







如今各个公司对程序员的数据库知识尤其是SQL语句的掌握程度有很高的要求,作为一名光荣的程序员,不会玩儿SQL语句走在街上根本不好意思和人打招呼!好了,废话不多说。
sql server常用的两种主键数据类型 int(或bigint)+标识列(又称自动增长字段),另外一种就是uniqueidentifier数据类型(又称Guid UUID)
GUID在SQL server里的使用就是直接newid就可以了
insert into T_us (id,userName,[password])values(newid,'tom',123456)
Guid在c#里的调用方法就是Guid.NewGuid();
一、SQL 基础知识
1、DDL(数据定义语言)
创建表
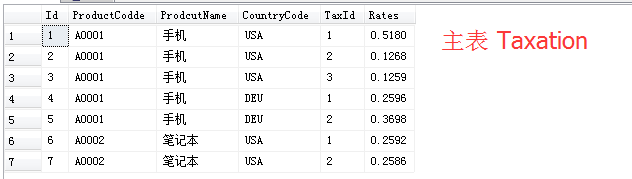
/*----------主表,各种产品在各国的税收种类及税率表----------*/
Create Table Procut_Taxation
(
Id int IDENTITY(1,1) PRIMARY KEY , --编号
ProductCodde varchar(20) null, --产品编码
ProdcutName nvarchar(50) null, --产品名称
CountryCode varchar(20) null, --国家编码
TaxId int null, --税种编号
Rates decimal(18, 4) null --税率
)
/*-------从表,税收种类表---------------*/
Create Table Procut_TaxSpecies
(
Id int IDENTITY(1,1) PRIMARY KEY , --编号
TaxId int null, --税种编号
TaxName nvarchar(50) null, --税收名称
IsEnable bit null, --是否启用
Remark nvarchar(1000) null, --备注
)

创建表,同时为表设置主键,及外键
Create table T_UserInfo --创建主表
(
Id int identity(1,1) primary key , --将Id设为自增的主键,每次自增1
Name nvarchar(4),
Age int,
LoginId int,
--将LoginId列设为外键,与这个外键对应的是(从表)T_UserLogin表中的LoginId列
Foreign key(LoginId) References T_UserLogin(LoginId)
)为表创建外键
为什么要创建外键?创建了外键与没有创建外键有什么区别:答案:如果说Taxation表与TaxSpecies表建立了以TaxId列为主外键的关系,那么在主表Taxation中添加一行的时候,其中TaxId列的值必须是在从表TaxSpecies中的TaxId列中存在的 (比方说:从表TaxSpecies中的TaxId列的值有1,2,3 那么我在主表Taxation中添加一行数据的时候,其中TaxId列的值必须是1或者2,或者3 ,不能是1,2,3之外的值)
--为(主表)Taxation表的TaxId列建立外键,与这个外键对应的是(从表)TaxSpecies表中的TaxId列
--特别要注意:(从表)TaxSpecies表中的TaxId列中每行的值必须是唯一的,这就要求TaxId列在TaxSpecies表中是主键,如果不是主键,那么需要给TaxId列添加唯一索引,以确保它的值是唯一的
alter table Taxation add constraint FK_Taxation_TaxSpecies foreign key(TaxId) references TaxSpecies(TaxId)
为表创建主键约束
--为T_UserInfo表创建一个主键约束,约束名为PK_UserInfo(主键约束名一般是以PK开头,后面跟_表名)
alter table T_UserInfo add constraint PK_UserInfo primary key(Id) --将Id列设为主键删除主键约束
alter table [Procut_TaxSpecies] drop constraint PK__Procut_T__3214EC07086D53A1 --删除主键约束(PK__Procut_T__3214EC07086D53A1是主键名称)为表创建唯一约束
--为TaxSpecies这个表的TaxId列建立一个名字为UQ_TaxSpecies_TaxId的唯一约束
alter table TaxSpecies add constraint UQ_TaxSpecies_TaxId unique nonclustered(TaxId)修改列的数据类型
alter table 表名 alter column 列名 decimal(18,4) not null --将列的数据类型修改为decimal(18, 4)修改列名
--exec sp_rename '表名.原列名','新列名','column'
exec sp_rename '[T_Book].FName','UserName','column'; --将T_Book表的FName列名修改为UserName增加列
alter table T_Book add Age int --为T_Book表添加一列,列名为Age,类型为int
alter table T_Book drop column Age --删除T_Book表中 名字为Age的列删除表
Drop table T_Book --删除T_Book表sql表是可以设置默认值的。如果id不是为int类型主键,而是guid类型主键,那么我们可以给id设一个默认值“newid()”到时候就会自动生成了。但是一般我们很少这么干。
use sales 指向sales的数据库
select 姓名 ,datediff(year,出生时间,getdate()) as '年龄' from xs --查询年龄datediff(year,出生时间,getdate())函数就是获取你的年龄,例如:36
2、DML(数据操纵语言)
插入数据
--插入一条据数,字段和值必须前后对应
insert into T_UserInfo (Name,Age,LoginId) values('Vicky', 20, 1)
insert into T_UserInfo (Name,Age,LoginId) values('Tom', 19, 2)
insert into T_UserInfo (Name,Age,LoginId) values('Jim', 19, 3)
insert into T_UserInfo (Name,Age,LoginId) values('Green', 20, 4)更新数据
update T_UserInfo set Age=30 where Id=1 --修改列,把Id的age字段改为30
update T_Person1 set Name=N'中文字符' where Age=2 --修改的值为中文的时候最好在前面加个一个N,以防出现乱码删除数据
delete from T_UserInfo --删除T_UserInfo表中全部数据
delete from T_UserInfo where Name='Tom' --删除T_UserInfo表中Name='Tom'的数据简单的数据查询
查询语句非常强大,几乎可以查任意东西!
