






 本文介绍了Laravel中chunk和chunkById在处理MySQL数据时的区别,尤其是在涉及分组和求和操作时。chunk会导致全表聚合分批取数据,而chunkById会忽略部分数据,影响统计准确性。在复杂业务场景中需谨慎选择使用方法。
本文介绍了Laravel中chunk和chunkById在处理MySQL数据时的区别,尤其是在涉及分组和求和操作时。chunk会导致全表聚合分批取数据,而chunkById会忽略部分数据,影响统计准确性。在复杂业务场景中需谨慎选择使用方法。
一、介绍
大家在日常开发过程中,在处理mysql数据时,肯定会遇到分块、分批次处理数据。在Laravel中提供了 chunk 与 chunkById ,可以使我们专注处理数据逻辑。
二、用法
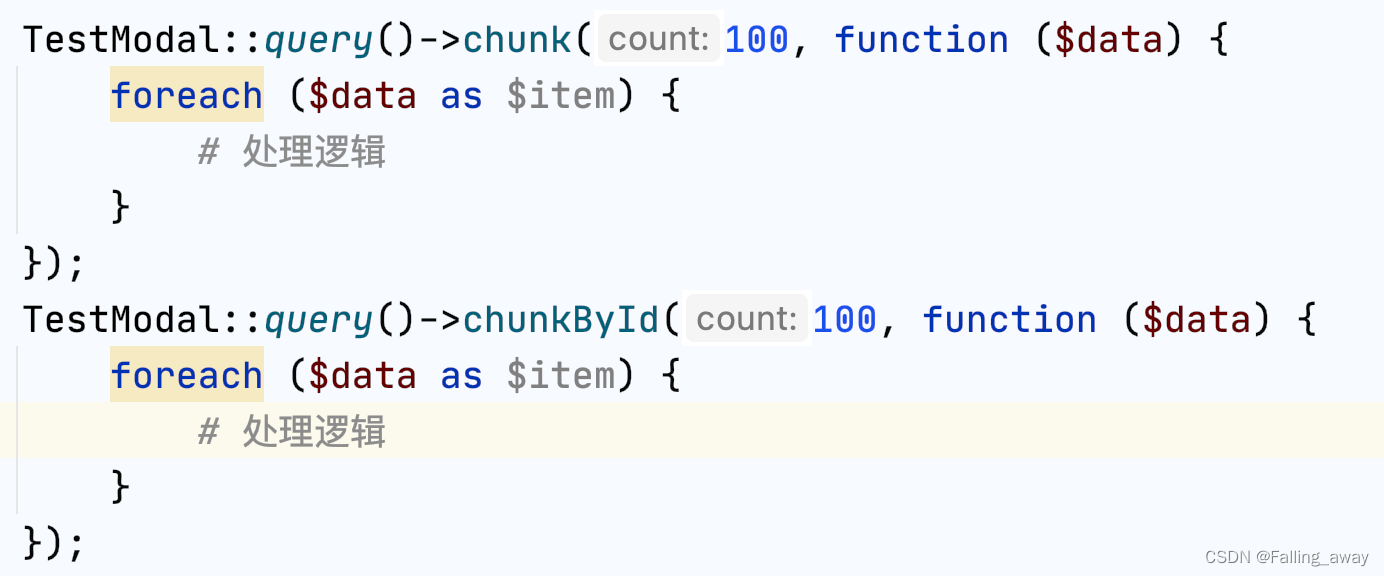
在用法上,可以看到两者没有区别。
三、区别
1、使用chunk时生成的sql
# 第一次
select * from `test` order by `id` asc limit 100 offset 0;
# 第二次
select * from `test` order by `id` asc limit 100 offset 100;
# 第三次
select * from `test` order by `id` asc limit 100 offset 200;
2、使用chunkById时生成的sql
# 第一次
select * from `test` order by `id` asc limit 100;
# 第二次
select * from `test` where `id` > 100 order by `id` asc limit 100;
# 第三次
select * from `test` where `id` > 200 order by `id` asc limit 100;
3、我们可以看到在全表处理时,两者sql虽格式不同,在处理全表数据并无特别大的区别。
四、避坑(重点来了)
相信每个公司的业务并不可能这么简单,只通过全表查询就完成业务。
当我们在程序中加入 分组(group by) 、字段求和(sum)等处理函数,就会发现 chunk 和 chunkById 两者本质上的区别。
1、使用chunk + group by + sum(字段)时生成的sql
# 第一次
select `name`, sum(`amount`) from `test` group by `name` order by `id` asc limit 100 offset 0;
# 第二次
select `name`, sum(`amount`) from `test` group by `name` order by `id` asc limit 100 offset 100;
# 第三次
select `name`, sum(`amount`) from `test` group by `name` order by `id` asc limit 100 offset 200;
2、使用chunkById + group by + sum(字段)时生成的sql
# 第一次
select `name`, sum(`amount`) from `test` group by `name` order by `id` asc limit 100;
# 第二次
select `name`, sum(`amount`) from `test` where `id` > 100 group by `name` order by `id` asc limit 100;
# 第三次
select `name`, sum(`amount`) from `test` where `id` > 200 group by `name` order by `id` asc limit 100;
3、通过生成的sql,我们可以看到一个本质上的区别。
我们会发现:
- chunk生成的sql,是全表聚合,在聚合完成后分批取数据。
- 而反观chunkById生成的sql,出现了where条件,这就会导致sql每次执行都会抛弃小于当前id的数据。
导致的后果:
- 使用 chunk + group by 统计的 sum(`amount`) 是准确无误的。
- 而使用 chunkById + group by 统计的sum(`amount`) 是错误的。
五、总结
当我们在日常开发过程中,在使用到chunk、chunkById时,如果只是简单的全表查询处理数据,两者并无无别。
当我们的业务场景比较复杂,需要用到group by、sum等函数时,切记:
使用chunk!!!
使用chunk!!!
使用chunk!!!

















 368
368

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









