







1.主要动机
Helix是应用广泛的MP3音频解码库,但是由于原版代码只针对ARM处理器和X86处理器做了底层的优化并有且只有适配这两种构架的处理器的底层代码。而常用的处理器架构远远不止这两种,例如英特尔FPGA的软核NIOS II处理器、德州仪器TMS320F28系列数字信号处理器、英飞凌TC2系列单片机的TC1处理器等,尤其是近年来,国产单片机如雨后春笋涌现,其大都采用自主研发的RISC-V构架的处理器,例如K210、联盛德基于平头哥XT804处理器的W801和W806、江苏恒沁CH57系列单片机、EPS8266和EPS32系列单片机、中科蓝汛AB32VG1单片机等。在使用这些基于RISC-V处理器的单片机时,此前在基于ARM处理器的单片机上的功能如果追求性能优化,使用汇编实现了一些功能,将无法移植,笔者正是在开发中科蓝汛AB32VG1单片机时在配置Helix库后报错时发现,其底层调用了ARM汇编编写的代码,从而导致性能优秀的国产单片机做不了MP3播放器,正可谓巧妇难为无米之炊啊!
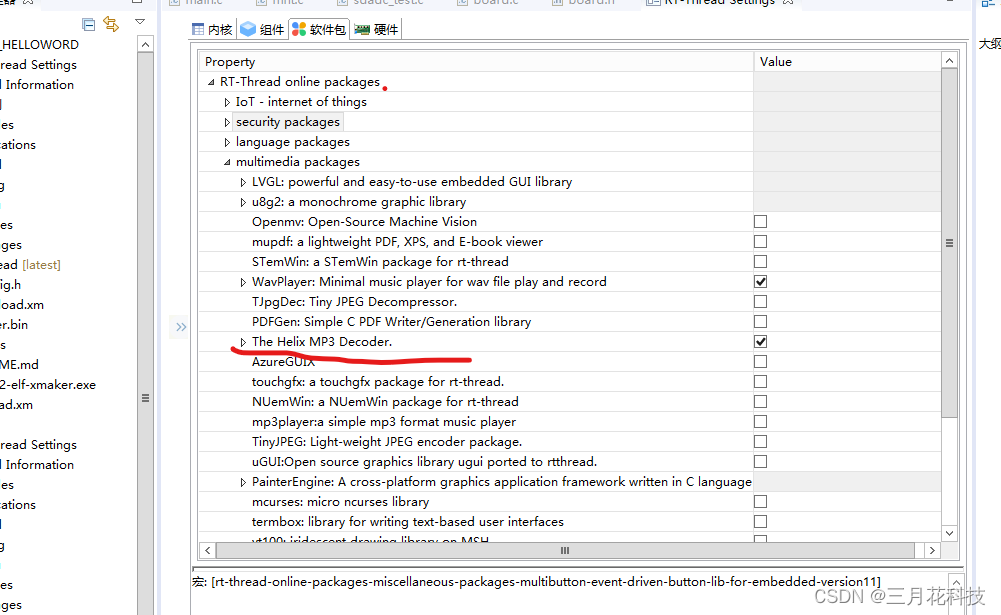
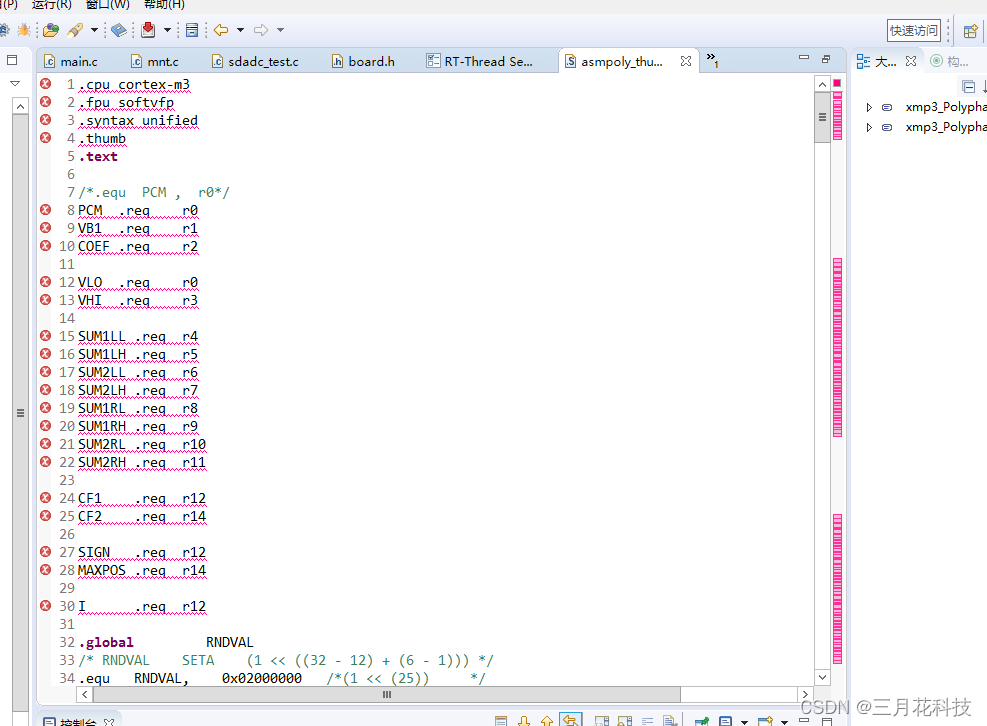
下图分别是在软件包添加Helix解码库和编译后报错查看报错位置的图片。从第二张图片显然看到是ARM指令,更何况开头赤裸裸得写着Cortex-M3。
2.解决思路
既然所有基于RISC-V处理器的单片机都有其对应的GCC工具链实现从C或C++语言编译的功能,那只要把此前不能移植的功能中使用汇编实现的功能重新用C或C++语言实现,就可以在所有的处理器上运行了(暂且不考虑改C或C++后对性能要求的提高,毕竟改了只是耗费更多性能来是实现功能,而不改连功能都不会有,其次现在的C编译器优化功能非常强,编译器生成的汇编代码可能效率比自己写得高)
3.修改详细过程
其实非常简单,处理器无论多复杂,其功能只有一个——处理数据,其方法也只有两个——逻辑运算和算术运算。只要搞明白汇编文件中每个指令的意义,重新用C语言编写即可。
3.1首先找到Helix库中的所有汇编文件
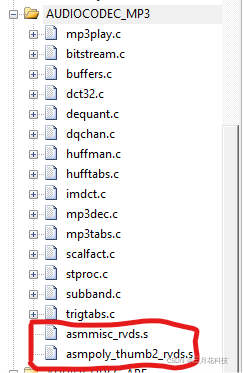
可以看到有这两个汇编文件,我们只需要重新用C语言实现这两个汇编文件的功能即可。
3.2然后我想偷懒
这两个汇编文件虽然篇幅不是很长,但还是想偷懒,有没有十分钟搞定的方法?!
有!
