在运行过程中发生了例外,就产生这个对象。如果一个JSP页面要应用此对象,就必须把isErrorPage设为true,否则无法编译。他实际上是java.lang.Throwable的对象
8.pageContext对象
pageContext对象提供了对JSP页面内所有的对象及名字空间的访问,也就是说他可以访问到本页所在的SESSION,也可以取本页面所在的application的某一属性值,他相当于页面中所有功能的集大成者,它的本 类名也叫pageContext。
9.config对象
config对象是在一个Servlet初始化时,JSP引擎向它传递信息用的,此信息包括Servlet初始化时所要用到的参数(通过属性名和属性值构成)以及服务器的有关信息(通过传递一个ServletContext对象)
3.接口中常量的调用方式
-
实现类中获取调用接口常量的方式 4种
public class A implements B{ public static void main(String args[]){ int i; A a1=new A(); i =k;//直接调用 i=a1.k;//实现类实例调用 i=A.k;//实现类名.调用 i=B.k;//接口名.调用 System.out.println("i="+i); } } interface B{ int k=10; }
4.中间件
题目
关于中间件特点的描述.不正确的是()A
中间件运行于客户机/服务器的操作系统内核中,提高内核运行效率
中间件应支持标准的协议和接口
中间件可运行于多种硬件和操作系统平台上
跨越网络,硬件,操作系统平台的应用或服务可通过中间件透明交互
解析
中间件位于操作系统之上,应用软件之下,而不是操作系统内核中
知识点
- 概述中间件是一种独立的系统软件或服务程序,分布式应用软件借助这种软件在不同的技术之间共享资源。中间件位于客户机/ 服务器的操作系统之上,管理计算机资源和网络通讯。是连接两个独立应用程序或独立系统的软件。相连接的系统,即使它们具有不同的接口,但通过中间件相互之间仍能交换信息。执行中间件的一个关键途径是信息传递。通过中间件,应用程序可以工作于多平台或OS环境。
(简单来说,中间件并不能提高内核的效率,一般只是负责网络信息的分发处理)
-
中间件特点的描述:
-
中间件应支持标准的协议和接口
-
中间件可运行于多种硬件和操作系统平台上
-
跨越网络,硬件,操作系统平台的应用或服务可通过中间件透明交互
-
5.OutOfMemory(OOM)
题目
关于OutOfMemoryError,下面说法正确的是()?ABC
java.lang.OutOfMemoryError: PermGen space 增加-XX:MaxPermSize这个参数的值的话,这个问题通常会得到解决。
java.lang.OutOfMemoryError: Requested array size exceeds VM limit当你正准备创建一个超过虚拟机允许的大小的数组时,这条错误将会出现
java.lang.OutOfMemoryError: Java heap space 一般情况下解决这个问题最快的方法就是通过-Xmx参数来增加堆的大小
java.lang.OutOfMemoryError: nativeGetNewTLA这个异常只有在jRockit虚拟机时才会碰到
解析
关于此题,《深入理解java虚拟机》有关于OOM(OutOfMemory)问题的解释
A:属于运行时常量池导致的溢出,设置-XX:MaxPermSize可以解决这个问题,
B:属于堆空间不足导致的错误,问题比较少见,解决方式和C相同,
C:属于java堆内存问题,一般的手段是通过内存映像分析工具,对Dump出来的堆转储存快照进行分析,重点是确认内存中的对象是否是有必要的,也就是要判断是出现了内存泄漏,还是出现了内存溢出,如果是内存泄漏,通过工具检查泄露对象打GC Roots的引用链信息,可以准确的确定出泄露代码的位置,不存在泄露,就应该检查虚拟机的堆参数,如果可以继续调大,可以设置-Xmx解决问题
D:java.lang.OutOfMemoryError: nativeGetNewTLA指当虚拟机不能分配新的线程本地空间(Thread Local Area)的时候错误信息,此错误是线程申请一个新的TLA时产生的,这个异常一般只会发生在jRockit虚拟机,只有过于绝对。
6.单例模式
题目
单例模式中,两个基本要点是 AD
构造函数私有
静态工厂方法
以上都不对
唯一实例
知识点
-
定义
单例模式(Singleton Pattern)是 Java 中最简单的设计模式之一。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。
这种模式涉及到一个单一的类,该类负责创建自己的对象,同时确保只有单个对象被创建。这个类提供了一种访问其唯一的对象的方式,可以直接访问,不需要实例化该类的对象。
单例模式有分为饿汉式和懒汉式
-
特点:
- 1、单例类只能有一个实例。
- 2、单例类必须自己创建自己的唯一实例。
- 3、单例类必须给所有其他对象提供这一实例。
-
应用实例:
- 1、一个班级只有一个班主任。
- 2、Windows 是多进程多线程的,在操作一个文件的时候,就不可避免地出现多个进程或线程同时操作一个文件的现象,所以所有文件的处理必须通过唯一的实例来进行。
