







数据去重这个实例主要是为了读者掌握并利用并行化思想对数据进行有意义的筛选。统计大数据集上的数据种类个数、从网站日志中计算访问等这些看似庞杂的任务都会涉及数据去重。下面就进入这个实例的MapReduce程序设计。
1.实例描述
对数据文件中的数据进行去重。数据文件中的每行都是一个数据。
样例输入:
file1:
2006-6-9 a
2006-6-10 b
2006-6-11 c
2006-6-12 d
2006-6-13 a
2006-6-14 b
2006-6-15 c
2006-6-11 c
file2:
2006-6-9 b
2006-6-10 a
2006-6-11 b
2006-6-12 d
2006-6-13 a
2006-6-14 c
2006-6-15 d
2006-6-11 c
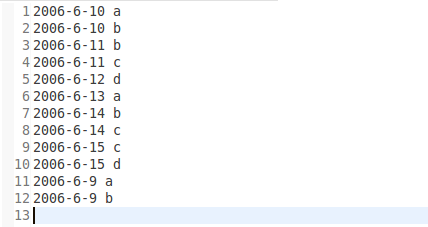
运行结果:
2.设计思路
数据去重实例的最终目标是让原始数据中出现次数超过一次的数据在输出文件中只出现一次。我们自然而然会想到将同一个数据的所有记录都交给一台Reduce机器,无论这个数据出现多少次,只要在最终结果中输出一次就可以了。具体就是Reduce的输入应该以数据作为key,而对value-list则没有要求。当Reduce接收到一个<key,value-list>时就直接将key复制到输出的key中,并将value设置成空值。在MapReduce流程中,Map的输出<key,value>经过shuffle过程聚集成<key,value-list>后会被交给Reduce。所以从设计好的Reduce输入可以反推出Map输出的key应为数据,而value为任意值。继续反推,Map输出的key为数据。而在这个实例中每个数据代表输入文件中的一行内容,所以Map阶段要完成的任务就是在采用Hadoop默认的作业输入方式之后,将value设置成key,并直接输出(输出中的value任意)。Map中的结果经过shuffle过程之后被交给Reduce。在Reduce阶段不管每个key有多少个value,都直接将输入的key复制为输出的key,并输出就可以了(输出中的value被设置成空)
3.程序代码:
程序代码如下:
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Dedup {
// map 将输入中的value复制到输出数据的key上,并直接输出
public static class Map extends Mapper<Object, Text, Text, Text>{
private static Text line = new Text();
@Override
protected void map(Object key, Text value,Mapper<Object, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
// super.map(key, value, context);
line = value;
context.write(line, new Text(""));
}
}
// reduce 将输入中的key复制到输出数据的key上,并直接输出
public static class Reduce extends Reducer<Text, Text, Text, Text>{
@Override
protected void reduce(Text key, Iterable<Text> values,Reducer<Text, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
// super.reduce(arg0, arg1, arg2);
context.write(key, new Text(""));
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
if(otherArgs.length!=2){
System.out.println("Usage:Score Avg");
System.exit(2);
}
Job job = new Job(conf,"Data Deduplication");
job.setJarByClass(Dedup.class);
job.setMapperClass(Map.class);
job.setCombinerClass(Reduce.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true)?0:1);
}
}

















 335
335











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











