







题目:Knowledge-aware Graph Neural Networks with Label Smoothness Regularization for Recommender Systems
作者:Hongwei Wang
文章目录
Abstract
知识图谱能够捕获实体或item之间的关系,缓解稀疏性,改善推荐系统的性能。
以往利用知识图谱做推荐大多依靠特征工程,本文提出了具有标签平滑正则化的知识感知图神经网络
- 首先利用一个可训练的函数计算item embedding,把知识图转化为加权图(特定用户的)【为了解释KG中的关系异质性】
- 用图神经网络计算个性化item embeddings【为什么计算、如何计算】
- 依赖于平滑假设,提供归纳偏差【用来干嘛】
Introduction
介绍推荐系统,引出稀疏性和冷启动问题
介绍知识图(捕捉结构化信息和一组实体之间的关系。通过不同类型的关系提供项目之间的连接信息,从而捕获项目之间的语义关联)
如何在推荐系统中使用KGs。核心挑战是如何获取KG所定义的用户特定项和项关系(做第2步的原因)。现有方法分为基于路径、基于嵌入和混合方法,均依赖人工特征,扩展性差。发现GNNs架构很有前途,但是现有方法都针对同质的二部用户项目交互图,如何扩展到异构知识图?为了解决问题,提出本文模型。将GNNs体系结构扩展到知识图谱,同时捕获项目之间的语义关系和用户个性化偏好。
- KG->加权图,描述了KG的语义信息和用户的个性化兴趣。与传统方式的区别是边权值不是按照实际给出,而是使用关系评分函数设置,以监督方式进行训练(关系评分函数可以知道给定用户更关注电影的导演是谁,还是更关注男主角是谁)。监督信号的唯一来源是用户项目交互(很稀疏),为了解决这个稀疏性问题,开发了一种在学习过程中对边缘权值正则化的技术,从而获得更好的泛化效果。
- 利用该加权图,通过图神经网络,在项目节点的局部网络领域上聚集节点特征信息来计算每个项目节点的embedding,每个项目的embedding以用户个性化的方式捕捉其本地KG结构。
- 开发了一种基于标签平滑度的方法,假设KG中的相邻实体可能具有相似的偏好,并证明标签平滑正则化和标签传播是等价的。设计了一个标签传播的留守损失函数,学习边缘评分函数额外提供的监督信号。证明了在同一框架下,知识感知图神经网络可以和标签平滑正则化统一起来,其中标签平滑可以看作是知识感知图神经网络正则化的自然选择。
总结:KG->加权图,再通过GNN得到项目节点embedding。用评分函数设置边权值,评分太少容易过拟合,提出标签平滑度方法。证明:标签平滑度正则化等价标签传播,为学习边缘评分函数额外监督信息设计标签传播的留守损失函数。
Problem Formulation
一组用户
U