select 1+1; --简单运算 输出:2
select newid() as [Guid];--创建一个Guid 输出: 2FBF779F-8101-4D4A-B966-AF0F1800B23B
select getdate() as 今日日期 --查询日期 输出:2016-07-17 21:42:11.750
select @@version as SQLServer版本 --可以查询SQLServer版本
select FNumber from T_Employee; --查询T_Employee表中名字为FNumber的列
select * from T_Employee where FSalary<5000; --查询T_Employee表中FSalary列的值小于5000的行
select FName as 姓名 from T_Employee; --as的作用是给列取别名(例如这里将FName列取个别名叫'姓名')
order by (asc desc ) 排序
--对表记录进行排序,默认排序规则是ASC
select * from T_Employee order by FAge asc, FSalary desc; --对FAge列作升序排序,然后对FSalary列作降序排序
--order by子句要放在 where 子句之后.
select * from T_Employee where FAge>23 order by FAge desc,FSalary desc;--WHERE 中可以使用的逻辑运算符:or、and、not、<、>、=、>=、<=、!=、<>等.
LIKE 模糊查询
--通配符查询
--1.单字符通配符_
--2.多字符通配符%
select * from T_Employee where FNumber like 'DEV%' --查询以 DEV 开头的任意个字符串
select * from T_Employee where FName like '_om' --查询以一个字符开头,om结尾的字符串
select * from T_Employee where FName like '%m%' --查询FName中包含m的字符
select * from xs where 姓名 like'王%' or 姓名 like'李%' --查询姓名以王和李开头的学生NULL 和 IS NOT NULL
--NULL 表示"不知道",不是没有值。有 NULL 参与的运算结果一般都为 NULL.
select NULL+1 --NULL和其他值计算结果是NULL
--查询数据是否为 NULL,不能用 = 、!= 或 <>,要用IS关键字
select * from T_Employee where FName IS NULL; --查询FName列为空的行
select * from T_Employee where FName IS NOT NULL; --查询FName列不为空的行IN 语句
--查询在某个范围内的数据,IN 表示包含于,IN后面是一个集合
select * from T_Employee where FAge IN (23, 25, 28); --查询FAge为23或25,或28的行between and
--下面两条查询语句等价。
select * from T_Employee where FAge>=23 AND FAge<=30;
select * from T_Employee where FAge BETWEEN 23 AND 30; --查询FAge在23到30之间的行
二、SQL Server 中的数据类型
1、精确数字类型
bigint int smallint tinyint bit money smallmoney
2、字符型数据类型,MS建议用VarChar(max)代替Text
Char VarChar Text
3、近似数字类型
Decimal Numeric Real Float
4、Unicode字符串类型
Nchar NvarChar Ntext
5、二进制数据类型,MS建议VarBinary(Max)代替Image数据类型,max=231-1
Binary(n) 存储固定长度的二进制数据 VarBinary(n) 存储可变长度的二进制数据,范围在n~(1,8000)
Image 存储图像信息
6、日期和时间类型,数据范围不同,精确地不同
DateTime SmallDateTime
7、特殊用途数据类型
Cursor Sql-variant Table TimeStamp UniqueIdentifier XML
创建一张T_Employee表,以下几个Demo中会用的这张表中的数据
----在SQL管理器中执行下面的SQL语句,在T_Employee表中进行练习
create table T_Employee
(
FNumber varchar(20),
FName varchar(20),
FAge int,
FSalary Numeric(10,2),
primary key (FNumber)
)
insert into T_Employee(FNumber,FName,FAge,FSalary) values('DEV001','Tom',25,8300)
insert into T_Employee(FNumber,FName,FAge,FSalary) values('DEV002','Jerry',28,2300.83)
insert into T_Employee(FNumber,FName,FAge,FSalary) values('SALES001','Lucy',25,5000)
insert into T_Employee(FNumber,FName,FAge,FSalary) values('SALES002','Lily',25,6200)
insert into T_Employee(FNumber,FName,FAge,FSalary) values('SALES003','Vicky',25,1200)
insert into T_Employee(FNumber,FName,FAge,FSalary) values('HR001','James',23,2200.88)
insert into T_Employee(FNumber,FName,FAge,FSalary) values('HR002','Tom',25,5100.36)
insert into T_Employee(FNumber,FName,FAge,FSalary) values('IT001','Tom',28,3900)
---修改数据表,添加字段,更新字段的值等操作。
alter table T_Employee add FSubCompany varchar(20)
alter table T_Employee add FDepartment varchar(20)
update T_Employee set FSubCompany='Beijing',FDepartment='Development'
where FNumber='DEV001';
update T_Employee set FSubCompany='ShenZhen',FDepartment='Development'
where FNumber='DEV002';
update T_Employee set FSubCompany='Beijing',FDepartment='HumanResource'
where FNumber='HR001';
update T_Employee set FSubCompany='Beijing',FDepartment='HumanResource'
where FNumber='HR002';
update T_Employee set FSubCompany='Beijing',FDepartment='InfoTech'
where FNumber='IT001';
update T_Employee set FSubCompany='ShenZhen',FDepartment='InfoTech'
where FNumber='IT002'
update T_Employee set FSubCompany='Beijing',FDepartment='Sales'
where FNumber='SALES001';
update T_Employee set FSubCompany='Beijing',FDepartment='Sales'
where FNumber='SALES002';
update T_Employee set FSubCompany='ShenZhen',FDepartment='Sales'
where FNumber='SALES003';
select * from T_Employee
Create Table T_TempEmployee (FIdCardNumber varchar(20),FName varchar(20),FAge int,Primarykey(FIdCardNumber));
insert into T_TempEmployee(FIdCardNumber,FName,FAge) values('1234567890121','Sarani',33);
insert into T_TempEmployee(FIdCardNumber,FName,FAge) values('1234567890122','Tom',26);