- 3、一些设备管理器常常设计为单例模式,比如一个电脑有两台打印机,在输出的时候就要处理不能两台打印机打印同一个文件。
-
优点:
- 1、在内存里只有一个实例,减少了内存的开销,尤其是频繁的创建和销毁实例)。
- 2、避免对资源的多重占用(比如写文件操作)。
-
**缺点:**没有接口,不能继承,与单一职责原则冲突,一个类应该只关心内部逻辑,而不关心外面怎么样来实例化。
-
使用场景:
- 1、要求生产唯一序列号。
- 2、WEB 中的计数器,不用每次刷新都在数据库里加一次,用单例先缓存起来。
- 3、创建的一个对象需要消耗的资源过多,比如 I/O 与数据库的连接等。
-
**注意事项:**getInstance() 方法中需要使用同步锁 synchronized (Singleton.class) 防止多线程同时进入造成 instance 被多次实例化。
-
饿汉式代码 全局的单例实例在第一次被使用时构建
//单例模式-饿汉式 public class SingletonDemo { public static void main(String[] args) { //编译错误:无法实例化 // Singleton singleton = new Singleton(); //正确获取对象的方法 Singleton singleton = Singleton.getINSTANCE(); singleton.hello(); } } class Singleton{ //创建一个本身对象 private static final Singleton INSTANCE = new Singleton(); //让构造方法为private,这样该类就不会被实例化 private Singleton(){} //创建一个获取对象的方法 public static Singleton getINSTANCE() { return INSTANCE; } public void hello(){ System.out.println("Hello World! ——单例模式-饿汉式"); } } -
懒汉式(线程不安全版)–全局的单例实例在类装载时构建。
这种方式是最基本的实现方式,这种实现最大的问题就是不支持多线程。因为没有加锁 synchronized,所以严格意义上它并不算单例模式。
//单例模式-懒汉式 public class SingletonDemo2 { public static void main(String[] args) { Singleton2 singleton = Singleton2.getInstance(); singleton.hello(); } } class Singleton2{ private static Singleton2 instance; private Singleton2(){} public static Singleton2 getInstance() { if (instance == null){ instance = new Singleton2(); } return instance; } public void hello(){ System.out.println("Hello World! ——单例模式-懒汉式"); } } -
懒汉式(线程安全版1)
**描述:**这种方式具备很好的 lazy loading,能够在多线程中很好的工作,但是,效率很低,99% 情况下不需要同步。
**优点:**第一次调用才初始化,避免内存浪费。
**缺点:**必须加锁 synchronized 才能保证单例,但加锁会影响效率。
getInstance() 的性能对应用程序不是很关键(该方法使用不太频繁)
//单例模式-懒汉式
public class SingletonDemo3 {
public static void main(String[] args) {
Singleton3 singleton = Singleton3.getInstance();
singleton.hello();
}
}
class Singleton3{
private static Singleton3 instance;
private Singleton3(){}
public synchronized static Singleton3 getInstance() {
if (instance == null){
instance = new Singleton3();
}
return instance;
}
public void hello(){
System.out.println("Hello World! ——单例模式-懒汉式");
}
}
-
懒汉式(线程安全版2-双重校验锁)
public class Singleton{ private volatile static Singleton instance; //私有构造函数 private Singleton{ } //唯一实例 public static Singleton getInstacne(){ if(instance == null){ synchronized(Singleton.class){ if(instance == null){ instance = new Singleton(); } } } return instance; } }
