







一、并发情况下内存分配
1、CAS配上失败重试保证保证线程安全
2、把内存分配的动作按照线程划分在不同的空间,即为每个线程在Java堆预先分配一小块内存,称为本地线程分配缓冲 (TLAB)。
二、对象头存放的信息
类的元数据指针、对象的哈希码、对象的GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等
三、对象的访问定位
1、句柄访问
2、直接指针
四、JVM命令行工具
1、jps: 显示系统内所有HotSpot虚拟机进程
2、jstat: 用于监视虚拟机各种运行状态信息,它可以显示本地或远程虚拟机进程中的类加载、内存、垃圾收集、JIT编译等运行数据
3、jinfo: 实时查看和调整虚拟机各项参数
4、jmap: 用于生成对转储快照
5、jhat:与jmap联合使用,用于分析对转储快照
6、jstack: 用于生成虚拟机当前时刻的线程快照。线程快照就是当前虚拟机中每一个线程正在执行的方法的堆栈集合,生成线程快照的目的就是定位线程出现长时间停顿的原因。
jmap
Jmap是一个可以输出所有内存中对象的工具,甚至可以将VM 中的heap,以二进制输出成文本。打印出某个java进程(使用pid)内存内的,所有‘对象’的情况(如:产生那些对象,及其数量)。
使用方法 jmap -histo pid。如果使用SHELL ,可采用jmap -histo pid>a.log日志将其保存到文件中,在一段时间后,使用文本对比工具,可以对比出GC回收了哪些对象。jmap -dump:format=b,file=outfile 3024 可以将3024进程的内存heap输出出来到outfile文件里,再配合MAT(内存分析工具)。
64位机上使用需要使用如下方式:
jmap -J-d64 -heap pid2、命令格式
l jmap [ option ] pid
l jmap [ option ] executable core
l jmap [ option ] [server-id@]remote-hostname-or-IP
3、参数说明
1)、options:
l executable :产生core dump的java可执行程序;
l core 将被打印信息的core dump文件;
l remote-hostname-or-IP 远程debug服务的主机名或ip;
l server-id 唯一id,假如一台主机上多个远程debug服务;
2)、基本参数:
Ø -dump:[live,]format=b,file= 使用hprof二进制形式,输出jvm的heap内容到文件=. live子选项是可选的,假如指定live选项,那么只输出活的对象到文件.
$jmap–dump:live,format=b,file=aaa.bin 3772
jstack
jstack主要用来查看某个Java进程内的线程堆栈信息。语法格式如下:
jstack [option] pid
jstack [option] executable core
jstack [option] [server-id@]remote-hostname-or-ip
命令行参数选项说明如下:
- -l long listings,会打印出额外的锁信息,在发生死锁时可以用jstack -l pid来观察锁持有情况
-
-m mixed mode,不仅会输出Java堆栈信息,还会输出C/C++堆栈信息(比如Native方法)
jstack可以定位到线程堆栈,根据堆栈信息我们可以定位到具体代码,所以它在JVM性能调优中使用得非常多。下面我们来一个实例找出某个Java进程中最耗费CPU的Java线程并定位堆栈信息,用到的命令有ps、top、printf、jstack、grep。
jstat(JVM统计监测工具)
语法格式如下:
jstat [ generalOption | outputOptions vmid [interval[s|ms] [count]] ]
vmid是虚拟机ID,在Linux/Unix系统上一般就是进程ID。interval是采样时间间隔。count是采样数目。比如下面输出的是GC信息,采样时间间隔为250ms,采样数为4:
root@ubuntu:/# jstat -gc 21711 250 4
S0C S1C S0U S1U EC EU OC OU PC PU YGC YGCT FGC FGCT GCT
192.0 192.0 64.0 0.0 6144.0 1854.9 32000.0 4111.6 55296.0 25472.7 702 0.431 3 0.218 0.649
192.0 192.0 64.0 0.0 6144.0 1972.2 32000.0 4111.6 55296.0 25472.7 702 0.431 3 0.218 0.649
192.0 192.0 64.0 0.0 6144.0 1972.2 32000.0 4111.6 55296.0 25472.7 702 0.431 3 0.218 0.649
192.0 192.0 64.0 0.0 6144.0 2109.7 32000.0 4111.6 55296.0 25472.7 702 0.431 3 0.218 0.649
要明白上面各列的意义,先看JVM堆内存布局:
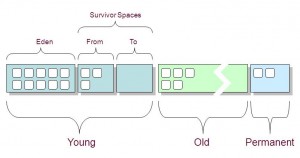
堆内存 = 年轻代 + 年老代 + 永久代
年轻代 = Eden区 + 两个Survivor区(From和To)
现在来解释各列含义:
S0C、S1C、S0U、S1U:Survivor 0/1区容量(Capacity)和使用量(Used)
EC、EU:Eden区容量和使用量
OC、OU:年老代容量和使用量
PC、PU:永久代容量和使用量
YGC、YGT:年轻代GC次数和GC耗时
FGC、FGCT:Full GC次数和Full GC耗时
GCT:GC总耗时
五、JVM 调优的方法
1 、 选择合适的堆大小
设置参数如下:
-Xmx:设置 JVM 最大可用内存
-Xms:设置 JVM 最小可用内存,一般-Xmx 和-Xms 相同,以避免每次垃圾回收完后 JVM 重新分配内存。
-Xmn:设置年轻代的大小。
-Xss:设置每个线程的堆栈大小
-XX:SurvivorRatio:设置年轻代中 Eden 和 Survivor 区的大小比值。
-XX:MaxTenuringThreshold:设置年轻代经过多少次 GC 进入老年代。
2 、 选择合适的回收器
吞吐量优先的应用使用并行收集器:
-XX:UseParellelGC:选择垃圾收集器为并行收集器
-XX:ParallelGCThreads=n:配置并行收集器的线程数
-XX:UseParallelOldGC:配置老年代垃圾收集方式为并行收集
-XX:MaxGCPauseMillis=n:设置每次年轻代垃圾回收的最长时间
响应时间优先的应用使用并发收集器:
-XX:UseParNewGC:设置年轻代为并发收集。可与 CMS 收集同时使用
-XX:UseConcMarkSweepGC:设置老年代为并发收集。
-XX:UseCMSCompactAtFullCollection:打开对年老代的压缩。可能会影响性能,但是可以消除碎片
-XX:CMSFullGCsBeforeCompaction:设置运行多少次 GC 以后对内存空间进行压缩、整理。















 295
295

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