阅读Helix的底层文件可以发现,该库除了适配ARM处理器还适配x86处理器,而x86处理器版本的底层文件原本就是用C实现的,这个文件是polyphase.c(在Helix目录下,即原汇编文件的上一层目录),此文件在往常的移植过程中是不能添加进工程的,但是现在,这是偷懒的最佳方案【手动狗头】。
使用此文件后,直接编译会报错,错误指示在assembly.h文件中,查看得知,在其中几个几位高频的计算方面,使用了内联汇编实现了优化,而由于针对的是x86处理器,所以此时编译依旧会报错。
虽然依旧是走老路,把汇编变成C语言,但是assembly.h文件中出现汇编的函数只有4个,且函数功能极为简单转为C语言后,最多不超过三行。
具体修改如下:
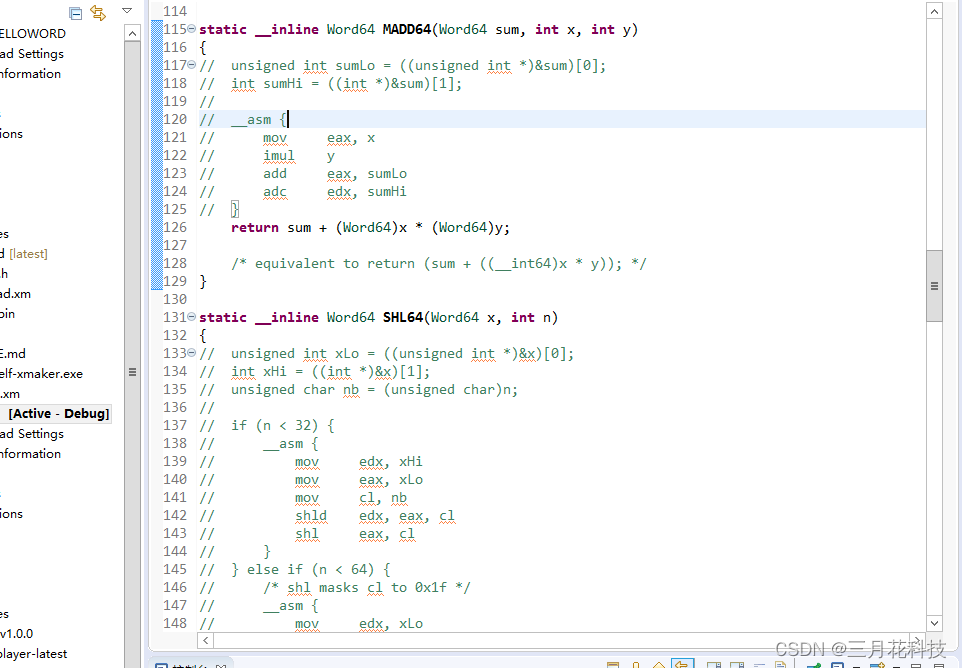
64位乘法并取高32位结果(注释掉的部分为原x86指令)
static __inline int MULSHIFT32(int x, int y)
{
// __asm {
// mov eax, x
// imul y
// mov eax, edx
// }
long long temp;
temp = (long long)x * (long long)y;
return temp >> 32;
}64位乘加运算(注释掉的部分为x86指令)
static __inline Word64 MADD64(Word64 sum, int x, int y)
{
// unsigned int sumLo = ((unsigned int *)&sum)[0];
// int sumHi = ((int *)&sum)[1];
// __asm {
// mov eax, x
// imul y
// add eax, sumLo
// adc edx, sumHi
// }
return sum + (Word64)x * (Word64)y;
/* equivalent to return (sum + ((__int64)x * y)); */
}64位逻辑左移(注释掉的为原汇编代码)
static __inline Word64 SHL64(Word64 x, int n)
{
// unsigned int xLo = ((unsigned int *)&x)[0];
// int xHi = ((int *)&x)[1];
// unsigned char nb = (unsigned char)n;
// if (n < 32) {