7.对象引用类型&垃圾回收
题目
下面有关java的引用类型,说法正确的有? ABCD-其中A有异议
被GCroot强引用=Gcroot对象来说,只要有强引用的存在,它就会一直存在于内存中
如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收器回收。
如果一个对象只具有软引用,则内存空间足够,垃圾回收器就不会回收它;如果内存空间不足了,就会回收这些对象的内存
一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的空间
知识点
四种引用类型-强软弱虚
JDK1.2 之前,一个对象只有“已被引用”和"未被引用"两种状态,这将无法描述某些特殊情况下的对象,比如,当内存充足时需要保留,而内存紧张时才需要被抛弃的一类对象。
所以在 JDK.1.2 之后,Java 对引用的概念进行了扩充,将引用分为了:强引用(Strong Reference)、软引用(Soft Reference)、弱引用(Weak Reference)、虚引用(Phantom Reference)4 种,这 4 种引用的强度依次减弱。
一,强引用
Object obj = new Object(); //只要obj还指向Object对象,Object对象就不会被回收 obj = null; //手动置null
只要强引用存在,垃圾回收器将永远不会回收被引用的对象,哪怕内存不足时,JVM也会直接抛出OutOfMemoryError,不会去回收。如果想中断强引用与对象之间的联系,可以显示的将强引用赋值为null,这样一来,JVM就可以适时的回收对象了
二,软引用
软引用是用来描述一些非必需但仍有用的对象。在内存足够的时候,软引用对象不会被回收,只有在内存不足时,系统则会回收软引用对象,如果回收了软引用对象之后仍然没有足够的内存,才会抛出内存溢出异常。这种特性常常被用来实现缓存技术,比如网页缓存,图片缓存等。
在 JDK1.2 之后,用java.lang.ref.SoftReference类来表示软引用。
三,弱引用
弱引用的引用强度比软引用要更弱一些,无论内存是否足够,只要 JVM 开始进行垃圾回收,那些被弱引用关联的对象都会被回收。在 JDK1.2 之后,用 java.lang.ref.WeakReference 来表示弱引用。
四,虚引用
虚引用是最弱的一种引用关系,如果一个对象仅持有虚引用,那么它就和没有任何引用一样,它随时可能会被回收,在 JDK1.2 之后,用 PhantomReference 类来表示,通过查看这个类的源码,发现它只有一个构造函数和一个 get() 方法,而且它的 get() 方法仅仅是返回一个null,也就是说将永远无法通过虚引用来获取对象,虚引用必须要和 ReferenceQueue 引用队列一起使用。不能单独存在,必须和引用队列联合使用。主要作用是跟踪对象被回收的状态。
2022.3.18
1. 创建对象的5种方式
题目
Java创建对象的说法正确的有()ABCD
用new语句创建对象,是最常见的创建对象的方法。
运用反射手段,调用java.lang.Class或者java.lang.reflect.Constructor类的newInstance()实例方法。
调用对象的clone()方法。
运用反序列化手段,调用java.io.ObjectInputStream对象的 readObject()方法。
知识点
Java有5种方式来创建对象:
1、使用 new 关键字(最常用): ObjectName obj = new ObjectName();
2、使用反射的Class类的newInstance()方法: ObjectName obj = ObjectName.class.newInstance();
3、使用反射的Constructor类的newInstance()方法: ObjectName obj = ObjectName.class.getConstructor.newInstance();
4、使用对象克隆**clone()**方法: ObjectName obj = obj.clone();
5、使用反序列化(ObjectInputStream)的readObject()方法: try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream(FILE_NAME))) { ObjectName obj = ois.readObject(); }
其中通过对象克隆和反序列化流的readObject方法创建的对象不走构造方法,readObject方法只是从文件中还原对象,clone只是一种复制拷贝对象。
2.Maven&Ant
题目
下面有关maven和ant的描述,描述错误的是?C
Ant 没有正式的约定如一个一般项目的目录结构,你必须明确的告诉 Ant 哪里去找源代码
Maven 拥有约定,因为你遵循了约定,它已经知道你的源代码在哪里
maven和ant都有“生命周期”的概念,当你输入一个命令后,maven或者ant会执行一系列的有序的步骤,直到到达你指定的生命周期
Ant构建文件默认命名为build.xml,Maven默认构建文件为pom.xml
知识点
Ant一种基于Java的构建build工具
-