insert into T_TempEmployee(FIdCardNumber,FName,FAge) values('1234567890123','Yamaha',38);
insert into T_TempEmployee(FIdCardNumber,FName,FAge) values('1234567890124','Tina',36);
insert into T_TempEmployee(FIdCardNumber,FName,FAge) values('1234567890125','Konkaya',29);
insert into T_TempEmployee(FIdCardNumber,FName,FAge) values('1234567890126','Foortia',29);
select * from T_TempEmployee 三、SQL中的内置函数
聚合函数 (汇总,求最大值,求最小值,求平均值,求和)
select COUNT(*) from T_Employee --查询T_Employee表中数据条数
select MAX(FSalary) as Top1 from T_Employee --查询工资最高的人
select Min(FSalary) as Bottom1 from T_Employee --查询工资最低的人
select Avg(FSalary) as 平均水平 from T_Employee --查询工资的平均水平
select SUM(FSalary) as 总工资 from T_Employee --所有工资的和
select COUNT(*) as total from T_Employee where FSalary>5000 --查询工资大于5K的员工总数--年龄在35到36之间的学生信息 (表中没有学生的年龄,只有出生时间"1988-10-12 00:00:00",所以这个时候就必须把学生的年龄计算出来)
datediff(year,出生时间,getdate()) 就取得了学生的实际年龄 比如说36 ,有了所有学生的实际年龄。这个时候只要between
35 and 36 就可以啦。
select* from xs where
datediff(year,出生时间,getdate())between 35 and 36
group by 分组
--计算出具有相同年龄的人数(即:根据年龄进行分组,统计不同年龄的人数)
Select FAge ,COUNT(*) from T_Employee
group by FAge
--注意:没有出现在group by 子句中的字段,不能出现在select语句后的列名列表中(聚合函数除外)
Select FAge,AVG(FSalary),COUNT(*) from T_Employee
group by FAge
--错误用法
Select FAge,FName,COUNT(*) from T_Employee
group by FAge --因为FName字段没有出现在group by 子句中,所以它也不能出现在select语句中
--如果一条语句同时包含where和group by语句 那么group by语句必须出现在where语句后面
Select FAge,AVG(FSalary),COUNT(*) from T_Employee
where FAge>=25
group by FAgeHaving 语句
--having是分组(group by)后的筛选条件,分组后的数据组内再筛选
--where则是在分组前筛选
--Having不能包含查不到的字段,只能包含聚合函数和本次查询有关的字段
select FAge,COUNT(*) from T_Employee
group by FAge
Having COUNT(*)>2 --首先对FAge字段进行分组,并统计每组的数量,最后通过Having语句筛选出数量大于2的组
select FAge,COUNT(*) from T_Employee
group by FAge
Having COUNT(*)>1 and FAge>23 --对FAge字段进行分组,并统计每组数量,并筛选出数量大于1且FAge大于23的组Order by 排序
--Order by语句只能出现在 where语句 和 Group by语句的后面
select * from T_Employee --取出所有员工的信息,根据工资降序排列
order by FSalary DESC
select top 3 * from T_Employee --取出前三名员工的信息,根据工资降序排列
where FSalary >6000
order by FSalary DESC
--根据工资取出排名在6-8的员工信息,按工资降排列
select top 3 * from T_Employee
where FNumber not in (select top 5 FNumber from T_Employee order by FSalary DESC)
order by FSalary DESC
select FAge from T_Employee
where FSalary>2500
group by FAge --group by语句只能出现在where语句的后面
order by FAge desc --而order by语句只能出现在where或者order by的后面Distinct 语句 去重复
select Distinct FDepartment, FSubCompany from T_Employee; --去重(针对行去重复,针对一摸一行的行去重,一模一样即,每列都一样)
select FDepartment,FSubCompany from T_Employee --没有去重复Union 和 Union All 联合结果集
--Union关键字,联合2个结果
--把2个查询结果结合为1个查询结果
--要求:上下2个查询语句的字段(个数,名字,类型相容)必须一致
select FName,Fage from T_TempEmployee
union
select FName,Fage from T_Employee
select FNumber, FName,Fage,FDepartment from T_Employee
union
select FIdCardNumber,FName,Fage,'临时工,无部门' from T_TempEmployee
---Union All:不合并重复数据
--Union:合并重复数据
select FName,FAge from T_Employee
union all --不合并重复数据
select FName,FAge from T_TempEmployee
select FAge from T_Employee
union --合并重复数据
select FAge from T_TempEmployee
------------------------------
----- SQL其他内置函数 ------
------------------------------
--1.数学函数
--ABS():求绝对值
--CEILING():舍入到最大整数
--FLOOR():舍入到最小整数
--ROUND():四舍五入
select ABS(-3) --查询-3的绝对值。结果是3
--四舍五入。第二个参数是精度,小数点后的位数。
select ROUND(-3.61,1)--四舍五入。小数点精确到1位。结果是-3.6
select ROUND(-3.61,0)--四舍五入。小数点精确到0位。结果是-4
select ROUND(3.1415926,3)--四舍五入。小数点精确到3位。结果是-3.142
select CEILING(3.33)--舍入到最大整数。结果为4
select CEILING(-3.61)--舍入到最大整数。结果为-3
select FLOOR(2.98)--舍入到最小整数。结果为
select FLOOR(-3.61)--舍入到最整数。结果为-4
--2.字符串函数
--LEN():计算字符串长度
--LOWER(),UPPER():转大小写
--LTRIM():去掉字符串左侧的空格
--RTRIM():去掉字符串右侧的空格
--SUBSTRING(string,start_positoin,length):
--索引从1开始
select SUBSTRING('abc111',2,3)--结果是bc1
select FName, SUBSTRING(FName,2,2) from T_Employee
select LEN('abc') --结果是3
select FName, LEN(FName) from T_Employee
--没有可以同时既去掉左边空格、又去掉右边空格的TRIM()内置函数,所以先左后右的进行TRim,当然,你也可以先右后左
select LTRIM(' abc '),RTRIM(' abc '),LEN(LTRIM(RTRIM(' abc ')))
--3.日期函数
--GETDATE():获取当前日期时间
--DATEADD(datepart,numbre,date):计算增加以后的日期,
--参数date为待计算的日期;参数number为增量;参数datepart为计量单位,时间间隔单位;
--DATEDIFF(datepart,startdate,enddate):计算2个日期之间的差额
--DATEPART(datepart,date):返回一个日期的特定部分,比如年月日,时分秒等.