\mathcal{U}
U、一组项目
V
\mathcal{V}
V、用户-项目交互矩阵
Y
\mathsf{Y}
Y(隐反馈),
y
u
v
=
1
y_{uv}=1
yuv=1代表用户
u
u
u参与了项目
v
v
v,知识图
G
=
(
h
,
r
,
t
)
\mathcal{G}={(h,r,t)}
G=(h,r,t),
h
∈
E
,
r
∈
r
,
t
∈
E
h∈E,r∈r,t∈E
h∈E,r∈r,t∈E代表知识三元组的头、关系、尾。例如(沉默的羔羊,电影明星,安东尼霍普金斯)这个三元组描述了安东尼霍普金斯是电影沉默的羔羊当中的一位明星。
给定用户-项目交互矩阵
Y
\mathsf{Y}
Y和知识图
G
\mathcal{G}
G,我们的任务是预测用户
u
u
u是否对他之前未参与过的项目
v
v
v感兴趣。
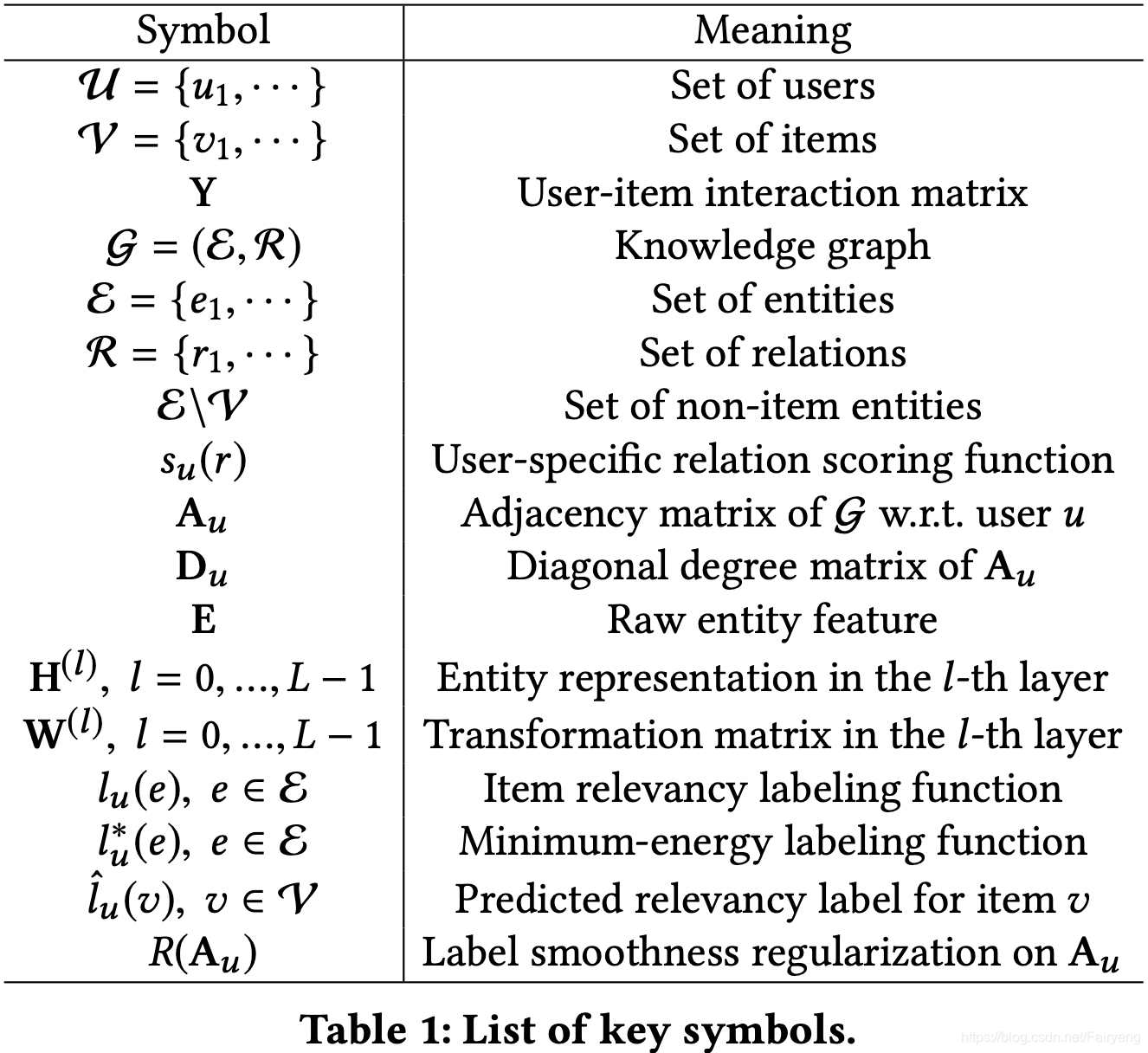
文章中使用到的符号在下表中给出定义:
Our Approach
知识感知图神经网络
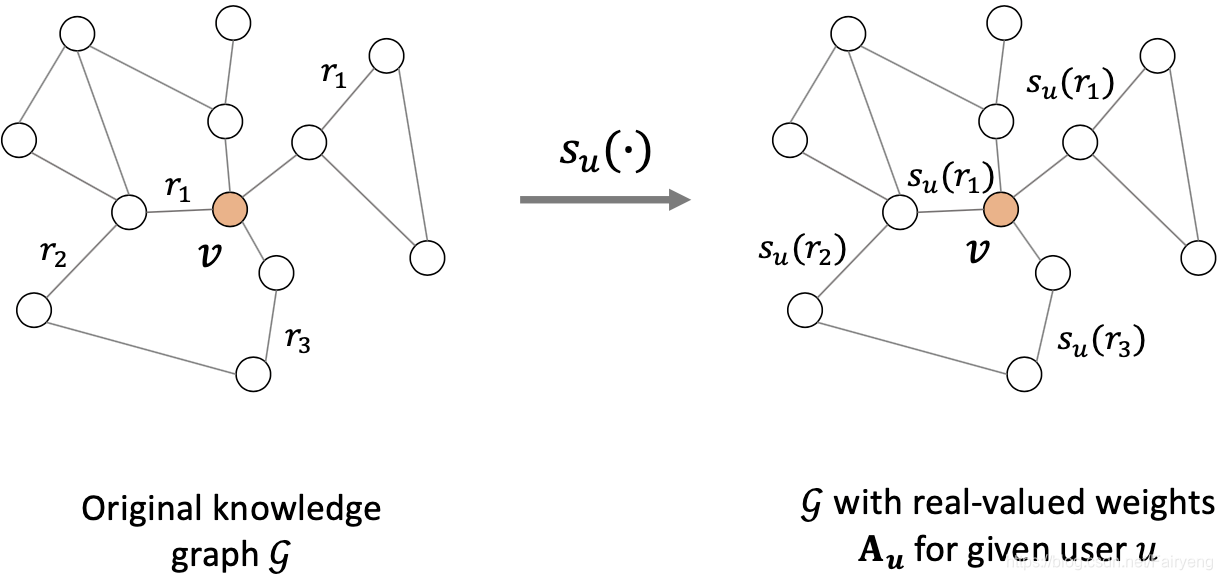
将一个异构的KG转换为一个一个描述用户偏好的个性加权图。
使用了一个用户特定的关系评分函数
s
u
(
r
)
s_u(r)
su(r),该函数为用户
u
u
u提供了关系
r
r
r的重要性(用户可能更偏好一部电影的导演而不是演员),
s
u
(
r
)
=
g
(
u
,
r
)
s_u(r)=g(\bf u,r)
su(r)=g(u,r),
g
g
g是可微函数,如内积。其中
u
\bf u
u和
r
\bf r
r是用户
u
u
u和关系类型
r
r
r的特征向量【文献28】
通过这个关系评分函数,知识图
G
\mathcal{G}
G可以转化为用户特有的邻接矩阵
A
u
∈
R
∣
ε
∣
×
∣
ε
∣
\bf A_u∈\Bbb R^{|\varepsilon|\times|\varepsilon|}
Au∈R∣ε∣×∣ε∣,
A
u
i
j
=
\bf A_u^{ij}=
Auij=
s
u
(
r
e
i
,
e
j
)
s_u(r_{e_i,e_j})
su(rei,ej),这里的
r
r
r指的是实体
e
i
e_i
ei与
e
j
e_j
ej的关系。
原始的实体特征矩阵为
E
∈
R
∣
ε
∣
×
d
0
{\bf E}∈\Bbb R^{|\varepsilon|\times d_0}
E∈R∣ε∣×d0,
d
0
d_0
d0是实体特征(entity feature)的维度,使用多个前馈层,聚合相邻实体表示,更新实体表示矩阵,可以表示为:
H
l
+
1
=
σ
(
D
u
1
/
2
A
u
D
u
1
/
2
H
l
W
l
)
,
l
=
0
,
1
,
.