Ant的作用
- 能够用ant编译java类。生成class文件
- ant能够自己定义标签、配置文件,用于构建。
- ant能够把相关层构建成jar包 。
- ant把整个项目生成web包。并公布到Tomcat
-
Ant的优点
- 跨平台性:Ant是纯Java语言编写的,因此具有非常好的跨平台性。
- 操作简单:Ant是由一个内置任务和可选任务组成的。Ant执行时须要一个XML文件(构建文件,默认命名为build.xml)。
- Ant通过调用target树,就能够运行各种task:每一个task实现了特定接口对象。因为Ant构建文件时XML格式的文件。所以非常easy维护和书写,并且结构非常清晰。
- Ant能够集成到开发环境中:因为Ant的跨平台性和操作简单的特点。它非常easy集成到一些开发环境中去。
Maven的作用: 除了以程序构建能力为特色之外,还提供高级项目管理工具。
1.Maven除了具备Ant的功能外。还添加了下面基本的功能:
- 使用Project Object Model来对软件项目管理。
- 内置了很多其它的隐式规则,使得构建文件更加简单。
- 内置依赖管理和Repository来实现依赖的管理和统一存储;
- 内置了软件构建的生命周期;
2.Maven优点
- 拥有约定,知道你的代码在哪里,放到哪里去
- 拥有一个生命周期,比如运行 mvn install就能够自己主动运行编译,測试。打包等构建过程
- 仅仅须要定义一个pom.xml,然后把源代码放到默认的文件夹,Maven帮你处理其它事情
- 拥有依赖管理。仓库管理
Ant VS Maven
Ant
①没有一个约定的目录结构
②必须明确让ant做什么,什么时候做,然后编译,打包
③没有生命周期,必须定义目标及其实现的任务序列
④没有集成依赖管理
3.Java程序分类(Application/Applet/Servlet)及特点&J2SDK JDK JRE JVM
题目
下列说法正确的有()A
能被java.exe成功运行的java class文件必须有main()方法
J2SDK就是Java API
Appletviewer.exe可利用jar选项运行.jar文件
能被Appletviewer成功运行的java class文件必须有main()方法
解析
**B.**错误。
J2SDK = JDK + JRE
JDK(Java Development kit) = JRE + Java工具(javac/java/jdb等) + Java API(基础类库)
JRE(Java Runtime Environment) = JVM + Java核心类库
JVM(Java Virtual Mechinal),Java虚拟机,是JRE的一部分。它是整个java实现跨平台的最核心的部分,负责解释执行字节码文件,是可运行java字节码文件的虚拟计算机。
**C.**可用java.exe选项运行.jar文件
D.不需要main方法,继承Applet即可
知识点
1. java程序的种类
1.Application:Java应用程序,是可以由Java解释器直接运行的程序。
2.Applet:即Java小应用程序,是可随网页下载到客户端由浏览器解释执行的Java程序。 不需要main方法
3.Servlet:Java服务器端小程序,由Web服务器(容器)中配置运行的Java程序。
4.CMS(Concurrent Mark Sweep)垃圾回收器&用户线程
题目
CMS垃圾回收器在那些阶段是没用用户线程参与的 AC
初始标记
并发标记
重新标记
并发清理
知识点
-
CMS概述
CMS全称 Concurrent Mark Sweep,是一款并发的、使用标记-清除算法的垃圾回收器,以牺牲吞吐量为代价来获得最短回收停顿时间的垃圾回收器,对于要求服务器响应速度的应用上,这种垃圾回收器非常适合。
-
CMS基础算法
标记—清除
-
CMS步骤
它的过程可以分为以下6个步骤:
- 初始标记(STW initial mark)
- 并发标记(Concurrent marking)
- 并发预清理(Concurrent precleaning)
- 重新标记(STW remark)
- 并发清理(Concurrent sweeping)
- 并发重置(Concurrent reset)
-
CMS各步骤解释
- 初始标记:在这个阶段,需要虚拟机停顿正在执行的任务,官方的叫法STW(Stop The Word)。这个过程从垃圾回收的"根对象"开始,只扫描到能够和"根对象"直接关联的对象,并作标记。所以这个过程虽然暂停了整个JVM,但是很快就完成了。
- **并发标记:**这个阶段紧随初始标记阶段,在初始标记的基础上继续向下追溯标记。并发标记阶段,应用程序的线程和并发标记的线程并发执行,所以用户不会感受到停顿。
- 并发预清理:并发预清理阶段仍然是并发的。在这个阶段,虚拟机查找在执行并发标记阶段新进入老年代的对象(可能会有一些对象从新生代晋升到老年代, 或者有一些对象被分配到老年代)。通过重新扫描,减少下一个阶段"重新标记"的工作,因为下一个阶段会Stop The World。
- 重新标记:这个阶段会暂停虚拟机,收集器线程扫描在CMS堆中剩余的对象。扫描从"根对象"开始向下追溯,并处理对象关联。
- **并发清理:**清理垃圾对象,这个阶段收集器线程和应用程序线程并发执行。
