






一、requests简介
简介:使用requests可以模拟浏览器的请求,比起之前用的urllib,requests模块的api更加便捷(本质就是封装了urllib3)
 https://www.bilibili.com/video/BV17p4y1B77x/?spm_id_from=333.337.search-card.all.click
https://www.bilibili.com/video/BV17p4y1B77x/?spm_id_from=333.337.search-card.all.click注意:requests库发送请求将网页内容下载下来以后,并不会执行js代码,这需要我们自己分析目标站点然后发起新的request请求
安装:pip3 install requests
各种请求方式:常用的就是requests.get()和requests.post()
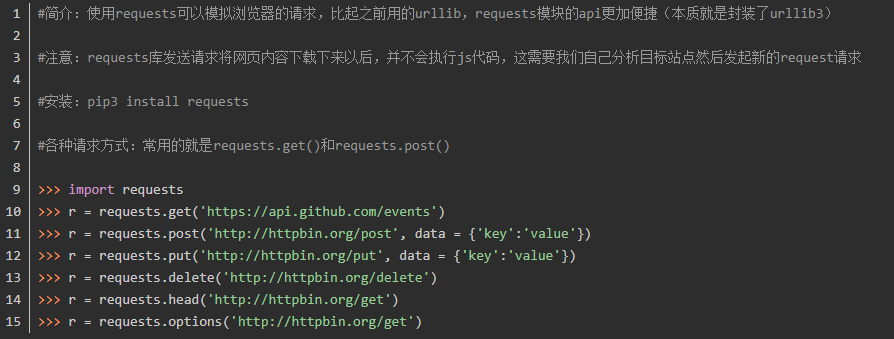
二 、基于requests之GET请求
1、基本请求

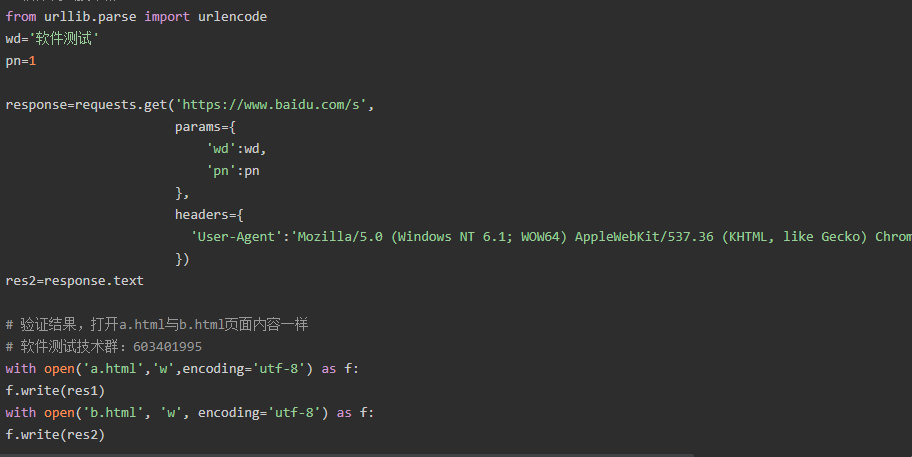
2、带参数的GET请求->params
在请求头内将自己伪装成浏览器,否则百度不会正常返回页面内容

如果查询关键词是中文或者有其他特殊符号,则不得不进行url编码
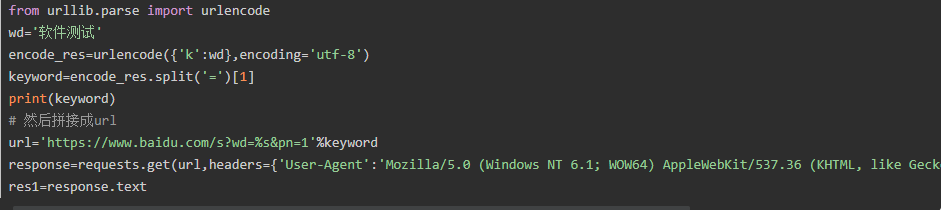
上述操作可以用requests模块的一个params参数搞定,本质还是调用urlencode
3、带参数的GET请求->headers
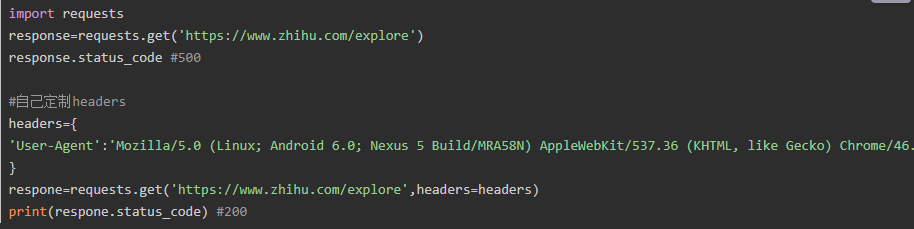
通常我们在发送请求时都需要带上请求头,请求头是将自身伪装成浏览器的关键,常见的有用的请求头如下

