







1.实例描述
通过一个计算学生平均成绩的例子来讲解开发MapReduce程序的流程。输入文件都是纯文本文件,输入文件中的每行内容均为一个学生的姓名和他相应的成绩,如果有多门学科,则每门学科为一个文件。输出文件每行包含学生的姓名和平均成绩。下面给出样本输入文件,以及跑MapReduce程序过后的输出文件。代码亲测可用。注意:本人的开发环境是在Ubuntu+Eclipse下跑的。
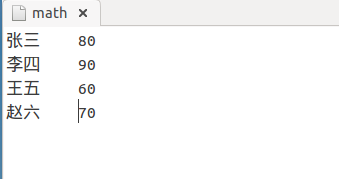
1)math
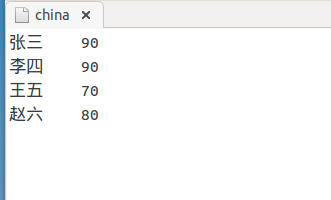
2)china
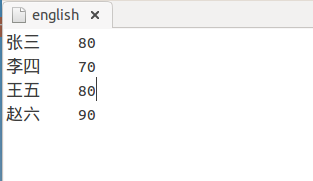
3)english
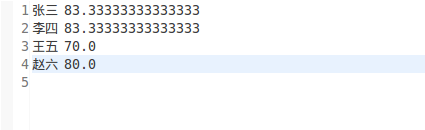
4)输出文件
2.程序代码
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class AvgScore {
public static class Map extends Mapper<Object, Text, Text, DoubleWritable>{
private static Text name = new Text();
private static DoubleWritable score = new DoubleWritable();
@Override
protected void map(Object key, Text value,Mapper<Object, Text, Text, DoubleWritable>.Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
// super.map(key, value, context);
String[] splits = value.toString().split("\t"); // 源文件一定要用tab键分割,不然会出错。
if(splits.length!=2){
return ;
}
name.set(splits[0]);
score.set(Double.parseDouble(splits[1]));
// System.out.println(name);
// System.out.println(score);
context.write(name, score);
}
}
public static class Reduce extends Reducer<Text, DoubleWritable, Text, DoubleWritable>{
private static DoubleWritable avg = new DoubleWritable();
@Override
protected void reduce(Text name, Iterable<DoubleWritable> scores,Reducer<Text, DoubleWritable, Text, DoubleWritable>.Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
// super.reduce(arg0, arg1, arg2);
double sum = 0;
int count = 0;
for(DoubleWritable score:scores){
sum += score.get();
count ++;
}
avg.set(sum/count);
// System.out.println(avg);
context.write(name, avg);
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// TODO Auto-generated method stub
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
if(otherArgs.length!=2){
System.out.println("Usage:Score Avg");
System.exit(2);
}
Job job = new Job(conf,"Score Avg");
job.setJarByClass(AvgScore.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(DoubleWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DoubleWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true)?0:1);
}
}3.程序解释
Mapper处理的数据是由InputFormat分解过的数据集,其中 InputFormat的作用是将数据集切割成小数据集InputSplit,每一个InputSlit将由一个Mapper负责处理。此 外,InputFormat中还提供了一个RecordReader的实现,并将一个InputSplit解析成<key,value>对提 供给了map函数。InputFormat的默认值是TextInputFormat,它针对文本文件,按行将文本切割成InputSlit,并用 LineRecordReader将InputSplit解析成<key,value>对,key是行在文本中的位置,value是文件中的 一行。
Map的结果会通过partion分发到Reducer,Reducer做完Reduce操作后,将通过以格式OutputFormat输出。
Mapper最终处理的结果对<key,value>,会送到Reducer中进行合并,合并的时候,有相同key的键/值对则送到同一个 Reducer上。Reducer是所有用户定制Reducer类地基础,它的输入是key和这个key对应的所有value的一个迭代器,同时还有 Reducer的上下文。Reduce的结果由Reducer.Context的write方法输出到文件中。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