// __asm {
// mov edx, xHi
// mov eax, xLo
// mov cl, nb
// shld edx, eax, cl
// shl eax, cl
// }
// } else if (n < 64) {
// /* shl masks cl to 0x1f */
// __asm {
// mov edx, xLo
// mov cl, nb
// xor eax, eax
// shl edx, cl
// }
// } else {
// __asm {
// xor edx, edx
// xor eax, eax
// }
// }
return x << n;
}64位算数右移(注释掉的为原汇编代码)
static __inline Word64 SAR64(Word64 x, int n)
{
// unsigned int xLo = ((unsigned int *)&x)[0];
// int xHi = ((int *)&x)[1];
// unsigned char nb = (unsigned char)n;
// if (n < 32) {
// __asm {
// mov edx, xHi
// mov eax, xLo
// mov cl, nb
// shrd eax, edx, cl
// sar edx, cl
// }
// } else if (n < 64) {
// /* sar masks cl to 0x1f */
// __asm {
// mov edx, xHi
// mov eax, xHi
// mov cl, nb
// sar edx, 31
// sar eax, cl
// }
// } else {
// __asm {
// sar xHi, 31
// mov eax, xHi
// mov edx, xHi
// }
// }
return x >> n;
}
改完了!就这么简单。
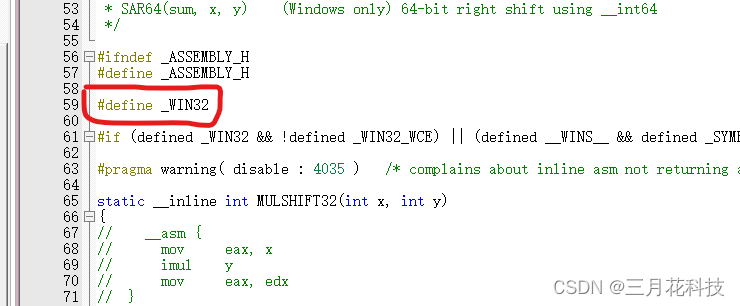
最后,在此文件的条件编译前加个定义,哄一哄编译器,让他把我们的处理器当作x86处理器,这样刚刚改的4个函数才可以生效。
4.测试效果
这样修改后,正常播放,音质没有任何影响。当然,笔者在测试时遇到了一些小插曲,正如上面修改成C的代码都加了强制类型转换把int格式强制转换为long long 格式,如果不经过此转换,将听不到声音!