添加headers(浏览器会识别请求头,不加可能会被拒绝访问,比如访问
https://www.zhihu.com/explore)
4、带参数的GET请求->cookies
登录github,然后从浏览器中获取cookies,以后就可以直接拿着cookie登录了,无需输入用户名密码

三、基于POST请求
GET请求
HTTP默认的请求方法就是GET
1.没有请求体
2.数据必须在1K之内
3.GET请求数据会暴露在浏览器的地址栏中
GET请求常用的操作:
1. 在浏览器的地址栏中直接给出URL,那么就一定是GET请求
2. 点击页面上的超链接也一定是GET请求
3. 提交表单时,表单默认使用GET请求,但可以设置为POST
POST请求
1.数据不会出现在地址栏中
2.数据的大小没有上限
3.有请求体
4.请求体中如果存在中文,会使用URL编码!
#!!!requests.post()用法与requests.get()完全一致,特殊的是requests.post()有一个data参数,用来存放请求体数据
2、发送POST请求,模拟浏览器的登录行为
对于登录来说,应该输错用户名或密码然后分析抓包流程,用脑子想一想,输对了浏览器就跳转了,还分析个毛线,累死你也找不到包
一 目标站点分析
浏览器输入https://github.com/login
然后输入错误的账号密码,抓包
发现登录行为是post提交到:
https://github.com/session
而且请求头包含cookie
而且请求体包含:
commit:Sign in
utf8:✓
authenticity_token:lbI8IJCwGslZS8qJPnof5e7ZkCoSoMn6jmDTsL1r/m06NLyIbw7vCrpwrFAPzHMep3Tmf/TSJVoXWrvDZaVwxQ==
login:admin
password:123456
二 流程分析
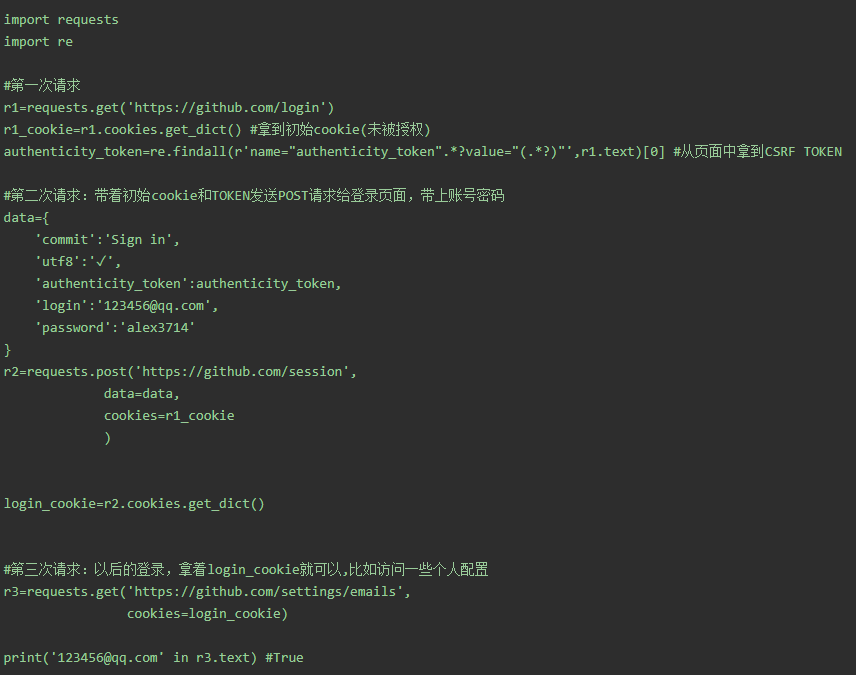
先GET:https://github.com/login拿到初始cookie与authenticity_token
返回POST:
https://github.com/session, 带上初始cookie,带上请求体(authenticity_token,用户名,密码等)
最后拿到登录cookie
ps:如果密码时密文形式,则可以先输错账号,输对密码,然后到浏览器中拿到加密后的密码,github的密码是明文
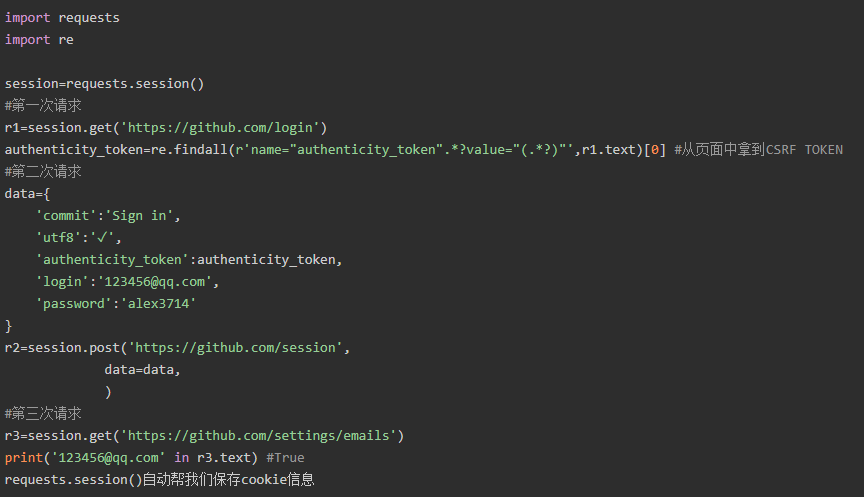
3、补充