- **并发重置:**这个阶段,重置CMS收集器的数据结构,等待下一次垃圾回收。
-
用户线程概念
**用户线程(user-level threads)**指不需要内核支持而在用户程序中实现的线程,其不依赖于操作系统核心,应用进程利用线程库提供创建、同步、调度和管理线程的函数来控制用户线程。
初次标记,重新标志的时候,要求我们暂停其它应用程序,那么这两个阶段用户线程是不会参与的
5.++(i++)编译不通过,++(需要变量而i++结果而言是字面量)
6.前台线程(非守护线程|用户线程)、后台线程(守护线程)
题目
jre 判断程序是否执行结束的标准是()A
所有的前台线程执行完毕
所有的后台线程执行完毕
所有的线程执行完毕
和以上都无关
知识点
-
后台线程定义
指为其他线程提供服务的线程,也称为守护线程。JVM的垃圾回收线程就是一个后台线程。
-
前台线程定义
指接受后台线程服务的线程,是程序中必须执行完成的。 main()函数即主函数,是一个前台线程
-
前后台线程区别与联系
1、后台线程不会阻止进程的终止。属于某个进程的所有前台线程都终止后,该进程就会被终止。所有剩余的后台线程都会停止且不会完成。举例如下:
class ThreadDemo extends Thread{ public void run(){ System.out.println(Thread.currentThread().getName()+" : begin"); try{ Thread.sleep(2000); }catch(Exception e){ e.printStackTrace(); } System.out.println(Thread.currentThread().getName()+" : end"); } } public class Test{ public static void main(String[] args){ System.out.println("test : begin"); Thread t = new ThreadDemo(); t.setDaemon(true); t.start(); System.out.println("test : end"); } } /** 程序输出: test : begin test : end Thread-0 :begin 运行结果中不会有Thread-0 : end,是因为,守护线程开启之后,中间睡了2s,这个时候又没有锁,主线程直接就执行完了, 一旦主线程结束,那么JVM中就只剩守护线程了,JVM直接就退出了,不管你守护线程有没有执行完。 */2、可以在任何时候将前台线程修改为后台线程,方式是设置Thread.IsBackground 属性。
3、不管是前台线程还是后台线程,如果线程内出现了异常,都会导致进程的终止。
4、托管线程池中的线程都是后台线程,使用new Thread方式创建的线程默认都是前台线程。
2022.3.20
1.String类方法-split
题目
输出结果为:1
String str = "";
System.out.print(str.split(",").length);
解析
- String[] split(String regx)
将字符串根据匹配正则regx的分隔符划分为一个字符数组,如果找不到该分隔符,则把整个str字符串放入字符串数组的第一个元素。
2.理解i++的赋值机制
题目
public class Demo {
public static void main(String[] args) {
int count = 0;
int sum = 0;
for (int i = 0; i < 100; i++) {
sum = sum + i;
// count = count++;
// count = count++;相当于 temp = count; count = count+1;count = temp
//所以count始终为0
count = ++count;
}
System.out.println("count*sum: "+sum * count);
}
}
解析
count = count ++;这个先将count这个值0暂存起来,然后count自加1变成1,最后将暂存的值赋值给count,count最终的值为0
3.Java体系结构
题目
Java的体系结构包含( )。ABCD
Java编程语言
Java类文件格式
Java API
JVM
知识点
Java体系结构包括四个独立但相关的技术:
- Java程序设计语言
- Java.class文件格式
- Java应用编程接口(API)
- Java虚拟机
我们再在看一下它们四者的关系:
当我们编写并运行一个Java程序时,就同时运用了这四种技术,用Java程序设计语言编写源代码,把它编译成Java.class文件格式,然后再在Java虚拟机中运行class文件。当程序运行的时候,它通过调用class文件实现了Java API的方法来满足程序的Java API调用
2022.3.21
1.静态域在类加载时只加载一次,不能重复加载
题目
以下代码的输出结果是?构造块 构造块 静态块 构造块
public class B
{
public static B t1 = new B();
public static B t2 = new B();
{
System.out.println("构造块");