.
.
,
L
−
1
(
1
)
{\bf H}_{l+1}=\sigma({\bf D}_u^{1/2}{\bf A}_u {\bf D}_u^{1/2}{\bf H}_l {\bf W}_l), l=0,1,...,L-1 \qquad(1)
Hl+1=σ(Du1/2AuDu1/2HlWl),l=0,1,...,L−1(1)
其中, H 0 = E {\bf H}_0={\bf E} H0=E,这里 H l {\bf H}_l Hl就是实体在 l l l层的隐表达, A u {\bf A}_u Au就是对相邻实体表示进行聚合,并给每个实体添加self-connection ( A u ⟸ A u + I ) ({\bf A}_u\impliedby{\bf A}_u+{\bf I}) (Au⟸Au+I),确保实体更新时考虑到了自己本身的旧表示
上面这个公式是GCN的更新公式
关于这个公式的前世今生这个文章真的讲的特别好
G
\mathcal{G}
G是一个无向图,
A
u
{\bf A}_u
Au是一个对称矩阵,
D
u
{\bf D}_u
Du是一个斜对角矩阵,可计算。
D
u
1
/
2
{\bf D}_u^{1/2}
Du1/2用来规范化
A
u
{\bf A}_u
Au并保持实体表示矩阵
H
l
{\bf H}_l
Hl的稳定性,
W
l
{\bf W}_l
Wl为特定层可训练权重矩阵。
我们可以自然地将模型拓展到多层,以更广泛和更深入的方式探索用户的潜在兴趣,最后的输出是
H
l
{\bf H}_l
Hl,他混合了自身初始特征及l跳的领域特征。
最后由
y
^
u
v
=
f
(
u
,
v
u
)
\hat{y}_{uv}=f({\bf u,v}_u)
y^uv=f(u,vu),计算项目
u
u
u与
v
v
v的接触概率。
v
u
{\bf v}_u
vu就是
H
l
{\bf H}_l
Hl的第
v
v
v行(用户特定的),也是item
v
v
v的最终表示。
f
f
f是一个预测函数(可微,例如内积或多层感知器)。系统是端到端可训练的。
标签平滑正则化
模型与GNN的区别在于:传统GNN中,输入图的边缘权重是固定的,但在文章中,等式(1)中的边缘权重
D
u
1
/
2
A
u
D
u
1
/
2
{\bf D}_u^{1/2}{\bf A}_u {\bf D}_u^{1/2}
Du1/2AuDu1/2是可学习的(包括函数
g
g
g当中的可能参数、用户与关系的特征向量),还需要监督训练。但是监督的唯一信号来源是GNN层外的用户-项目交互,因此很容易过拟合。但是呢,边缘权重在图的表示学习中又有着很重要的作用【文献10,20,21,35,38都提出此观点】,因此就需要对边缘权值进行更规范化的处理,以便更好地学习实体表示去找到那些未被观察到的交互作用。
理想的边缘权重是,我们希望KG中的相邻实体都尽可能有相似的标签,这就是所谓的标签平滑假设。那么我们考虑知识图