四、 响应Response
1、response属性
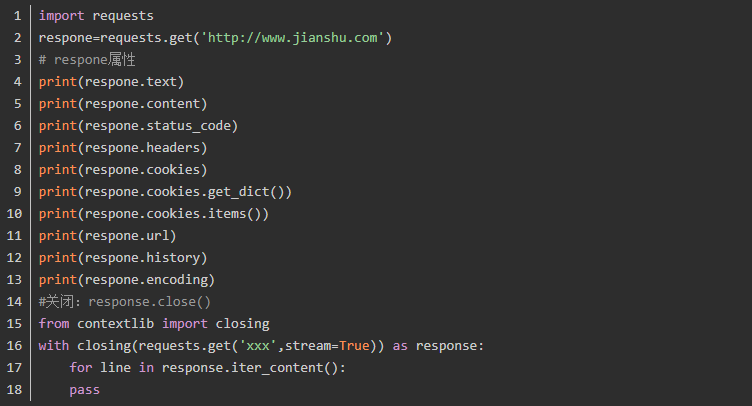
2、编码的问题

3、获取二进制数据
import requests
response=requests.get('https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=123456&di=712e4ef3ab258b36e9f4b48e85a81c9d&imgtype=0&src=http%3A%2F%2Fc.hiphotos.baidu.com%2Fimage%2Fpic%2Fitem%2F11385343fbf2b211e1fb58a1c08065380dd78e0c.jpg')
with open('a.jpg','wb') as f:
f.write(response.content)#stream参数:一点一点的取,比如下载视频时,如果视频100G,用response.content然后一下子写到文件中是不合理的
import requests
response=requests.get('https://gss3.baidu.com/6LZ0ej3k1Qd3ote6lo7D0j9wehsv/tieba-smallvideo-transcode/1767502_56ec685f9c7ec542eeaf6eac93a65dc7_6fe25cd1347c_3.mp4',
stream=True)
with open('b.mp4','wb') as f:
for line in response.iter_content():
f.write(line)4、解析json