}
static
{
System.out.println("静态块");
}
public static void main(String[] args)
{
B t = new B();
}
}
解析
- 静态域(静态变量,静态方法,静态代码块)随类的第一次加载而执行,且按照先后顺序只加载一次
- 每次new一个对象都会调用一次构造块和构造方法,且构造块总是在构造方法前执行
- 首先加载类B,执行静态域的第一个静态变量,static b1=new B,输出构造块和构造方法(空)。ps:这里为什么不加载静态方法呢?因为执行了静态变量的初始化,意味着已经加载了B的静态域的一部分,这时候不能再加载另一个静态域了,否则属于重复加载 了(静态域必须当成一个整体来看待。否则加载会错乱) 于是,依次static b2 =new B,输出构造块,再执行静态块,完成对整个静态域的加载,再执行main方法,new b,输出构造块。
2.Linux命令-tar
题目
以下哪个命令用于查看tar(backup.tar)文件的内容而不提取它?( B)
tar -xvf backup.tar
tar -tvf backup.tar
tar -svf backup.tar
none of these
解析
-
tar命令
-c: 建立压缩档案
-x:解压
-t:查看内容
-r:向压缩归档文件末尾追加文件
-u:更新原压缩包中的文件这五个是独立的命令,压缩解压都要用到其中一个,可以和别的命令连用但只能用其中一个。下面的参数是根据需要在压缩或解压档案时可选的。
-z:有gzip属性的
-j:有bz2属性的
-Z:有compress属性的
-v:显示所有过程
-O:将文件解开到标准输出下面的参数-f是必须的
-f: 使用档案名字,切记,这个参数是最后一个参数,后面只能接档案名。
# tar -cf all.tar *.jpg
这条命令是将所有.jpg的文件打成一个名为all.tar的包。-c是表示产生新的包,-f指定包的文件名。# tar -rf all.tar *.gif
这条命令是将所有.gif的文件增加到all.tar的包里面去。-r是表示增加文件的意思。# tar -uf all.tar logo.gif
这条命令是更新原来tar包all.tar中logo.gif文件,-u是表示更新文件的意思。# tar -tf all.tar
这条命令是列出all.tar包中所有文件,-t是列出文件的意思# tar -xf all.tar
这条命令是解出all.tar包中所有文件,-x是解开的意思压缩
- tar –cvf jpg.tar *.jpg 将目录里所有jpg文件打包成tar.jpg
- tar –czf jpg.tar.gz *.jpg 将目录里所有jpg文件打包成jpg.tar后,并且将其用gzip压缩,生成一个gzip压缩过的包,命名为jpg.tar.gz
- tar –cjf jpg.tar.bz2 *.jpg 将目录里所有jpg文件打包成jpg.tar后,并且将其用bzip2压缩,生成一个bzip2压缩过的包,命名为jpg.tar.bz2
- tar –cZf jpg.tar.Z *.jpg 将目录里所有jpg文件打包成jpg.tar后,并且将其用compress压缩,生成一个umcompress压缩过的包,命名为jpg.tar.Z
- rar a jpg.rar *.jpg rar格式的压缩,需要先下载rar for linux
- zip jpg.zip *.jpg zip格式的压缩,需要先下载zip for linux
解压
- tar –xvf file.tar 解压 tar包
- tar -xzvf file.tar.gz 解压tar.gz
- tar -xjvf file.tar.bz2 解压 tar.bz2
- tar –xZvf file.tar.Z 解压tar.Z
- unrar e file.rar 解压rar
- unzip file.zip 解压zip
总结
- *.tar 用 tar –xvf 解压
- *.gz 用 gzip -d或者gunzip 解压
- .tar.gz和.tgz 用 tar –xzf 解压
- *.bz2 用 bzip2 -d或者用bunzip2 解压
- *.tar.bz2用tar –xjf 解压
- *.Z 用 uncompress 解压
- *.tar.Z 用tar –xZf 解压
- *.rar 用 unrar e解压
- *.zip 用 unzip 解压
3.String类创建对象个数
题目
String s = new String(“xyz”);创建了几个StringObject? A
两个或一个都有可能
两个
一个
三个
解析
1.String对象的两种创建方式:–是否需要在额外堆中创建字符串对象
第一种方式:
String str1 = “aaa”;
是在常量池中获取对象(“aaa” 属于字符串字面量,因此编译时期会在常量池中创建一个字符串对象),
第二种方式: String str2 = new String(“aaa”) ; 一共会创建两个字符串对象一个在堆中,一个在常量池中(前提是常量池中还没有 “aaa” 字符串对象)。
System.out.println(str1==str2);//false
2.String类型的常量池比较特殊。它的主要使用方法有两种:
直接使用双引号声明出来的String对象会直接存储在常量池中。
如果不是用双引号声明的String对象,可以使用 String 提供的 intern 方法。 String.intern() 是一个 Native 方法,它的作用是: 如果运行时常量池中已经包含一个等于此 String 对象内容的字符串,则返回常量池中该字符串的引用; 如果没有,则在常量池中创建与此 String 内容相同的字符串,并返回常量池中创建的字符串的引用。
String s1 = new String(“AAA”);
String s2 = s1.intern();
String s3 = “AAA”;
System.out.println(s2);//AAA
System.out.println(s1 == s2);//false,因为一个是堆内存中的String对象一个是常量池中的String对象,
gin
运行结果中不会有Thread-0 : end,是因为,守护线程开启之后,中间睡了2s,这个时候又没有锁,主线程直接就执行完了,
一旦主线程结束,那么JVM中就只剩守护线程了,JVM直接就退出了,不管你守护线程有没有执行完。 */
2、**可以在任何时候将前台线程修改为后台线程**,方式是设置Thread.IsBackground 属性。
3、不管是前台线程还是后台线程,如果**线程内出现了异常,都会导致进程的终止**。
4、**托管线程池中的线程都是后台线程,使用new Thread方式创建的线程默认都是前台线程**。
### 2022.3.20
#### 1.String类方法-split
**题目**
输出结果为:1
String str = “”;
System.out.print(str.split(“,”).length);
**解析**
1. String[] split(String regx)
**将字符串根据匹配正则regx的分隔符划分为一个字符数组,如果找不到该分隔符,则把整个str字符串放入字符串数组的第一个元素。**
#### 2.理解i++的赋值机制
**题目**
```java
public class Demo {
public static void main(String[] args) {
int count = 0;
int sum = 0;
for (int i = 0; i < 100; i++) {
sum = sum + i;
// count = count++;
// count = count++;相当于 temp = count; count = count+1;count = temp
//所以count始终为0
count = ++count;
}
System.out.println("count*sum: "+sum * count);
}
}
解析
count = count ++;这个先将count这个值0暂存起来,然后count自加1变成1,最后将暂存的值赋值给count,count最终的值为0
3.Java体系结构
题目
Java的体系结构包含( )。ABCD
Java编程语言
Java类文件格式
Java API
JVM
知识点
Java体系结构包括四个独立但相关的技术:
- Java程序设计语言
- Java.class文件格式
- Java应用编程接口(API)
- Java虚拟机
我们再在看一下它们四者的关系:
当我们编写并运行一个Java程序时,就同时运用了这四种技术,用Java程序设计语言编写源代码,把它编译成Java.class文件格式,然后再在Java虚拟机中运行class文件。当程序运行的时候,它通过调用class文件实现了Java API的方法来满足程序的Java API调用
2022.3.21
1.静态域在类加载时只加载一次,不能重复加载
题目
以下代码的输出结果是?构造块 构造块 静态块 构造块
public class B
{
public static B t1 = new B();
public static B t2 = new B();
{
System.out.println("构造块");
}
static
{
System.out.println("静态块");
}
public static void main(String[] args)
{
B t = new B();
}
}
解析
- 静态域(静态变量,静态方法,静态代码块)随类的第一次加载而执行,且按照先后顺序只加载一次
- 每次new一个对象都会调用一次构造块和构造方法,且构造块总是在构造方法前执行
- 首先加载类B,执行静态域的第一个静态变量,static b1=new B,输出构造块和构造方法(空)。ps:这里为什么不加载静态方法呢?因为执行了静态变量的初始化,意味着已经加载了B的静态域的一部分,这时候不能再加载另一个静态域了,否则属于重复加载 了(静态域必须当成一个整体来看待。否则加载会错乱) 于是,依次static b2 =new B,输出构造块,再执行静态块,完成对整个静态域的加载,再执行main方法,new b,输出构造块。
2.Linux命令-tar
题目
以下哪个命令用于查看tar(backup.tar)文件的内容而不提取它?( B)
tar -xvf backup.tar
tar -tvf backup.tar
tar -svf backup.tar