G
\mathcal{G}
G上的一个real- valued label 函数
l
u
:
ε
→
R
l_u:\varepsilon\rightarrow \Bbb R
lu:ε→R,如果用户
u
u
u发现项
v
v
v并与之相关,则
l
u
(
v
)
=
1
l_u(v)=1
lu(v)=1,否则
l
u
(
v
)
=
0
l_u(v)=0
lu(v)=0。标签平滑性假设促使我们选择能量函数
E
E
E:
E
(
l
u
,
A
u
)
=
1
2
∑
e
i
∈
ε
,
e
j
∈
ε
A
u
i
j
(
l
u
(
e
i
)
−
l
u
(
e
j
)
)
2
(
2
)
E(l_u,{\bf A}_u)=\frac{1}{2}\sum_{e_i∈\varepsilon,e_j∈\varepsilon}A_u^{ij}(lu(e_i)-l_u(e_j))^2 \qquad(2)
E(lu,Au)=21ei∈ε,ej∈ε∑Auij(lu(ei)−lu(ej))2(2)
这里用到的定理是:能量越小系统越稳定
(能量函数)
根据该定理,我们接下来要最小化能量函数
l
u
∗
=
a
r
g
m
i
n
l
u
:
l
u
(
v
)
=
y
u
v
,
∀
v
∈
V
E
(
l
u
,
A
u
)
(
3
)
l_u^*=argmin_{l_u:l_u(v)=y_{uv},\forall v∈\mathcal V} E(l_u,{\bf A}_u ) \qquad(3)
lu∗=argminlu:lu(v)=yuv,∀v∈VE(lu,Au)(3)
最后得到的结果是
l
u
∗
(
e
i
)
=
1
∑
j
A
u
i
j
∑
j
A
u
i
j
l
u
∗
(
e
j
)
=
1
D
u
i
j
∑
j
A
u
i
j
l
u
∗
(
e
j
)
,
∀
e
i
∈
ε
∖
V
l_u^*(e_i)=\frac{1}{\sum_{j}A_u^{ij}}\sum_{j}A_u^{ij}l_u^*(e_j)=\frac{1}{D_u^{ij}}\sum_{j}A_u^{ij}l_u^*(e_j),\forall e_i∈\varepsilon \setminus \mathcal V
lu∗(ei)=∑jAuij1j∑Auijlu∗(ej)=Duij1j∑Auijlu∗(ej),∀ei∈ε∖V
谐波性质表明,在每个非item的实体项
e
i
e_i
ei处
l
u
∗
l_u^*
lu∗的值是其相邻实体的平均值,这导致了下面的标签传播方案:
- 为所有实体传播标签
- 将所有item标签重置为初始值
以上方案提供了一种达到标签函数的最小能量
E
E
E的方法。然而,
l
u
∗
l_u^*
lu∗不提供任何用于更新边权重矩阵
A
u
{\bf A}_u
Au的东西,因为
l
u
∗
l_u^*
lu∗的标记部分,即