5.性能损耗比较及估值
5.1比较方法:
将MP3解码功能放入FreeRTOS的一个进程,然后查看此进程的CPU使用率,先后对比使用汇编和C实现底层的CPU占用率。
5.2估值方法:
已知测试平台处理器在额定工作频率下的性能,乘以CPU占用率得出运行此解码库需要的最小性能。
5.3开始测试:
测试曲目为:阿肆 - 热爱105°C的你.mp3
其比特率为320kpbs是MP3常见文件的最高规格。
测试平台为:STM32H743VBT6,其处理器为Cortex-M7,工作频率480MHZ,性能为1027DMIPS
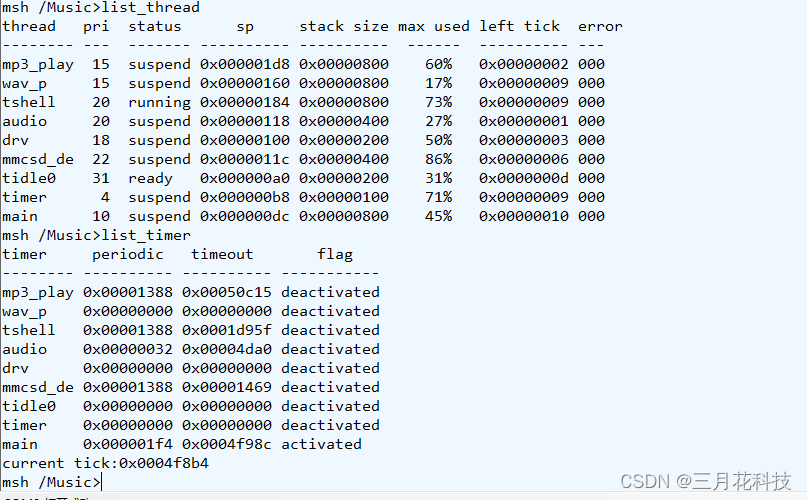
使用C实现底层的情况如下图,可见CPU占用率15%
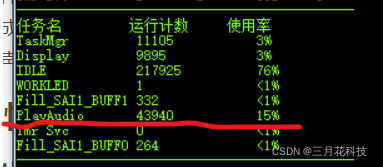
使用原版ARM汇编指令实现底层的情况如下图,可见CPU占用率5%
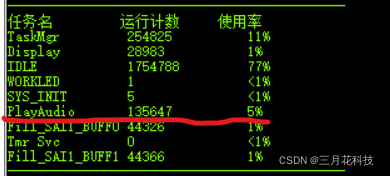
功能确实是实现了,但是性能的损耗为此前的3倍。
由此计算可得:
使用汇编实现底层时,至少需要处理器的性能为1027DMIPS * 5% = 51.35DMIPS
使用C实现底层时,至少需要处理器的性能为1027DMIPS * 15% = 154.05DMIPS
这也从侧面证明了为什么MP3解码可以在STM32F103上跑起来(STM32F103处理器为Cortex-M3工作频率为72MHZ,性能90DMIPS)
6.成果实践
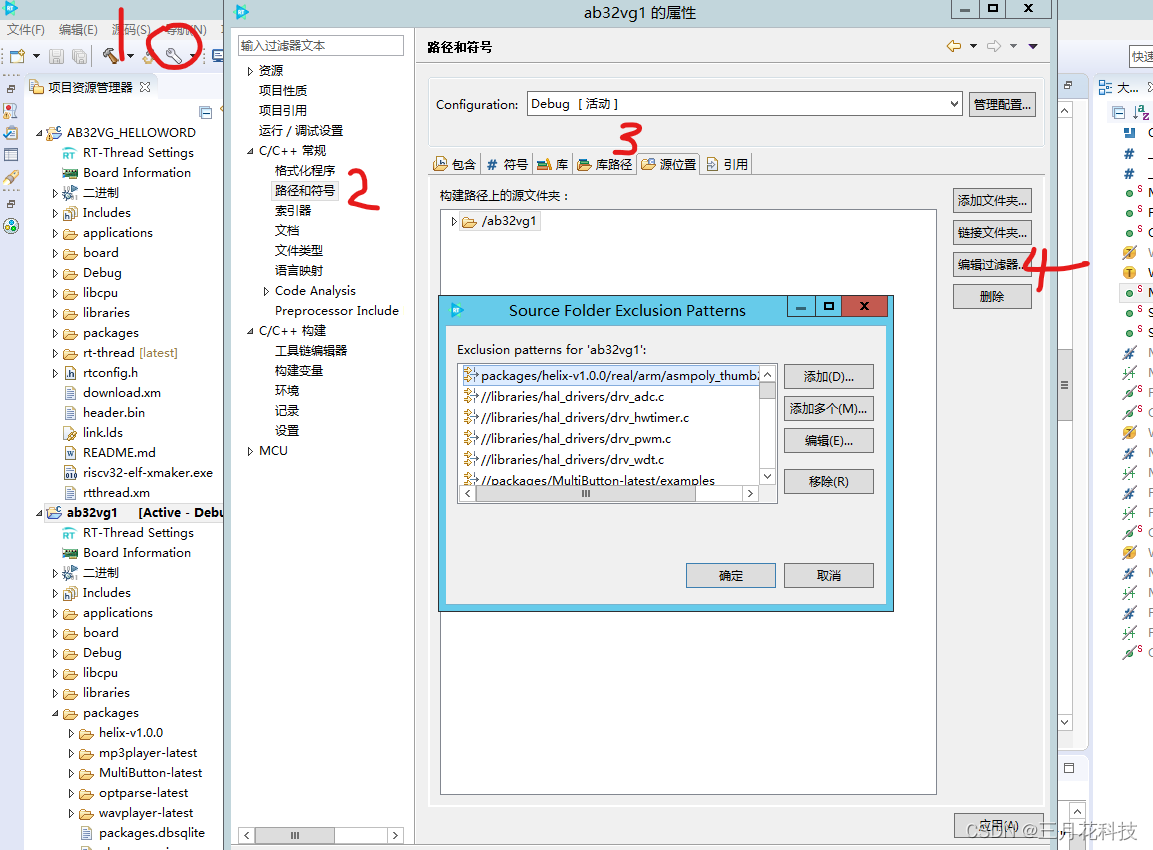
回到最初的RT-Thread Studio和中科蓝汛的AB32VG1的工程中,如法炮制修改代码
注意:RT-Thread Stduio与KEIL5在工程源文件的管理方式上截然不同,RT-Thread Stduio会显示工作空间的所有源文件,不想加入工程编译又不愿意删除的需要通过文件过滤器过滤掉。文件过滤器的操作流程如下。我们需要用文件过滤器过滤掉两个汇编源文件,并且找到过滤器中文件polyphase.c的配置项,并点击移除,即可在工程中看到C语言实现的底层文件polyphase.c