/*
值 缩 写(Sql Server) (Access 和 ASP) 说明
Year Yy yyyy 年 1753 ~ 9999
Quarter Qq q 季 1 ~ 4
Month Mm m 月 1 ~ 12
Day of year Dy y 一年的日数,一年中的第几日 1-366
Day Dd d 日, 1-31
Weekday Dw w 一周的日数,一周中的第几日 1-7
Week Wk ww 周,一年中的第几周 0 ~ 51
Hour Hh h 时0 ~ 23
Minute Mi n 分钟0 ~ 59
Second Ss s 秒 0 ~ 59
Millisecond Ms - 毫秒 0 ~ 999
*/
selectDATEADD(DAY,3,getdate())--在当前日期的基础上加上天
selectDATEADD(MONTH,-3,getdate())--在当前日期的基础上减去个月
selectDATEADD(HOUR,8,getdate()) --在当前日期的基础上加上小时
selectDATEDIFF(YEAR,'1989-05-01',GETDATE())--求年月日到当前时间的年限
selectDATEDIFF(HH,GETDATE(),DATEADD(DAY,-3,GETDATE()))
--查询员工的工龄,年为单位
select FName,FInDate,DATEDIFF(year,FInDate,getdate()) as 工龄 from T_Employee
--取出每一年入职员工的个数V1
select DATEDIFF(year,FInDate,getdate()),COUNT(*)
from T_Employee
group by DATEDIFF(year,FInDate,getdate())
--取出每一年入职员工的个数V2
select DATEPART(YEAR,FInDate), COUNT(*)
from T_Employee
group by DATEPART(YEAR,FInDate)
select DATEPART(YEAR,GETDATE()) --获取当前日期的年份
select DATEPART(MONTH,GETDATE()) --获取当前日期的月份
select DATEPART(DAY,GETDATE()) --获取当前日期的天数(比如,今天是多少号?)
select DATEPART(HH,GETDATE()) --获取当前日期的小时数(比如现在是几点)
select DATEPART(MINUTE,GETDATE())--获取当前日期的分数(比如现在是1:15分;那么查询结果就是15)
select DATEPART(SECOND,GETDATE())--获取当前日期的分数(比如现在是1:15:25秒;那么查询结果就是25)
CAST 和 Convert 类型转换函数
--CAST(expression as data_type)
--CONVERT(data_type,expression)
select cast('123.5' as float) --将字符串'123.5'转换成float类型的123.5
select convert(varchar(20),123) ----将数字123转换成varchar类型的'123'
select cast('2010-09-08' as datetime) --将字符串类型的'2010-09-08'转换成datetime类型(写法1)
select convert(datetime,'2010-09-08') --将字符串类型的'2010-09-08'转换成datetime类型(写法2)
select convert(varchar(100), getdate(), 120) --将当前时间转换为字符串类型。120是表示格式:2016-08-17 14:14:06
select convert(varchar(100), getdate(), 112) --将当前时间转换为字符串类型。112是表示格式:20160817isNull 空值处理函数
--ISNULL(expression,value)
select ISNULL(FName,'佚名') as 姓名 from T_Employee --如果FName这个字段为NULL 那么就用'佚名'替换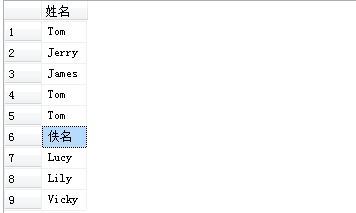
CASE函数 用法:
--1.单值判断:相当于switch.case
--CASE expression
--WHEN value1 then returnvalue1
--WHEN value2 then returnvalue2
--WHEN value3 then returnvalue3
--ELSE default_return_value
--END
--判断客户类型
select FName,
(
case FLevel
when 1 then '普通客户'
when 2 then '会员'
when 3 then 'VIP'
else '未知客户类型'
end
) as 客户类型
from T_Customer-----------------------------这两个case 的区别:上面的case 后面跟了FLevel字段。 when 1 表示FLevel等于某个值的时候(这里表示等于1的时候) 我们怎么处理
而下面这个case 后面没有跟字段的 。when FSalary<2000 表示 FSalary这个字段的值在某个区间的时候(这里表示<2000的这个区间)我们怎么处理。
--收入水平查询
select FName,
(
case
when FSalary < 2000 then '低收入'
when FSalary >= 2000 and FSalary <=5000 then '中等收入'
else '高收入'
end
)as 收入水平
from T_Employee-- 这里有一道关于 CASE 用法的面试题
--表T中有ABC三列,用SQL语句实现:当A列大于B列时选择A列,否则选择B列;
--当B列大于C列时选择B列,否则选择C列。
select(case when a > b then a else b end ),(case when b>c then b else c end )
from T---------------------------------------
select FNumber,
(case when FAmount>0 then FAmount else 0 end ) as 收入,
(case when FAmount<0 then ABS(FAmount) else 0 end ) as 支出
from T
select *,
(
case
when FSalary >8000 then '高收入'
when FSalary>5000 then '中等收入'
else '低收入'
end
)as 收入
from [T_Employee]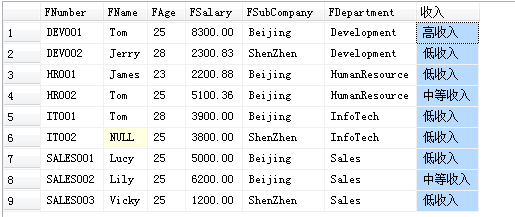
其实只要将收入改成FSalary ,然后不查询FSalary这一列,就达到将工资具体的金额以 高收入,中等收入,低收入来表示了
select FNumber,[FName],[FAge],
(
case
when FSalary >8000 then '高收入'
when FSalary>5000 then '中等收入'
else '低收入'
end) as [FSalary],[FSalary],[FSubCompany],[FDepartment]
from [T_Employee] 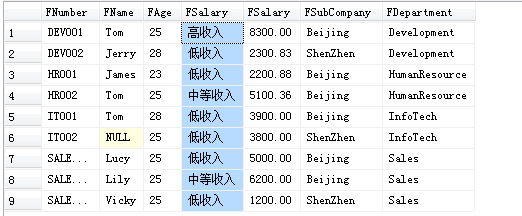
-----------------------------------------
--球队比赛那个题
--有一张表T_Scroes,记录比赛成绩:
--Date Name Scroe
--2008-8-8 拜仁 胜
--2008-8-9 奇才 胜
--2008-8-8 湖人 胜
--2008-8-10 拜仁 负
--2008-8-8 拜仁 负
--2008-8-12 奇才 胜
--要求输出下面格式:
--Name 胜 负
--拜仁 1 2
--湖人 1 0
--奇才 2 0
实现方法:我将每个队(Name)的Score中的值用数字标识,在胜的一栏里将胜用1来替代,负用0来替代,在负的一栏里 负用1替代,胜用0替代。然后查询每个队(Name)的 Score中值的和(sum).最后对Name进行分组
select Name, SUM(胜)as'胜',SUM(负) as'负' from(
select Name ,(case Scroes when '胜' then 1 else 0 end)as '胜',(case Score when '负' then 1 else 0 end)as'负'
from T_Scores) as t1
group by Name
--题5) 创建一张表,记录电话呼叫员的工作流水,记录呼叫员编号,对方号码,通话开始时间,通话结束时间,。
--创建一张表T_Callers,记录电话呼叫员的工作流水,记录呼叫员编号、对方号码、通话开始时间、通话结束时间。建表、插数据等最后都自己写SQL语句。
--要求:
-- 1) 输出所有数据中通话时间最长的5条记录。
-- 2) 输出所有数据中拨打长途号码(对方号码以0开头)的总时长。
-- 3) 输出本月通话总时长最多的前三个呼叫员的编号。
-- 4) 输出本月拨打电话次数最多的前三个呼叫员的编号。
-- 5) 输出所有数据的拨号流水,并且在最后一行添加总呼叫时长。
-- 记录呼叫员编号、对方号码、通话时长
-- ......
-- 汇总[市内号码总时长][长途号码总时长]
--Id CallerNumber TellNumber StartDateTime EndDateTime
--1 001 02088888888 2010-7-10 10:01 2010-7-10 10:05
--2 001 02088888888 2010-7-11 13:41 2010-7-11 13:52
--3 001 89898989 2010-7-11 14:42 2010-7-11 14:49
--4 002 02188368981 2010-7-13 21:04 2010-7-13 21:18
--5 002 76767676 2010-6-29 20:15 2010-6-29 20:30
--6 001 02288878243 2010-7-15 13:40 2010-7-15 13:56
--7 003 67254686 2010-7-13 11:06 2010-7-13 11:19
--8 003 86231445 2010-6-19 19:19 2010-6-19 19:25
--9 001 87422368 2010-6-19 19:25 2010-6-19 19:36
--10 004 40045862245 2010-6-19 19:50 2010-6-19 19:59
创建T_CallRecords表
create table T_CallRecords(
id int not null,
CallerNumber varchar(3),
TellNumber varchar(13),
StartDateTIme datetime,
EndDateTime datetime,
Primary key(Id)
);--插入数据
INSERT INTO T_CallRecords(Id,CallerNumber,TellNumber,StartDateTime,EndDateTIme)
VALUES(1,'001','02088888888','2010-7-10 10:01','2010-7-10 10:05');
INSERT INTO T_CallRecords(Id,CallerNumber,TellNumber,StartDateTime,EndDateTime)
VALUES (2,'002','02088888888', '2010-7-11 13:41','2010-7-11 13:52');
INSERT INTO T_CallRecords(Id,CallerNumber,TellNumber,StartDateTime,EndDateTime)
VALUES (3,'003','89898989', '2010-7-11 14:42', '2010-7-11 14:49');
INSERT INTO T_CallRecords(Id,CallerNumber,TellNumber,StartDateTime,EndDateTime)
VALUES (4,'004','02188368981', '2010-7-13 21:04', '2010-7-13 21:18');
INSERT INTO T_CallRecords(Id,CallerNumber,TellNumber,StartDateTime,EndDateTime)
VALUES (5,'005','76767676', '2010-6-29 20:15', '2010-6-29 20:30');
INSERT INTO T_CallRecords(Id,CallerNumber,TellNumber,StartDateTime,EndDateTime)
VALUES (6,'006','02288878243', '2010-7-15 13:40', '2010-7-15 13:56');
INSERT INTO T_CallRecords(Id,CallerNumber,TellNumber,StartDateTime,EndDateTime)
VALUES (7,'007','67254686', '2010-7-13 11:06', '2010-7-13 11:19');
INSERT INTO T_CallRecords(Id,CallerNumber,TellNumber,StartDateTime,EndDateTime)
VALUES (8,'008','86231445', '2010-6-19 19:19', '2010-6-19 19:25');
INSERT INTO T_CallRecords(Id,CallerNumber,TellNumber,StartDateTime,EndDateTime)
VALUES (9,'009','87422368', '2010-6-19 19:25', '2010-6-19 19:36');
INSERT INTO T_CallRecords(Id,CallerNumber,TellNumber,StartDateTime,EndDateTime)
VALUES (10,'010','40045862245', '2010-6-19 19:50', '2010-6-19 19:59');--修改呼叫员编号
UPDATE T_CallRecords SET CallerNumber='001' WHERE Id IN (1,2,3,6,9);
UPDATE T_CallRecords SET CallerNumber='002' WHERE Id IN (4,5);
UPDATE T_CallRecords SET CallerNumber='003' WHERE Id IN (7,8);
UPDATE T_CallRecords SET CallerNumber='004' WHERE Id=10;
创建四张表 T_Reader T_Book T_Category T_ReaderFavorite
--创建4张表
create table T_Reader(FId INT NOT NULL,FName varchar(50),FYearOfBirth INT,FCity varchar(50),FProvincevar char(50),FYearOfJoin INT);