l
u
∗
(
V
)
l_u^*(\mathcal V)
lu∗(V)等于它们的真实相关性标签
Y
[
u
,
V
]
{\bf Y}[u,\mathcal V]
Y[u,V];
此外,对于未标记的节点,我们不知道真正的相关标签
l
u
∗
(
ε
∖
V
)
l_u^*(\varepsilon \setminus \mathcal V)
lu∗(ε∖V)。因此提出了最小化留一损失(leave-one-out loss)。假设我们拿出一个单独的item
v
v
v不加标记地处理它,然后利用剩余的item(有标签的)和非item实体(无标签的)来预测那个item
v
v
v,预测过程与标签传播方案相同,只是item
v
v
v的标签需要计算,这样item
v
v
v的真实相关性标签
y
u
v
y_uv
yuv和预测标签
l
^
u
(
v
)
\hat {l}_u(v)
l^u(v)之间的差异就可以用来作为规范边缘权重的监督信号。
R
(
A
)
=
∑
u
R
(
A
u
)
=
∑
u
∑
v
J
(
y
u
v
,
l
^
u
(
v
)
)
(
7
)
R({\bf A})=\sum_{u}R({\bf A}_u)=\sum_{u}\sum_{v}J(y_{uv},\hat{l}_u(v)) \qquad (7)
R(A)=u∑R(Au)=u∑v∑J(yuv,l^u(v))(7)
J
J
J是交叉熵损失函数,式(7)中的正则化,理想边缘权重矩阵
A
\bf A
A应该再现每个held out item真实标签,同时满足标签的平滑度。
统一损失函数
将知识感知图神经网络和标签正则化相结合,得到如下完全损失函数
m
i
n
W
,
A
=
m
i
n
W
,
A
∑
u
,
v
J
(
y
u
v
,
y
^
u
v
)
+
λ
R
(
A
)
+
γ
∣
∣
F
∣
∣
2
2
,
(
8
)
min_{{\bf W,A}}=min_{{\bf W,A}}\sum_{u,v}J(y_{uv},\hat{y}_{uv})+\lambda R({\bf A})+\gamma||\mathcal F||_2^2,\qquad (8)
minW,A=minW,Au,v∑J(yuv,y^uv)+λR(A)+γ∣∣F∣∣22,(8)
第一项对应于GNN种同时学习变换矩阵
W
\bf W
W和边权值
A
\bf A
A的部分(可以看作是KG上的feature传播);第二项
R
(
⋅
)
R(\sdot)
R(⋅)对应标签平滑部分,可以看作是对边权值
A
\bf A
A添加约束的部分(可以看作是KG上的label传播),也就是作用于
A
\bf A
A上的正则化辅助GNN学习边权值;
∣
∣
F
∣
∣
2
2
||\mathcal F||_2^2
∣∣F∣∣22是L2正则化项。
针对特定用户
u
u
u的推荐实际上就是从item features到用户-项目交互标签的映射,即