none of these
解析
-
tar命令
-c: 建立压缩档案
-x:解压
-t:查看内容
-r:向压缩归档文件末尾追加文件
-u:更新原压缩包中的文件这五个是独立的命令,压缩解压都要用到其中一个,可以和别的命令连用但只能用其中一个。下面的参数是根据需要在压缩或解压档案时可选的。
-z:有gzip属性的
-j:有bz2属性的
-Z:有compress属性的
-v:显示所有过程
-O:将文件解开到标准输出下面的参数-f是必须的
-f: 使用档案名字,切记,这个参数是最后一个参数,后面只能接档案名。
# tar -cf all.tar *.jpg
这条命令是将所有.jpg的文件打成一个名为all.tar的包。-c是表示产生新的包,-f指定包的文件名。# tar -rf all.tar *.gif
这条命令是将所有.gif的文件增加到all.tar的包里面去。-r是表示增加文件的意思。# tar -uf all.tar logo.gif
这条命令是更新原来tar包all.tar中logo.gif文件,-u是表示更新文件的意思。# tar -tf all.tar
这条命令是列出all.tar包中所有文件,-t是列出文件的意思# tar -xf all.tar
这条命令是解出all.tar包中所有文件,-x是解开的意思压缩
- tar –cvf jpg.tar *.jpg 将目录里所有jpg文件打包成tar.jpg
- tar –czf jpg.tar.gz *.jpg 将目录里所有jpg文件打包成jpg.tar后,并且将其用gzip压缩,生成一个gzip压缩过的包,命名为jpg.tar.gz
- tar –cjf jpg.tar.bz2 *.jpg 将目录里所有jpg文件打包成jpg.tar后,并且将其用bzip2压缩,生成一个bzip2压缩过的包,命名为jpg.tar.bz2
- tar –cZf jpg.tar.Z *.jpg 将目录里所有jpg文件打包成jpg.tar后,并且将其用compress压缩,生成一个umcompress压缩过的包,命名为jpg.tar.Z
- rar a jpg.rar *.jpg rar格式的压缩,需要先下载rar for linux
- zip jpg.zip *.jpg zip格式的压缩,需要先下载zip for linux
解压
- tar –xvf file.tar 解压 tar包
- tar -xzvf file.tar.gz 解压tar.gz
- tar -xjvf file.tar.bz2 解压 tar.bz2
- tar –xZvf file.tar.Z 解压tar.Z
- unrar e file.rar 解压rar
- unzip file.zip 解压zip
总结
- *.tar 用 tar –xvf 解压
- *.gz 用 gzip -d或者gunzip 解压
- .tar.gz和.tgz 用 tar –xzf 解压
- *.bz2 用 bzip2 -d或者用bunzip2 解压
- *.tar.bz2用tar –xjf 解压
- *.Z 用 uncompress 解压
- *.tar.Z 用tar –xZf 解压
- *.rar 用 unrar e解压
- *.zip 用 unzip 解压
3.String类创建对象个数
题目
String s = new String(“xyz”);创建了几个StringObject? A
两个或一个都有可能
两个
一个
三个
解析
1.String对象的两种创建方式:–是否需要在额外堆中创建字符串对象
第一种方式:
String str1 = “aaa”;
是在常量池中获取对象(“aaa” 属于字符串字面量,因此编译时期会在常量池中创建一个字符串对象),
第二种方式: String str2 = new String(“aaa”) ; 一共会创建两个字符串对象一个在堆中,一个在常量池中(前提是常量池中还没有 “aaa” 字符串对象)。
System.out.println(str1==str2);//false
2.String类型的常量池比较特殊。它的主要使用方法有两种:
直接使用双引号声明出来的String对象会直接存储在常量池中。
如果不是用双引号声明的String对象,可以使用 String 提供的 intern 方法。 String.intern() 是一个 Native 方法,它的作用是: 如果运行时常量池中已经包含一个等于此 String 对象内容的字符串,则返回常量池中该字符串的引用; 如果没有,则在常量池中创建与此 String 内容相同的字符串,并返回常量池中创建的字符串的引用。
String s1 = new String(“AAA”);
String s2 = s1.intern();
String s3 = “AAA”;
System.out.println(s2);//AAA
System.out.println(s1 == s2);//false,因为一个是堆内存中的String对象一个是常量池中的String对象,
System.out.println(s2 == s3);//true, s2,s3指向常量池中的”AAA“














 2062
2062











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