默认情况下,编译会报错,仔细看是data段内存溢出,修改link.lds文件即可,既然说data段不够,那就把另外几个改小一点,给data段多给一点,笔者的设置如下,仅供参考。

修改后,编译通过
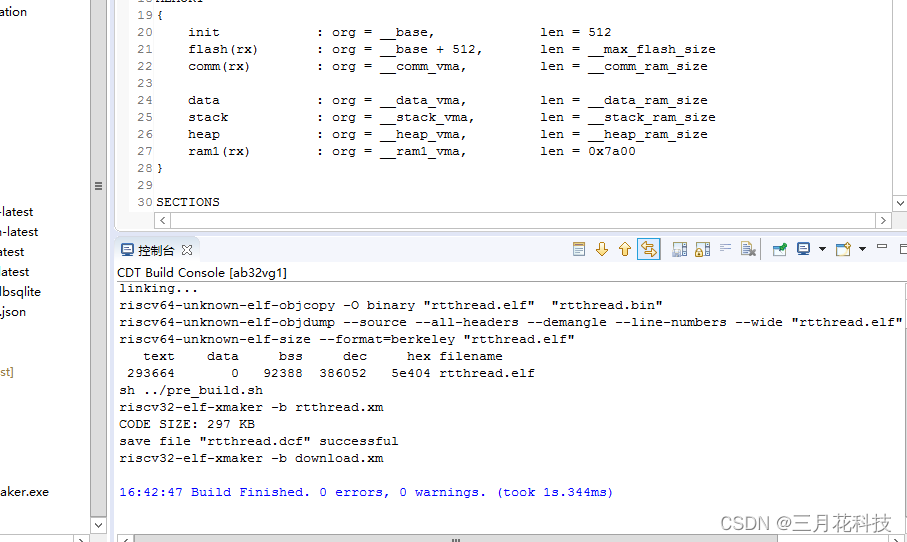
下载,启动并成功挂载SD卡
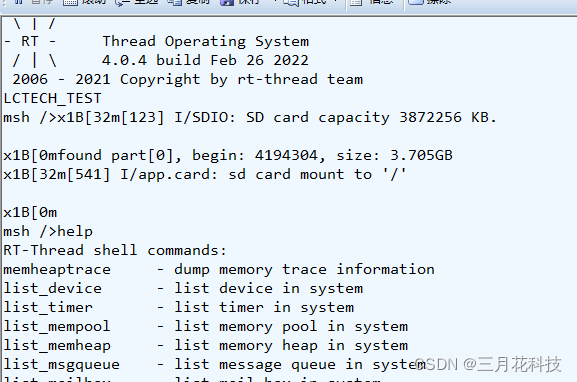
MP3播放器功能
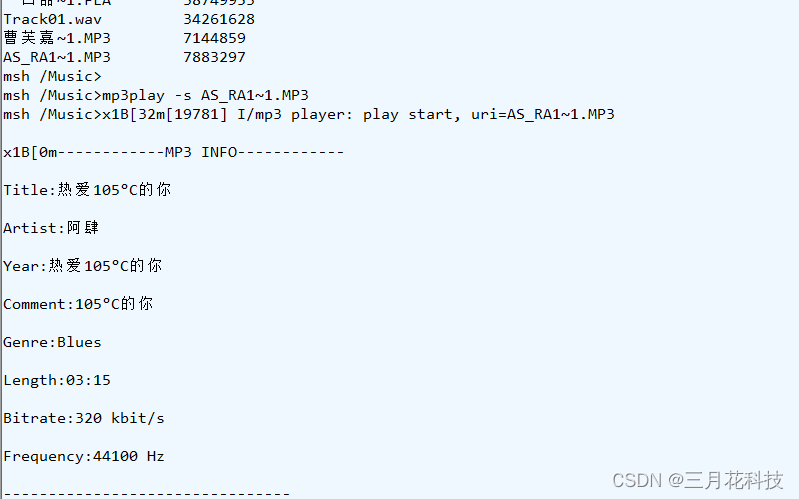
成功播放,至此在国产单片机上移植Helix的小心愿实现。虽然实际播放的效果很差,很卡,毕竟前面计算过,运行此C语言实现底层的解码库,至少需要154.05DMIPS,而AB32VG1的主频只有120MHZ,如果需要运行起此解码库,处理器的效率必须大于1.28DMIPS/MHZ。(Cortex-M3和M4为1.25DMIPS/MHZ,Cortex-M7为2.14DMIPS/MHZ)


















 1710
1710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