F
u
:
E
v
→
y
u
v
{\mathcal F}_u:{\bf E}_v \rightarrow y_{uv}
Fu:Ev→yuv,其中
E
v
{\bf E}_v
Ev代表item feature,式(8)利用
F
u
{\mathcal F}_u
Fu特征和标签的KG结构信息来捕获用户的高阶偏好。
Discussion
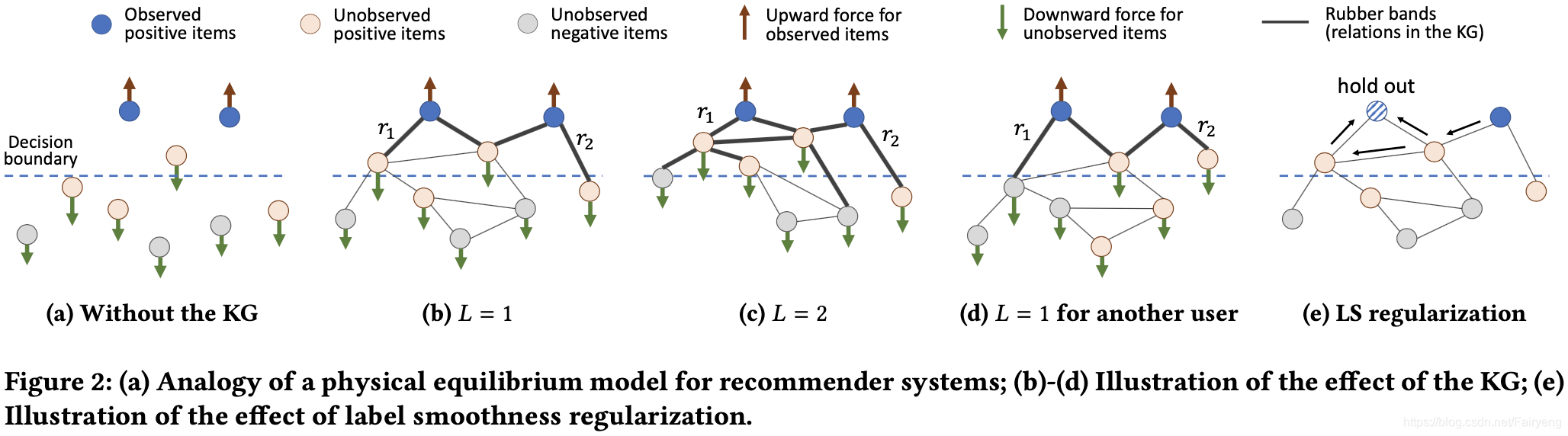
为了更加直观地理解KG的作用,用物理平衡模型做一个类比。每个item/entity被看作是一个粒子,被监督的positive user-relevancy acts被看作是从决策边界向上拉的力,negative item signal acts作为未观察项目向下推的力。
如果没有KG(图2a),这些项目通过协同过滤相互松散的连接。而KG中的边相当于橡皮筋,对连接的实体施加明确的约束。当层数
l
=
1
l=1
l=1(图2b)时,每个实体的表示都是自己和其近邻的混合。因此对positive item进行优化将把他们的近邻拉到一起。随着
L
L
L的增加,KG中向上的力变得越深,有助于探索用户的深层兴趣。
KG中施加的接近约束是个性化的,因为橡皮筋的强度(即
s
u
(
r
)
s_u(r)
su(r))是基于特定用户和特定关系的,如2b和2d中,一个用户可能更喜欢关系
r
1
r_1
r1,另一个用户可能更喜欢关系
r
2
r_2
r2。
尽管KG中边缘施加了力,但边缘权重的设置可能不恰当。(太小无法拉起未观察到的物品(橡皮筋太弱)),2e展示了标签平滑度假设如何帮助规则化边缘化边缘权重的学习,假设留一为左上角条纹item,我们想用剩余的其他item来复现条纹item的标签。由于条纹item的真实标签为1,且右上角样本的标签值最大,正则化项
R
(
A
)
R(\bf A)
R(A)强制带有箭头的边变大,这样标签就可以尽可能地从蓝色流动到条纹,这样会收紧橡皮筋然后鼓励模型拉起粉色项。
Experiment
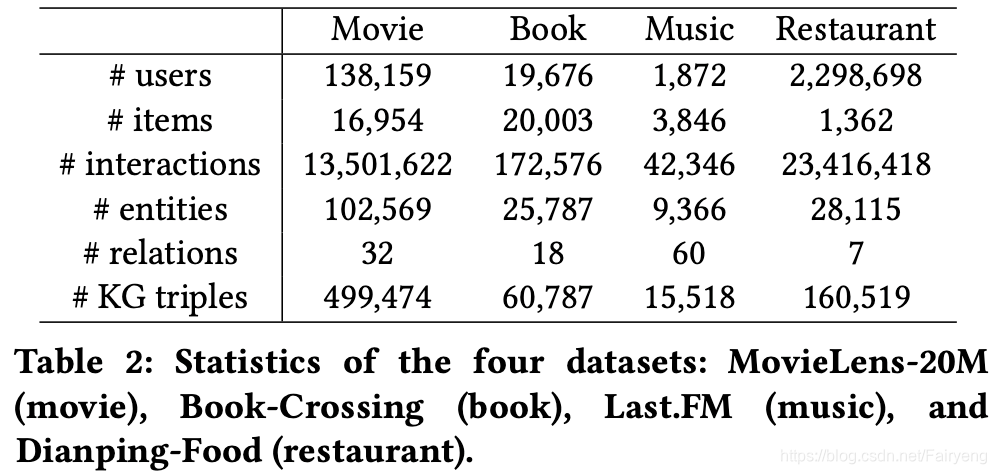
在电影(MovieLens-20M^3)、书籍(Book-Crossing)、音乐(Last.FM)、餐厅(Dianping-Food(由美团点评内部工具箱构建))四个真实场景评估文章模型性能
数据集
Baselines
- SVD:经典的基于协同过滤的模型,利用点积建模user与item的交互。文章中用的是无偏版本(公式y_uv=u^Tv)
- LibFM:基于特征的因子分解模型用于CTR预测,连接user ID和item ID作为LibFM的输入,维度设置{1,1,8},所有数据训练周期为50
- LibFM+TransE:在每个user-item对上附加一个由TransE获得的实体表示来扩展LibFM。TransE的用到的数据维度是32