create table T_Book(FId int not null,FName varchar(50),FYearPublished int,FCategoryId int);
create table T_Category(FId int not null,FName varchar(50));
create table T_ReaderFavorite(FCategoryId int,FReaderId int);
--分别为4张表插入数据
insert into T_Category(FId,FName) values(1,'Story');
insert into T_Category(FId,FName) values(2,'History');
insert into T_Category(FId,FName) values(3,'Theory');
insert into T_Category(FId,FName) values(4,'Technology');
insert into T_Category(FId,FName) values(5,'Art');
insert into T_Category(FId,FName) values(6,'Philosophy');
insert into T_Reader(FId,FName,FYearOfBirth,FCity,FProvince,FyearOfJoin)values(1,'Tom',1979,'TangShan','Hebei',2003);
insert into T_Reader(FId,FName,FYearOfBirth,FCity,FProvince,FyearOfJoin)values(2,'Sam',1981,'LangFang','Hebei',2001);
insert into T_Reader(FId,FName,FYearOfBirth,FCity,FProvince,FyearOfJoin)values(3,'Jerry',1966,'DongGuan','GuangDong',1995);
insert into T_Reader(FId,FName,FYearOfBirth,FCity,FProvince,FyearOfJoin)values(4,'Lily',1972,'JiaXing','ZheJiang',2005);
insert into T_Reader(FId,FName,FYearOfBirth,FCity,FProvince,FyearOfJoin)values(5,'Marry',1985,'BeiJing','BeiJing',1999);
insert into T_Reader(FId,FName,FYearOfBirth,FCity,FProvince,FyearOfJoin)values(6,'Kelly',1977,'ZhuZhou','HuNan',1995);
insert into T_Reader(FId,FName,FYearOfBirth,FCity,FProvince,FyearOfJoin)values(7,'Tim',1982,'YongZhou','HuNan',2001);
insert into T_Reader(FId,FName,FYearOfBirth,FCity,FProvince,FyearOfJoin)values(8,'King',1979,'JiNan','ShanDong',1997);
insert into T_Reader(FId,FName,FYearOfBirth,FCity,FProvince,FyearOfJoin)values(11,'John',1979,'QingDao','ShanDong',2003);
insert into T_Reader(FId,FName,FYearOfBirth,FCity,FProvince,FyearOfJoin)values(9,'Lucy',1978,'LuoYang','HeNan',1996);
insert into T_Reader(FId,FName,FYearOfBirth,FCity,FProvince,FyearOfJoin)values(10,'July',1983,'ZhuMaDian','HeNan',1999);
insert into T_Reader(FId,FName,FYearOfBirth,FCity,fProvince,FyearOfJoin)values(12,'Fige',1981,'JinCheng','ShanXi',2003);
insert into T_Book(FId,FName,FYearPublished,FCategoryId) values(1,'About J2EE',2005,4);
insert into T_Book(FId,FName,FYearPublished,FCategoryId) values(2,'Learning Hibernate',2003,4);
insert into T_Book(FId,FName,FYearPublished,FCategoryId) values(3,'Tow Cites',1999,1);
insert into T_Book(FId,FName,FYearPublished,FCategoryId) values(4,'Jane Eyre',2001,1);
insert into T_Book(FId,FName,FYearPublished,FCategoryId) values(5,'Oliver Twist',2002,1);
insert into T_Book(FId,FName,FYearPublished,FCategoryId) values(6,'History of China',1982,2);
insert into T_Book(FId,FName,FYearPublished,FCategoryId) values(7,'History of England',1860,2);
insert into T_Book(FId,FName,FYearPublished,FCategoryId) values(8,'History of America',1700,2);
insert into T_Book(FId,FName,FYearPublished,FCategoryId) values(9,'History of The Vorld',2008,2);
insert into T_Book(FId,FName,FYearPublished,FCategoryId) values(10,'Atom',1930,3);
insert into T_Book(FId,FName,FYearPublished,FCategoryId) values(11,'RELATIVITY',1945,3);
insert into T_Book(FId,FName,FYearPublished,FCategoryId) values(12,'Computer',1970,3);
insert into T_Book(FId,FName,FYearPublished,FCategoryId) values(13,'Astronomy',1971,3);
insert into T_Book(FId,FName,FYearPublished,FCategoryId) values(14,'How To singing',1771,5);
insert into T_Book(FId,FName,FYearPublished,FCategoryId) values(15,'DaoDeJing',2001,6);
insert into T_Book(FId,FName,FYearPublished,FCategoryId) values(16,'Obedience to Au',1995,6);