5、Redirection and History
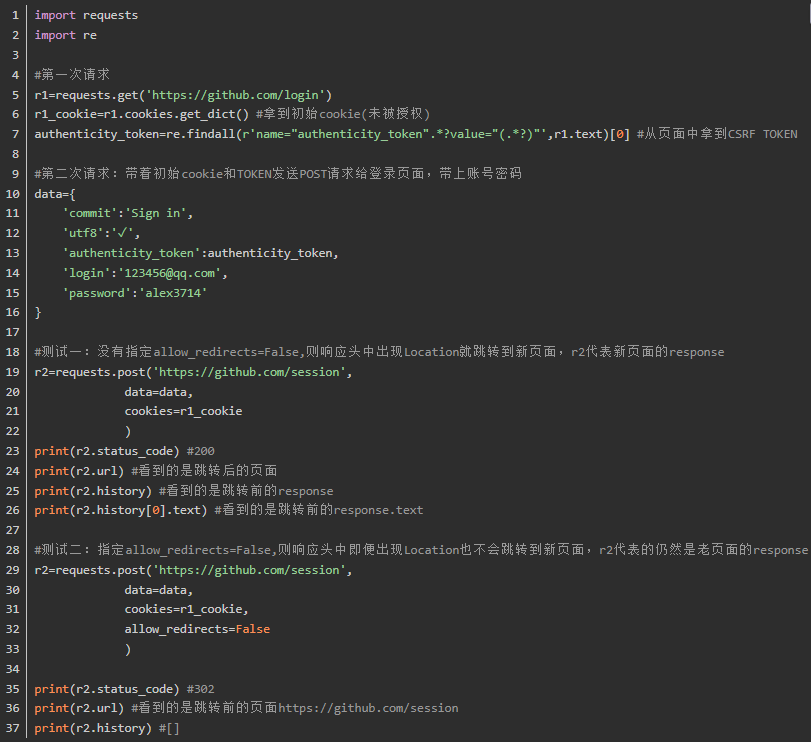
五、高级用法
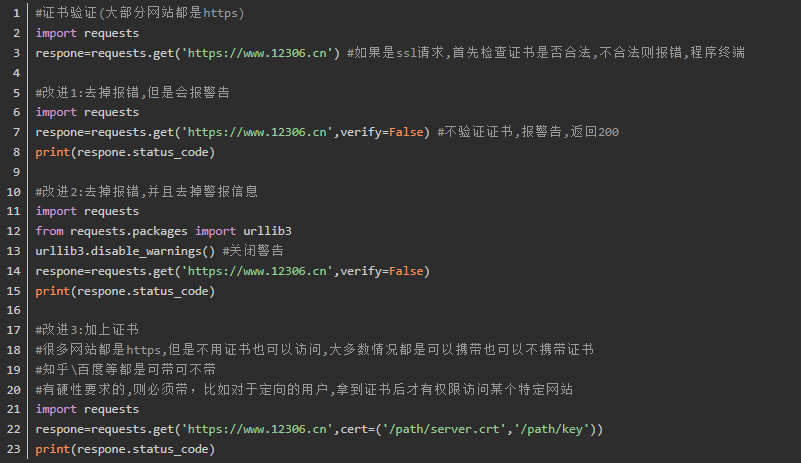
1、SSL Cert Verification
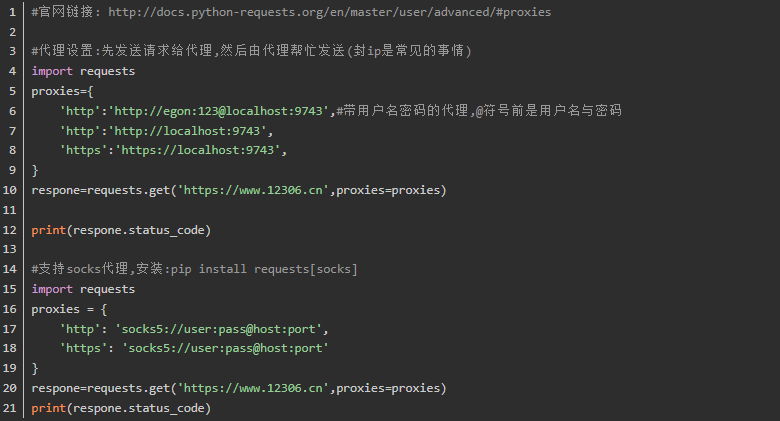
2、使用代理
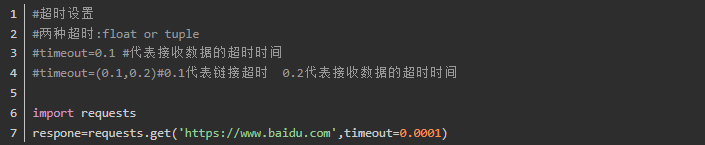
3、超时设置
4、认证设置

5、异常处理

6、上传文件
















 890
890











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