- PEPR:基于路径的方法的代表,将KG视为异构信息网络,基于特征提取元路径来表示拥护和项目之间的连接。手动设计“user-item-attribute-item”作为元路径,(例“user-movie-director-movie”,“user-book-author-book”…)
- CKE:基于嵌入的方法的代表,它把协同过滤和结构化、文本、视觉知识结合在一个统一的框架当中,文章中实现方式是CF+一个知识结构模块。
- RippleNet:混合方法的代表,memory- network-like方法,将用户的偏好在KG上传播以便推荐。
Validating the connection between G and Y
为了验证知识图
G
\mathcal G
G和用户-项目交互
Y
\bf Y
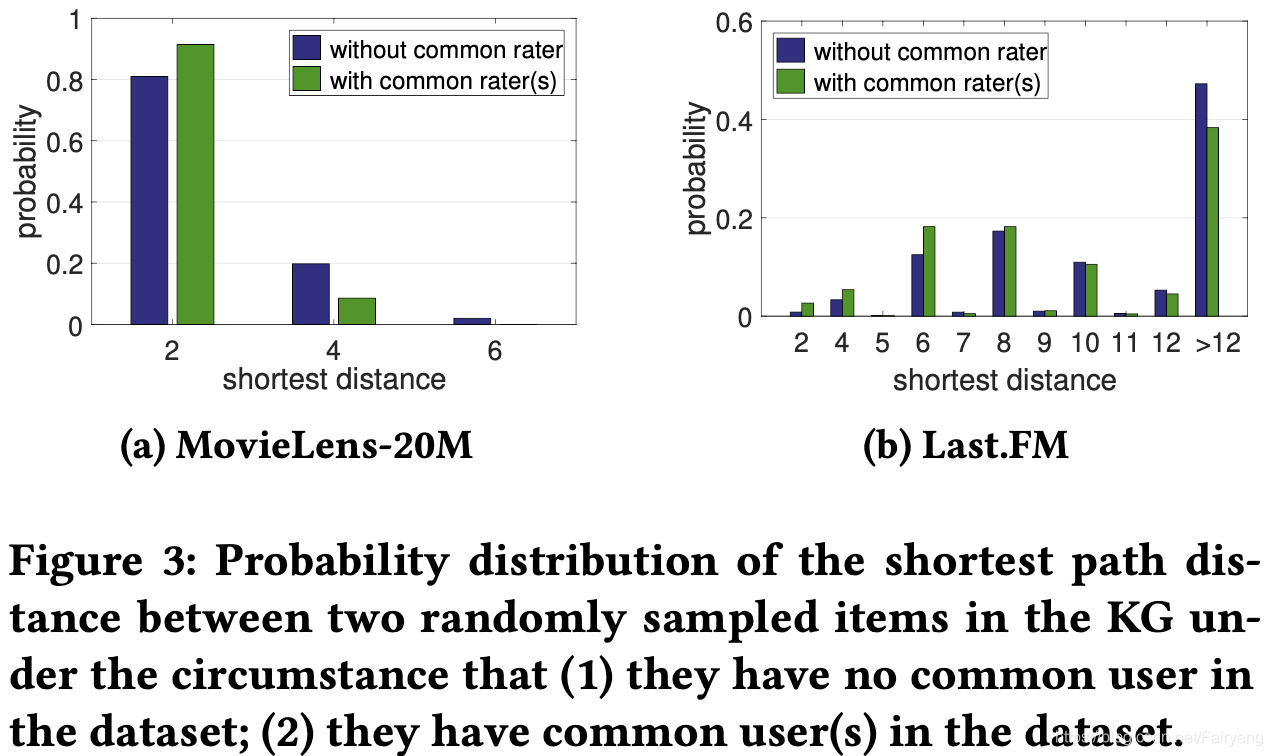
Y之间的关系,考察了KG中两个随机抽样的item的最短路径距离和他们在数据集中是否有共同user(即是否存在与这两个item都交互的用户)的相关性。对于数据集MovieLens-20M和Last.FM,随机抽取一万个没有公共用户的item pairs和一万个至少有一个公共用户的item pairs,然后在KG中统计他们的最短路径距离分布。如图3,如果两个item在数据集中有公共用户,那么他们会在KG中更接近。例如,如果两部电影在MovieLens-20M中有公共用户,那么他们在KG中的两跳内的概率为0.92,否则这个概率则降到0.8。这证明可以利用KG的邻近结构帮助推荐,也证明了文章中使用标签平滑正则化帮助学习实体表示的动机。
Results
-
comparison with baseline
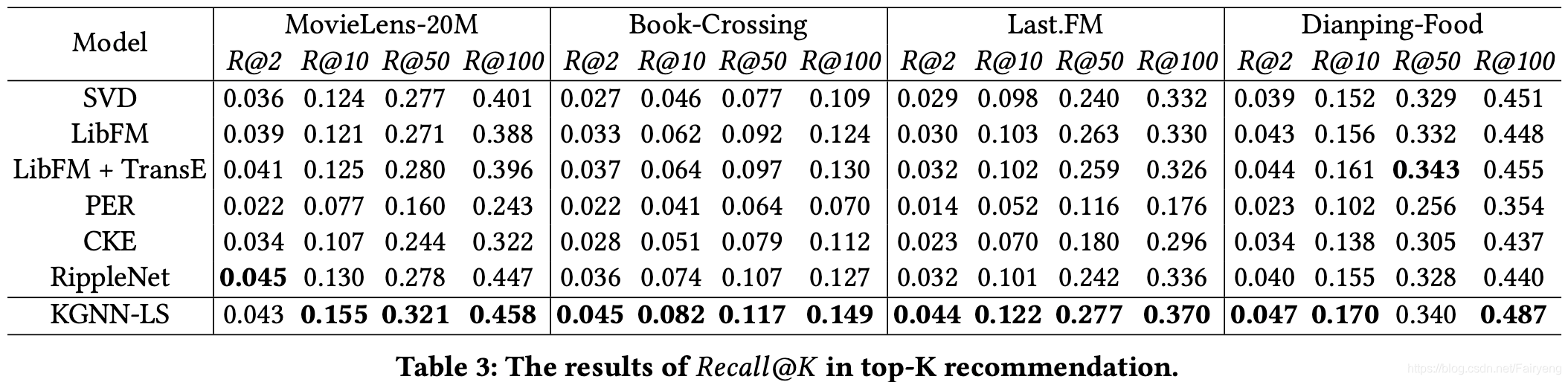
在top- k k k推荐中我们使用训练好的模型为测试集当中的每个用户选择 k k k个预测点击率最高的羡慕,然后使用 R e c a l l @ k Recall@k Recall@k去评估
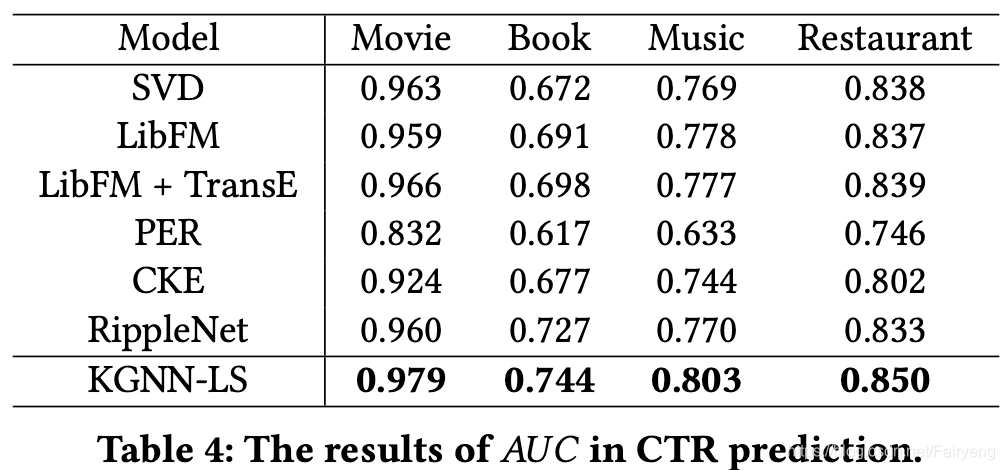
在点击率预测中,应用训练好的模型来预测测试集中的每一对user-item pairs(包括positive items和随机选择的negative items),使用 A U C AUC AUC作为CTR预测的指标。
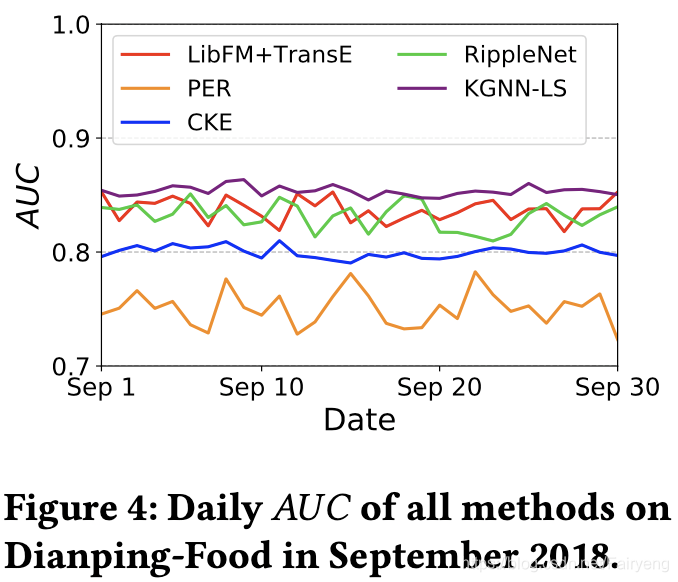
展示了KGNN-LS和基线在dianping-food上的日常表现,以考察其稳定性。下图展示了从18年9月1日到18年9月30的AUC的粉,测试期间KGNN-LS始终高于基线,且KGNN-LS的性能方差较小,说明有较强的鲁棒性和稳定性
-
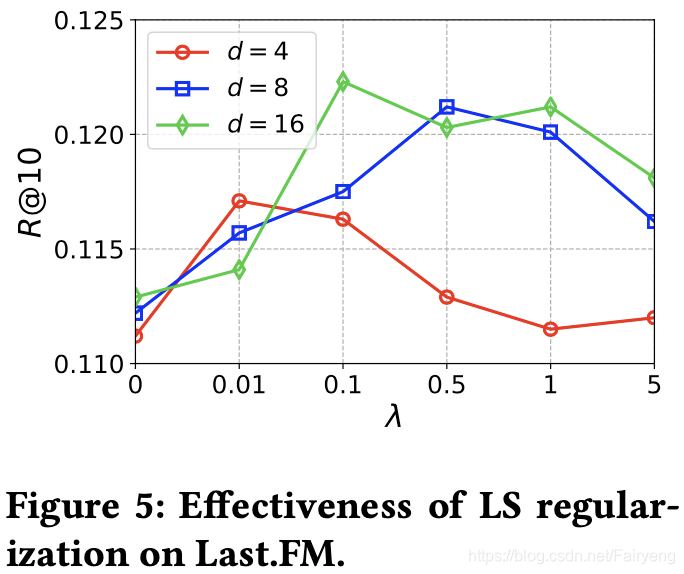