insert into T_ReaderFavorite(FCategoryId,FReaderId) values(1,1);
insert into T_ReaderFavorite(FCategoryId,FReaderId) values(5,2);
insert into T_ReaderFavorite(FCategoryId,FReaderId) values(2,3);
insert into T_ReaderFavorite(FCategoryId,FReaderId) values(3,4);
insert into T_ReaderFavorite(FCategoryId,FReaderId) values(5,5);
insert into T_ReaderFavorite(FCategoryId,FReaderId) values(1,6);
insert into T_ReaderFavorite(FCategoryId,FReaderId) values(1,7);
insert into T_ReaderFavorite(FCategoryId,FReaderId) values(4,8);
insert into T_ReaderFavorite(FCategoryId,FReaderId) values(6,9);
insert into T_ReaderFavorite(FCategoryId,FReaderId) values(5,10);
insert into T_ReaderFavorite(FCategoryId,FReaderId) values(2,11);
insert into T_ReaderFavorite(FCategoryId,FReaderId) values(2,12);
insert into T_ReaderFavorite(FCategoryId,FReaderId) values(1,12);
insert into T_ReaderFavorite(FCategoryId,FReaderId) values(3,1);
insert into T_ReaderFavorite(FCategoryId,FReaderId) values(1,3);
insert into T_ReaderFavorite(FCategoryId,FReaderId) values(4,4);
--题 1): 输出所有数据中通话时间最长的5条记录。
--@计算通话时间;
--@按通话时间降序排列;
--@取前5条记录。
select top 5 CallerNumber,DATEDIFF(SECOND,StartDateTime,EndDateTime) as 总时长
from T_CallRecords
order by DATEDIFF(SECOND,StartDateTime,EndDateTime) DESC
--题 2):输出所有数据中拨打长途号码(对方号码以0开头)的总时长
--@查询拨打长途号码的记录;
--@计算各拨打长途号码的通话时长;
--@对各拨打长途号码的通话时长进行求和。
select SUM(DATEDIFF(SECOND,StartDateTime,EndDateTime)) as 总时长 from T_CallRecords
where TellNumber like '0%'
--题 3):输出本月通话总时长最多的前三个呼叫员的编号。
--@按呼叫员编号进行分组;
--@计算各呼叫员通话总时长;
--@按通话总时长进行降序排列;
--@查询前3条记录中呼叫员的编号。
select datediff(month,convert(datetime,'2010-06-01'),convert(datetime,'2010-07-22'))--测试
select CallerNumber,TellNumber,datediff(month,StartDateTime,EndDateTime)
from T_CallRecords
select top 3 CallerNumber from T_CallRecords
where datediff(month,StartDateTime,getdate())=12--一年前的
group by CallerNumber
order by SUM(DATEDIFF(SECOND,StartDateTime,EndDateTime)) DESC
--题 4) 输出本月拨打电话次数最多的前三个呼叫员的编号.
--@按呼叫员编号进行分组;
--@计算个呼叫员拨打电话的次数;
--@按呼叫员拨打电话的次数进行降序排序;
--@查询前3条记录中呼叫员的编号。
select top 3 CallerNumber,count(*)
from T_CallRecords
where datediff(month,StartDateTime,getdate())=12--一年前的
group by CallerNumber
order by count(*) DESC
--题5) 输出所有数据的拨号流水,并且在最后一行添加总呼叫时长:
-- 记录呼叫员编号、对方号码、通话时长
-- ......
-- 汇总[市内号码总时长][长途号码总时长]
--@计算每条记录中通话时长;
--@查询包含不加 0 号码,即市内号码的记录;
--@计算市内号码通话总时长;
--@查询包含加 0 号码,即长途号码的记录;
--@计算长途号码通话总时长;
--@联合查询。
select '汇总' as 汇总,
convert(varchar(20),
sum((
case
when TellNumber not like '0%' then datediff(second,StartDateTime,EndDateTime)
else 0
end
))) as 市内通话,
sum((
case
when TellNumber like '0%' then datediff(second,StartDateTime,EndDateTime)
else 0
end
)) as 长途通话
from T_CallRecords
union all
select CallerNumber,TellNumber,datediff(second,StartDateTime,EndDateTime) as 通话时长
from T_CallRecords
--客户和订单表的练习
--建立一个客户表
create table T_Customers(
id int not null,
name nvarchar(50) collate chinese_prc_ci_as null,
age int null
);
insert T_Customers(id,name,age) values(1,N'tom',10);
insert T_Customers(id,name,age) values(2,N'jerry',15);
insert T_Customers(id,name,age) values(3,N'john',22);
insert T_Customers(id,name,age) values(4,N'lily',18);
insert T_Customers(id,name,age) values(5,N'lucy',18);
select * from T_Customers
--建立一个销售单表
create table T_Orders(
id int not null,
billno nvarchar(50) collate chinese_prc_ci_as null,
customerid int null);
insert T_Orders(id,billno,customerid)values(1,N'001',1)
insert T_Orders(id,billno,customerid)values(2,N'002',1)
insert T_Orders(id,billno,customerid)values(3,N'003',3)
insert T_Orders(id,billno,customerid)values(4,N'004',2)
insert T_Orders(id,billno,customerid)values(5,N'005',2)
insert T_Orders(id,billno,customerid)values(6,N'006',5)
insert T_Orders(id,billno,customerid)values(7,N'007',4)
insert T_Orders(id,billno,customerid)values(8,N'008',5)
select * from T_Orders
select o.billno,c.name,c.age
from T_Orders as o join T_Customers as c on o.customerid=c.id
--查询订单号,顾客名字,顾客年龄
select o.billno,c.name,c.age
from T_Orders as o join T_Customers as c on o.customerid=c.id
where c.age>15
--显示年龄大于15岁的顾客姓名、年龄和订单号
select o.billno,c.name,c.age
from T_Orders as o join T_Customers as c on o.customerid=c.id
where c.age>(select avg(age) from T_Customers)
--显示年龄大于平均年龄的顾客姓名、年龄和订单号
--子查询练习
--新建一个数据库,名为BookShop
Create database BookShop
select * from T_Book
select * from T_Category
select * from T_Reader
select * from T_ReaderFavorite
--并列查询
select 1 as f1,2,(select MIN(FYearPublished) from T_Book),
(select MAX(FYearPublished) from T_Book) as f4
--查询入会日期在2001或者2003年的读者信息
select * from T_Reader
where FYearOfJoin in (2001,2003)
--与between...and不同
select * from T_Reader
where FYearOfJoin between 2001 and 2003
--查询有书出版的年份入会的读者信息
select * from T_Reader
where FYearOfJoin in
(
select FYearPublished from T_Book
)
--SQL Server 2005之后的版本内置函数:ROW_NUMBER(),称为开窗函数,可以进行分页等操作。
select ROW_NUMBER() over(order by FSalary DESC) as Row_Num,
FNumber,FName,FSalary,FAge from T_Employee
--特别注意,开窗函数row_number()只能用于select或order by 子句中,不能用于where子句中
效果:在前面增加了一列行号。及对FSalary 做了降序排序。
| Row_Num | FNumber | FName | FSalary | FAge |
| 1 | DEV001 | Tom | 8300 | 25 |
| 2 | SALES002 | Lily | 6200 | 25 |
| 3 | HR002 | Tom | 5100.36 | 25 |
| 4 | SALES001 | Lucy | 5000 | 25 |
| 5 | IT001 | Tom | 3900 | 28 |
| 6 | IT002 | NULL | 3800 | 25 |
| 7 | DEV002 | Jerry | 2300.83 | 28 |
| 8 | HR001 | James | 2200.88 | 23 |
| 9 | SALES003 | Vicky | 1200 | 25 |
--查询第3行到第5行的数据
select * from
(
select ROW_NUMBER() over(order by FSalary DESC) as Row_Num,
FNumber,FName,FSalary,FAge from T_Employee
) as e1
where e1.Row_Num>=3 and e1.Row_Num<=5
四、SQL其他概念
--索引
1、什么是索引?优缺点是什么?
索引是对数据库表中一列或多列的值进行排序的一种单独的、物理的数据库结构。
优点:
1) 大大加快数据的检索速度;
2) 创建唯一性索引,保证数据库表中每一行数据的唯一性;
3) 加速表和表之间的连接;
4) 在使用分组和排序子句进行数据检索时,可以显著减少查询中分组和排序的时间。
缺点:
1) 索引需要占物理空间;
2) 当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,降低了数据的维护速度。
--创建索引,在列上点击右键,写一个名称,选定列即可。
2、业务主键和逻辑主键
业务主键是使用有业务意义的字段做主键,比如身份证号,银行账号等;
逻辑主键是使用没有任何业务意义的字段做主键。因为很难保证业务主键不会重复(身份证号重复)、不会变化(账号升位),因此推荐使用逻辑主键。
3、SQL Server 两种常用的主键数据类型
1) int(或 bigint) + 标识列(又称自动增长字段)
用标识列实现字段自增可以避免并发等问题,不要开发人员控制自增。用标识列的字段在Insert的时候不用指定主键的值。
优点:占用空间小、无需开发人员干预、易读;
缺点:效率低,数据导入导出的时候很痛苦。
设置:"修改表"->选定主键->"列属性"->"标识规范"选择"是"
2) uniqueidentifier(又称GUID、UUID)
GUID算法是一种可以产生唯一表示的高效算法,它使用网卡MAC、地址、纳秒级时间、芯片ID码等算出来的,这样保证每次生成的GUID永远不会重复,无论是同一计算机还是不同计算机。在公元3400年前产生的GUID与任何其他产生过的GUID都不相同。
SQL Server中生成GUID的函数newid()。
优点:效率高、数据导入导出方便;
缺点:占用空间大、不易读。
业界主流倾向于使用GUID。
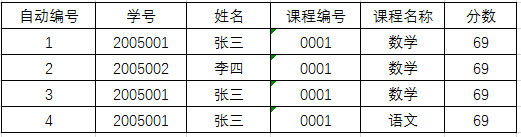
写法1
selectmin(自动编号)as自动编号,学号,姓名,课程编号,课程名称,分数from stu
groupby学号,姓名,课程编号,课程名称,分数
orderby自动编号
写法2
select*from stu where 自动编号in(
selectmin(自动编号)as自动编号from stu
groupby学号,姓名,课程编号,课程名称,分数
)--注意:这里不允许有order by语句哦
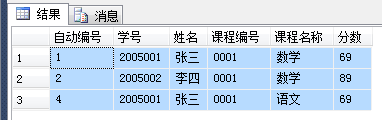
以上语句仅仅是查询,这条语句是删除,删除后,自动编号为3的那条数据就删除了
delete stuwhere自动编号notin(
selectmin(自动编号)as自动编号from stu
groupby学号,姓名,课程编号,课程名称,分数
)--注意:这里不允许有order by语句哦















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