LS正则化的有效性
固定隐层的维数,变换lamda的值观察性能的变化,显然非零的lambda比0的性能要好【28】,证明了正则化的有效性,但太大的lambda会误导梯度方向
-
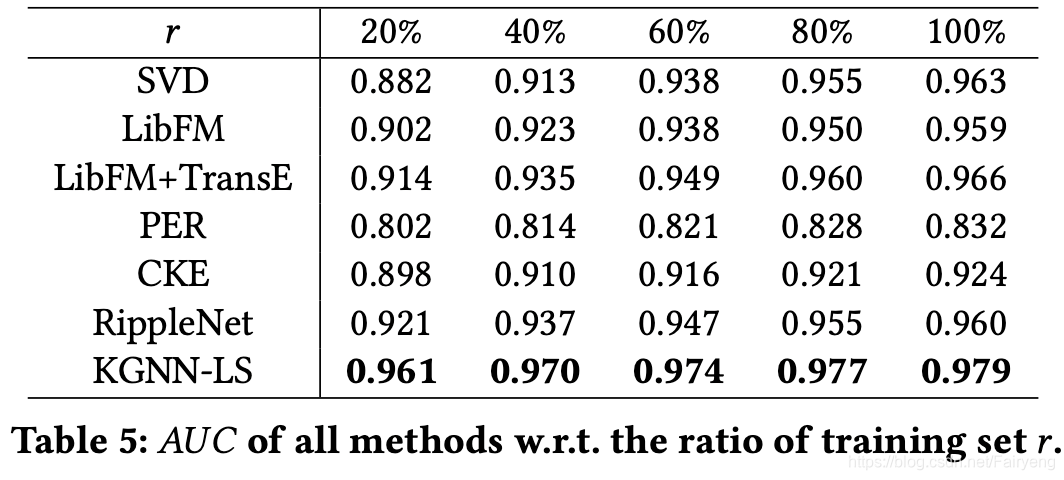
冷启动情况下的效果
我们将MovieLens-20M的训练集大小从 r = 100 r=100% r=100变化到 r = 20 r=20% r=20(同时验证集和测试集保持不变),并将AUC的结果报告在表5中。当 r = 20 r=20% r=20时,6条基线的AUC分别比完全训练数据( r = 100 r=100% r=100)训练的模型下降8.4%、5.9%、5.4%、3.6%、2.8%和4.1%,而KGNN-LS的性能下降仅为1.8%。这表明即使在用户项交互很少的情况下,KGNN-LS仍然保持预测性能。
-
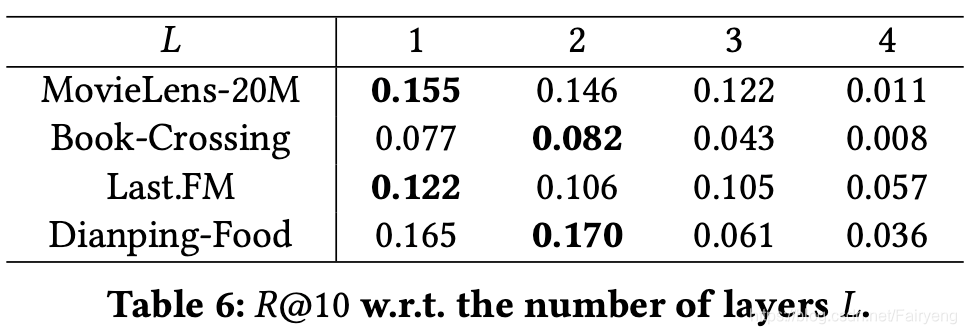
超参数灵敏度
分析了KGNN-LS对GNN层数 L L L的敏感性,我们在保持其他超参数不变的情况下,将 L L L从1变为4。结果见表6。我们发现当 L = 4 L=4 L=4时,模型的性能很差,这是因为较大的 L L L会混合太多的实体embedding,在给定的实体中,这会过度平滑KGs上的表示学习。当 L = 1 L=1 L=1或 2 2 2时,KGNN-LS的性能最好。
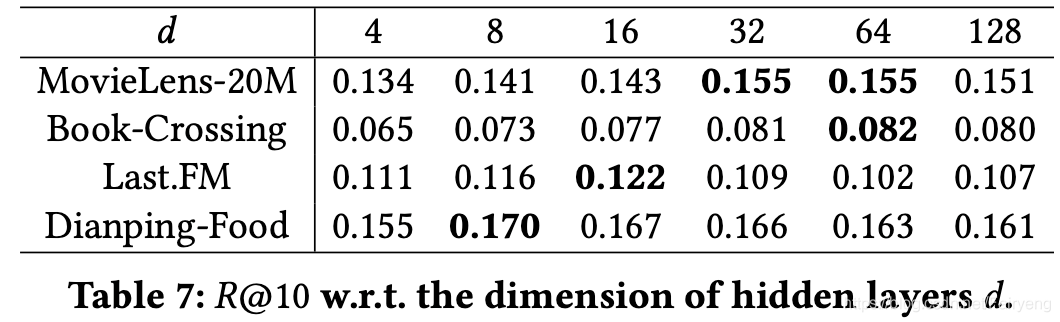
研究了隐藏层 d d d的维数对KGNN-LS性能的影响。结果如表7所示。由于隐藏层中更多的 d d d以提高模型的容量,所以在开始时随着 d d d的增加,性能得到了提高。但是,当 d d d进一步增加时,性能会下降,因为过大的维度可能会过度拟合数据集。当 d = 8 ∼ 64 d=8∼64 d=8∼64时,性能最佳。
-
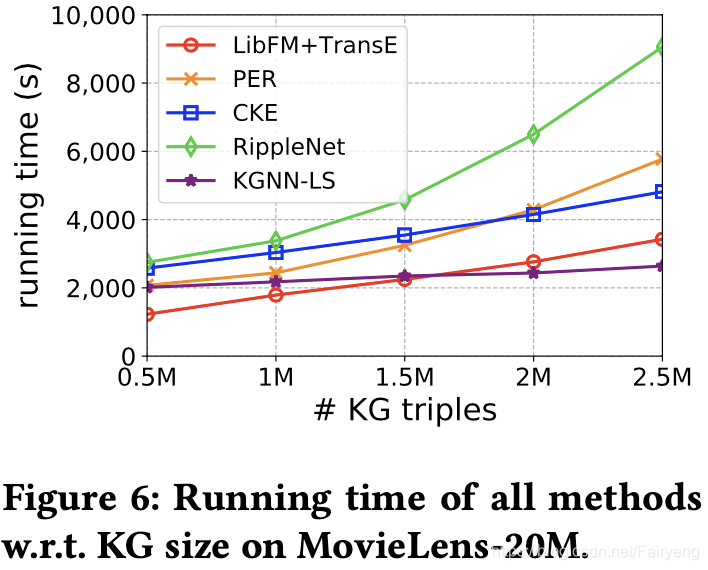
运行时间分析
研究了我们的方法对于KG大小的运行时间。我们在一台微软Azure虚拟主机上运行实验,该机器配有1台NVIDIA Tesla M60 GPU、12台Intel Xeon CPU(E5-2690 v3@2.60GHz)和128GB RAM。通过从Satori中提取更多的三倍体,KG的大小增加了五倍,MovieLens-20M上所有方法的运行时间如图6所示。请注意,曲线的趋势比实际值更重要,因为这些值在很大程度上取决于小批量的大小和时间段的数量(但我们确实尝试调整所有方法的配置)。结果表明,即使在KG较大的情况下,KGNN-LS仍具有很强的可扩展性。
(这可能是我今年读的最久的一篇论文了,学新东西真的好累)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









